Identifying Street-Character-Weighted Local Area Using Locally Weighted Community Detection Methods
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Transvaalbuurt (Amsterdam) - Wikipedia
Transvaalbuurt (Amsterdam) - Wikipedia http://nl.wikipedia.org/wiki/Transvaalbuurt_(Amsterdam) 52° 21' 14" N 4° 55' 11"Archief E Philip Staal (http://toolserver.org/~geohack Transvaalbuurt (Amsterdam)/geohack.php?language=nl& params=52_21_14.19_N_4_55_11.49_E_scale:6250_type:landmark_region:NL& pagename=Transvaalbuurt_(Amsterdam)) Uit Wikipedia, de vrije encyclopedie De Transvaalbuurt is een buurt van het stadsdeel Oost van de Transvaalbuurt gemeente Amsterdam, onderdeel van de stad Amsterdam in de Nederlandse provincie Noord-Holland. De buurt ligt tussen de Wijk van Amsterdam Transvaalkade in het zuiden, de Wibautstraat in het westen, de spoorlijn tussen Amstelstation en Muiderpoortstation in het noorden en de Linnaeusstraat in het oosten. De buurt heeft een oppervlakte van 38 hectare, telt 4500 woningen en heeft bijna 10.000 inwoners.[1] Inhoud Kerngegevens 1 Oorsprong Gemeente Amsterdam 2 Naam Stadsdeel Oost 3 Statistiek Oppervlakte 38 ha 4 Bronnen Inwoners 10.000 5 Noten Oorsprong De Transvaalbuurt is in de jaren '10 en '20 van de 20e eeuw gebouwd als stadsuitbreidingswijk. Architect Berlage ontwierp het stratenplan: kromme en rechte straten afgewisseld met pleinen en plantsoenen. Veel van de arbeiderswoningen werden gebouwd in de stijl van de Amsterdamse School. Dit maakt dat dat deel van de buurt een eigen waarde heeft, met bijzondere hoekjes en mooie afwerkingen. Nadeel van deze bouw is dat een groot deel van de woningen relatief klein is. Aan de basis van de Transvaalbuurt stonden enkele woningbouwverenigingen, die er huizenblokken -
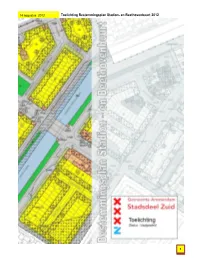
Toelichting 2012 07 24 GECON
14 augustus 2012 Toelichting Bestemmingsplan Stadion- en Beethovenbuurt 2012 1 14 augustus 2012 Toelichting Bestemmingsplan Stadion- en Beethovenbuurt 2012 Inhoudsopgave Hoofdstuk 1 Inleiding .................................................................................................................. 3 1.1 Aanleiding ...................................................................................................................... 3 1.2 Ligging en beschrijving plangebied ................................................................................ 4 1.3 Plangrenzen................................................................................................................... 4 1.4 Leeswijzer...................................................................................................................... 5 Hoofdstuk 2 Beschrijving plangebied........................................................................................ 6 2.1 Ontstaansgeschiedenis.................................................................................................. 6 2.2 Stedenbouwkundige structuur........................................................................................ 7 2.3 Functionele structuur ................................................................................................... 10 Hoofdstuk 3 Ontwikkelingsvisie en planbeschrijving ............................................................ 15 3.1 Inleiding ...................................................................................................................... -

Gebiedsplan 2016 Oud-Zuid
Gebiedsplan 2017 Oud-Zuid In dit gebiedsplan leest u wat de belangrijkste thema’s zijn in Oud-Zuid en wat de gemeente samen met bewoners, ondernemers en instellingen in 2017 per thema gaat doen. Inhoud Inleiding Prioriteit 1: Beter benutten van de kansen ten aanzien van economie, cultuur, sport en prettige woonomgeving Prioriteit 2: Meer mensen leven zo zelfstandig mogelijk Prioriteit 3: Veiligere en aantrekkelijkere verkeersroutes voor fietsers en voetgangers Prioriteit 4: Meer weerbaarheid van jongeren ten aanzien van alcohol- en drugsgebruik Prioriteit 5: Hogere kwaliteit van Museumplein en Vondelpark, passend bij het toenemende gebruik van de openbare ruimte Bijlagen Focuspuntenkaart Contactgegevens gebiedsteam Overzicht participatieactiviteiten 1 Inleiding Kenmerken van het gebied Gebied Oud-Zuid maakt samen met de gebieden De Pijp/Rivierenbuurt en Zuidas/Buitenveldert deel uit van stadsdeel Zuid. Oud-Zuid omvat zowel welgestelde woonbuurten – zoals de Apollobuurt, de Willemsparkbuurt en het Museumkwartier – als gemengde wijken: de Hoofddorpplein-, de Marathon-, de Schinkel- en de Stadionbuurt. Oud-Zuid is een gebied met relatief veel hoogopgeleide en actieve bewoners. Het Museumkwartier en de Willemsparkbuurt zijn van oudsher kinderrijk. In de Hoofddorppleinbuurt is het aantal kinderen en gezinnen de laatste jaren toegenomen. De Apollobuurt en het Museumkwartier tellen relatief veel ouderen. Oud-Zuid beschikt over veel basisscholen en scholen voor voortgezet onderwijs. Een derde van alle Amsterdamse middelbare scholieren gaat in Zuid naar school. De bewoners van Zuid voelen zich over het algemeen prettig in hun buurt Het is een gebied met goede voorzieningen en een winkel- en horeca- aanbod dat aantrekkelijk is voor zowel de bewoners zelf als voor bezoekers uit binnen- en buitenland. -

Leefbaarheid En Veiligheid De Leefbaarheid En Veiligheid Van De Woonomgeving Heeft Invloed Op Hoe Amsterdammers Zich Voelen in De Stad
13 Leefbaarheid en veiligheid De leefbaarheid en veiligheid van de woonomgeving heeft invloed op hoe Amsterdammers zich voelen in de stad. De mate waarin buurtgenoten met elkaar contact hebben en de manier waarop zij met elkaar omgaan zijn daarbij van belang. Dit hoofdstuk gaat over de leefbaar- heid, sociale cohesie en veiligheid in de stad. Auteurs: Hester Booi, Laura de Graaff, Anne Huijzer, Sara de Wilde, Harry Smeets, Nathalie Bosman & Laurie Dalmaijer 150 De Staat van de Stad Amsterdam X Kernpunten Leefbaarheid op te laten groeien. Dat is het laagste Veiligheid ■ De waardering voor de eigen buurt cijfer van de Metropoolregio Amster- ■ Volgens de veiligheidsindex is Amster- is stabiel en goed. Gemiddeld geven dam. dam veiliger geworden sinds 2014. Amsterdammers een 7,5 als rapport- ■ De tevredenheid met het aanbod aan ■ Burgwallen-Nieuwe Zijde en Burgwal- cijfer voor tevredenheid met de buurt. winkels voor dagelijkse boodschap- len-Oude Zijde zijn de meest onveilige ■ In Centrum neemt de tevredenheid pen in de buurt is toegenomen en buurten volgens de veiligheidsindex. met de buurt af. Rond een kwart krijgt gemiddeld een 7,6 in de stad. ■ Er zijn minder misdrijven gepleegd in van de bewoners van Centrum vindt Alleen in Centrum is men hier minder Amsterdam (ruim 80.000 bij de politie dat de buurt in het afgelopen jaar is tevreden over geworden. geregistreerde misdrijven in 2018, achteruitgegaan. ■ In de afgelopen tien jaar hebben –15% t.o.v. 2015). Het aantal over- ■ Amsterdammers zijn door de jaren steeds meer Amsterdammers zich vallen neemt wel toe. heen positiever geworden over het ingezet voor een onderwerp dat ■ Slachtofferschap van vandalisme komt uiterlijk van hun buurt. -

Fact Sheet Leefbaarheidsindex Periode 2010-2012
Fact sheet Leefbaarheidsindex Periode 2010-2012 nummer 3 | februari 2013 Deze fact sheet gaat in op de leefbaarheid van buurten in Amsterdam. Ontwikkelingen vanaf 2010 komen aan de orde, met specifieke aandacht voor de verandering tussen 2011 en 2012. De leefbaarheid in Amsterdam is tussen 2010 en 2012 licht verbeterd. Tussen 2011 en 2012 is de leefbaarheid op vergelijkbaar niveau gebleven. Bewoners in de stadsdelen Centrum, Nieuw-West en Noord beoordelen in 2012 de leefbaarheid het slechtste. Bewoners van Zuid en Zuidoost beoordelen de leefbaarheid juist beter dan gemiddeld het geval is. Een openbare ruimte die schoon, heel en veilig is hun buurt ervaren, oftewel het gaat om een draagt bij aan het verminderen van gevoelens van subjectieve index. onveiligheid. Om deze reden is in het Programakkoord Amsterdam 2010-2014 opge- Het bronjaar van de leefbaarheidsindex is 2010 nomen dat de leefbaarheid van Amsterdamse (oftewel de index is in 2010 op 100 gezet). De buurten gemonitord moet worden met een scores op de 24 verschillende indicatoren zijn leefbaarheidsindex. Op verzoek van de direc- per indicator geïndexeerd door te delen door tie Openbare Orde en Veiligheid (OOV) van de de gemiddelde waarde in 2010.1 De indexcijfers gemeente Amsterdam heeft O+S deze leefbaar- worden per buurt gepresenteerd met toevoe- heidsindex ontworpen. De leefbaarheidsindex ging van de kleuren rood, oranje, lichtgroen en bestaat uit drie deelindexen, die elk uit acht donkergroen. Deze kleuren laten zien hoe de indicatoren bestaan (zie tabel 1). De indicatoren leefbaarheid van de buurt zich verhoudt tot de komen uit de Veiligheidsmonitor Amsterdam- gemiddelde buurt in Amsterdam in 2010. -

Neighbourhood Liveability and Active Modes of Transport the City of Amsterdam
Neighbourhood Liveability and Active modes of transport The city of Amsterdam ___________________________________________________________________________ Yael Federman s4786661 Master thesis European Spatial and Environmental Planning (ESEP) Nijmegen school of management Thesis supervisor: Professor Karel Martens Second reader: Dr. Peraphan Jittrapiro Radboud University Nijmegen, March 2018 i List of Tables ........................................................................................................................................... ii Acknowledgment .................................................................................................................................... ii Abstract ................................................................................................................................................... 1 1. Introduction .................................................................................................................................... 2 1.1. Liveability, cycling and walking .............................................................................................. 2 1.2. Research aim and research question ..................................................................................... 3 1.3. Scientific and social relevance ............................................................................................... 4 2. Theoretical background ................................................................................................................. 5 2.1. -

Lau Peters, Architect
Lau Peters, Architect Local Heroes #18 The architects who benefit us most may be those generous enough to lay aside their claims to genius in order to devote themselves to assembling graceful but predominantly unoriginal boxes. Lau Peters - Alain de Botton, The Architecture of Happiness (1900-1969) Architect Although you may have walked past his work in Amsterdam, City: Lau Peters remains an unknown architect, due to how Amsterdam seamlessly his buildings blend into their surrounding neighbourhoods. His most prominent project is perhaps the Author: collection of buildings that form the Sint-Nicolaas complex, Menora Tse which has been the subject of recent discussion regarding their June 2020 further adaptation. Photography Early Life City Archives, Amsterdam Het Nieuwe Instituut, Rotterdam Laurentius Theodorus Franciscus Peters was born in Amsterdam Menora Tse in 1900. His father, Johannes Peters (1867-1949) was a Jan Peter Wingender zelfbouwer, an independent carpenter who worked for small construction companies. The influence of his practical hands-on Lau Peters, March 27 1931 approach formed the foundation for Lau Peters’ professional development. Coming from a working class family, his pursuit of the architectural vocation was unusual and yet, in many ways he did not follow the traditional trajectory of his contemporaries. Unlike other aspiring architects, Lau did not follow the mainstream curriculum offered at the Delft University of Technology. Instead, he was educated at a technical school. After completing his HBS (Dutch Higher Civic School), Lau studied architecture as his MTS subject (Secondary Technical School) in Utrecht. He first started to work as an architectural draftsman with Amsterdam architect Rijnja while completing evening courses in architecture. -

Sociaal Vertrouwen in De Marathonbuurt
Sociaal vertrouwen in de Marathonbuurt Resultaten bewonersenquête Ron van Wonderen Hans Boutellier Oktober 2007 Inhoud Leesvervangende samenvatting 5 1 Uitvoering onderzoek in de Marathonbuurt 15 1.1 Onderzoekspopulatie 16 1.2 Resultaten polarisatie en vertrouwen (afzonderlijke items) 16 1.3 Resultaten risico- en beschermingsfactoren 20 2 Vier buurten in Oud-Zuid vergeleken 29 2.1 Introductie 29 2.2 Risicofactoren (schalen) 32 2.3 Trends 42 2.4 Meest saillante risico- en beschermingsfactoren 47 Bijlage 1: Resultaten bewonersenquête 53 Bijlage 2: Open antwoorden/suggesties bewoners 63 Bijlage 3: Samenvatting groepsgesprek bewoners 65 Bijlage 4: Vragenlijst bewonersenquête 68 3 4 Verwey-Jonker Instituut Leesvervangende samenvatting Sociaal vertrouwen en polarisatie in de Marathonbuurt Introductie In de eerste drie weken van juni 2007 is in de Marathonbuurt (inclusief de Bertelmanpleinbuurt) een bewonersonderzoek gehouden. De doelstelling daarvan was inzicht te verwerven in de aard, omvang en het proces van intimidatie en polarisatie, evenals in de tegenpool ‘sociaal vertrouwen’. De enquêtes moesten antwoord geven op de vraag welke risicofactoren en beschermingsfactoren aanwezig zijn in de buurten die sociaal vertrouwen kunnen belemmeren of polarisatie kunnen bevorderen. Opzet onderzoek In de eerste helft van 2007 zijn in totaal 258 inwoners geïnterviewd. Daarnaast werden interviews gehouden met professionals en sleutelpersonen in de wijk. Ook is een groepsgesprek met bewoners georganiseerd om de resultaten van het onderzoek nader uit te diepen. Het onderzoek is in opdracht van stadsdeel Oud- Zuid uitgevoerd door het Verwey-Jonker Instituut. Dit gebeurde in nauwe samenwerking met de dienst O&S van de gemeente Amsterdam, onder auspiciën van de leerstoel Veiligheid en Burgerschap van de Vrije Universiteit. -

Besluit Van Het College Van Burgemeester En Wethouders Van De
Nr. 33144 15 februari GEMEENTEBLAD 2018 Officiële uitgave van de gemeente Amsterdam Besluit van het college van burgemeester en wethouders van de gemeente Amsterdam houdende regels omtrent parkeren Uitwerkingsbesluit parkeerverordening stadsdeel Zuid 2018 Burgemeester en wethouders van Amsterdam Brengen ter algemene kennis dat zij in hun vergadering van 19 december 2017 hebben besloten: I. In te trekken: a. het Uitwerkingsbesluit parkeerverordening stadsdeel Zuid 2016; II. Onder de voorwaarde van vaststelling door de gemeenteraad op 20 december 2017 van de Ver- ordening Parkeerbelastingen 2018 en de gewijzigde Parkeerverordening 2013 vast te stellen: a. het Uitwerkingsbesluit parkeerverordening stadsdeel Zuid 2018 met als belangrijkste punten: 3. Stadsdeel Zuid Prinses Irenebuurt a. een parkeerduurbeperking van twee uur in het voormalig experiment gebied met belanghebbenden parkeren; b. verruimen van de bezoekersregeling van 30 naar 60 bezoekersuren met 50% korting per maand in het nieuwe gebied; c. de omgeving van de Fred Roeskestraat wordt vergunninggebied Zuid-2 (was Zuid-5). Buitenveldert-Noord d. toevoegen parkeerduurbeperking maximaal 3 uur op Amstelveenseweg ( tussen De Boelelaan en Van Nijenrodeweg); e. afschaffen parkeerduurbeperking Cronenburg en Rupelmonde; f. verruimen van de bezoekersregeling van 30 naar 60 gratis bezoekersuren per maand. III. Dat het Uitwerkingsbesluit parkeerverordening stadsdeel Zuid 2018 wordt gepubliceerd in het Gemeenteblad; IV. Dat dit besluit in werking treedt per 1 januari 2018, met uitzondering van het besluit zoals opge- nomen in het beslispunt II.3c; V. Dat het besluit, zoals opgenomen in beslispunt II.3c per 1 maart 2018 in werking treedt. Artikel 1 Begripsbepalingen In dit uitwerkingsbesluit wordt verstaan onder: • Verordening: de Parkeerverordening 2013; • Stadsdeel: het stadsdeel Zuid; • College: het college van burgemeester en wethouders van de gemeente Amsterdam. -

Housing for Whom?
Housing for whom? Distributive justice in times of increasing housing shortages in Amsterdam Author: Spike Snellens Student nr.: 10432590 Track: Political Science PPG Course: Politics of Inequality Supervisor: Dr. F.J. van Hooren 2nd reader: R.J. Pistorius Date: 23 June 2017 Words: 23.999 1. Abstract Famous for its egalitarian housing provision and social sector Amsterdam has inspired urban justice theorists and planners throughout Europe and beyond. However, due to a list of developments for more than ten years now the depiction of Amsterdam as a ‘just city’ is criticized. In fact, even reserved authors fear that in the near future Amsterdam will lose the features that once distinguished it as an example of a just city. In this thesis Amsterdam is treated as such, i.e. as a deteriorating just city. It is treated as a city characterized increasingly by the principle cause of injustice, i.e. shortages in housing, due to insufficient supplies and too much demand and due to the housing reforms which the past twenty years on the local, national and European level have been implemented. These shortages, in turn, are interpreted through the lens of scarce goods multi-principled distributing frameworks, a concept which was borrowed from Persad, Wertheimer and Emanuel. The idea behind this conceptual framework is that multi-principled distributing frameworks highlight and downplay morally relevant considerations, i.e. both include and exclude on the basis of justice principles, which means in turn that ‘just injustice’ entails that there exist a certain un-biased balance between allocative principles. The use of this lens mirrors the idea that housing is a perennial challenge, by which is meant that distributive struggles revolve around the design of such allocating frameworks and that these can increase when shortage increases. -

Wooncarrière in De Veranderende Stad a M S T E R D a M INHOUD
Wooncarrière in de veranderende stad A m s t e r d a m INHOUD Voorwoord Hoofdstukken: 1 Binding, wooncarrière en de veranderende stad 7 2 I Amsterdam 17 3 Een dorp in de stad 31 4 Stedelijk leven 43 2 5 Weg van Amsterdam 59 6 Verschillende buurten, verschillende mensen 73 Korte verantwoording van het onderzoek 83 Voetnoten 86 Colofon 88 Voorwoord Iedere twee jaar voeren de Gemeente Amsterdam en de Amsterdamse Federatie van Woningcorporaties een grootschalige enquête uit onder duizenden Amsterdammers. In dit onderzoek ‘Wonen in Amsterdam’ worden de woonwensen en de woonsituatie van Amsterdammers onderzocht. Wonen in Amsterdam geeft een goed en uitgebreid beeld van de woningmarkt met veel feiten en cijfers. Wat ontbreekt is het verhaal achter de cijfers. Voor dit onderzoek zijn daarom geen enquêtes afgenomen, maar gesprekken gevoerd met honderd Amsterdammers over hun woonsituatie. Het stedelijk wonen is weer populair. Steeds meer mensen kiezen bewust voor het stedelijk leven. Tegelijkertijd maken veel buurten in Amsterdam een proces van herwaardering door. Soms autonoom, soms gestimuleerd door investeringen door corporaties en de gemeente. Dit onderzoek vormt een overzicht van ervaringen van stedelingen op de woningmarkt. Deze woningmarkt bestaat uit een mozaïek van mensen en woningen en wordt gekenmerkt door een enorme diversiteit. Juist die diversiteit komt in dit boek naar voren. 5 In dit boek wordt de dynamiek van de stad gecombineerd met de individuele keuzes die mensen maken in hun wooncarrière. We zijn verheugd te zien dat de meeste geïnterviewde Amsterdammers tevreden zijn en ieder op zijn eigen wijze een binding met de buurt of stad heeft. -

AFC Schakel 5 Nov 2005.Indd
Dit is de Schakel die komt binden. De oude club aan d’oude vrinden. 9 november 2005 84e jaargang nr. 5 Autobedrijf De Jong AFC IN BEELD zondag 13 november 14.30 uur zondag 20 november 14.30 uur AFC - Haaglandia Blauw Wit - AFC zondag 27 november 14.30 uur AFC - ADO’20 Andere interessante wedstrijden zaterdag 12 november zondag 13 november 14.45 uur AFC zat. 1 - Vlug en Vaardig 1 11.00 uur AFC 2 - DWS 2 12.00 uur AFC B1 - Emmen B1 11.45 uur AFC A2 - Kolping Boys A1 14.45 uur AFC C1 - GVVV C1 zaterdag 19 november zondag 20 november 14.30 uur AFC A1 - Argon A1 11.45 uur AFC C2 - Stormvogels/Telstar C2 11.45 uur AFC B2 - Geinoord B1 zaterdag 26 november zondag 27 november 14.30 uur AFC A1 - FC Utrecht A1 11.45 uur AFC B2 - DWS B2 De volgende Schakel zal op 30 november verschijnen, dus over 3 weken. 05 0 ster 2 m da - A m 5 s 9 c h 8 e 1 F o o t e b a l 9 november 2005 84 jaargang nr. 5 l C l u b b de AFC Schakel ‘Red’-aktueel Website: www.afc-amsterdam.nl; teletekst AT5 pag. 515 e-mail Schakel en website: [email protected] AFC is in de afgelopen weken zeer uitgebreid en op uiterst positieve wijze in de e-mail teletekst: [email protected] publiciteit gekomen. Voor de leden die, om welke reden dan ook, AFC uitsluitend Productie Schakel Hans Elias 0297-563328 via de Schakel (kunnen) volgen loop ik de mediabelangstelling langs.