Programming of Graphics
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Energy-Efficient VLSI Architectures for Next
UNIVERSITY OF CALIFORNIA Los Angeles Energy-Efficient VLSI Architectures for Next- Generation Software-Defined and Cognitive Radios A dissertation submitted in partial satisfaction of the requirements for the degree Doctor of Philosophy in Electrical Engineering by Fang-Li Yuan 2014 c Copyright by Fang-Li Yuan 2014 ABSTRACT OF THE DISSERTATION Energy-Efficient VLSI Architectures for Next- Generation Software-Defined and Cognitive Radios by Fang-Li Yuan Doctor of Philosophy in Electrical Engineering University of California, Los Angeles, 2014 Professor Dejan Markovic,´ Chair Dedicated radio hardware is no longer promising as it was in the past. Today, the support of diverse standards dictates more flexible solutions. Software-defined radio (SDR) provides the flexibility by replacing dedicated blocks (i.e. ASICs) with more general processors to adapt to various functions, standards and even allow mutable de- sign changes. However, such replacement generally incurs significant efficiency loss in circuits, hindering its feasibility for energy-constrained devices. The capability of dy- namic and blind spectrum analysis, as featured in the cognitive radio (CR) technology, makes chip implementation even more challenging. This work discusses several design techniques to achieve near-ASIC energy effi- ciency while providing the flexibility required by software-defined and cognitive radios. The algorithm-architecture co-design is used to determine domain-specific dataflow ii structures to achieve the right balance between energy efficiency and flexibility. The flexible instruction-set-architecture (ISA), the multi-scale interconnects, and the multi- core dynamic scheduling are also proposed to reduce the energy overhead. We demon- strate these concepts on two real-time blind classification chips for CR spectrum anal- ysis, as well as a 16-core processor for baseband SDR signal processing. -

Drivers for Windows Compressed Modes User’S Guide
Drivers for Windows Compressed Modes User’s Guide Version 2.1 NVIDIA Corporation October 24, 2002 NVIDIA Drivers Compressed Modes User’s Guide Version 2.1 Published by NVIDIA Corporation 2701 San Tomas Expressway Santa Clara, CA 95050 Copyright © 2002 NVIDIA Corporation. All rights reserved. This software may not, in whole or in part, be copied through any means, mechanical, electromechanical, or otherwise, without the express permission of NVIDIA Corporation. Information furnished is believed to be accurate and reliable. However, NVIDIA assumes no responsibility for the consequences of use of such information nor for any infringement of patents or other rights of third parties, which may result from its use. No License is granted by implication or otherwise under any patent or patent rights of NVIDIA Corporation. Specifications mentioned in the software are subject to change without notice. NVIDIA Corporation products are not authorized for use as critical components in life support devices or systems without express written approval of NVIDIA Corporation. NVIDIA, the NVIDIA logo, GeForce, GeForce2 Ultra, GeForce2 MX, GeForce2 GTS, GeForce 256, GeForce3, Quadro2, NVIDIA Quadro2, Quadro2 Pro, Quadro2 MXR, Quadro, NVIDIA Quadro, Vanta, NVIDIA Vanta, TNT2, NVIDIA TNT2, TNT, NVIDIA TNT, RIVA, NVIDIA RIVA, NVIDIA RIVA 128ZX, and NVIDIA RIVA 128 are registered trademarks or trademarks of NVIDIA Corporation in the United States and/or other countries. Intel and Pentium are registered trademarks of Intel. Microsoft, Windows, Windows NT, Direct3D, DirectDraw, and DirectX are registered trademarks of Microsoft Corporation. CDRS is a trademark and Pro/ENGINEER is a registered trademark of Parametric Technology Corporation. OpenGL is a registered trademark of Silicon Graphics Inc. -

1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27
Case M:07-cv-01826-WHA Document 249 Filed 11/08/2007 Page 1 of 34 1 BOIES, SCHILLER & FLEXNER LLP WILLIAM A. ISAACSON (pro hac vice) 2 5301 Wisconsin Ave. NW, Suite 800 Washington, D.C. 20015 3 Telephone: (202) 237-2727 Facsimile: (202) 237-6131 4 Email: [email protected] 5 6 BOIES, SCHILLER & FLEXNER LLP BOIES, SCHILLER & FLEXNER LLP JOHN F. COVE, JR. (CA Bar No. 212213) PHILIP J. IOVIENO (pro hac vice) 7 DAVID W. SHAPIRO (CA Bar No. 219265) ANNE M. NARDACCI (pro hac vice) KEVIN J. BARRY (CA Bar No. 229748) 10 North Pearl Street 8 1999 Harrison St., Suite 900 4th Floor Oakland, CA 94612 Albany, NY 12207 9 Telephone: (510) 874-1000 Telephone: (518) 434-0600 Facsimile: (510) 874-1460 Facsimile: (518) 434-0665 10 Email: [email protected] Email: [email protected] [email protected] [email protected] 11 [email protected] 12 Attorneys for Plaintiff Jordan Walker Interim Class Counsel for Direct Purchaser 13 Plaintiffs 14 15 UNITED STATES DISTRICT COURT 16 NORTHERN DISTRICT OF CALIFORNIA 17 18 IN RE GRAPHICS PROCESSING UNITS ) Case No.: M:07-CV-01826-WHA ANTITRUST LITIGATION ) 19 ) MDL No. 1826 ) 20 This Document Relates to: ) THIRD CONSOLIDATED AND ALL DIRECT PURCHASER ACTIONS ) AMENDED CLASS ACTION 21 ) COMPLAINT FOR VIOLATION OF ) SECTION 1 OF THE SHERMAN ACT, 15 22 ) U.S.C. § 1 23 ) ) 24 ) ) JURY TRIAL DEMANDED 25 ) ) 26 ) ) 27 ) 28 THIRD CONSOLIDATED AND AMENDED CLASS ACTION COMPLAINT BY DIRECT PURCHASERS M:07-CV-01826-WHA Case M:07-cv-01826-WHA Document 249 Filed 11/08/2007 Page 2 of 34 1 Plaintiffs Jordan Walker, Michael Bensignor, d/b/a Mike’s Computer Services, Fred 2 Williams, and Karol Juskiewicz, on behalf of themselves and all others similarly situated in the 3 United States, bring this action for damages and injunctive relief under the federal antitrust laws 4 against Defendants named herein, demanding trial by jury, and complaining and alleging as 5 follows: 6 NATURE OF THE CASE 7 1. -

In5050 – Gpu & Cuda
IN5050 – GPU & CUDA Håkon Kvale Stensland Simula Research Laboratory / Department for Informatics PC Graphics Timeline § Challenges: − Render infinitely complex scenes − And extremely high resolution − In 1/60th of one second (60 frames per second) § Graphics hardware has evolved from a simple hardwired pipeline to a highly programmable multiword processor DirectX 6 DirectX 7 DirectX 8 DirectX 9 DirectX 9.0c DirectX 9.0c DirectX 10 DirectX 5 Multitexturing T&L TextureStageState SM 1.x SM 2.0 SM 3.0 SM 3.0 SM 4.0 Riva 128 Riva TNT GeForce 256 GeForce 3 Cg GeForceFX GeForce 6 GeForce 7 GeForce 8 1998 1999 2000 2001 2002 2003 2004 2005 2006 University of Oslo IN5050, Pål Halvorsen, Carsten Griwodz, Håkon Stensland GPU – Graphics Processing Units University of Oslo IN5050, Pål Halvorsen, Carsten Griwodz, Håkon Stensland Basic 3D Graphics Pipeline Application Host Scene Management Geometry Rasterization GPU Frame Pixel Processing Buffer Memory ROP/FBI/Display University of Oslo IN5050, Pål Halvorsen, Carsten Griwodz, Håkon Stensland Graphics in the PC Architecture § PCIe (PCI Express) Between processor and chipset − Memory Control now integrated in CPU § The old “NorthBridge” integrated onto CPU − PCI Express 4.0 x16 bandwidth at 64 GB/s (32 GB in each direction) § “SouthBridge” (X570) handles all other peripherals § Most mainstream CPUs now come with integrated GPU − Same capabilities as discrete GPU’s − Less performance (limited by die space and power) AMD «Raven Ridge» Zen+ APU University of Oslo IN5050, Pål Halvorsen, Carsten Griwodz, Håkon Stensland High-end «Graphics» Hardware § nVIDIA Ampere Architecture § The latest generation GPU, codenamed A100 § 54,2 billion transistors § 6912 Processing cores (SP) − Mixed precision − Dedicated Tensor cores − PCI Express 4.0 − NVLink interconnect Tesla V100 − Hardware support for preemption. -

Programming Graphics Hardware Overview of the Tutorial: Afternoon
Tutorial 5 ProgrammingProgramming GraphicsGraphics HardwareHardware Randy Fernando, Mark Harris, Matthias Wloka, Cyril Zeller Overview of the Tutorial: Morning 8:30 Introduction to the Hardware Graphics Pipeline Cyril Zeller 9:30 Controlling the GPU from the CPU: the 3D API Cyril Zeller 10:15 Break 10:45 Programming the GPU: High-level Shading Languages Randy Fernando 12:00 Lunch Tutorial 5: Programming Graphics Hardware Overview of the Tutorial: Afternoon 12:00 Lunch 14:00 Optimizing the Graphics Pipeline Matthias Wloka 14:45 Advanced Rendering Techniques Matthias Wloka 15:45 Break 16:15 General-Purpose Computation Using Graphics Hardware Mark Harris 17:30 End Tutorial 5: Programming Graphics Hardware Tutorial 5: Programming Graphics Hardware IntroductionIntroduction toto thethe HardwareHardware GraphicsGraphics PipelinePipeline Cyril Zeller Overview Concepts: Real-time rendering Hardware graphics pipeline Evolution of the PC hardware graphics pipeline: 1995-1998: Texture mapping and z-buffer 1998: Multitexturing 1999-2000: Transform and lighting 2001: Programmable vertex shader 2002-2003: Programmable pixel shader 2004: Shader model 3.0 and 64-bit color support PC graphics software architecture Performance numbers Tutorial 5: Programming Graphics Hardware Real-Time Rendering Graphics hardware enables real-time rendering Real-time means display rate at more than 10 images per second 3D Scene = Image = Collection of Array of pixels 3D primitives (triangles, lines, points) Tutorial 5: Programming Graphics Hardware Hardware Graphics Pipeline -

GPU-Based Deep Learning Inference
Whitepaper GPU-Based Deep Learning Inference: A Performance and Power Analysis November 2015 1 Contents Abstract ......................................................................................................................................................... 3 Introduction .................................................................................................................................................. 3 Inference versus Training .............................................................................................................................. 4 GPUs Excel at Neural Network Inference ..................................................................................................... 5 Inference Optimizations in Caffe and cuDNN 4 ........................................................................................ 5 Experimental Setup and Testing Methodology ........................................................................................ 7 Inference on Small and Large GPUs .......................................................................................................... 8 Conclusion ................................................................................................................................................... 10 References .................................................................................................................................................. 10 2 Abstract Deep learning methods are revolutionizing various areas of machine perception. On a -
![Arxiv:1809.03668V2 [Cs.LG] 20 Jan 2019 17, 20, 21]](https://docslib.b-cdn.net/cover/1376/arxiv-1809-03668v2-cs-lg-20-jan-2019-17-20-21-481376.webp)
Arxiv:1809.03668V2 [Cs.LG] 20 Jan 2019 17, 20, 21]
Comparing Computing Platforms for Deep Learning on a Humanoid Robot Alexander Biddulph∗, Trent Houliston, Alexandre Mendes, and Stephan K. Chalup School of Electrical Engineering and Computing The University of Newcastle, Callaghan, NSW, 2308, Australia. [email protected] Abstract. The goal of this study is to test two different computing plat- forms with respect to their suitability for running deep networks as part of a humanoid robot software system. One of the platforms is the CPU- centered Intel R NUC7i7BNH and the other is a NVIDIA R Jetson TX2 system that puts more emphasis on GPU processing. The experiments addressed a number of benchmarking tasks including pedestrian detec- tion using deep neural networks. Some of the results were unexpected but demonstrate that platforms exhibit both advantages and disadvantages when taking computational performance and electrical power require- ments of such a system into account. Keywords: deep learning, robot vision, gpu computing, low powered devices 1 Introduction Deep learning comes with challenges with respect to computational resources and training data requirements [6, 13]. Some of the breakthroughs in deep neu- ral networks (DNNs) only became possible through the availability of massive computing systems or through careful co-design of software and hardware. For example, the AlexNet system presented in [15] was implemented efficiently util- ising two NVIDIA R GTX580 GPUs for training. Machine learning on robots has been a growing area over the past years [4, arXiv:1809.03668v2 [cs.LG] 20 Jan 2019 17, 20, 21]. It has become increasingly desirable to employ DNNs in low powered devices, among them humanoid robot systems, specifically for complex tasks such as object detection, walk learning, and behaviour learning. -

4010, 237 8514, 226 80486, 280 82786, 227, 280 a AA. See Anti-Aliasing (AA) Abacus, 16 Accelerated Graphics Port (AGP), 219 Acce
Index 4010, 237 AIB. See Add-in board (AIB) 8514, 226 Air traffic control system, 303 80486, 280 Akeley, Kurt, 242 82786, 227, 280 Akkadian, 16 Algebra, 26 Alias Research, 169 Alienware, 186 A Alioscopy, 389 AA. See Anti-aliasing (AA) All-In-One computer, 352 Abacus, 16 All-points addressable (APA), 221 Accelerated Graphics Port (AGP), 219 Alpha channel, 328 AccelGraphics, 166, 273 Alpha Processor, 164 Accel-KKR, 170 ALT-256, 223 ACM. See Association for Computing Altair 680b, 181 Machinery (ACM) Alto, 158 Acorn, 156 AMD, 232, 257, 277, 410, 411 ACRTC. See Advanced CRT Controller AMD 2901 bit-slice, 318 (ACRTC) American national Standards Institute (ANSI), ACS, 158 239 Action Graphics, 164, 273 Anaglyph, 376 Acumos, 253 Anaglyph glasses, 385 A.D., 15 Analog computer, 140 Adage, 315 Anamorphic distortion, 377 Adage AGT-30, 317 Anatomic and Symbolic Mapper Engine Adams Associates, 102 (ASME), 110 Adams, Charles W., 81, 148 Anderson, Bob, 321 Add-in board (AIB), 217, 363 AN/FSQ-7, 302 Additive color, 328 Anisotropic filtering (AF), 65 Adobe, 280 ANSI. See American national Standards Adobe RGB, 328 Institute (ANSI) Advanced CRT Controller (ACRTC), 226 Anti-aliasing (AA), 63 Advanced Remote Display Station (ARDS), ANTIC graphics co-processor, 279 322 Antikythera device, 127 Advanced Visual Systems (AVS), 164 APA. See All-points addressable (APA) AED 512, 333 Apalatequi, 42 AF. See Anisotropic filtering (AF) Aperture grille, 326 AGP. See Accelerated Graphics Port (AGP) API. See Application program interface Ahiska, Yavuz, 260 standard (API) AI. -
Shippensburg University Investment Management Program
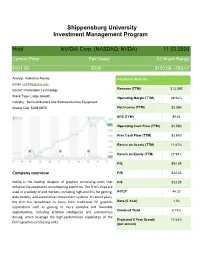
Shippensburg University Investment Management Program Hold NVIDIA Corp. (NASDAQ: NVDA) 11.03.2020 Current Price Fair Value 52 Week Range $501.36 $300 $180.68 - 589.07 Analyst: Valentina Alonso Key Stock Statistics Email: [email protected] Sector: Information Technology Revenue (TTM) $13.06B Stock Type: Large Growth Operating Margin (TTM) 28.56% Industry: Semiconductors and Semiconductors Equipment Market Cap: $309.697B Net Income (TTM) $3.39B EPS (TTM) $5.44 Operating Cash Flow (TTM) $5.58B Free Cash Flow (TTM) $3.67B Return on Assets (TTM) 11.67% Return on Equity (TTM) 27.94% P/E $92.59 Company overview P/B $22.32 Nvidia is the leading designer of graphics processing units that P/S $23.29 enhance the experience on computing platforms. The firm's chips are used in a variety of end markets, including high-end PCs for gaming, P/FCF 44.22 data centers, and automotive infotainment systems. In recent years, the firm has broadened its focus from traditional PC graphics Beta (5-Year) 1.54 applications such as gaming to more complex and favorable Dividend Yield 0.13% opportunities, including artificial intelligence and autonomous driving, which leverage the high-performance capabilities of the Projected 5 Year Growth 17.44% firm's graphics processing units. (per annum) Contents Executive Summary ....................................................................................................................................................3 Company Overview ....................................................................................................................................................4 -

Numerical Behavior of NVIDIA Tensor Cores
Numerical behavior of NVIDIA tensor cores Massimiliano Fasi1, Nicholas J. Higham2, Mantas Mikaitis2 and Srikara Pranesh2 1 School of Science and Technology, Örebro University, Örebro, Sweden 2 Department of Mathematics, University of Manchester, Manchester, UK ABSTRACT We explore the floating-point arithmetic implemented in the NVIDIA tensor cores, which are hardware accelerators for mixed-precision matrix multiplication available on the Volta, Turing, and Ampere microarchitectures. Using Volta V100, Turing T4, and Ampere A100 graphics cards, we determine what precision is used for the intermediate results, whether subnormal numbers are supported, what rounding mode is used, in which order the operations underlying the matrix multiplication are performed, and whether partial sums are normalized. These aspects are not documented by NVIDIA, and we gain insight by running carefully designed numerical experiments on these hardware units. Knowing the answers to these questions is important if one wishes to: (1) accurately simulate NVIDIA tensor cores on conventional hardware; (2) understand the differences between results produced by code that utilizes tensor cores and code that uses only IEEE 754-compliant arithmetic operations; and (3) build custom hardware whose behavior matches that of NVIDIA tensor cores. As part of this work we provide a test suite that can be easily adapted to test newer versions of the NVIDIA tensorcoresaswellassimilaracceleratorsfromothervendors,astheybecome available. Moreover, we identify a non-monotonicity issue -

Manycore GPU Architectures and Programming, Part 1
Lecture 19: Manycore GPU Architectures and Programming, Part 1 Concurrent and Mul=core Programming CSE 436/536, [email protected] www.secs.oakland.edu/~yan 1 Topics (Part 2) • Parallel architectures and hardware – Parallel computer architectures – Memory hierarchy and cache coherency • Manycore GPU architectures and programming – GPUs architectures – CUDA programming – Introduc?on to offloading model in OpenMP and OpenACC • Programming on large scale systems (Chapter 6) – MPI (point to point and collec=ves) – Introduc?on to PGAS languages, UPC and Chapel • Parallel algorithms (Chapter 8,9 &10) – Dense matrix, and sorng 2 Manycore GPU Architectures and Programming: Outline • Introduc?on – GPU architectures, GPGPUs, and CUDA • GPU Execuon model • CUDA Programming model • Working with Memory in CUDA – Global memory, shared and constant memory • Streams and concurrency • CUDA instruc?on intrinsic and library • Performance, profiling, debugging, and error handling • Direc?ve-based high-level programming model – OpenACC and OpenMP 3 Computer Graphics GPU: Graphics Processing Unit 4 Graphics Processing Unit (GPU) Image: h[p://www.ntu.edu.sg/home/ehchua/programming/opengl/CG_BasicsTheory.html 5 Graphics Processing Unit (GPU) • Enriching user visual experience • Delivering energy-efficient compung • Unlocking poten?als of complex apps • Enabling Deeper scien?fic discovery 6 What is GPU Today? • It is a processor op?mized for 2D/3D graphics, video, visual compu?ng, and display. • It is highly parallel, highly multhreaded mulprocessor op?mized for visual -

COM Express® + GPU Embedded System (VXG/DXG)
COM Express® + GPU Embedded System (VXG/DXG) VXG Series DXG Series Connect Tech Inc. Tel: 519-836-1291 42 Arrow Road Toll: 800-426-8979 (North America only) Guelph, Ontario Fax: 519-836-4878 N1K 1S6 Email: [email protected] www.connecttech.com [email protected] CTIM-00409 Revision 0.12 2018-03-16 COM Express® + GPU Embedded System (VXG/DXG) Users Guide www.connecttech.com Table of Contents Preface ................................................................................................................................................... 4 Disclaimer ....................................................................................................................................................... 4 Customer Support Overview ........................................................................................................................... 4 Contact Information ........................................................................................................................................ 4 One Year Limited Warranty ............................................................................................................................ 5 Copyright Notice ............................................................................................................................................. 5 Trademark Acknowledgment .......................................................................................................................... 5 ESD Warning .................................................................................................................................................