Data, Covariance, and Correlation Matrix
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

04 – Everything You Want to Know About Correlation but Were
EVERYTHING YOU WANT TO KNOW ABOUT CORRELATION BUT WERE AFRAID TO ASK F R E D K U O 1 MOTIVATION • Correlation as a source of confusion • Some of the confusion may arise from the literary use of the word to convey dependence as most people use “correlation” and “dependence” interchangeably • The word “correlation” is ubiquitous in cost/schedule risk analysis and yet there are a lot of misconception about it. • A better understanding of the meaning and derivation of correlation coefficient, and what it truly measures is beneficial for cost/schedule analysts. • Many times “true” correlation is not obtainable, as will be demonstrated in this presentation, what should the risk analyst do? • Is there any other measures of dependence other than correlation? • Concordance and Discordance • Co-monotonicity and Counter-monotonicity • Conditional Correlation etc. 2 CONTENTS • What is Correlation? • Correlation and dependence • Some examples • Defining and Estimating Correlation • How many data points for an accurate calculation? • The use and misuse of correlation • Some example • Correlation and Cost Estimate • How does correlation affect cost estimates? • Portfolio effect? • Correlation and Schedule Risk • How correlation affect schedule risks? • How Shall We Go From Here? • Some ideas for risk analysis 3 POPULARITY AND SHORTCOMINGS OF CORRELATION • Why Correlation Is Popular? • Correlation is a natural measure of dependence for a Multivariate Normal Distribution (MVN) and the so-called elliptical family of distributions • It is easy to calculate analytically; we only need to calculate covariance and variance to get correlation • Correlation and covariance are easy to manipulate under linear operations • Correlation Shortcomings • Variances of R.V. -

11. Correlation and Linear Regression
11. Correlation and linear regression The goal in this chapter is to introduce correlation and linear regression. These are the standard tools that statisticians rely on when analysing the relationship between continuous predictors and continuous outcomes. 11.1 Correlations In this section we’ll talk about how to describe the relationships between variables in the data. To do that, we want to talk mostly about the correlation between variables. But first, we need some data. 11.1.1 The data Table 11.1: Descriptive statistics for the parenthood data. variable min max mean median std. dev IQR Dan’s grumpiness 41 91 63.71 62 10.05 14 Dan’s hours slept 4.84 9.00 6.97 7.03 1.02 1.45 Dan’s son’s hours slept 3.25 12.07 8.05 7.95 2.07 3.21 ............................................................................................ Let’s turn to a topic close to every parent’s heart: sleep. The data set we’ll use is fictitious, but based on real events. Suppose I’m curious to find out how much my infant son’s sleeping habits affect my mood. Let’s say that I can rate my grumpiness very precisely, on a scale from 0 (not at all grumpy) to 100 (grumpy as a very, very grumpy old man or woman). And lets also assume that I’ve been measuring my grumpiness, my sleeping patterns and my son’s sleeping patterns for - 251 - quite some time now. Let’s say, for 100 days. And, being a nerd, I’ve saved the data as a file called parenthood.csv. -

LECTURES 2 - 3 : Stochastic Processes, Autocorrelation Function
LECTURES 2 - 3 : Stochastic Processes, Autocorrelation function. Stationarity. Important points of Lecture 1: A time series fXtg is a series of observations taken sequentially over time: xt is an observation recorded at a specific time t. Characteristics of times series data: observations are dependent, become available at equally spaced time points and are time-ordered. This is a discrete time series. The purposes of time series analysis are to model and to predict or forecast future values of a series based on the history of that series. 2.2 Some descriptive techniques. (Based on [BD] x1.3 and x1.4) ......................................................................................... Take a step backwards: how do we describe a r.v. or a random vector? ² for a r.v. X: 2 d.f. FX (x) := P (X · x), mean ¹ = EX and variance σ = V ar(X). ² for a r.vector (X1;X2): joint d.f. FX1;X2 (x1; x2) := P (X1 · x1;X2 · x2), marginal d.f.FX1 (x1) := P (X1 · x1) ´ FX1;X2 (x1; 1) 2 2 mean vector (¹1; ¹2) = (EX1; EX2), variances σ1 = V ar(X1); σ2 = V ar(X2), and covariance Cov(X1;X2) = E(X1 ¡ ¹1)(X2 ¡ ¹2) ´ E(X1X2) ¡ ¹1¹2. Often we use correlation = normalized covariance: Cor(X1;X2) = Cov(X1;X2)=fσ1σ2g ......................................................................................... To describe a process X1;X2;::: we define (i) Def. Distribution function: (fi-di) d.f. Ft1:::tn (x1; : : : ; xn) = P (Xt1 · x1;:::;Xtn · xn); i.e. this is the joint d.f. for the vector (Xt1 ;:::;Xtn ). (ii) First- and Second-order moments. ² Mean: ¹X (t) = EXt 2 2 2 2 ² Variance: σX (t) = E(Xt ¡ ¹X (t)) ´ EXt ¡ ¹X (t) 1 ² Autocovariance function: γX (t; s) = Cov(Xt;Xs) = E[(Xt ¡ ¹X (t))(Xs ¡ ¹X (s))] ´ E(XtXs) ¡ ¹X (t)¹X (s) (Note: this is an infinite matrix). -

Ph 21.5: Covariance and Principal Component Analysis (PCA)
Ph 21.5: Covariance and Principal Component Analysis (PCA) -v20150527- Introduction Suppose we make a measurement for which each data sample consists of two measured quantities. A simple example would be temperature (T ) and pressure (P ) taken at time (t) at constant volume(V ). The data set is Ti;Pi ti N , which represents a set of N measurements. We wish to make sense of the data and determine thef dependencej g of, say, P on T . Suppose P and T were for some reason independent of each other; then the two variables would be uncorrelated. (Of course we are well aware that P and V are correlated and we know the ideal gas law: PV = nRT ). How might we infer the correlation from the data? The tools for quantifying correlations between random variables is the covariance. For two real-valued random variables (X; Y ), the covariance is defined as (under certain rather non-restrictive assumptions): Cov(X; Y ) σ2 (X X )(Y Y ) ≡ XY ≡ h − h i − h i i where ::: denotes the expectation (average) value of the quantity in brackets. For the case of P and T , we haveh i Cov(P; T ) = (P P )(T T ) h − h i − h i i = P T P T h × i − h i × h i N−1 ! N−1 ! N−1 ! 1 X 1 X 1 X = PiTi Pi Ti N − N N i=0 i=0 i=0 The extension of this to real-valued random vectors (X;~ Y~ ) is straighforward: D E Cov(X;~ Y~ ) σ2 (X~ < X~ >)(Y~ < Y~ >)T ≡ X~ Y~ ≡ − − This is a matrix, resulting from the product of a one vector and the transpose of another vector, where X~ T denotes the transpose of X~ . -

6 Probability Density Functions (Pdfs)
CSC 411 / CSC D11 / CSC C11 Probability Density Functions (PDFs) 6 Probability Density Functions (PDFs) In many cases, we wish to handle data that can be represented as a real-valued random variable, T or a real-valued vector x =[x1,x2,...,xn] . Most of the intuitions from discrete variables transfer directly to the continuous case, although there are some subtleties. We describe the probabilities of a real-valued scalar variable x with a Probability Density Function (PDF), written p(x). Any real-valued function p(x) that satisfies: p(x) 0 for all x (1) ∞ ≥ p(x)dx = 1 (2) Z−∞ is a valid PDF. I will use the convention of upper-case P for discrete probabilities, and lower-case p for PDFs. With the PDF we can specify the probability that the random variable x falls within a given range: x1 P (x0 x x1)= p(x)dx (3) ≤ ≤ Zx0 This can be visualized by plotting the curve p(x). Then, to determine the probability that x falls within a range, we compute the area under the curve for that range. The PDF can be thought of as the infinite limit of a discrete distribution, i.e., a discrete dis- tribution with an infinite number of possible outcomes. Specifically, suppose we create a discrete distribution with N possible outcomes, each corresponding to a range on the real number line. Then, suppose we increase N towards infinity, so that each outcome shrinks to a single real num- ber; a PDF is defined as the limiting case of this discrete distribution. -

Construct Validity and Reliability of the Work Environment Assessment Instrument WE-10
International Journal of Environmental Research and Public Health Article Construct Validity and Reliability of the Work Environment Assessment Instrument WE-10 Rudy de Barros Ahrens 1,*, Luciana da Silva Lirani 2 and Antonio Carlos de Francisco 3 1 Department of Business, Faculty Sagrada Família (FASF), Ponta Grossa, PR 84010-760, Brazil 2 Department of Health Sciences Center, State University Northern of Paraná (UENP), Jacarezinho, PR 86400-000, Brazil; [email protected] 3 Department of Industrial Engineering and Post-Graduation in Production Engineering, Federal University of Technology—Paraná (UTFPR), Ponta Grossa, PR 84017-220, Brazil; [email protected] * Correspondence: [email protected] Received: 1 September 2020; Accepted: 29 September 2020; Published: 9 October 2020 Abstract: The purpose of this study was to validate the construct and reliability of an instrument to assess the work environment as a single tool based on quality of life (QL), quality of work life (QWL), and organizational climate (OC). The methodology tested the construct validity through Exploratory Factor Analysis (EFA) and reliability through Cronbach’s alpha. The EFA returned a Kaiser–Meyer–Olkin (KMO) value of 0.917; which demonstrated that the data were adequate for the factor analysis; and a significant Bartlett’s test of sphericity (χ2 = 7465.349; Df = 1225; p 0.000). ≤ After the EFA; the varimax rotation method was employed for a factor through commonality analysis; reducing the 14 initial factors to 10. Only question 30 presented commonality lower than 0.5; and the other questions returned values higher than 0.5 in the commonality analysis. Regarding the reliability of the instrument; all of the questions presented reliability as the values varied between 0.953 and 0.956. -
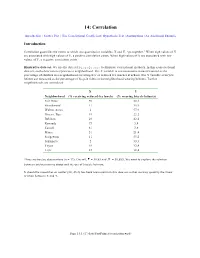
14: Correlation
14: Correlation Introduction | Scatter Plot | The Correlational Coefficient | Hypothesis Test | Assumptions | An Additional Example Introduction Correlation quantifies the extent to which two quantitative variables, X and Y, “go together.” When high values of X are associated with high values of Y, a positive correlation exists. When high values of X are associated with low values of Y, a negative correlation exists. Illustrative data set. We use the data set bicycle.sav to illustrate correlational methods. In this cross-sectional data set, each observation represents a neighborhood. The X variable is socioeconomic status measured as the percentage of children in a neighborhood receiving free or reduced-fee lunches at school. The Y variable is bicycle helmet use measured as the percentage of bicycle riders in the neighborhood wearing helmets. Twelve neighborhoods are considered: X Y Neighborhood (% receiving reduced-fee lunch) (% wearing bicycle helmets) Fair Oaks 50 22.1 Strandwood 11 35.9 Walnut Acres 2 57.9 Discov. Bay 19 22.2 Belshaw 26 42.4 Kennedy 73 5.8 Cassell 81 3.6 Miner 51 21.4 Sedgewick 11 55.2 Sakamoto 2 33.3 Toyon 19 32.4 Lietz 25 38.4 Three are twelve observations (n = 12). Overall, = 30.83 and = 30.883. We want to explore the relation between socioeconomic status and the use of bicycle helmets. It should be noted that an outlier (84, 46.6) has been removed from this data set so that we may quantify the linear relation between X and Y. Page 14.1 (C:\data\StatPrimer\correlation.wpd) Scatter Plot The first step is create a scatter plot of the data. -

Spatial Autocorrelation: Covariance and Semivariance Semivariance
Spatial Autocorrelation: Covariance and Semivariancence Lily Housese P eters GEOG 593 November 10, 2009 Quantitative Terrain Descriptorsrs Covariance and Semivariogram areare numericc methods used to describe the character of the terrain (ex. Terrain roughness, irregularity) Terrain character has important implications for: 1. the type of sampling strategy chosen 2. estimating DTM accuracy (after sampling and reconstruction) Spatial Autocorrelationon The First Law of Geography ““ Everything is related to everything else, but near things are moo re related than distant things.” (Waldo Tobler) The value of a variable at one point in space is related to the value of that same variable in a nearby location Ex. Moranan ’s I, Gearyary ’s C, LISA Positive Spatial Autocorrelation (Neighbors are similar) Negative Spatial Autocorrelation (Neighbors are dissimilar) R(d) = correlation coefficient of all the points with horizontal interval (d) Covariance The degree of similarity between pairs of surface points The value of similarity is an indicator of the complexity of the terrain surface Smaller the similarity = more complex the terrain surface V = Variance calculated from all N points Cov (d) = Covariance of all points with horizontal interval d Z i = Height of point i M = average height of all points Z i+d = elevation of the point with an interval of d from i Semivariancee Expresses the degree of relationship between points on a surface Equal to half the variance of the differences between all possible points spaced a constant distance apart -

Fast Estimation of the Median Covariation Matrix with Application to Online Robust Principal Components Analysis
Fast Estimation of the Median Covariation Matrix with Application to Online Robust Principal Components Analysis Hervé Cardot, Antoine Godichon-Baggioni Institut de Mathématiques de Bourgogne, Université de Bourgogne Franche-Comté, 9, rue Alain Savary, 21078 Dijon, France July 12, 2016 Abstract The geometric median covariation matrix is a robust multivariate indicator of dis- persion which can be extended without any difficulty to functional data. We define estimators, based on recursive algorithms, that can be simply updated at each new observation and are able to deal rapidly with large samples of high dimensional data without being obliged to store all the data in memory. Asymptotic convergence prop- erties of the recursive algorithms are studied under weak conditions. The computation of the principal components can also be performed online and this approach can be useful for online outlier detection. A simulation study clearly shows that this robust indicator is a competitive alternative to minimum covariance determinant when the dimension of the data is small and robust principal components analysis based on projection pursuit and spherical projections for high dimension data. An illustration on a large sample and high dimensional dataset consisting of individual TV audiences measured at a minute scale over a period of 24 hours confirms the interest of consider- ing the robust principal components analysis based on the median covariation matrix. All studied algorithms are available in the R package Gmedian on CRAN. Keywords. Averaging, Functional data, Geometric median, Online algorithms, Online principal components, Recursive robust estimation, Stochastic gradient, Weiszfeld’s algo- arXiv:1504.02852v5 [math.ST] 9 Jul 2016 rithm. -

Characteristics and Statistics of Digital Remote Sensing Imagery (1)
Characteristics and statistics of digital remote sensing imagery (1) Digital Images: 1 Digital Image • With raster data structure, each image is treated as an array of values of the pixels. • Image data is organized as rows and columns (or lines and pixels) start from the upper left corner of the image. • Each pixel (picture element) is treated as a separate unite. Statistics of Digital Images Help: • Look at the frequency of occurrence of individual brightness values in the image displayed • View individual pixel brightness values at specific locations or within a geographic area; • Compute univariate descriptive statistics to determine if there are unusual anomalies in the image data; and • Compute multivariate statistics to determine the amount of between-band correlation (e.g., to identify redundancy). 2 Statistics of Digital Images It is necessary to calculate fundamental univariate and multivariate statistics of the multispectral remote sensor data. This involves identification and calculation of – maximum and minimum value –the range, mean, standard deviation – between-band variance-covariance matrix – correlation matrix, and – frequencies of brightness values The results of the above can be used to produce histograms. Such statistics provide information necessary for processing and analyzing remote sensing data. A “population” is an infinite or finite set of elements. A “sample” is a subset of the elements taken from a population used to make inferences about certain characteristics of the population. (e.g., training signatures) 3 Large samples drawn randomly from natural populations usually produce a symmetrical frequency distribution. Most values are clustered around the central value, and the frequency of occurrence declines away from this central point. -

CORRELATION COEFFICIENTS Ice Cream and Crimedistribute Difficulty Scale ☺ ☺ (Moderately Hard)Or
5 COMPUTING CORRELATION COEFFICIENTS Ice Cream and Crimedistribute Difficulty Scale ☺ ☺ (moderately hard)or WHAT YOU WILLpost, LEARN IN THIS CHAPTER • Understanding what correlations are and how they work • Computing a simple correlation coefficient • Interpretingcopy, the value of the correlation coefficient • Understanding what other types of correlations exist and when they notshould be used Do WHAT ARE CORRELATIONS ALL ABOUT? Measures of central tendency and measures of variability are not the only descrip- tive statistics that we are interested in using to get a picture of what a set of scores 76 Copyright ©2020 by SAGE Publications, Inc. This work may not be reproduced or distributed in any form or by any means without express written permission of the publisher. Chapter 5 ■ Computing Correlation Coefficients 77 looks like. You have already learned that knowing the values of the one most repre- sentative score (central tendency) and a measure of spread or dispersion (variability) is critical for describing the characteristics of a distribution. However, sometimes we are as interested in the relationship between variables—or, to be more precise, how the value of one variable changes when the value of another variable changes. The way we express this interest is through the computation of a simple correlation coefficient. For example, what’s the relationship between age and strength? Income and years of education? Memory skills and amount of drug use? Your political attitudes and the attitudes of your parents? A correlation coefficient is a numerical index that reflects the relationship or asso- ciation between two variables. The value of this descriptive statistic ranges between −1.00 and +1.00. -

Covariance of Cross-Correlations: Towards Efficient Measures for Large-Scale Structure
View metadata, citation and similar papers at core.ac.uk brought to you by CORE provided by RERO DOC Digital Library Mon. Not. R. Astron. Soc. 400, 851–865 (2009) doi:10.1111/j.1365-2966.2009.15490.x Covariance of cross-correlations: towards efficient measures for large-scale structure Robert E. Smith Institute for Theoretical Physics, University of Zurich, Zurich CH 8037, Switzerland Accepted 2009 August 4. Received 2009 July 17; in original form 2009 June 13 ABSTRACT We study the covariance of the cross-power spectrum of different tracers for the large-scale structure. We develop the counts-in-cells framework for the multitracer approach, and use this to derive expressions for the full non-Gaussian covariance matrix. We show that for the usual autopower statistic, besides the off-diagonal covariance generated through gravitational mode- coupling, the discreteness of the tracers and their associated sampling distribution can generate strong off-diagonal covariance, and that this becomes the dominant source of covariance as spatial frequencies become larger than the fundamental mode of the survey volume. On comparison with the derived expressions for the cross-power covariance, we show that the off-diagonal terms can be suppressed, if one cross-correlates a high tracer-density sample with a low one. Taking the effective estimator efficiency to be proportional to the signal-to-noise ratio (S/N), we show that, to probe clustering as a function of physical properties of the sample, i.e. cluster mass or galaxy luminosity, the cross-power approach can outperform the autopower one by factors of a few.