The World Wide Web
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
Web Content Analysis
Web Content Analysis Workshop in Advanced Techniques for Political Communication Research: Web Content Analysis Session Professor Rachel Gibson, University of Manchester Aims of the Session • Defining and understanding the Web as on object of study & challenges to analysing web content • Defining the shift from Web 1.0 to Web 2.0 or ‘social media’ • Approaches to analysing web content, particularly in relation to election campaign research and party homepages. • Beyond websites? Examples of how web 2.0 campaigns are being studied – key research questions and methodologies. The Web as an object of study • Inter-linkage • Non-linearity • Interactivity • Multi-media • Global reach • Ephemerality Mitra, A and Cohen, E. ‘Analyzing the Web: Directions and Challenges’ in Jones, S. (ed) Doing Internet Research 1999 Sage From Web 1.0 to Web 2.0 Tim Berners-Lee “Web 1.0 was all about connecting people. It was an interactive space, and I think Web 2.0 is of course a piece of jargon, nobody even knows what it means. If Web 2.0 for you is blogs and wikis, then that is people to people. But that was what the Web was supposed to be all along. And in fact you know, this ‘Web 2.0’, it means using the standards which have been produced by all these people working on Web 1.0,” (from Anderson, 2007: 5) Web 1.0 The “read only” web Web 2.0 – ‘What is Web 2.0’ Tim O’Reilly (2005) “The “read/write” web Web 2.0 • Technological definition – Web as platform, supplanting desktop pc – Inter-operability , through browser access a wide range of programmes that fulfil a variety of online tasks – i.e. -

The Origins of the Underline As Visual Representation of the Hyperlink on the Web: a Case Study in Skeuomorphism
The Origins of the Underline as Visual Representation of the Hyperlink on the Web: A Case Study in Skeuomorphism The Harvard community has made this article openly available. Please share how this access benefits you. Your story matters Citation Romano, John J. 2016. The Origins of the Underline as Visual Representation of the Hyperlink on the Web: A Case Study in Skeuomorphism. Master's thesis, Harvard Extension School. Citable link http://nrs.harvard.edu/urn-3:HUL.InstRepos:33797379 Terms of Use This article was downloaded from Harvard University’s DASH repository, and is made available under the terms and conditions applicable to Other Posted Material, as set forth at http:// nrs.harvard.edu/urn-3:HUL.InstRepos:dash.current.terms-of- use#LAA The Origins of the Underline as Visual Representation of the Hyperlink on the Web: A Case Study in Skeuomorphism John J Romano A Thesis in the Field of Visual Arts for the Degree of Master of Liberal Arts in Extension Studies Harvard University November 2016 Abstract This thesis investigates the process by which the underline came to be used as the default signifier of hyperlinks on the World Wide Web. Created in 1990 by Tim Berners- Lee, the web quickly became the most used hypertext system in the world, and most browsers default to indicating hyperlinks with an underline. To answer the question of why the underline was chosen over competing demarcation techniques, the thesis applies the methods of history of technology and sociology of technology. Before the invention of the web, the underline–also known as the vinculum–was used in many contexts in writing systems; collecting entities together to form a whole and ascribing additional meaning to the content. -

To Make Claims About Or Even Adequately Understand the "True Nature" of Organizations Or Leadership Is a Monumental Task
BooK REvrnw: HERE CoMES EVERYBODY: THE PowER OF ORGANIZING WITHOUT ORGANIZATIONS (Clay Shirky, Penguin Press, 2008. Hardback, $25.95] -CHRIS FRANCOVICH GONZAGA UNIVERSITY To make claims about or even adequately understand the "true nature" of organizations or leadership is a monumental task. To peer into the nature of the future of these complex phenomena is an even more daunting project. In this book, however, I think we have both a plausible interpretation of organ ization ( and by implication leadership) and a rare glimpse into what we are becoming by virtue of our information technology. We live in a complex, dynamic, and contingent environment whose very nature makes attributing cause and effect, meaning, or even useful generalizations very difficult. It is probably not too much to say that historically the ability to both access and frame information was held by the relatively few in a system and structure whose evolution is, in its own right, a compelling story. Clay Shirky is in the enviable position of inhabiting the domain of the technological elite, as well as being a participant and a pioneer in the social revolution that is occurring partly because of the technologies and tools invented by that elite. As information, communication, and organization have grown in scale, many of our scientific, administrative, and "leader-like" responses unfortu nately have remained the same. We find an analogous lack of appropriate response in many followers as evidenced by large group effects manifested through, for example, the response to advertising. However, even that herd like consumer behavior seems to be changing. Markets in every domain are fragmenting. -

Build Lightning Fast Web Apps with HTML5 and SAS® Allan Bowe, SAS Consultant
1091-2017 Build Lightning Fast Web Apps with HTML5 and SAS® Allan Bowe, SAS consultant ABSTRACT What do we want? Web applications! When do we want them? Well.. Why not today? This author argues that the key to delivering web apps ‘lightning fast’ can be boiled down to a few simple factors, such as: • Standing on the shoulders (not the toes) of giants. Specifically, learning and leveraging the power of free / open source toolsets such as Google’s Angular, Facebook’s React.js and Twitter Bootstrap • Creating ‘copy paste’ templates for web apps that can be quickly re-used and tweaked for new purposes • Using the right tools for the job (and being familiar with them) By choosing SAS as the back end, your apps will benefit from: • Full blown analytics platform • Access to all kinds of company data • Full SAS metadata security (every server request is metadata validated) By following the approach taken in this paper, you may well find yourself in possession of an electrifying capability to deliver great content and professional-looking web apps faster than one can say “Usain Bolt”. AUDIENCE This paper is aimed at a rare breed of SAS developer – one with both front end (HTML / Javascript) and platform administration (EBI) experience. If you can describe the object of object arrays, the object spawner and the Document Object Model – then this paper is (objectionably?) for you! INTRODUCTION You are about to receive a comprehensive overview of building Enterprise Grade web applications with SAS. Such a framework will enable you to build hitherto unimaginable things. -

Rdfa in XHTML: Syntax and Processing Rdfa in XHTML: Syntax and Processing
RDFa in XHTML: Syntax and Processing RDFa in XHTML: Syntax and Processing RDFa in XHTML: Syntax and Processing A collection of attributes and processing rules for extending XHTML to support RDF W3C Recommendation 14 October 2008 This version: http://www.w3.org/TR/2008/REC-rdfa-syntax-20081014 Latest version: http://www.w3.org/TR/rdfa-syntax Previous version: http://www.w3.org/TR/2008/PR-rdfa-syntax-20080904 Diff from previous version: rdfa-syntax-diff.html Editors: Ben Adida, Creative Commons [email protected] Mark Birbeck, webBackplane [email protected] Shane McCarron, Applied Testing and Technology, Inc. [email protected] Steven Pemberton, CWI Please refer to the errata for this document, which may include some normative corrections. This document is also available in these non-normative formats: PostScript version, PDF version, ZIP archive, and Gzip’d TAR archive. The English version of this specification is the only normative version. Non-normative translations may also be available. Copyright © 2007-2008 W3C® (MIT, ERCIM, Keio), All Rights Reserved. W3C liability, trademark and document use rules apply. Abstract The current Web is primarily made up of an enormous number of documents that have been created using HTML. These documents contain significant amounts of structured data, which is largely unavailable to tools and applications. When publishers can express this data more completely, and when tools can read it, a new world of user functionality becomes available, letting users transfer structured data between applications and web sites, and allowing browsing applications to improve the user experience: an event on a web page can be directly imported - 1 - How to Read this Document RDFa in XHTML: Syntax and Processing into a user’s desktop calendar; a license on a document can be detected so that users can be informed of their rights automatically; a photo’s creator, camera setting information, resolution, location and topic can be published as easily as the original photo itself, enabling structured search and sharing. -

Hypertext Semiotics in the Commercialized Internet
Hypertext Semiotics in the Commercialized Internet Moritz Neumüller Wien, Oktober 2001 DOKTORAT DER SOZIAL- UND WIRTSCHAFTSWISSENSCHAFTEN 1. Beurteiler: Univ. Prof. Dipl.-Ing. Dr. Wolfgang Panny, Institut für Informationsver- arbeitung und Informationswirtschaft der Wirtschaftsuniversität Wien, Abteilung für Angewandte Informatik. 2. Beurteiler: Univ. Prof. Dr. Herbert Hrachovec, Institut für Philosophie der Universität Wien. Betreuer: Gastprofessor Univ. Doz. Dipl.-Ing. Dr. Veith Risak Eingereicht am: Hypertext Semiotics in the Commercialized Internet Dissertation zur Erlangung des akademischen Grades eines Doktors der Sozial- und Wirtschaftswissenschaften an der Wirtschaftsuniversität Wien eingereicht bei 1. Beurteiler: Univ. Prof. Dr. Wolfgang Panny, Institut für Informationsverarbeitung und Informationswirtschaft der Wirtschaftsuniversität Wien, Abteilung für Angewandte Informatik 2. Beurteiler: Univ. Prof. Dr. Herbert Hrachovec, Institut für Philosophie der Universität Wien Betreuer: Gastprofessor Univ. Doz. Dipl.-Ing. Dr. Veith Risak Fachgebiet: Informationswirtschaft von MMag. Moritz Neumüller Wien, im Oktober 2001 Ich versichere: 1. daß ich die Dissertation selbständig verfaßt, andere als die angegebenen Quellen und Hilfsmittel nicht benutzt und mich auch sonst keiner unerlaubten Hilfe bedient habe. 2. daß ich diese Dissertation bisher weder im In- noch im Ausland (einer Beurteilerin / einem Beurteiler zur Begutachtung) in irgendeiner Form als Prüfungsarbeit vorgelegt habe. 3. daß dieses Exemplar mit der beurteilten Arbeit überein -
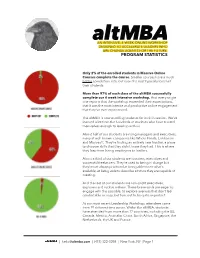
Program Statistics
AN INTENSIVE, 4-WEEK ONLINE WORKSHOP DESIGNED TO ACCELERATE LEADERS WHO ARE CHANGE AGENTS FOR THE FUTURE. PROGRAM STATISTICS Only 2% of the enrolled students in Massive Online Courses complete the course. Smaller courses have a much better completion rate, but even the best typically lose half their students. More than 97% of each class of the altMBA successfully complete our 4 week intensive workshop. And every single one reports that the workshop exceeded their expectations, that it was the most intense and productive online engagement that they’ve ever experienced. The altMBA is now enrolling students for its fifth session. We’ve learned a lot from the hundreds of students who have trusted themselves enough to level up with us. About half of our students are rising managers and executives, many at well-known companies like Whole Foods, Lululemon and Microsoft. They’re finding an entirely new frontier, a place to discover skills that they didn’t know they had. This is where they leap from being employees to leaders. About a third of our students are founders, executives and successful freelancers. They’re used to being in charge but they’re not always practiced at being able to see what’s available, at being able to describe a future they are capable of creating. And the rest of our students are non-profit executives, explorers and ruckus makers. These brave souls are eager to engage with the possible, to explore avenues that don’t feel comfortable or easy, but turn out to be quite important. At our most recent Leadership Workshop, attendees came from 19 different time zones. -

Systems Administrator
SYSTEMS ADMINISTRATOR SUMMARY The System Administrator’s role is to manage in-house computer software systems, servers, storage devices and network connections to ensure high availability and security of the supported business applications. This individual also participates in the planning and implementation of policies and procedures to ensure system provisioning and maintenance that is consistent with company goals, industry best practices, and regulatory requirements. ESSENTIAL DUTIES AND RESPONSIBILITIES: The Authority’s Senior Systems Manager may designate various other activities. The following statements are intended to describe the general nature and level of work being performed. They are not intended to be construed, as an exhaustive list of all responsibilities, duties and skills required of personnel so classified. Nothing in this job description restricts management's right to assign or reassign duties and responsibilities to this job at any time for any reason, including reasonable accommodation. Operational Management Manage virtual and physical servers with Windows Server 2003 – 2012 R2 and RHEL operating systems Manage Active Directory, Microsoft Office 365, and server and workstation patching with SCCM Manage the physical and virtual environment (VMware) of 300 plus servers Have familiarity with MS SQL server, windows clustering, domain controller setup, and group policy Ensure the security of the server infrastructure by implementing industry best-practices regarding privacy, security, and regulatory compliance. Develop and maintain documentation about current environment setup, standard operating procedures, and best practices. Manage end user accounts, permissions, access rights, and storage allocations in accordance with best- practices Perform and test routine system backups and restores. Anticipate, mitigate, identify, troubleshoot, and correct hardware and software issues on servers, and workstations. -

Webbrowser Webpages
Web Browser A web browser, or simply "browser," is an application used to access and view websites. Common web browsers include Microsoft Internet Explorer, Google Chrome, Mozilla Firefox, and Apple Safari. The primary function of a web browser is to render HTML, the code used to design or "markup" web pages. Each time a browser loads a web page, it processes the HTML, which may include text, links, and references to images and other items, such as cascading style sheets and JavaScript functions. The browser processes these items, then renders them in the browser window. Early web browsers, such as Mosaic and Netscape Navigator, were simple applications that rendered HTML, processed form input, and supported bookmarks. As websites have evolved, so have web browser requirements. Today's browsers are far more advanced, supporting multiple types of HTML (such as XHTML and HTML 5), dynamic JavaScript, and encryption used by secure websites. The capabilities of modern web browsers allow web developers to create highly interactive websites. For example, Ajax enables a browser to dynamically update information on a webpage without the need to reload the page. Advances in CSS allow browsers to display a responsive website layouts and a wide array of visual effects. Cookies allow browsers to remember your settings for specific websites. While web browser technology has come a long way since Netscape, browser compatibility issues remain a problem. Since browsers use different rendering engines, websites may not appear the same across multiple browsers. In some cases, a website may work fine in one browser, but not function properly in another. -

How to Page a Document in Microsoft Word
1 HOW TO PAGE A DOCUMENT IN MICROSOFT WORD 1– PAGING A WHOLE DOCUMENT FROM 1 TO …Z (Including the first page) 1.1 – Arabic Numbers (a) Click the “Insert” tab. (b) Go to the “Header & Footer” Section and click on “Page Number” drop down menu (c) Choose the location on the page where you want the page to appear (i.e. top page, bottom page, etc.) (d) Once you have clicked on the “box” of your preference, the pages will be inserted automatically on each page, starting from page 1 on. 1.2 – Other Formats (Romans, letters, etc) (a) Repeat steps (a) to (c) from 1.1 above (b) At the “Header & Footer” Section, click on “Page Number” drop down menu. (C) Choose… “Format Page Numbers” (d) At the top of the box, “Number format”, click the drop down menu and choose your preference (i, ii, iii; OR a, b, c, OR A, B, C,…and etc.) an click OK. (e) You can also set it to start with any of the intermediate numbers if you want at the “Page Numbering”, “Start at” option within that box. 2 – TITLE PAGE WITHOUT A PAGE NUMBER…….. Option A – …And second page being page number 2 (a) Click the “Insert” tab. (b) Go to the “Header & Footer” Section and click on “Page Number” drop down menu (c) Choose the location on the page where you want the page to appear (i.e. top page, bottom page, etc.) (d) Once you have clicked on the “box” of your preference, the pages will be inserted automatically on each page, starting from page 1 on. -

Ted Nelson History of Computing
History of Computing Douglas R. Dechow Daniele C. Struppa Editors Intertwingled The Work and Influence of Ted Nelson History of Computing Founding Editor Martin Campbell-Kelly, University of Warwick, Coventry, UK Series Editor Gerard Alberts, University of Amsterdam, Amsterdam, The Netherlands Advisory Board Jack Copeland, University of Canterbury, Christchurch, New Zealand Ulf Hashagen, Deutsches Museum, Munich, Germany John V. Tucker, Swansea University, Swansea, UK Jeffrey R. Yost, University of Minnesota, Minneapolis, USA The History of Computing series publishes high-quality books which address the history of computing, with an emphasis on the ‘externalist’ view of this history, more accessible to a wider audience. The series examines content and history from four main quadrants: the history of relevant technologies, the history of the core science, the history of relevant business and economic developments, and the history of computing as it pertains to social history and societal developments. Titles can span a variety of product types, including but not exclusively, themed volumes, biographies, ‘profi le’ books (with brief biographies of a number of key people), expansions of workshop proceedings, general readers, scholarly expositions, titles used as ancillary textbooks, revivals and new editions of previous worthy titles. These books will appeal, varyingly, to academics and students in computer science, history, mathematics, business and technology studies. Some titles will also directly appeal to professionals and practitioners -

Dewarpnet: Single-Image Document Unwarping with Stacked 3D and 2D Regression Networks
DewarpNet: Single-Image Document Unwarping With Stacked 3D and 2D Regression Networks Sagnik Das∗ Ke Ma∗ Zhixin Shu Dimitris Samaras Roy Shilkrot Stony Brook University fsadas, kemma, zhshu, samaras, [email protected] Abstract Capturing document images with hand-held devices in unstructured environments is a common practice nowadays. However, “casual” photos of documents are usually unsuit- able for automatic information extraction, mainly due to physical distortion of the document paper, as well as var- ious camera positions and illumination conditions. In this work, we propose DewarpNet, a deep-learning approach for document image unwarping from a single image. Our insight is that the 3D geometry of the document not only determines the warping of its texture but also causes the il- lumination effects. Therefore, our novelty resides on the ex- plicit modeling of 3D shape for document paper in an end- to-end pipeline. Also, we contribute the largest and most comprehensive dataset for document image unwarping to date – Doc3D. This dataset features multiple ground-truth annotations, including 3D shape, surface normals, UV map, Figure 1. Document image unwarping. Top row: input images. albedo image, etc. Training with Doc3D, we demonstrate Middle row: predicted 3D coordinate maps. Bottom row: pre- state-of-the-art performance for DewarpNet with extensive dicted unwarped images. Columns from left to right: 1) curled, qualitative and quantitative evaluations. Our network also 2) one-fold, 3) two-fold, 4) multiple-fold with OCR confidence significantly improves OCR performance on captured doc- highlights in Red (low) to Blue (high). ument images, decreasing character error rate by 42% on average.