Concurrency Control 3
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Smart Methods for Retrieving Physiological Data in Physiqual
University of Groningen Bachelor thesis Smart methods for retrieving physiological data in Physiqual Marc Babtist & Sebastian Wehkamp Supervisors: Frank Blaauw & Marco Aiello July, 2016 Contents 1 Introduction 4 1.1 Physiqual . 4 1.2 Problem description . 4 1.3 Research questions . 5 1.4 Document structure . 5 2 Related work 5 2.1 IJkdijk project . 5 2.2 MUMPS . 6 3 Background 7 3.1 Scalability . 7 3.2 CAP theorem . 7 3.3 Reliability models . 7 4 Requirements 8 4.1 Scalability . 8 4.2 Reliability . 9 4.3 Performance . 9 4.4 Open source . 9 5 General database options 9 5.1 Relational or Non-relational . 9 5.2 NoSQL categories . 10 5.2.1 Key-value Stores . 10 5.2.2 Document Stores . 11 5.2.3 Column Family Stores . 11 5.2.4 Graph Stores . 12 5.3 When to use which category . 12 5.4 Conclusion . 12 5.4.1 Key-Value . 13 5.4.2 Document stores . 13 5.4.3 Column family stores . 13 5.4.4 Graph Stores . 13 6 Specific database options 13 6.1 Key-value stores: Riak . 14 6.2 Document stores: MongoDB . 14 6.3 Column Family stores: Cassandra . 14 6.4 Performance comparison . 15 6.4.1 Sensor Data Storage Performance . 16 6.4.2 Conclusion . 16 7 Data model 17 7.1 Modeling rules . 17 7.2 Data model Design . 18 2 7.3 Summary . 18 8 Architecture 20 8.1 Basic layout . 20 8.2 Sidekiq . 21 9 Design decisions 21 9.1 Keyspaces . 21 9.2 Gap determination . -

Quantum Dxi4500 User's Guide
User’s Guide User’s Guide User’s Guide User’s Guide QuantumQuantum DXDXii45004500 DX i -Series 6-66904-01 Rev C DXi4500 User’s Guide, 6-66904-01 Rev C, August 2010, Product of USA. Quantum Corporation provides this publication “as is” without warranty of any kind, either express or implied, including but not limited to the implied warranties of merchantability or fitness for a particular purpose. Quantum Corporation may revise this publication from time to time without notice. COPYRIGHT STATEMENT © 2010 Quantum Corporation. All rights reserved. Your right to copy this manual is limited by copyright law. Making copies or adaptations without prior written authorization of Quantum Corporation is prohibited by law and constitutes a punishable violation of the law. TRADEMARK STATEMENT Quantum, the Quantum logo, DLT, DLTtape, the DLTtape logo, Scalar, and StorNext are registered trademarks of Quantum Corporation, registered in the U.S. and other countries. Backup. Recovery. Archive. It’s What We Do., the DLT logo, DLTSage, DXi, DXi-Series, Dynamic Powerdown, FastSense, FlexLink, GoVault, MediaShield, Optyon, Pocket-sized. Well-armored, SDLT, SiteCare, SmartVerify, StorageCare, Super DLTtape, SuperLoader, and Vision are trademarks of Quantum. LTO and Ultrium are trademarks of HP, IBM, and Quantum in the U.S. and other countries. All other trademarks are the property of their respective companies. Specifications are subject to change without notice. ii Quantum DXi4500 User’s Guide Contents Preface xv Chapter 1 DXi4500 System Description 1 Overview . 1 Features and Benefits . 3 Data Reduction . 3 Data Deduplication . 3 Compression. 4 Space Reclamation . 4 Remote Replication . 5 DXi4500 System . -

Replication Using Group Communication Over a Partitioned Network
Replication Using Group Communication Over a Partitioned Network Thesis submitted for the degree “Doctor of Philosophy” Yair Amir Submitted to the Senate of the Hebrew University of Jerusalem (1995). This work was carried out under the supervision of Professor Danny Dolev ii Acknowledgments I am deeply grateful to Danny Dolev, my advisor and mentor. I thank Danny for believing in my research, for spending so many hours on it, and for giving it the theoretical touch. His warm support and patient guidance helped me through. I hope I managed to adopt some of his professional attitude and integrity. I thank Daila Malki for her help during the early stages of the Transis project. Thanks to Idit Keidar for helping me sharpen some of the issues of the replication server. I enjoyed my collaboration with Ofir Amir on developing the coloring model of the replication server. Many thanks to Roman Vitenberg for his valuable insights regarding the extended virtual synchrony model and the replication algorithm. I benefited a lot from many discussions with Ahmad Khalaila regarding distributed systems and other issues. My thanks go to David Breitgand, Gregory Chokler, Yair Gofen, Nabil Huleihel and Rimon Orni, for their contribution to the Transis project and to my research. I am grateful to Michael Melliar-Smith and Louise Moser from the Department of Electrical and Computer Engineering, University of California, Santa Barbara. During two summers, several mutual visits and extensive electronic correspondence, Louise and Michael were involved in almost every aspect of my research, and unofficially served as my co-advisors. The work with Deb Agarwal and Paul Ciarfella on the Totem protocol contributed a lot to my understanding of high-speed group communication. -
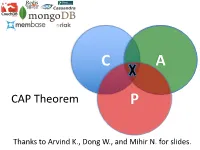
CAP Theorem P
C A CAP Theorem P Thanks to Arvind K., Dong W., and Mihir N. for slides. CAP Theorem • “It is impossible for a web service to provide these three guarantees at the same time (pick 2 of 3): • (Sequential) Consistency • Availability • Partition-tolerance” • Conjectured by Eric Brewer in ’00 • Proved by Gilbert and Lynch in ’02 • But with definitions that do not match what you’d assume (or Brewer meant) • Influenced the NoSQL mania • Highly controversial: “the CAP theorem encourages engineers to make awful decisions.” – Stonebraker • Many misinterpretations 2 CAP Theorem • Consistency: – Sequential consistency (a data item behaves as if there is one copy) • Availability: – Node failures do not prevent survivors from continuing to operate • Partition-tolerance: – The system continues to operate despite network partitions • CAP says that “A distributed system can satisfy any two of these guarantees at the same time but not all three” 3 C in CAP != C in ACID • They are different! • CAP’s C(onsistency) = sequential consistency – Similar to ACID’s A(tomicity) = Visibility to all future operations • ACID’s C(onsistency) = Does the data satisfy schema constraints 4 Sequential consistency • Makes it appear as if there is one copy of the object • Strict ordering on ops from same client • A single linear ordering across client ops – If client a executes operations {a1, a2, a3, ...}, client b executes operations {b1, b2, b3, ...} – Then, globally, clients observe some serialized version of the sequence • e.g., {a1, b1, b2, a2, ...} (or whatever) Notice -

Replication Vs. Caching Strategies for Distributed Metadata Management in Cloud Storage Systems
ShardFS vs. IndexFS: Replication vs. Caching Strategies for Distributed Metadata Management in Cloud Storage Systems Lin Xiao, Kai Ren, Qing Zheng, Garth A. Gibson Carnegie Mellon University {lxiao, kair, zhengq, garth}@cs.cmu.edu Abstract 1. Introduction The rapid growth of cloud storage systems calls for fast and Modern distributed storage systems commonly use an archi- scalable namespace processing. While few commercial file tecture that decouples metadata access from file read and systems offer anything better than federating individually write operations [21, 25, 46]. In such a file system, clients non-scalable namespace servers, a recent academic file sys- acquire permission and file location information from meta- tem, IndexFS, demonstrates scalable namespace processing data servers before accessing file contents, so slower meta- based on client caching of directory entries and permissions data service can degrade performance for the data path. Pop- (directory lookup state) with no per-client state in servers. In ular new distributed file systems such as HDFS [25] and the this paper we explore explicit replication of directory lookup first generation of the Google file system [21] have used cen- state in all servers as an alternative to caching this infor- tralized single-node metadata services and focused on scal- mation in all clients. Both eliminate most repeated RPCs to ing only the data path. However, the single-node metadata different servers in order to resolve hierarchical permission server design limits the scalability of the file system in terms tests. Our realization for server replicated directory lookup of the number of objects stored and concurrent accesses to state, ShardFS, employs a novel file system specific hybrid the file system [40]. -

Replication As a Prelude to Erasure Coding in Data-Intensive Scalable Computing
DiskReduce: Replication as a Prelude to Erasure Coding in Data-Intensive Scalable Computing Bin Fan Wittawat Tantisiriroj Lin Xiao Garth Gibson fbinfan , wtantisi , lxiao , garth.gibsong @ cs.cmu.edu CMU-PDL-11-112 October 2011 Parallel Data Laboratory Carnegie Mellon University Pittsburgh, PA 15213-3890 Acknowledgements: We would like to thank several people who made significant contributions. Robert Chansler, Raj Merchia and Hong Tang from Yahoo! provide various help. Dhruba Borthakur from Facebook provides statistics and feedback. Bin Fu and Brendan Meeder gave us their scientific applications and data-sets for experimental evaluation. The work in this paper is based on research supported in part by the Betty and Gordon Moore Foundation, by the Department of Energy, under award number DE-FC02-06ER25767, by the Los Alamos National Laboratory, by the Qatar National Research Fund, under award number NPRP 09-1116-1-172, under contract number 54515- 001-07, by the National Science Foundation under awards CCF-1019104, CCF-0964474, OCI-0852543, CNS-0546551 and SCI-0430781, and by Google and Yahoo! research awards. We also thank the members and companies of the PDL Consortium (including APC, EMC, Facebook, Google, Hewlett-Packard, Hitachi, IBM, Intel, Microsoft, NEC, NetApp, Oracle, Panasas, Riverbed, Samsung, Seagate, STEC, Symantec, and VMware) for their interest, insights, feedback, and support. Keywords: Distributed File System, RAID, Cloud Computing, DISC Abstract The first generation of Data-Intensive Scalable Computing file systems such as Google File System and Hadoop Distributed File System employed n (n ≥ 3) replications for high data reliability, therefore delivering users only about 1=n of the total storage capacity of the raw disks. -

Nosql Databases: Yearning for Disambiguation
NOSQL DATABASES: YEARNING FOR DISAMBIGUATION Chaimae Asaad Alqualsadi, Rabat IT Center, ENSIAS, University Mohammed V in Rabat and TicLab, International University of Rabat, Morocco [email protected] Karim Baïna Alqualsadi, Rabat IT Center, ENSIAS, University Mohammed V in Rabat, Morocco [email protected] Mounir Ghogho TicLab, International University of Rabat Morocco [email protected] March 17, 2020 ABSTRACT The demanding requirements of the new Big Data intensive era raised the need for flexible storage systems capable of handling huge volumes of unstructured data and of tackling the challenges that arXiv:2003.04074v2 [cs.DB] 16 Mar 2020 traditional databases were facing. NoSQL Databases, in their heterogeneity, are a powerful and diverse set of databases tailored to specific industrial and business needs. However, the lack of the- oretical background creates a lack of consensus even among experts about many NoSQL concepts, leading to ambiguity and confusion. In this paper, we present a survey of NoSQL databases and their classification by data model type. We also conduct a benchmark in order to compare different NoSQL databases and distinguish their characteristics. Additionally, we present the major areas of ambiguity and confusion around NoSQL databases and their related concepts, and attempt to disambiguate them. Keywords NoSQL Databases · NoSQL data models · NoSQL characteristics · NoSQL Classification A PREPRINT -MARCH 17, 2020 1 Introduction The proliferation of data sources ranging from social media and Internet of Things (IoT) to industrially generated data (e.g. transactions) has led to a growing demand for data intensive cloud based applications and has created new challenges for big-data-era databases. -

IBM Cloudant: Database As a Service Fundamentals
Front cover IBM Cloudant: Database as a Service Fundamentals Understand the basics of NoSQL document data stores Access and work with the Cloudant API Work programmatically with Cloudant data Christopher Bienko Marina Greenstein Stephen E Holt Richard T Phillips ibm.com/redbooks Redpaper Contents Notices . 5 Trademarks . 6 Preface . 7 Authors. 7 Now you can become a published author, too! . 8 Comments welcome. 8 Stay connected to IBM Redbooks . 9 Chapter 1. Survey of the database landscape . 1 1.1 The fundamentals and evolution of relational databases . 2 1.1.1 The relational model . 2 1.1.2 The CAP Theorem . 4 1.2 The NoSQL paradigm . 5 1.2.1 ACID versus BASE systems . 7 1.2.2 What is NoSQL? . 8 1.2.3 NoSQL database landscape . 9 1.2.4 JSON and schema-less model . 11 Chapter 2. Build more, grow more, and sleep more with IBM Cloudant . 13 2.1 Business value . 15 2.2 Solution overview . 16 2.3 Solution architecture . 18 2.4 Usage scenarios . 20 2.5 Intuitively interact with data using Cloudant Dashboard . 21 2.5.1 Editing JSON documents using Cloudant Dashboard . 22 2.5.2 Configuring access permissions and replication jobs within Cloudant Dashboard. 24 2.6 A continuum of services working together on cloud . 25 2.6.1 Provisioning an analytics warehouse with IBM dashDB . 26 2.6.2 Data refinement services on-premises. 30 2.6.3 Data refinement services on the cloud. 30 2.6.4 Hybrid clouds: Data refinement across on/off–premises. 31 Chapter 3. -

Middleware-Based Database Replication: the Gaps Between Theory and Practice
Appears in Proceedings of the ACM SIGMOD Conference, Vancouver, Canada (June 2008) Middleware-based Database Replication: The Gaps Between Theory and Practice Emmanuel Cecchet George Candea Anastasia Ailamaki EPFL EPFL & Aster Data Systems EPFL & Carnegie Mellon University Lausanne, Switzerland Lausanne, Switzerland Lausanne, Switzerland [email protected] [email protected] [email protected] ABSTRACT There exist replication “solutions” for every major DBMS, from Oracle RAC™, Streams™ and DataGuard™ to Slony-I for The need for high availability and performance in data Postgres, MySQL replication and cluster, and everything in- management systems has been fueling a long running interest in between. The naïve observer may conclude that such variety of database replication from both academia and industry. However, replication systems indicates a solved problem; the reality, academic groups often attack replication problems in isolation, however, is the exact opposite. Replication still falls short of overlooking the need for completeness in their solutions, while customer expectations, which explains the continued interest in developing new approaches, resulting in a dazzling variety of commercial teams take a holistic approach that often misses offerings. opportunities for fundamental innovation. This has created over time a gap between academic research and industrial practice. Even the “simple” cases are challenging at large scale. We deployed a replication system for a large travel ticket brokering This paper aims to characterize the gap along three axes: system at a Fortune-500 company faced with a workload where performance, availability, and administration. We build on our 95% of transactions were read-only. Still, the 5% write workload own experience developing and deploying replication systems in resulted in thousands of update requests per second, which commercial and academic settings, as well as on a large body of implied that a system using 2-phase-commit, or any other form of prior related work. -

Manufacturing Equipment Technologies for Hard Disk's
Manufacturing Equipment Technologies for Hard Disk’s Challenge of Physical Limits 222 Manufacturing Equipment Technologies for Hard Disk’s Challenge of Physical Limits Kyoichi Mori OVERVIEW: To meet the world’s growing demands for volume information, Brian Rattray not just with computers but digitalization and video etc. the HDD must Yuichi Matsui, Dr. Eng. continually increase its capacity and meet expectations for reduced power consumption and green IT. Up until now the HDD has undergone many innovative technological developments to achieve higher recording densities. To continue this increase, innovative new technology is again required and is currently being developed at a brisk pace. The key components for areal density improvements, the disk and head, require high levels of performance and reliability from production and inspection equipment for efficient manufacturing and stable quality assurance. To meet this demand, high frequency electronics, servo positioning and optical inspection technology is being developed and equipment provided. Hitachi High-Technologies Corporation is doing its part to meet market needs for increased production and the adoption of next-generation technology by developing the technology and providing disk and head manufacturing/inspection equipment (see Fig. 1). INTRODUCTION higher efficiency storage, namely higher density HDDS (hard disk drives) have long relied on the HDDs will play a major role. computer market for growth but in recent years To increase density, the performance and quality of there has been a shift towards cloud computing and the HDD’s key components, disks (media) and heads consumer electronics etc. along with a rapid expansion have most effect. Therefore further technological of data storage applications (see Fig. -

A Crash Course in Wide Area Data Replication
A Crash Course In Wide Area Data Replication Jacob Farmer, CTO, Cambridge Computer SNIA Legal Notice The material contained in this tutorial is copyrighted by the SNIA. Member companies and individuals may use this material in presentations and literature under the following conditions: Any slide or slides used must be reproduced without modification The SNIA must be acknowledged as source of any material used in the body of any document containing material from these presentations. This presentation is a project of the SNIA Education Committee. A Crash Course in Wide Area Data Replication 2 © 2008 Storage Networking Industry Association. All Rights Reserved. Abstract A Crash Course in Wide Area Data Replication Replicating data over a WAN sounds pretty straight-forward, but it turns out that there are literally dozens of different approaches, each with it's own pros and cons. Which approach is the best? Well, that depends on a wide variety of factors! This class is a fast-paced crash course in the various ways in which data can be replicated with some commentary on each major approach. We trace the data path from applications to disk drives and examine all of the points along the way wherein replication logic can be inserted. We look at host based replication (application, database, file system, volume level, and hybrids), SAN replication (disk arrays, virtualization appliances, caching appliances, and storage switches), and backup system replication (block level incremental backup, CDP, and de-duplication). This class is not only the fastest way to understand replication technology it also serves as a foundation for understanding the latest storage virtualization techniques. -

Replication Under Scalable Hashing: a Family of Algorithms for Scalable Decentralized Data Distribution
Replication Under Scalable Hashing: A Family of Algorithms for Scalable Decentralized Data Distribution R. J. Honicky Ethan L. Miller [email protected] [email protected] Storage Systems Research Center Jack Baskin School of Engineering University of California, Santa Cruz Abstract block management is handled by the disk as opposed to a dedicated server. Because block management on individ- Typical algorithms for decentralized data distribution ual disks requires no inter-disk communication, this redis- work best in a system that is fully built before it first used; tribution of work comes at little cost in performance or ef- adding or removing components results in either exten- ficiency, and has a huge benefit in scalability, since block sive reorganization of data or load imbalance in the sys- layout is completely parallelized. tem. We have developed a family of decentralized algo- There are differing opinions about what object-based rithms, RUSH (Replication Under Scalable Hashing), that storage is or should be, and how much intelligence belongs maps replicated objects to a scalable collection of storage in the disk. In order for a device to be an OSD, however, servers or disks. RUSH algorithms distribute objects to each disk or disk subsystem must have its own filesystem; servers according to user-specified server weighting. While an OSD manages its own allocation of blocks and disk lay- all RUSH variants support addition of servers to the sys- out. To store data on an OSD, a client providesthe data and tem, different variants have different characteristics with a key for the data. To retrieve the data, a client provides a respect to lookup time in petabyte-scale systems, perfor- key.