Voldemortkg: Mapping Schema.Org and Web Entities to Linked Open Data
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

How to Keep a Knowledge Base Synchronized with Its Encyclopedia Source
Proceedings of the Twenty-Sixth International Joint Conference on Artificial Intelligence (IJCAI-17) How to Keep a Knowledge Base Synchronized with Its Encyclopedia Source Jiaqing Liang12, Sheng Zhang1, Yanghua Xiao134∗ 1School of Computer Science, Shanghai Key Laboratory of Data Science Fudan University, Shanghai, China 2Shuyan Technology, Shanghai, China 3Shanghai Internet Big Data Engineering Technology Research Center, China 4Xiaoi Research, Shanghai, China [email protected], fshengzhang16,[email protected] Abstract However, most of these knowledge bases tend to be out- dated, which limits their utility. For example, in many knowl- Knowledge bases are playing an increasingly im- edge bases, Donald Trump is only a business man even af- portant role in many real-world applications. How- ter the inauguration. Obviously, it is important to let ma- ever, most of these knowledge bases tend to be chines know that Donald Trump is the president of the United outdated, which limits the utility of these knowl- States so that they can understand that the topic of an arti- edge bases. In this paper, we investigate how to cle mentioning Donald Trump is probably related to politics. keep the freshness of the knowledge base by syn- Moreover, new entities are continuously emerging and most chronizing it with its data source (usually ency- of them are popular, such as iphone 8. However, it is hard for clopedia websites). A direct solution is revisiting a knowledge base to cover these entities in time even if the the whole encyclopedia periodically and rerun the encyclopedia websites have already covered them. entire pipeline of the construction of knowledge freshness base like most existing methods. -

Learning Ontologies from RDF Annotations
/HDUQLQJÃRQWRORJLHVÃIURPÃ5')ÃDQQRWDWLRQV $OH[DQGUHÃ'HOWHLOÃ&DWKHULQHÃ)DURQ=XFNHUÃ5RVHÃ'LHQJ ACACIA project, INRIA, 2004, route des Lucioles, B.P. 93, 06902 Sophia Antipolis, France {Alexandre.Delteil, Catherine.Faron, Rose.Dieng}@sophia.inria.fr $EVWUDFW objects, as in [Mineau, 1990; Carpineto and Romano, 1993; Bournaud HWÃDO., 2000]. In this paper, we present a method for learning Since all RDF annotations are gathered inside a common ontologies from RDF annotations of Web RDF graph, the problem which arises is the extraction of a resources by systematically generating the most description for a given resource from the whole RDF graph. specific generalization of all the possible sets of After a brief description of the RDF data model (Section 2) resources. The preliminary step of our method and of RDF Schema (Section 3), Section 4 presents several consists in extracting (partial) resource criteria for extracting partial resource descriptions. In order descriptions from the whole RDF graph gathering to deal with the intrinsic complexity of the building of a all the annotations. In order to deal with generalization hierarchy, we propose an incremental algorithmic complexity, we incrementally build approach by gradually increasing the size of the descriptions the ontology by gradually increasing the size of the resource descriptions we consider. we consider. The principle of the approach is explained in Section 5 and more deeply detailed in Section 6. Ã ,QWURGXFWLRQ Ã 7KHÃ5')ÃGDWDÃPRGHO The Semantic Web, expected to be the next step that will RDF is the emerging Web standard for annotating resources lead the Web to its full potential, will be based on semantic HWÃDO metadata describing all kinds of Web resources. -

Introduction to Linked Data and Its Lifecycle on the Web
Introduction to Linked Data and its Lifecycle on the Web Sören Auer, Jens Lehmann, Axel-Cyrille Ngonga Ngomo, Amrapali Zaveri AKSW, Institut für Informatik, Universität Leipzig, Pf 100920, 04009 Leipzig {lastname}@informatik.uni-leipzig.de http://aksw.org Abstract. With Linked Data, a very pragmatic approach towards achieving the vision of the Semantic Web has gained some traction in the last years. The term Linked Data refers to a set of best practices for publishing and interlinking struc- tured data on the Web. While many standards, methods and technologies devel- oped within by the Semantic Web community are applicable for Linked Data, there are also a number of specific characteristics of Linked Data, which have to be considered. In this article we introduce the main concepts of Linked Data. We present an overview of the Linked Data lifecycle and discuss individual ap- proaches as well as the state-of-the-art with regard to extraction, authoring, link- ing, enrichment as well as quality of Linked Data. We conclude the chapter with a discussion of issues, limitations and further research and development challenges of Linked Data. This article is an updated version of a similar lecture given at Reasoning Web Summer School 2011. 1 Introduction One of the biggest challenges in the area of intelligent information management is the exploitation of the Web as a platform for data and information integration as well as for search and querying. Just as we publish unstructured textual information on the Web as HTML pages and search such information by using keyword-based search engines, we are already able to easily publish structured information, reliably interlink this informa- tion with other data published on the Web and search the resulting data space by using more expressive querying beyond simple keyword searches. -

Linked Data Services for Internet of Things
International Conference on Recent Advances in Computer Systems (RACS 2015) Linked Data Services for Internet of Things Jaroslav Pullmann, Dr. Yehya Mohamad User-Centered Ubiquitous Computing department Fraunhofer Institute for Applied Information Technology FIT Sankt Augustin, Germany {jaroslav.pullmann, yehya.mohamad}@fit.fraunhofer.de Abstract — In this paper we present the open source “LinkSmart Resource Framework” allowing developers to II. LINKSMART RESOURCE FRAMEWORK incorporate heterogeneous data sources and physical devices through a generic service facade independent of the data model, A. Rationale persistence technology or access protocol. We particularly consi- The Java Data Objects standard [2] specifies an interface to der the integration and maintenance of Linked Data, a widely persist Java objects in a technology agnostic way. The related accepted means for expressing highly-structured, machine reada- ble (meta)data graphs. Thanks to its uniform, technology- Java Persistence specification [3] concentrates on object-rela- agnostic view on data, the framework is expected to increase the tional mapping only. We consider both specifications techno- ease-of-use, maintainability and usability of software relying on logy-driven, overly detailed with regards to common data ma- it. The development of various technologies to access, interact nagement tasks, while missing some important high-level with and manage data has led to rise of parallel communities functionality. The rationale underlying the LinkSmart Resour- often unaware of alternatives beyond their technology bounda- ce Platform is to define a generic, uniform interface for ries. Systems for object-relational mapping, NoSQL document or management, retrieval and processing of data while graph-based Linked Data storage usually exhibit complex, maintaining a technology and implementation agnostic facade. -

Using Shape Expressions (Shex) to Share RDF Data Models and to Guide Curation with Rigorous Validation B Katherine Thornton1( ), Harold Solbrig2, Gregory S
View metadata, citation and similar papers at core.ac.uk brought to you by CORE provided by Repositorio Institucional de la Universidad de Oviedo Using Shape Expressions (ShEx) to Share RDF Data Models and to Guide Curation with Rigorous Validation B Katherine Thornton1( ), Harold Solbrig2, Gregory S. Stupp3, Jose Emilio Labra Gayo4, Daniel Mietchen5, Eric Prud’hommeaux6, and Andra Waagmeester7 1 Yale University, New Haven, CT, USA [email protected] 2 Johns Hopkins University, Baltimore, MD, USA [email protected] 3 The Scripps Research Institute, San Diego, CA, USA [email protected] 4 University of Oviedo, Oviedo, Spain [email protected] 5 Data Science Institute, University of Virginia, Charlottesville, VA, USA [email protected] 6 World Wide Web Consortium (W3C), MIT, Cambridge, MA, USA [email protected] 7 Micelio, Antwerpen, Belgium [email protected] Abstract. We discuss Shape Expressions (ShEx), a concise, formal, modeling and validation language for RDF structures. For instance, a Shape Expression could prescribe that subjects in a given RDF graph that fall into the shape “Paper” are expected to have a section called “Abstract”, and any ShEx implementation can confirm whether that is indeed the case for all such subjects within a given graph or subgraph. There are currently five actively maintained ShEx implementations. We discuss how we use the JavaScript, Scala and Python implementa- tions in RDF data validation workflows in distinct, applied contexts. We present examples of how ShEx can be used to model and validate data from two different sources, the domain-specific Fast Healthcare Interop- erability Resources (FHIR) and the domain-generic Wikidata knowledge base, which is the linked database built and maintained by the Wikimedia Foundation as a sister project to Wikipedia. -

Hidden Meaning
FEATURES Microdata and Microformats Kit Sen Chin, 123RF.com Chin, Sen Kit Working with microformats and microdata Hidden Meaning Programs aren’t as smart as humans when it comes to interpreting the meaning of web information. If you want to maximize your search rank, you might want to dress up your HTML documents with microformats and microdata. By Andreas Möller TML lets you mark up sections formats and microdata into your own source code for the website shown in of text as headings, body text, programs. Figure 1 – an HTML5 document with a hyperlinks, and other web page business card. The Heading text block is H elements. However, these defi- Microformats marked up with the element h1. The text nitions have nothing to do with the HTML was originally designed for hu- for the business card is surrounded by meaning of the data: Does the text refer mans to read, but with the explosive the div container element, and <br/> in- to a person, an organization, a product, growth of the web, programs such as troduces a line break. or an event? Microformats [1] and their search engines also process HTML data. It is easy for a human reader to see successor, microdata [2] make the mean- What do programs that read HTML data that the data shown in Figure 1 repre- ing a bit more clear by pointing to busi- typically find? Listing 1 shows the HTML sents a business card – even if the text is ness cards, product descriptions, offers, and event data in a machine-readable LISTING 1: HTML5 Document with Business Card way. -

Le Microformat Hproduct C'est Quoi ? Pourquoi Utiliser Le Microformat
Apprendre à utiliser les microformats : hProduct 2017-02-21 23:02:01 Nicolaseo Le microformat hProduct c’est quoi ? hProduct est un microformat approprié pour publier et embarquer les données de vos produits. C’est une sorte de méta tags qui permet de structurer vos données pour permettre aux robots des moteurs de recherche de mieux référencer votre contenu. Pourquoi utiliser le microformat hProduct Le microformat hProduct est basé sur un ensemble de champs très important pour communiquer avec les robots des moteurs de recherche comme Google. Utiliser les {meta- tags|richsnippets|microformats} (et tout ce qui peut permettre aux moteurs de recherche de mieux classer votre contenu) vous apportera plus de visibilité sur internet grâce à un meilleur référencement de votre site et de son contenu. Comment utiliser le microformat hProduct Le schéma hProduct se compose de ce qui suit : hproduct brand. optionnel. texte. peut aussi utiliser hCard pour les fabricants. category. optionnel. texte. peut aussi utiliser rel-tag. ré-utilisé à partir de hCard. price. optionnel. floating point number. peut utiliser un format de devise. description. optionnel. texte. peut aussi inclure un marquage HTML valide. réutilisé à partir de hReview. fn. requis. texte. nom du produit ou titre. réutilisé de hCard. photo. optionnel. élément image ou lien. réutilisé de hCard. url. optionnel. href. peut contenir rel-tag rel=’product’. ré-utilisé de hCard. review. optionnel. hReview, ou hReview-aggregate. listing. optionnel. hListing, ou hListing-aggregate. identifier. optionnel. type. requis. – exemples : model mpn upc isbn issn ean jan sn vin sku value. requis. – l’étiquette peut être implicite. Détails des champs du microformat hProduct Les noms de classe category, fn, photo, url sont réutilisés à partir de hCard. -

Where Is the Semantic Web? – an Overview of the Use of Embeddable Semantics in Austria
Where Is The Semantic Web? – An Overview of the Use of Embeddable Semantics in Austria Wilhelm Loibl Institute for Service Marketing and Tourism Vienna University of Economics and Business, Austria [email protected] Abstract Improving the results of search engines and enabling new online applications are two of the main aims of the Semantic Web. For a machine to be able to read and interpret semantic information, this content has to be offered online first. With several technologies available the question arises which one to use. Those who want to build the software necessary to interpret the offered data have to know what information is available and in which format. In order to answer these questions, the author analysed the business websites of different Austrian industry sectors as to what semantic information is embedded. Preliminary results show that, although overall usage numbers are still small, certain differences between individual sectors exist. Keywords: semantic web, RDFa, microformats, Austria, industry sectors 1 Introduction As tourism is a very information-intense industry (Werthner & Klein, 1999), especially novel users resort to well-known generic search engines like Google to find travel related information (Mitsche, 2005). Often, these machines do not provide satisfactory search results as their algorithms match a user’s query against the (weighted) terms found in online documents (Berry and Browne, 1999). One solution to this problem lies in “Semantic Searches” (Maedche & Staab, 2002). In order for them to work, web resources must first be annotated with additional metadata describing the content (Davies, Studer & Warren., 2006). Therefore, anyone who wants to provide data online must decide on which technology to use. -

Linked Data Vs Schema.Org: a Town Hall Debate About the Future of Information
Linked Data vs Schema.org: A Town Hall Debate about the Future of Information Schema.org Resources Schema.org Microdata Creation and Analysis Tools Schema.org Google Structured Data Testing Tool http://schema.org/docs/full.html http://www.google.com/webmasters/tools/richsnippets The entire hierarchy in one file. Microdata Parser Schema.org FAQ http://tools.seomoves.org/microdata http://schema.org/docs/faq.html This tool parses HTML5 microdata on a web page and displays the results in a graphical view. You can see the full details of each microdata type by clicking on it. Getting Started with Schema.org http://schema.org/docs/gs.html Drupal module Includes information about how to mark up your content http://drupal.org/project/schemaorg using microdata, using the schema.org vocabulary, and advanced topics. A drop-in solution to enable the collections of schemas available at schema.org on your Drupal 7 site. Micro Data & Schema.org: Guide To Generating Rich Snippets Wordpress plugins http://seogadget.com/micro-data-schema-org-guide-to- http://wordpress.org/extend/plugins/tags/schemaorg generating-rich-snippets A list of Wordpress plugins that allow you to easily insert A very comprehensive guide that includes an schema.org microdata on your site. introduction, a section on integrating microdata (use cases) schema.org, and a section on tools and useful Microdata generator resources. http://www.microdatagenerator.com A simple generator that allows you to input basic HTML5 Microdata and Schema.org information and have that info converted into the http://journal.code4lib.org/articles/6400 standard schema.org markup structure. -

Microformats the Next (Small) Thing on the Semantic Web?
Standards Editor: Jim Whitehead • [email protected] Microformats The Next (Small) Thing on the Semantic Web? Rohit Khare • CommerceNet “Designed for humans first and machines second, microformats are a set of simple, open data formats built upon existing and widely adopted standards.” — Microformats.org hen we speak of the “evolution of the is precisely encoding the great variety of person- Web,” it might actually be more appropri- al, professional, and genealogical relationships W ate to speak of “intelligent design” — we between people and organizations. By contrast, can actually point to a living, breathing, and an accidental challenge is that any blogger with actively involved Creator of the Web. We can even some knowledge of HTML can add microformat consult Tim Berners-Lee’s stated goals for the markup to a text-input form, but uploading an “promised land,” dubbed the Semantic Web. Few external file dedicated to machine-readable use presume we could reach those objectives by ran- remains forbiddingly complex with most blog- domly hacking existing Web standards and hop- ging tools. ing that “natural selection” by authors, software So, although any intelligent designer ought to developers, and readers would ensure powerful be able to rely on the long-established facility of enough abstractions for it. file transfer to publish the “right” model of a social Indeed, the elegant and painstakingly inter- network, the path of least resistance might favor locked edifice of technologies, including RDF, adding one of a handful of fixed tags to an exist- XML, and query languages is now growing pow- ing indirect form — the “blogroll” of hyperlinks to erful enough to attack massive information chal- other people’s sites. -

Data Models for Home Services
__________________________________________PROCEEDING OF THE 13TH CONFERENCE OF FRUCT ASSOCIATION Data Models for Home Services Vadym Kramar, Markku Korhonen, Yury Sergeev Oulu University of Applied Sciences, School of Engineering Raahe, Finland {vadym.kramar, markku.korhonen, yury.sergeev}@oamk.fi Abstract An ultimate penetration of communication technologies allowing web access has enriched a conception of smart homes with new paradigms of home services. Modern home services range far beyond such notions as Home Automation or Use of Internet. The services expose their ubiquitous nature by being integrated into smart environments, and provisioned through a variety of end-user devices. Computational intelligence require a use of knowledge technologies, and within a given domain, such requirement as a compliance with modern web architecture is essential. This is where Semantic Web technologies excel. A given work presents an overview of important terms, vocabularies, and data models that may be utilised in data and knowledge engineering with respect to home services. Index Terms: Context, Data engineering, Data models, Knowledge engineering, Semantic Web, Smart homes, Ubiquitous computing. I. INTRODUCTION In recent years, a use of Semantic Web technologies to build a giant information space has shown certain benefits. Rapid development of Web 3.0 and a use of its principle in web applications is the best evidence of such benefits. A traditional database design in still and will be widely used in web applications. One of the most important reason for that is a vast number of databases developed over years and used in a variety of applications varying from simple web services to enterprise portals. In accordance to Forrester Research though a growing number of document, or knowledge bases, such as NoSQL is not a hype anymore [1]. -
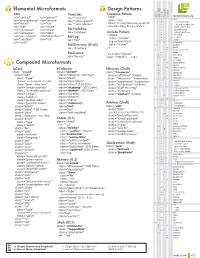
Microformats Cheat Sheet
Elemental Microformats Design Patterns tom eview Datetime Pattern esume XFN VoteLinks microformats.org hR hR hCard hCalendar rel="contact" rel="parent" rev="vote-for" <abbr hA rel="acquaintance" rel="spouse" class="foo" • adr rev="vote-against" + country-name title="YYYY-MM-DDTHH:MM:SS+ZZ:ZZ" rel="friend" rel="kin" rev="vote-abstain" • extended-address rel="met" rel="muse" >Human Date Time</abbr> + post-office-box rel="co-worker" rel="crush" Rel-Nofollow + postal-code rel="colleague" rel="date" rel="nofollow" Include Pattern • street-address + locality rel="co-resident" rel="sweetheart" <object Rel-Tag class="include" + region rel="neighbor" rel="me" rel="tag" • type rel="child" type="text/html" • affiliation Rel-Directory (Draft) data="#idref" ¤ author rel="directory" /> + best × + bookmark (rel) Rel-License + bday <a class="include" • • category rel="license" href="#idref">...</a> + + class × contact Compound Microformats + description + dtend + dtreviewed hCard hCalendar hResume (Draft) × dtstart class="vcard" class="vevent" class="hresume" × dtstamp class="adr" class="category" rel="tag" class="affiliation" (hcard) duration class="type" class="class" class="education" (hcalendar) • education [work|home|pref|postal|dom|intl] class="description" • email class="experience" (hcalendar) • type class="post-office-box" class="dtend" (ISO Date) class="publication" (citation) • value class="street-address" class="dtstamp" (ISO Date) class="skill" rel="tag" × entry-content class="extended-address" class="dtstart" (ISO Date) class="summary" • entry-summary