Pre-Print the Graphical Representation
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Teaching the Art of Poetry Using Dialect in Your Poems
TEACHING THE ART OF POETRY USING DIALECT IN YOUR POEMS by Liz Berry hinny … glinder … jinnyspins … dayclean1 Choosing to write poems using dialect is like finding a locked box full of treasure. You know there’s all sorts of magical things inside, you just have to find the key that will let you in. So put down your notebook, close your laptop, and start listening to the voices around you. For this is the way in, the place where the strongest dialect poetry starts: a voice you can hear. That’s how writing in Black Country dialect started for me - by listening to the voices of the area I’d grown up in. The Black Country dialect has long been mocked as guttural and middle-earthy but to me it’s beautiful because the people I love best have spoken it. None of them are poets but to me their language is the stuff of poetry. I started listening more carefully, rooting around in the past. It was like digging up my own Staffordshire Hoard; a field full of spectacular words, sounds and phrases glinting out of the muck. I was inspired by other poets who’d written using dialect. The brilliant Faber Book of Vernacular Verse edited by Tom Paulin presents a wonderful alternative poetic tradition. It praises the 'springy, irreverent, chanting, often tender and intimate, vernacular voice … which speaks for an alternative community that is mostly powerless and invisible'. Contemporary poets like Kathleen Jamie, Daljit Nagra and Jen Hadfield continue the tradition in fresh and irresistible ways. Reading their work you’re bowled over by the fizz and charm of dialect and how poetry can be a powerful way of protecting and celebrating the spoken language of regions and communities. -
Issue Number and Month Tip of the Month Clearly Clarified General
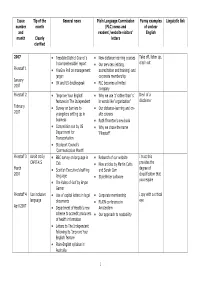
Issue Tip of the General news Plain Language Commission Funny examples Linguistic link number month (PLC) news and of unclear and readers’/website visitors’ English month Clearly letters clarified 2007 • Teesdale District Council’s • New distance-learning courses Take off, listen up, ‘incomprehensible’ report • Our services (editing, crash out Pikestaff 1 • YouGov Poll on management accreditation and training) and jargon corporate membership January • UK and US doublespeak • PLC becomes a limited 2007 company Pikestaff 2 • ‘Improve Your English’ • Why we use ‘z’ rather than ‘s’ Devil of a features in The Independent in words like ‘organization’ disclaimer February • Survey on barriers to • Our distance-learning and on- 2007 youngsters setting up in site courses business • Ruth Thornton’s new book • Competition run by US • Why we chose the name Department for ‘Pikestaff’ Transportation • Stockport Council’s ‘Communication Month’ Pikestaff 3 AVoid craZy • BBC survey on language in • Relaunch of our website I trust this CAPITALS CVs • New articles by Martin Cutts provides the March • Scottish Executive’s baffling and Sarah Carr degree of 2007 cloudification that language • StyleWriter software you require • The Rules of Golf by Bryan Garner Pikestaff 4 Use inclusive • Use of capital letters in legal • Corporate membership I spy with a critical language documents • PLAIN conference in eye April 2007 • Department of Health’s new Amsterdam scheme to accredit producers • Our approach to readability of health information • Letters to The Independent -

Investigating Residual Rhoticity in a Non-Rhotic Accent
INVESTIGATING RESIDUAL RHOTICITY IN A NON-RHOTIC ACCENT Esther Asprey Abstract This paper reports on preliminary findings of a study conducted in the Black Country area of the west midlands of England. The small number of linguistic studies carried out in this region in the last 40 years have not found evidence of the continuing existence of variable rhoticity in the local speech variety. The Survey of English Dialects in the 1950s found low levels of rhoticity among speakers in the location closest to the Black Country, and I examine here similar findings from a detailed study of the variety, carried out between 2003-2006. 1 1. The Black Country region: an overview The Black Country lies to the immediate west of the city of Birmingham: its eastern border adjoins that city. Figure 1 shows its location within the UK. The region is unusual in that it is not an area delimited by political, physical or economic boundaries, nor, unlike some areas with names unconnected to physical or political regions, does it have criteria for being a resident like that of, for example, being born within the sound of Bow Bells for Cockneys. Since the first known written use of the name ‘Black Country’ by Walter White in 1860, residents have been disputing amongst themselves exactly where its boundaries lie. The name ‘Black Country’ is generally acknowledged to stem from the pollution created in the Industrial Revolution. Modern day historians have put forward several definitions of the area’s boundaries. Their theories can be categorised under two main headings: those using the iron industry to define the area, and those using the South Staffordshire coalfield to do so. -

Regional Varieties, Language Shift and Linguistic Identities Programme
Regional Varieties, language shift and linguistic identities Programme Wednesday, 12th September 4.00– 5.30pm: Registration 5.30 – 6.00: Welcome by the conference organizers 6 .00 – 7.00: Yaron Matras (University of Manchester) The afterlife of a language: The journey of English Romani from community language to a discourse register 7 pm: Reception Thursday, 13th September 8.30 – 9.30: Registration 9.30 – 10.00: Welcome by the Executive Dean 10.00 – 11.00: Joan Beal (University of Sheffield) Inc: the commodification of languages in the ‘new economy’ 11.00 – 11.30: COFFEE 11.30 – 13.00 Papers Eline Zenner, Dirk Speelman & Carmen Maria Faggion Natalie Braber (Nottingham Trent Dirk Geeraerts (FWO Flanders, (Universidade de Caxias do Sul) University) Diane Davies University of Leuven) Regional Regional varieties in southern (University of Leicester) Charting variation in the use of English as an Brazil: first names modified language change and identity in the identity-marker in two varieties of through contact between an Italian East Midlands. Dutch. dialect and Portuguese. Maya Zara (Edge Hill University) Márcia Cristina do Carmo Lyndon Higgs (University of The role of the retroflex in identity (Universidade Estadual Paulista) Strasbourg) The Black Country construction – a purposeful The variable phonological dialect: solidarity, respect and feature? behaviour of the pretonic mid- disrespect expressed through a dual vowels in Paulista Portuguese. pronoun system. Stefania Marzo (KU Leuven) Evy Virginia Zavala & Roberto Urszula Clark & Team (Aston Ceuleers (University College Brañez (Pontificia Universidad University) “Tings a gwan”: Ghent/Ghent Univerty) The hybrid Católica del Perú) Language Linguistic superdiversity in indexical meaning of multilingual alternation in an affinity space: contemporary minority ethnic varieties: a perceptual approach. -

Notes Towards the Insertion of Black Dada
MARK BEASLEY Motherfist and her five glossaries: Notes towards the insertion of Black Dada — Black Dada is a way to talk about the future while talking about the past. It is our present moment. The Black Dada must use irrational language. The Black Dada must exploit the logic of identity. Black Dada is neither madness, nor wisdom, nor irony, nor naiveté. Black Dada: we are successive. Black Dada: we are not exclusive. Black Dada: we abhor simpletons and are perfectly capable of an intelligent discussion. The Black Dada’s manifesto is both form and life. Black Dada your history of art. Adam PENDLETON, ‘BLACK Dada MANIFesto’, 2008 By removing all semantic and normative functions of the word the Dada poets released language from its obligation to merely communicate. That is to say, through the rupture of speech, they reordered the code: they made the familiar strange. To what end? Corresponding with the outbreak of the First World War, it was an attempt on the part of the few—Hugo Ball, Emmy Hennings, Tristan Tzara, Jean Arp, Marcel Janco, Richard Huelsenbeck, and Sophie Täuber—to address the acts of the many. Deploring the ‘common sense’ 1 that had led Europe into blood- shed, Dada was for contrary action and contradiction. It was a gibbering, critical response to the brutality of the Somme and Verdun. As such, nonsense became a home for sagacity in the face of senselessness. Choosing the heterogeneous, the frustrating and disruptive above clarity, they created new glossaries and new dialects. In short, there is always a point to be made in nonsense—a point thoroughly explored by Kant—it too has its logic. -

Variation, Linguistic Hegemony and the Teaching of Literacy in English
English Teaching: Practice and Critique September, 2013, Volume 12, Number 2 http://education.waikato.ac.nz/research/files/etpc/files/2013v12n2art4.pdf pp. 58-75 A sense of place: Variation, linguistic hegemony and the teaching of literacy in English URSZULA CLARK English, School of Languages and Social Sciences, Aston University, Birmingham, UK ABSTRACT: The ways in which literacy in English is taught in school generally subscribe to and perpetuate the notion of a homogenous, unvaried set of writing conventions associated with the language they represent, especially in relation to spelling and punctuation as well as grammar. Such teaching also perpetuates the myth that there is one “correct” way of language use which is “fixed” and invariant, and that any deviation is at best “incorrect” or “illiterate” and at worst, a threat to social stability. It is also very clear that the linguistic norms associated with standard English are predicated upon and replicate white, cultural hegemony. Yet, at the same time, there are plenty of literary and creative works written by authors from all kinds of different cultural, ethnic and linguistic backgrounds, including canonical ones, where spelling and punctuation are varied and championed as a sign of creativity. In the world beyond school, pupils are also surrounded by variational use of written language, especially in public displays such as shop signs, writing on mugs and t-shirts, posters, graffiti and so on, which link language to place. Equally, the voices we hear in entertainment and public broadcasting, far from being homogenous, celebrate diversity in Englishes. The homes and backgrounds of pupils in our schools, including their linguistic backgrounds, may also be very different either in terms of a different variation of English or languages spoken other than English. -

Black Country Echoes Publication
BLACK COUNTRY ECHOES: PEOPLE | LANDSCAPE | INDUSTRY | ART A souvenir of the Black Country Echoes Festival 2014 CONTENTS New Chapters in a Centuries-old Story by Paul Quigley 3 A World that Someone Else Owns… by Brendan Jackson 6 Innovation for Survival in a Shifting Landscape: The Story of Rubery Owen by David Owen OBE 10 Goodnight Irene - Poem by Liz Berry 13 Wulfrun Hotel - Poem by Liz Berry 13 Women at Work… Thomas Trevis Smith Ltd Cooperage, Cradley Heath by Heather Wastie 14 Birmingham and The Black Country by Dr Chris Upton 16 In the Shadow of Elisabeth by Greig Campbell 19 Cover illustrations (left to right) Learning the Game by Dr Brian Dakin 23 Top row Year Zero: Black Country by Billy Dosanjh 27 Exterior of George Dyke Ltd Forgemasters, Darlaston. Watercolour by Arthur Lockwood. © Arthur Lockwood Workers at Unigate Dairies, Wolverhampton, 1976-8. © Nick Hedges In His Element - Poem by Dave Reeves 30 British Glass Biennale/ International Festival of Glass, Stourbridge, 2012 © John Plant Chance Brothers Glass Works, circa 1958-63, part of the Jubilee Arts Archive The Enduring Success of Stourbridge Glass by Natasha George 31 2nd row The Extraordinary Ordinary – in Everyday Photographs of The Black Country by Dr Peter Day 36 Picket line, Supreme Quiltings and Raindi Textiles, Smethwick, 1982. © Jubilee Arts Archive Settle - Poem by Dave Reeves 40 3rd row Images of Charleroi by British Glass Biennale/ International Festival of Glass, Stourbridge, 2012 © John Plant Xavier Canonne 41 Black Country photograph by Peter Donnelly. © Simon Donnelly Gaggia (Down the caff-ay) - Poem by Dave Reeves 45 Friar Park, Wednesbury, 1977/8. -

Flamingos in Dudley Zoo’ by Emma Purshouse
This is a peer-reviewed, post-print (final draft post-refereeing) version of the following published document and is licensed under Creative Commons: Attribution-Noncommercial-No Derivative Works 4.0 license: McLoughlin, Nigel F ORCID: 0000-0002-0382-6831 (2020) Text- worlds, blending, and allegory in ‘Flamingos in Dudley Zoo’ by Emma Purshouse. Language and Literature, 29 (4). pp. 389- 403. doi:10.1177/0963947020968664 Official URL: https://doi.org/10.1177/0963947020968664 DOI: http://dx.doi.org/10.1177/0963947020968664 EPrint URI: http://eprints.glos.ac.uk/id/eprint/8913 Disclaimer The University of Gloucestershire has obtained warranties from all depositors as to their title in the material deposited and as to their right to deposit such material. The University of Gloucestershire makes no representation or warranties of commercial utility, title, or fitness for a particular purpose or any other warranty, express or implied in respect of any material deposited. The University of Gloucestershire makes no representation that the use of the materials will not infringe any patent, copyright, trademark or other property or proprietary rights. The University of Gloucestershire accepts no liability for any infringement of intellectual property rights in any material deposited but will remove such material from public view pending investigation in the event of an allegation of any such infringement. PLEASE SCROLL DOWN FOR TEXT. Text-Worlds, Blending, and Allegory in ‘Flamingos in Dudley Zoo’ by Emma Purshouse Nigel McLoughlin University of Gloucestershire, UK Abstract This paper will develop a cognitive stylistic framework drawn from Conceptual Integration (Blending) Theory (Fauconnier and Turner 2002), and Text World Theory (Werth 1999; Gavins 2007), which uses the idea of elaboration sites (Langacker 2009) as potential structural enablers in mapping across blend spaces. -

The Graphical Representation of Phonological Dialect Features of the North of England on Social Media
Nini, A., Bailey, G., Guo, D., Grieve, J. (2020) The graphical representation of phonological dialect features of the North of England on social media. In Honeybone, P. & Maguire, W. (eds), Dialect Writing and the North of England, 266-296, Edinburgh: Edinburgh University Press The graphical representation of phonological dialect features of the North of England on social media Nini, A., Bailey, G., Guo, D., Grieve, J. 12.1. Introduction This chapter offers a complementary perspective to the subject of the book by looking at social media and on whether and how the graphological reflection of dialect writing is affecting these new forms of communication. By foregrounding the importance of the ways in which speakers construct and project personae (Eckert, 2012), third wave theoretical approaches to the study of linguistic variation would predict that users can break orthographic conventions in order to encode their dialect and linguistic identity on social media. However, the extent to which users of social media use spelling resources to convey dialectal identities and to what purposes is not immediately obvious and one of the objectives of this chapter is to shed light on this phenomenon both quantitatively and qualitatively. Recent research on dialect variation using social media data has so far provided evidence that spelling variants that reflect phonetic dialect s are found in social media posts, such as tweets. This is an important finding because it opens the possibility of analysing the dialect of a region using naturally occurring social media posts as opposed to using interviews or questionnaires. In addition, if users do adopt dialectal spelling variants in their social media communications, it is not clear whether their geographical patterning would match their respective phonetic forms. -

The Evolution of English Dental Fricatives: Variation and Change
Mateusz Jekiel The evolution of English dental fricatives: variation and change Praca magisterska napisana w Instytucie Filologii Angielskiej Uniwersytetu im. Adama Mickiewicza pod kierunkiem prof. dr hab. Piotra G ąsiorowskiego Pozna ń, 2012 Imi ę i nazwisko ............................................................................................................................ Kierunek i specjalno ść ................................................................................................................. Numer albumu ............................................................................................................................. Instytut Filologii Angielskiej Promotor ...................................................................................................................................... 1. Oryginalny tytuł pracy dyplomowej ..................................................................................................................................................... ..................................................................................................................................................... ..................................................................................................................................................... 2. Tłumaczenie tytułu pracy dyplomowej a) na j ęzyk polski (w przypadku prac napisanych w j ęzyku obcym) .................................................................................................................................................... -

BBC Voices Recordings: Dudley, West Midlands
BBC VOICES RECORDINGS http://sounds.bl.uk Title: Dudley, West Midlands Shelfmark: C1190/05/02 Recording date: 27.02.2005 Speakers: Dakin, Brian, b. 1952 Oldbury; male; retail manager (father b. Oldbury, steelworker; mother b. Oldbury) Hawthorn, Brendan, b. 1961 Tipton; male; museum assistant (father b. Great Bridge, manager; mother b. Tipton, print room office worker) O'Dea, Gary, b. 1962 Tipton; male; university administrator (father b. Tipton, steelworker; mother b. Tipton) Stokes, Greg, b. 1955 Dudley; male; clinical chemist (father b. Dudley, butcher’s clerk; mother b. Leicestershire, comptometer operator) All four interviewees are friends proud of their Black Country roots. ELICITED LEXIS ○ see English Dialect Dictionary (1898-1905) * see Survey of English Dialects Basic Material (1962-1971) ▼see Ey Up Mi Duck! Dialect of Derbyshire and the East Midlands (2000) ■ see The Black Country Dialect (2007) ∆ see New Partridge Dictionary of Slang and Unconventional English (2006) « see Roger’s Profanisaurus: The Magna Farta (2007) ◊ see Green’s Dictionary of Slang (2010) ♦ see Urban Dictionary (online) ⌂ no previous source (with this sense) identified pleased happy as a pig in muck◊ (used frequently); chuffed; nice one, good one, good ’un, nice ’un (used as term of approval) tired dog-tired; knackered, shattered (most common); bolloxed♦; tuckered out (“I’m plain tuckered out” used frequently when young) unwell poorly; on the box1 (used locally for ‘on sick leave’); ailing hot boiling cold freezing; froz*; froze; fruz* to death; brass monkeyed◊ 1 ‘Ow We Spake: Black Country Dialect’ (http://www.sedgleymanor.com/dictionaries/dialect.html) includes ‘on the box’ in this sense. -

Investigating Residual Rhoticity in a Non-Rhotic Accent
Manuscript version: Working paper (or pre-print) The version presented here is a Working Paper (or ‘pre-print’) that may be later published elsewhere. Persistent WRAP URL: http://wrap.warwick.ac.uk/138235 How to cite: Please refer to the repository item page, detailed above, for the most recent bibliographic citation information. If a published version is known of, the repository item page linked to above, will contain details on accessing it. Copyright and reuse: The Warwick Research Archive Portal (WRAP) makes this work by researchers of the University of Warwick available open access under the following conditions. Copyright © and all moral rights to the version of the paper presented here belong to the individual author(s) and/or other copyright owners. To the extent reasonable and practicable the material made available in WRAP has been checked for eligibility before being made available. Copies of full items can be used for personal research or study, educational, or not-for-profit purposes without prior permission or charge. Provided that the authors, title and full bibliographic details are credited, a hyperlink and/or URL is given for the original metadata page and the content is not changed in any way. Publisher’s statement: Please refer to the repository item page, publisher’s statement section, for further information. For more information, please contact the WRAP Team at: [email protected]. warwick.ac.uk/lib-publications INVESTIGATING RESIDUAL RHOTICITY IN A NON-RHOTIC ACCENT Esther Asprey Abstract This paper reports on preliminary findings of a study conducted in the Black Country area of the west midlands of England.