How to Keep a Knowledge Base Synchronized with Its Encyclopedia Source
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Learning Ontologies from RDF Annotations
/HDUQLQJÃRQWRORJLHVÃIURPÃ5')ÃDQQRWDWLRQV $OH[DQGUHÃ'HOWHLOÃ&DWKHULQHÃ)DURQ=XFNHUÃ5RVHÃ'LHQJ ACACIA project, INRIA, 2004, route des Lucioles, B.P. 93, 06902 Sophia Antipolis, France {Alexandre.Delteil, Catherine.Faron, Rose.Dieng}@sophia.inria.fr $EVWUDFW objects, as in [Mineau, 1990; Carpineto and Romano, 1993; Bournaud HWÃDO., 2000]. In this paper, we present a method for learning Since all RDF annotations are gathered inside a common ontologies from RDF annotations of Web RDF graph, the problem which arises is the extraction of a resources by systematically generating the most description for a given resource from the whole RDF graph. specific generalization of all the possible sets of After a brief description of the RDF data model (Section 2) resources. The preliminary step of our method and of RDF Schema (Section 3), Section 4 presents several consists in extracting (partial) resource criteria for extracting partial resource descriptions. In order descriptions from the whole RDF graph gathering to deal with the intrinsic complexity of the building of a all the annotations. In order to deal with generalization hierarchy, we propose an incremental algorithmic complexity, we incrementally build approach by gradually increasing the size of the descriptions the ontology by gradually increasing the size of the resource descriptions we consider. we consider. The principle of the approach is explained in Section 5 and more deeply detailed in Section 6. Ã ,QWURGXFWLRQ Ã 7KHÃ5')ÃGDWDÃPRGHO The Semantic Web, expected to be the next step that will RDF is the emerging Web standard for annotating resources lead the Web to its full potential, will be based on semantic HWÃDO metadata describing all kinds of Web resources. -

KBART: Knowledge Bases and Related Tools
NISO-RP-9-2010 KBART: Knowledge Bases and Related Tools A Recommended Practice of the National Information Standards Organization (NISO) and UKSG Prepared by the NISO/UKSG KBART Working Group January 2010 i About NISO Recommended Practices A NISO Recommended Practice is a recommended "best practice" or "guideline" for methods, materials, or practices in order to give guidance to the user. Such documents usually represent a leading edge, exceptional model, or proven industry practice. All elements of Recommended Practices are discretionary and may be used as stated or modified by the user to meet specific needs. This recommended practice may be revised or withdrawn at any time. For current information on the status of this publication contact the NISO office or visit the NISO website (www.niso.org). Published by National Information Standards Organization (NISO) One North Charles Street, Suite 1905 Baltimore, MD 21201 www.niso.org Copyright © 2010 by the National Information Standards Organization and the UKSG. All rights reserved under International and Pan-American Copyright Conventions. For noncommercial purposes only, this publication may be reproduced or transmitted in any form or by any means without prior permission in writing from the publisher, provided it is reproduced accurately, the source of the material is identified, and the NISO/UKSG copyright status is acknowledged. All inquires regarding translations into other languages or commercial reproduction or distribution should be addressed to: NISO, One North Charles Street, -

The Ontology Web Language (OWL) for a Multi-Agent Understating
The Ontology Web Language (OWL) for a Multi- Agent Understating System Mostafa M. Aref Zhengbo Zhou Department of Computer Science and Engineering University of Bridgeport, Bridgeport, CT 06601 email: [email protected] Abstract— Computer understanding is a challenge OWL is a Web Ontology Language. It is built on top of problem in Artificial Intelligence. A multi-agent system has RDF – Resource Definition Framework and written in XML. been developed to tackle this problem. Among its modules is It is a part of Semantic Web Vision, and is designed to be its knowledge base (vocabulary agents). This paper interpreted by computers, not for being read by people. discusses the use of the Ontology Web Language (OWL) to OWL became a W3C (World Wide Web Consortium) represent the knowledge base. An example of applying OWL Recommendation in February 2004 [2]. The OWL is a in sentence understanding is given. Followed by an language for defining and instantiating Web ontologies. evaluation of OWL. OWL ontology may include the descriptions of classes, properties, and their instances [3]. Given such ontology, the OWL formal semantics specifies how to derive its logical 1. INTRODUCTION consequences, i.e. facts not literally present in the ontology, but entailed by the semantics. One of various definitions for Artificial Intelligence is “The study of how to make computers do things which, at the Section 2 describes a multi-agents understanding system. moment, people do better”[7]. From the definition of AI Section 3 gives a brief description of a newly standardized mentioned above, “Understanding” can be looked as the technique, Web Ontology Language—OWL. -

Feature Engineering for Knowledge Base Construction
Feature Engineering for Knowledge Base Construction Christopher Re´y Amir Abbas Sadeghiany Zifei Shany Jaeho Shiny Feiran Wangy Sen Wuy Ce Zhangyz yStanford University zUniversity of Wisconsin-Madison fchrismre, amirabs, zifei, jaeho.shin, feiran, senwu, [email protected] Abstract Knowledge base construction (KBC) is the process of populating a knowledge base, i.e., a relational database together with inference rules, with information extracted from documents and structured sources. KBC blurs the distinction between two traditional database problems, information extraction and in- formation integration. For the last several years, our group has been building knowledge bases with scientific collaborators. Using our approach, we have built knowledge bases that have comparable and sometimes better quality than those constructed by human volunteers. In contrast to these knowledge bases, which took experts a decade or more human years to construct, many of our projects are con- structed by a single graduate student. Our approach to KBC is based on joint probabilistic inference and learning, but we do not see inference as either a panacea or a magic bullet: inference is a tool that allows us to be systematic in how we construct, debug, and improve the quality of such systems. In addition, inference allows us to construct these systems in a more loosely coupled way than traditional approaches. To support this idea, we have built the DeepDive system, which has the design goal of letting the user “think about features— not algorithms.” We think of DeepDive as declarative in that one specifies what they want but not how to get it. We describe our approach with a focus on feature engineering, which we argue is an understudied problem relative to its importance to end-to-end quality. -

Efficient Inference and Learning in a Large Knowledge Base
Mach Learn DOI 10.1007/s10994-015-5488-x Efficient inference and learning in a large knowledge base Reasoning with extracted information using a locally groundable first-order probabilistic logic William Yang Wang1 · Kathryn Mazaitis1 · Ni Lao2 · William W. Cohen1 Received: 10 January 2014 / Accepted: 4 March 2015 © The Author(s) 2015 Abstract One important challenge for probabilistic logics is reasoning with very large knowledge bases (KBs) of imperfect information, such as those produced by modern web- scale information extraction systems. One scalability problem shared by many probabilistic logics is that answering queries involves “grounding” the query—i.e., mapping it to a proposi- tional representation—and the size of a “grounding” grows with database size. To address this bottleneck, we present a first-order probabilistic language called ProPPR in which approxi- mate “local groundings” can be constructed in time independent of database size. Technically, ProPPR is an extension to stochastic logic programs that is biased towards short derivations; it is also closely related to an earlier relational learning algorithm called the path ranking algorithm. We show that the problem of constructing proofs for this logic is related to com- putation of personalized PageRank on a linearized version of the proof space, and based on this connection, we develop a provably-correct approximate grounding scheme, based on the PageRank–Nibble algorithm. Building on this, we develop a fast and easily-parallelized weight-learning algorithm for ProPPR. In our experiments, we show that learning for ProPPR is orders of magnitude faster than learning for Markov logic networks; that allowing mutual recursion (joint learning) in KB inference leads to improvements in performance; and that Editors: Gerson Zaverucha and Vítor Santos Costa. -

Semantic Web: a Review of the Field Pascal Hitzler [email protected] Kansas State University Manhattan, Kansas, USA
Semantic Web: A Review Of The Field Pascal Hitzler [email protected] Kansas State University Manhattan, Kansas, USA ABSTRACT which would probably produce a rather different narrative of the We review two decades of Semantic Web research and applica- history and the current state of the art of the field. I therefore do tions, discuss relationships to some other disciplines, and current not strive to achieve the impossible task of presenting something challenges in the field. close to a consensus – such a thing seems still elusive. However I do point out here, and sometimes within the narrative, that there CCS CONCEPTS are a good number of alternative perspectives. The review is also necessarily very selective, because Semantic • Information systems → Graph-based database models; In- Web is a rich field of diverse research and applications, borrowing formation integration; Semantic web description languages; from many disciplines within or adjacent to computer science, Ontologies; • Computing methodologies → Description log- and a brief review like this one cannot possibly be exhaustive or ics; Ontology engineering. give due credit to all important individual contributions. I do hope KEYWORDS that I have captured what many would consider key areas of the Semantic Web field. For the reader interested in obtaining amore Semantic Web, ontology, knowledge graph, linked data detailed overview, I recommend perusing the major publication ACM Reference Format: outlets in the field: The Semantic Web journal,1 the Journal of Pascal Hitzler. 2020. Semantic Web: A Review Of The Field. In Proceedings Web Semantics,2 and the proceedings of the annual International of . ACM, New York, NY, USA, 7 pages. -

Representing Knowledge in the Semantic Web Oreste Signore W3C Office in Italy at CNR - Via G
Representing Knowledge in the Semantic Web Oreste Signore W3C Office in Italy at CNR - via G. Moruzzi, 1 -56124 Pisa - (Italy) Phone: +39 050 315 2995 (office) e.mail: [email protected] home page: http://www.weblab.isti.cnr.it/people/oreste/ Abstract – The Web is an immense repository of data and knowledge. Semantic web technologies support semantic interoperability and machine-to-machine interaction. A significant role is played by ontologies, which can support reasoning. Generally much emphasis is given to retrieval, while users tend to browse by association. If data are semantically annotated, an appropriate intelligent user agent aware of the mental model and interests of the user can support her/him in finding the desired information. The whole process must be supported by a core ontology. 1. Introduction W3C leads the evolution of the Web. Universal Access and Semantic Web show a significant impact upon interoperability, technological as well as semantic. In this paper we will discuss the role played by XML to support interoperability within applications, while RDF helps in cross applications interoperability. Subsequently, the paper considers the metadata issue, with a brief description of RDF and the Semantic Web stack. Finally, we discuss an example in the area of cultural heritage, which is very rich in variety of possible associations, presenting an architecture where intelligent agents make use of core ontology to help users in finding the appropriate information. 2. The World Wide Web Consortium (W3C) The Wide Web Consortium (W3C) was created in October 1994 to lead the World Wide Web to its full potential by developing common protocols that promote its evolution and ensure its interoperability. -

Ontology and Information Systems
Ontology and Information Systems 1 Barry Smith Philosophical Ontology Ontology as a branch of philosophy is the science of what is, of the kinds and structures of objects, properties, events, processes and relations in every area of reality. ‘Ontology’ is often used by philosophers as a synonym for ‘metaphysics’ (literally: ‘what comes after the Physics’), a term which was used by early students of Aristotle to refer to what Aristotle himself called ‘first philosophy’.2 The term ‘ontology’ (or ontologia) was itself coined in 1613, independently, by two philosophers, Rudolf Göckel (Goclenius), in his Lexicon philosophicum and Jacob Lorhard (Lorhardus), in his Theatrum philosophicum. The first occurrence in English recorded by the OED appears in Bailey’s dictionary of 1721, which defines ontology as ‘an Account of being in the Abstract’. Methods and Goals of Philosophical Ontology The methods of philosophical ontology are the methods of philosophy in general. They include the development of theories of wider or narrower scope and the testing and refinement of such theories by measuring them up, either against difficult 1 This paper is based upon work supported by the National Science Foundation under Grant No. BCS-9975557 (“Ontology and Geographic Categories”) and by the Alexander von Humboldt Foundation under the auspices of its Wolfgang Paul Program. Thanks go to Thomas Bittner, Olivier Bodenreider, Anita Burgun, Charles Dement, Andrew Frank, Angelika Franzke, Wolfgang Grassl, Pierre Grenon, Nicola Guarino, Patrick Hayes, Kathleen Hornsby, Ingvar Johansson, Fritz Lehmann, Chris Menzel, Kevin Mulligan, Chris Partridge, David W. Smith, William Rapaport, Daniel von Wachter, Chris Welty and Graham White for helpful comments. -
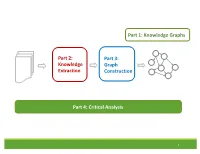
Knowledge Extraction Part 3: Graph
Part 1: Knowledge Graphs Part 2: Part 3: Knowledge Graph Extraction Construction Part 4: Critical Analysis 1 Tutorial Outline 1. Knowledge Graph Primer [Jay] 2. Knowledge Extraction from Text a. NLP Fundamentals [Sameer] b. Information Extraction [Bhavana] Coffee Break 3. Knowledge Graph Construction a. Probabilistic Models [Jay] b. Embedding Techniques [Sameer] 4. Critical Overview and Conclusion [Bhavana] 2 Critical Overview SUMMARY SUCCESS STORIES DATASETS, TASKS, SOFTWARES EXCITING ACTIVE RESEARCH FUTURE RESEARCH DIRECTIONS 3 Critical Overview SUMMARY SUCCESS STORIES DATASETS, TASKS, SOFTWARES EXCITING ACTIVE RESEARCH FUTURE RESEARCH DIRECTIONS 4 Why do we need Knowledge graphs? • Humans can explore large database in intuitive ways •AI agents get access to human common sense knowledge 5 Knowledge graph construction A1 E1 • Who are the entities A2 (nodes) in the graph? • What are their attributes E2 and types (labels)? A1 A2 • How are they related E3 (edges)? A1 A2 6 Knowledge Graph Construction Knowledge Extraction Graph Knowledge Text Extraction graph Construction graph 7 Two perspectives Extraction graph Knowledge graph Who are the entities? (nodes) What are their attributes? (labels) How are they related? (edges) 8 Two perspectives Extraction graph Knowledge graph Who are the entities? • Named Entity • Entity Linking (nodes) Recognition • Entity Resolution • Entity Coreference What are their • Entity Typing • Collective attributes? (labels) classification How are they related? • Semantic role • Link prediction (edges) labeling • Relation Extraction 9 Knowledge Extraction John was born in Liverpool, to Julia and Alfred Lennon. Text NLP Lennon.. Mrs. Lennon.. his father John Lennon... the Pool .. his mother .. he Alfred Person Location Person Person John was born in Liverpool, to Julia and Alfred Lennon. -

Meet the Data
Chapter 2 Meet the Data This chapter introduces the basic types of data sources, as well as specific datasets and resources, that we will be working with in later chapters of the book. These may be placed on a spectrum of varying degrees of structure, from unstructured to structured data, as shown in Fig. 2.1. Fig. 2.1 The data spectrum On the unstructured end of the spectrum we have plain text. Typically, these are documents written in natural language.1 As a matter of fact, almost any type of data can be converted into plain text, including web pages, emails, spreadsheets, and database records. Of course, such a conversion would result in an undesired loss of internal document structure and semantics. It is nevertheless always an option to treat data as unstructured, by not making any assumptions about the particular data format. Search in unstructured text is often referred to as full-text search. On the opposite end of the spectrum there is structured data, which is typically stored in relational databases; it is highly organized, tabular, and governed by a strict schema. Search in this type of data is performed using formal query languages, like SQL. These languages allow for a very precise formulation of information needs, but require expert knowledge of the query language and of the underlying database schema. This generally renders them unsuitable for ordinary users. The data we will mostly be dealing with is neither of two extremes and falls somewhere “in the middle.” Therefore, it is termed semi-structured.Itis 1Written in natural language does not imply that the text has to be grammatical (or even sensible). -

Application of Resource Description Framework to Personalise Learning: Systematic Review and Methodology
Informatics in Education, 2017, Vol. 16, No. 1, 61–82 61 © 2017 Vilnius University DOI: 10.15388/infedu.2017.04 Application of Resource Description Framework to Personalise Learning: Systematic Review and Methodology Tatjana JEVSIKOVA1, Andrius BERNIUKEVIČIUS1 Eugenijus KURILOVAS1,2 1Vilnius University Institute of Mathematics and Informatics Akademijos str. 4, LT-08663 Vilnius, Lithuania 2Vilnius Gediminas Technical University Sauletekio al. 11, LT-10223 Vilnius, Lithuania e-mail: [email protected], [email protected], [email protected] Received: July 2016 Abstract. The paper is aimed to present a methodology of learning personalisation based on ap- plying Resource Description Framework (RDF) standard model. Research results are two-fold: first, the results of systematic literature review on Linked Data, RDF “subject-predicate-object” triples, and Web Ontology Language (OWL) application in education are presented, and, second, RDF triples-based learning personalisation methodology is proposed. The review revealed that OWL, Linked Data, and triples-based RDF standard model could be successfully used in educa- tion. On the other hand, although OWL, Linked Data approach and RDF standard model are al- ready well-known in scientific literature, only few authors have analysed its application to person- alise learning process, but many authors agree that OWL, Linked Data and RDF-based learning personalisation trends should be further analysed. The main scientific contribution of the paper is presentation of original methodology to create personalised RDF triples to further development of corresponding OWL-based ontologies and recommender system. According to this methodology, RDF-based personalisation of learning should be based on applying students’ learning styles and intelligent technologies. -

RDFKB: Efficient Support for RDF Inference Queries and Knowledge Management James P
RDFKB: Efficient Support For RDF Inference Queries and Knowledge Management James P. McGlothlin Latifur R. Khan The University of Texas at Dallas The University of Texas at Dallas 800 West Campbell Road 800 West Campbell Road Richardson, TX 75080 Richardson, TX 75080 [email protected] [email protected] ABSTRACT knowledge, and not simply the recording of facts, the knowledge RDFKB (Resource Description Framework Knowledge Base) is a base must enable answering queries that require inference and relational database system for RDF datasets which supports deductive reasoning. inference and knowledge management. Significant research has A simple example of inference is the well-known logical addressed improving the performance of queries against RDF syllogism from the ancients Greeks: datasets. Generally, this research has not addressed queries All men are mortal. against inferred knowledge. Solutions which do support inference Socrates is a man. queries have done so as part of query processing. Ontologies Therefore, Socrates is mortal. define the rules that govern inference for RDF datasets. These The core strategy of RDFKB is to apply all known inference rules inference rules can be applied to RDF datasets to derive additional to the dataset to determine all possible knowledge, and then store facts through methods such as subsumption, symmetry and all this knowledge. Inference is performed at the time the data is transitive closure. We propose a framework that supports stored rather than at query time. When new data is added to the inference at data storage time rather than as part of query database, we execute the inference engine and attempt to processing.