Construct Validity and Reliability of the Work Environment Assessment Instrument WE-10
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

04 – Everything You Want to Know About Correlation but Were
EVERYTHING YOU WANT TO KNOW ABOUT CORRELATION BUT WERE AFRAID TO ASK F R E D K U O 1 MOTIVATION • Correlation as a source of confusion • Some of the confusion may arise from the literary use of the word to convey dependence as most people use “correlation” and “dependence” interchangeably • The word “correlation” is ubiquitous in cost/schedule risk analysis and yet there are a lot of misconception about it. • A better understanding of the meaning and derivation of correlation coefficient, and what it truly measures is beneficial for cost/schedule analysts. • Many times “true” correlation is not obtainable, as will be demonstrated in this presentation, what should the risk analyst do? • Is there any other measures of dependence other than correlation? • Concordance and Discordance • Co-monotonicity and Counter-monotonicity • Conditional Correlation etc. 2 CONTENTS • What is Correlation? • Correlation and dependence • Some examples • Defining and Estimating Correlation • How many data points for an accurate calculation? • The use and misuse of correlation • Some example • Correlation and Cost Estimate • How does correlation affect cost estimates? • Portfolio effect? • Correlation and Schedule Risk • How correlation affect schedule risks? • How Shall We Go From Here? • Some ideas for risk analysis 3 POPULARITY AND SHORTCOMINGS OF CORRELATION • Why Correlation Is Popular? • Correlation is a natural measure of dependence for a Multivariate Normal Distribution (MVN) and the so-called elliptical family of distributions • It is easy to calculate analytically; we only need to calculate covariance and variance to get correlation • Correlation and covariance are easy to manipulate under linear operations • Correlation Shortcomings • Variances of R.V. -

11. Correlation and Linear Regression
11. Correlation and linear regression The goal in this chapter is to introduce correlation and linear regression. These are the standard tools that statisticians rely on when analysing the relationship between continuous predictors and continuous outcomes. 11.1 Correlations In this section we’ll talk about how to describe the relationships between variables in the data. To do that, we want to talk mostly about the correlation between variables. But first, we need some data. 11.1.1 The data Table 11.1: Descriptive statistics for the parenthood data. variable min max mean median std. dev IQR Dan’s grumpiness 41 91 63.71 62 10.05 14 Dan’s hours slept 4.84 9.00 6.97 7.03 1.02 1.45 Dan’s son’s hours slept 3.25 12.07 8.05 7.95 2.07 3.21 ............................................................................................ Let’s turn to a topic close to every parent’s heart: sleep. The data set we’ll use is fictitious, but based on real events. Suppose I’m curious to find out how much my infant son’s sleeping habits affect my mood. Let’s say that I can rate my grumpiness very precisely, on a scale from 0 (not at all grumpy) to 100 (grumpy as a very, very grumpy old man or woman). And lets also assume that I’ve been measuring my grumpiness, my sleeping patterns and my son’s sleeping patterns for - 251 - quite some time now. Let’s say, for 100 days. And, being a nerd, I’ve saved the data as a file called parenthood.csv. -

Assessment Center Structure and Construct Validity: a New Hope
University of Central Florida STARS Electronic Theses and Dissertations, 2004-2019 2015 Assessment Center Structure and Construct Validity: A New Hope Christopher Wiese University of Central Florida Part of the Psychology Commons Find similar works at: https://stars.library.ucf.edu/etd University of Central Florida Libraries http://library.ucf.edu This Doctoral Dissertation (Open Access) is brought to you for free and open access by STARS. It has been accepted for inclusion in Electronic Theses and Dissertations, 2004-2019 by an authorized administrator of STARS. For more information, please contact [email protected]. STARS Citation Wiese, Christopher, "Assessment Center Structure and Construct Validity: A New Hope" (2015). Electronic Theses and Dissertations, 2004-2019. 733. https://stars.library.ucf.edu/etd/733 ASSESSMENT CENTER STRUCTURE AND CONSTRUCT VALIDITY: A NEW HOPE by CHRISTOPHER W. WIESE B.S., University of Central Florida, 2008 A dissertation submitted in partial fulfillment of the requirements for the degree of Doctor of Philosophy in the Department of Psychology in the College of Sciences at the University of Central Florida Orlando, Florida Summer Term 2015 Major Professor: Kimberly Smith-Jentsch © 2015 Christopher Wiese ii ABSTRACT Assessment Centers (ACs) are a fantastic method to measure behavioral indicators of job performance in multiple diverse scenarios. Based upon a thorough job analysis, ACs have traditionally demonstrated very strong content and criterion-related validity. However, researchers have been puzzled for over three decades with the lack of evidence concerning construct validity. ACs are designed to measure critical job dimensions throughout multiple situational exercises. However, research has consistently revealed that different behavioral ratings within these scenarios are more strongly related to one another (exercise effects) than the same dimension rating across scenarios (dimension effects). -
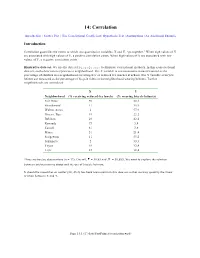
14: Correlation
14: Correlation Introduction | Scatter Plot | The Correlational Coefficient | Hypothesis Test | Assumptions | An Additional Example Introduction Correlation quantifies the extent to which two quantitative variables, X and Y, “go together.” When high values of X are associated with high values of Y, a positive correlation exists. When high values of X are associated with low values of Y, a negative correlation exists. Illustrative data set. We use the data set bicycle.sav to illustrate correlational methods. In this cross-sectional data set, each observation represents a neighborhood. The X variable is socioeconomic status measured as the percentage of children in a neighborhood receiving free or reduced-fee lunches at school. The Y variable is bicycle helmet use measured as the percentage of bicycle riders in the neighborhood wearing helmets. Twelve neighborhoods are considered: X Y Neighborhood (% receiving reduced-fee lunch) (% wearing bicycle helmets) Fair Oaks 50 22.1 Strandwood 11 35.9 Walnut Acres 2 57.9 Discov. Bay 19 22.2 Belshaw 26 42.4 Kennedy 73 5.8 Cassell 81 3.6 Miner 51 21.4 Sedgewick 11 55.2 Sakamoto 2 33.3 Toyon 19 32.4 Lietz 25 38.4 Three are twelve observations (n = 12). Overall, = 30.83 and = 30.883. We want to explore the relation between socioeconomic status and the use of bicycle helmets. It should be noted that an outlier (84, 46.6) has been removed from this data set so that we may quantify the linear relation between X and Y. Page 14.1 (C:\data\StatPrimer\correlation.wpd) Scatter Plot The first step is create a scatter plot of the data. -

CORRELATION COEFFICIENTS Ice Cream and Crimedistribute Difficulty Scale ☺ ☺ (Moderately Hard)Or
5 COMPUTING CORRELATION COEFFICIENTS Ice Cream and Crimedistribute Difficulty Scale ☺ ☺ (moderately hard)or WHAT YOU WILLpost, LEARN IN THIS CHAPTER • Understanding what correlations are and how they work • Computing a simple correlation coefficient • Interpretingcopy, the value of the correlation coefficient • Understanding what other types of correlations exist and when they notshould be used Do WHAT ARE CORRELATIONS ALL ABOUT? Measures of central tendency and measures of variability are not the only descrip- tive statistics that we are interested in using to get a picture of what a set of scores 76 Copyright ©2020 by SAGE Publications, Inc. This work may not be reproduced or distributed in any form or by any means without express written permission of the publisher. Chapter 5 ■ Computing Correlation Coefficients 77 looks like. You have already learned that knowing the values of the one most repre- sentative score (central tendency) and a measure of spread or dispersion (variability) is critical for describing the characteristics of a distribution. However, sometimes we are as interested in the relationship between variables—or, to be more precise, how the value of one variable changes when the value of another variable changes. The way we express this interest is through the computation of a simple correlation coefficient. For example, what’s the relationship between age and strength? Income and years of education? Memory skills and amount of drug use? Your political attitudes and the attitudes of your parents? A correlation coefficient is a numerical index that reflects the relationship or asso- ciation between two variables. The value of this descriptive statistic ranges between −1.00 and +1.00. -

Construct Validity in Psychological Tests
CONSTRUCT VALIDITY IN PSYCHOLOGICAL TF.STS - ----L. J. CRONBACH and P. E. MEEID..----- validity seems only to have stirred the muddy waters. Portions of the distinctions we shall discuss are implicit in Jenkins' paper, "Validity for 'What?" { 33), Gulliksen's "Intrinsic Validity" (27), Goo<lenough's dis tinction between tests as "signs" and "samples" (22), Cronbach's sepa· Construct Validity in Psychological Tests ration of "logical" and "empirical" validity ( 11 ), Guilford's "factorial validity" (25), and Mosier's papers on "face validity" and "validity gen eralization" ( 49, 50). Helen Peak ( 52) comes close to an explicit state ment of construct validity as we shall present it. VALIDATION of psychological tests has not yet been adequately concep· Four Types of Validation tua1ized, as the APA Committee on Psychological Tests learned when TI1e categories into which the Recommendations divide validity it undertook (1950-54) to specify what qualities should be investigated studies are: predictive validity, concurrent validity, content validity, and before a test is published. In order to make coherent recommendations constrnct validity. The first two of these may be considered together the Committee found it necessary to distinguish four types of validity, as criterion-oriented validation procedures. established by different types of research and requiring different interpre· TI1e pattern of a criterion-oriented study is familiar. The investigator tation. The chief innovation in the Committee's report was the term is primarily interested in some criterion which he wishes to predict. lie constmct validity.* This idea was first formulated hy a subcommittee administers the test, obtains an independent criterion measure on the {Meehl and R. -

Questionnaire Validity and Reliability
Questionnaire Validity and reliability Department of Social and Preventive Medicine, Faculty of Medicine Outlines Introduction What is validity and reliability? Types of validity and reliability. How do you measure them? Types of Sampling Methods Sample size calculation G-Power ( Power Analysis) Research • The systematic investigation into and study of materials and sources in order to establish facts and reach new conclusions • In the broadest sense of the word, the research includes gathering of data in order to generate information and establish the facts for the advancement of knowledge. ● Step I: Define the research problem ● Step 2: Developing a research plan & research Design ● Step 3: Define the Variables & Instrument (validity & Reliability) ● Step 4: Sampling & Collecting data ● Step 5: Analysing data ● Step 6: Presenting the findings A questionnaire is • A technique for collecting data in which a respondent provides answers to a series of questions. • The vehicle used to pose the questions that the researcher wants respondents to answer. • The validity of the results depends on the quality of these instruments. • Good questionnaires are difficult to construct; • Bad questionnaires are difficult to analyze. •Identify the goal of your questionnaire •What kind of information do you want to gather with your questionnaire? • What is your main objective? • Is a questionnaire the best way to go about collecting this information? Ch 11 6 How To Obtain Valid Information • Ask purposeful questions • Ask concrete questions • Use time periods -

Eight Things You Need to Know About Interpreting Correlations
Research Skills One, Correlation interpretation, Graham Hole v.1.0. Page 1 Eight things you need to know about interpreting correlations: A correlation coefficient is a single number that represents the degree of association between two sets of measurements. It ranges from +1 (perfect positive correlation) through 0 (no correlation at all) to -1 (perfect negative correlation). Correlations are easy to calculate, but their interpretation is fraught with difficulties because the apparent size of the correlation can be affected by so many different things. The following are some of the issues that you need to take into account when interpreting the results of a correlation test. 1. Correlation does not imply causality: This is the single most important thing to remember about correlations. If there is a strong correlation between two variables, it's easy to jump to the conclusion that one of the variables causes the change in the other. However this is not a valid conclusion. If you have two variables, X and Y, it might be that X causes Y; that Y causes X; or that a third factor, Z (or even a whole set of other factors) gives rise to the changes in both X and Y. For example, suppose there is a correlation between how many slices of pizza I eat (variable X), and how happy I am (variable Y). It might be that X causes Y - so that the more pizza slices I eat, the happier I become. But it might equally well be that Y causes X - the happier I am, the more pizza I eat. -

Chapter 11 -- Correlation
Contents 11 Association Between Variables 795 11.4 Correlation . 795 11.4.1 Introduction . 795 11.4.2 Correlation Coe±cient . 796 11.4.3 Pearson's r . 800 11.4.4 Test of Signi¯cance for r . 810 11.4.5 Correlation and Causation . 813 11.4.6 Spearman's rho . 819 11.4.7 Size of r for Various Types of Data . 828 794 Chapter 11 Association Between Variables 11.4 Correlation 11.4.1 Introduction The measures of association examined so far in this chapter are useful for describing the nature of association between two variables which are mea- sured at no more than the nominal scale of measurement. All of these measures, Á, C, Cramer's xV and ¸, can also be used to describe association between variables that are measured at the ordinal, interval or ratio level of measurement. But where variables are measured at these higher levels, it is preferable to employ measures of association which use the information contained in these higher levels of measurement. These higher level scales either rank values of the variable, or permit the researcher to measure the distance between values of the variable. The association between rankings of two variables, or the association of distances between values of the variable provides a more detailed idea of the nature of association between variables than do the measures examined so far in this chapter. While there are many measures of association for variables which are measured at the ordinal or higher level of measurement, correlation is the most commonly used approach. -

How to Create Scientifically Valid Social and Behavioral Measures on Gender Equality and Empowerment
April 2020 EMERGE MEASUREMENT GUIDELINES REPORT 2: How to Create Scientifically Valid Social and Behavioral Measures on Gender Equality and Empowerment BACKGROUND ON THE EMERGE PROJECT EMERGE (Evidence-based Measures of Empowerment for Research on Box 1. Defining Gender Equality and Gender Equality), created by the Center on Gender Equity and Health at UC San Diego, is a project focused on the quantitative measurement of gender Empowerment (GE/E) equality and empowerment (GE/E) to monitor and/or evaluate health and Gender equality is a form of social development programs, and national or subnational progress on UN equality in which one’s rights, Sustainable Development Goal (SDG) 5: Achieve Gender Equality and responsibilities, and opportunities are Empower All Girls. For the EMERGE project, we aim to identify, adapt, and not affected by gender considerations. develop reliable and valid quantitative social and behavioral measures of Gender empowerment is a type of social GE/E based on established principles and methodologies of measurement, empowerment geared at improving one’s autonomy and self-determination with a focus on 9 dimensions of GE/E- psychological, social, economic, legal, 1 political, health, household and intra-familial, environment and sustainability, within a particular culture or context. and time use/time poverty.1 Social and behavioral measures across these dimensions largely come from the fields of public health, psychology, economics, political science, and sociology. OBJECTIVE OF THIS REPORT The objective of this report is to provide guidance on the creation and psychometric testing of GE/E scales. There are many good GE/E measures, and we highly recommend using previously validated measures when possible. -

Reliability & Validity
Another bit of jargon… Reliability & Validity In sampling… In measurement… • More is Better We are trying to represent a We are trying to represent a • Properties of a “good measure” population of individuals domain of behaviors – Standardization – Reliability – Validity • Reliability We select participants We select items – Inter-rater – Internal – External • Validity The resulting sample of The resulting scale/test of – Criterion-related participants is intended to items is intended to –Face – Content represent the population represent the domain – Construct For both “more is better” “more give greater representation” Whenever we’ve considered research designs and statistical conclusions, we’ve always been concerned with “sample size” We know that larger samples (more participants) leads to ... • more reliable estimates of mean and std, r, F & X2 • more reliable statistical conclusions • quantified as fewer Type I and II errors The same principle applies to scale construction - “more is better” • but now it applies to the number of items comprising the scale • more (good) items leads to a better scale… • more adequately represent the content/construct domain • provide a more consistent total score (respondent can change more items before total is changed much) Desirable Properties of Psychological Measures Reliability (Agreement or Consistency) Interpretability of Individual and Group Scores Inter-rater or Inter-observers reliability • do multiple observers/coders score an item the same way ? • critical whenever using subjective measures -

Alternatives to Pearson's and Spearman's Correlation Coefficients
Alternatives To Pearson’s and Spearman’s Correlation Coefficients Florentin Smarandache Chair of Math & Sciences Department University of New Mexico Gallup, NM 87301, USA Abstract. This article presents several alternatives to Pearson’s correlation coefficient and many examples. In the samples where the rank in a discrete variable counts more than the variable values, the mixture of Pearson’s and Spearman’s gives a better result. Introduction Let’s consider a bivariate sample, which consists of n ≥ 2 pairs (x,y). We denote these pairs by: (x1, y1), (x2, y2), … , (xn,yn), where xi = the value of x for the i-th observation, and yi = the value of y for the i-th observation, for any 1 < i < n. We can construct a scatter plot in order to detect any relationship between variables x and y, drawing a horizontal x-axis and a vertical y-axis, and plotting points of coordinates (xi, yi) for all i ∈{1, 2, …, n}. We use the standard statistics notations, mostly used in regression analysis: n n n ∑ x = ∑ xi , ∑∑y = yi , ∑∑xyxy= ()ii , i=1 i=1 i=1 n n 2 2 2 2 ∑ x = ∑ xi , ∑ y = ∑ yi , (1) i=1 i=1 n ∑ xi X = i=1 = the mean of sample variable x, n n ∑ yi Y = i=1 = the mean of sample variable y. n Let’s introduce a notation for the median: XM = the median of sample variable x, (2) YM = the median of sample variable y. Correlation Coefficients. Correlation coefficient of variables x and y shows how strongly the values of these variables are related to one another.