Riak KV Performance in Sensor Data Storage Application
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

JETIR Research Journal
© 2018 JETIR October 2018, Volume 5, Issue 10 www.jetir.org (ISSN-2349-5162) QUALITATIVE COMPARISON OF KEY-VALUE BIG DATA DATABASES 1Ahmad Zia Atal, 2Anita Ganpati 1M.Tech Student, 2Professor, 1Department of computer Science, 1Himachal Pradesh University, Shimla, India Abstract: Companies are progressively looking to big data to convey valuable business insights that cannot be taken care by the traditional Relational Database Management System (RDBMS). As a result, a variety of big data databases options have developed. From past 30 years traditional Relational Database Management System (RDBMS) were being used in companies but now they are replaced by the big data. All big bata technologies are intended to conquer the limitations of RDBMS by enabling organizations to extract value from their data. In this paper, three key-value databases are discussed and compared on the basis of some general databases features and system performance features. Keywords: Big data, NoSQL, RDBMS, Riak, Redis, Hibari. I. INTRODUCTION Systems that are designed to store big data are often called NoSQL databases since they do not necessarily depend on the SQL query language used by RDBMS. NoSQL today is the term used to address the class of databases that do not follow Relational Database Management System (RDBMS) principles and are specifically designed to handle the speed and scale of the likes of Google, Facebook, Yahoo, Twitter and many more [1]. Many types of NoSQL database are designed for different use cases. The major categories of NoSQL databases consist of Key-Values store, Column family stores, Document databaseand graph database. Each of these technologies has their own benefits individually but generally Big data use cases are benefited by these technologies. -

Learning Key-Value Store Design
Learning Key-Value Store Design Stratos Idreos, Niv Dayan, Wilson Qin, Mali Akmanalp, Sophie Hilgard, Andrew Ross, James Lennon, Varun Jain, Harshita Gupta, David Li, Zichen Zhu Harvard University ABSTRACT We introduce the concept of design continuums for the data Key-Value Stores layout of key-value stores. A design continuum unifies major Machine Databases K V K V … K V distinct data structure designs under the same model. The Table critical insight and potential long-term impact is that such unifying models 1) render what we consider up to now as Learning Data Structures fundamentally different data structures to be seen as \views" B-Tree Table of the very same overall design space, and 2) allow \seeing" Graph LSM new data structure designs with performance properties that Store Hash are not feasible by existing designs. The core intuition be- hind the construction of design continuums is that all data Performance structures arise from the very same set of fundamental de- Update sign principles, i.e., a small set of data layout design con- Data Trade-offs cepts out of which we can synthesize any design that exists Access Patterns in the literature as well as new ones. We show how to con- Hardware struct, evaluate, and expand, design continuums and we also Cloud costs present the first continuum that unifies major data structure Read Memory designs, i.e., B+tree, Btree, LSM-tree, and LSH-table. Figure 1: From performance trade-offs to data structures, The practical benefit of a design continuum is that it cre- key-value stores and rich applications. -

Download Slides
Working with MIG • Our robust technology has been used by major broadcasters and media clients for over 7 years • Voting, Polling and Real-time Interactivity through second screen solutions • Incremental revenue generating services integrated with TV productions • Facilitate 10,000+ interactions per second as standard across our platforms • Platform and services have been audited by Deloitte and other compliant bodies • High capacity throughput for interactions, voting and transactions on a global scale • Partner of choice for BBC, ITV, Channel 5, SKY, MTV, Endemol, Fremantle and more: 1 | © 2012 Mobile Interactive Group @ QCON London mVoy Products High volume mobile messaging campaigns & mobile payments Social Interactivity & Voting via Facebook, iPhone, Android & Web Create, build, host & manage mobile commerce, mobile sites & apps Interactive messaging & multi-step marketing campaigns 2 | © 2012 Mobile Interactive Group @ QCON London MIG Technologies • Erlang • RIAK & leveldb • Redis • Ubuntu • Ruby on Rails • Java • Node.js • MongoDB • MySQL 3 | © 2012 Mobile Interactive Group @ QCON London Battle Stories • Building a wallet • Optimizing your hardware stack • Building a robust queue 4 | © 2012 Mobile Interactive Group @ QCON London Building a wallet • Fast – Over 10,000 debits / sec ( votes ) – Over 1,000 credits / sec • Scalable – Double hardware == Double performance • Robust / Recoverable – Transactions can not be lost – Wallet balances recoverable in the event of multi-server failure • Auditable – Complete transaction history -

Your Data Always Available for Applications and Users
DATASHEET RIAK® KV ENTERPRISE YOUR DATA ALWAYS AVAILABLE FOR APPLICATIONS AND USERS Companies rely on data to power their day-to- day operations. It is imperative that this data be always available. Even minutes of application RIAK KV BENEFITS downtime can mean lost sales, a poor user experience, and a bruised brand. This can add up GLOBAL AVAILABILITY to millions in lost revenue. Most databases work A distributed database with advanced local and multi-cluster at small scale, but how do you scale out, up, and replication means your data is always available. down predictably and linearly as your data grows? MASSIVE SCALABILITY You need a different database. Basho Riak® KV Automatic data distribution in the cluster and the ease of adding Enterprise is a distributed NoSQL database nodes mean near-linear performance increase as your data grows. architected to meet your application needs. Riak KV provides high availability and massive OPERATIONAL SIMPLICITY scalability. Riak KV can be operationalized at lower Easy to run, easy to add nodes to your cluster. Operations are costs than traditional relational databases and is powerful yet simple. Ensure your operations team sleeps better. easy to manage at scale. FAULT TOLERANCE Riak KV integrates with Apache Spark, Redis A masterless, multi-node architecture ensures no data loss in the event Caching, Apache Solr, and Apache Mesos of network or hardware failures. to reduce the complexity of integrating and deploying other Big Data technologies. FAST DATA ACCESS Your users expect your application to be fast. Low latency means your data requests are served predictably even during peak times. -
“Consistent Hashing”
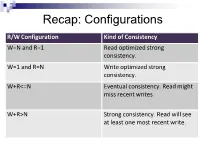
Recap: Configurations R/W Configuration Kind of Consistency W=N and R=1 Read optimized strong consistency. W=1 and R=N Write optimized strong consistency. W+R<=N Eventual consistency. Read might miss recent writes. W+R>N Strong consistency. Read will see at least one most recent write. Consistency Levels • Is there something between the extreme configurations “strong consistency” and “eventual consistency”? • Consider a client is working with a key value store Recap: Distributed Setup • N copies per record/object, spread across servers Client node4 node1 node2 node… node … node3 Client-Centric Consistency and Seen Writes Client-Centric Consistency: provides guarantees for a single client concerning the consistency of the accesses to a data store by that client. A client reading a value for a key is seeing a subset of the writes to this key; given the past history of writes by itself and other clients. Client-Centric Read Consistency Guarantees Guarantee Explanation Strong Consistency See all previous writes. Eventual Consistency See (any) subset of previous writes. Consistent Prefix See initial sequence of writes. Bounded Staleness See all “old” writes. E.g., everything older than 10 minutes. Monotonic Reads See increasing subset of writes. Read My Writes See all writes performed by reader. Causal Consistency • Consistency issues…. Our dog, Charlie, ran away today. Can’t find him, Alice we are afraid he got overrun by a car! Posted at 9:30am Thank God! I am so glad to hear this! Bob Posted at 10:20am Causal Consistency (2) • How it was supposed to appear…. Our dog, Charlie, ran away today. -

Memcached, Redis, and Aerospike Key-Value Stores Empirical
Memcached, Redis, and Aerospike Key-Value Stores Empirical Comparison Anthony Anthony Yaganti Naga Malleswara Rao University of Waterloo University of Waterloo 200 University Ave W 200 University Ave W Waterloo, ON, Canada Waterloo, ON, Canada +1 (226) 808-9489 +1 (226) 505-5900 [email protected] [email protected] ABSTRACT project. Thus, the results are somewhat biased as the tested DB The popularity of NoSQL database and the availability of larger setup might be set to give more advantage of one of the systems. DRAM have generated a great interest in in-memory key-value We will discuss more in Section 8 (Related Work). stores (kv-store) in the recent years. As a consequence, many In this work, we conduct a thorough experimental evaluation by similar kv-store store projects/products has emerged. Besides the comparing three major key-value stores nowadays, namely Redis, benchmarking results provided by the KV-store developers which Memcached, and Aerospike. We first elaborate the databases that are usually tested under their favorable setups and scenario, there we tested in Section 3. Then, the evaluation methodology are very limited comprehensive resources for users to decide comprises experimental setups, i.e., single and cluster mode; which kv-store to choose given a specific workload/use-case. To benchmark setups including the description of YCSB, dataset provide users with an unbiased and up-to-date insight in selecting configurations, types workloads (i.e., read-heavy, balanced, in-memory kv-stores, we conduct a study to empirically compare write-heavy), and concurrent access; and evaluation metrics will Redis, Memcached and Aerospike on equal ground by trying to be discussed in Section 4. -

Building Blocks of a Scalable Web Crawler
Building blocks of a scalable web crawler Marc Seeger Computer Science and Media Stuttgart Media University September 15, 2010 A Thesis Submitted in Fulfilment of the Requirements for a Degree of Master of Science in Computer Science and Media Primary thesis advisor: Prof. Walter Kriha Secondary thesis advisor: Dr. Dries Buytaert I I Abstract The purpose of this thesis was the investigation and implementation of a good architecture for collecting, analysing and managing website data on a scale of millions of domains. The final project is able to automatically collect data about websites and analyse the content management system they are using. To be able to do this efficiently, different possible storage back-ends were examined and a system was implemented that is able to gather and store data at a fast pace while still keeping it searchable. This thesis is a collection of the lessons learned while working on the project combined with the necessary knowledge that went into architectural decisions. It presents an overview of the different infrastructure possibilities and general approaches and as well as explaining the choices that have been made for the implemented system. II Acknowledgements I would like to thank Acquia and Dries Buytaert for allowing me to experience life in the USA while working on a great project. I would also like to thank Chris Brookins for showing me what agile project management is all about. Working at Acquia combined a great infrastructure and atmosphere with a pool of knowledgeable people. Both these things helped me immensely when trying to find and evaluate a matching architecture to this project. -

Analysis of Human Activities on Smart Devices Using Riak-TS
Analysis of human activities on smart devices using Riak TS Hinduja Dhanasekaran, Siddharth Selvam, Jeongkyu Lee University of Bridgeport Abstract—In this paper we have definition – “Extremely large data sets implemented Riak TS which is a time that may be analyzed computationally to series-based database. It is a key value- reveal patterns, trends, and associations, based database and has time as especially relating to human behavior important parameter. During the and interactions”. implementation of the project we have understood the installation process, We should also try to understand that big loading the data and also analyzing the data is changing every second and it is at data using Riak TS. By doing complex a very fast pace and hence the processing querying we learnt how time plays a rate must be super-fast in order to match crucial role in understanding the data the needs. Since big data has huge and analyzing them to visualize. amounts of data in terms of volume, we can’t process them using the traditional Index Terms—Big Data, NOSQL database, tools. The reason for traditional tools not Motivation, Riak TS features, Riak TS being a favorable one for processing Big Architecture, Dataset and Implementation, Data is because most of the Result, Conclusion traditional ones can’t handle huge I. INTRODUCTION amount of data at once and also the format of the data that is being collected We all know that the digital world today from various sources differ from each is based and is running because of the effective usage of Data. Social platforms like Facebook, Instagram, Snapchat all other and hence they are not ideal to deal with huge amount of data on a day handle the Big Data. -

On the Elasticity of Nosql Databases Over Cloud Management Platforms (Extended Version)
On the Elasticity of NoSQL Databases over Cloud Management Platforms (extended version) Ioannis Konstantinou, Evangelos Angelou, Christina Boumpouka, Dimitrios Tsoumakos, Nectarios Koziris Computing Systems Laboratory, School of Electrical and Computer Engineering National Technical University of Athens {ikons, eangelou, christina, dtsouma, nkoziris}@cslab.ece.ntua.gr ABSTRACT { VMs and storage space) according to application needs. NoSQL databases focus on analytical processing of large This is highly-compatible with NoSQL stores: Scalabil- scale datasets, offering increased scalability over commodity ity in processing big data is possible through elasticity and hardware. One of their strongest features is elasticity, which sharding. The former refers to the ability to expand or con- allows for fairly portioned premiums and high-quality per- tract dedicated resources in order to meet the exact demand. formance and directly applies to the philosophy of a cloud- The latter refers to the horizontal partitioning over a shared- based platform. Yet, the process of adaptive expansion and nothing architecture that enables scalable load processing. contraction of resources usually involves a lot of manual ef- It is obvious that these two properties (henceforth referred to fort during cluster configuration. To date, there exists no as elasticity) are intertwined: as computing resources grow comparative study to quantify this cost and measure the and shrink, data partitioning must be done in such a way efficacy of NoSQL engines that offer this feature over a that no loss occurs and the right amount of replication is cloud provider. In this work, we present a cloud-enabled conserved. framework for adaptive monitoring of NoSQL systems. We Many NoSQL systems (e.g., [6, 15, 20,8,9]) claim to perform a thorough study of the elasticity feature on some offer adaptive elasticity according to the number of partici- of the most popular NoSQL databases over an open-source pant commodity nodes. -

Using Erlang, Riak and the ORSWOT CRDT at Bet365 for Scalability and Performance
1 Using Erlang, Riak and the ORSWOT CRDT at bet365 for Scalability and Performance Michael Owen Research and Development Engineer 2 Background 3 bet365 in stats • Founded in 2000 • Located in Stoke-on-Trent • The largest online sports betting company • Over 19 million customers • One of the largest private companies in the UK • Employs more than 2,000 people • 2013-2014: Over £26 billion was staked – Last year is likely to be around 25% up • Business growing very rapidly! • Very technology focused company 4 bet365 technology stats • Over 500 employees within technology • £60 million per year IT budget • Fifteen datacentres in seven countries worldwide • 100Gb capable private dark fibre network • 9 upstream ISPs • 150 Gigabits of aggregated edge bandwidth – 25 Gbps and 6M HTTP requests/sec at peak • Around 1 to 1.5 million markets on site at any time • 18 languages supported • Push systems burst to 100,000 changes per second – Almost all this change generated via automated models • Database systems running at > 500K TPS at peak • Over 2.5 million concurrent users of our push systems • We stream more live sport than anyone else in Europe 5 Production systems using Erlang and Riak • Cash-out A system used by customers to close out bets early. • Stronger An online transaction processing (OLTP) data layer. 6 Why Erlang and Riak? 7 Our historical technology stack • Very pragmatic • What would deliver a quality product to market in record time • Mostly .NET with some Java middleware • Lot and lots of SQL Server 8 But we needed to change • Complexity of code and systems • Needed to make better use of multi-core CPUs • Needed to scale out – Could no longer scale our SQL infrastructure • Had scaled up and out as far as we could – Lack of scalability caused undue stress on the infrastructure • Lead to loss of availability 9 Erlang Adoption 10 Erlang – Key learnings • You can get a lot done in a short space of time. -

TIBCO Flogo® Connector for Riak KV Installation
TIBCO Flogo® Connector for Riak KV Installation Software Release 1.0.0 November 2018 Two-Second Advantage® 2 Important Information SOME TIBCO SOFTWARE EMBEDS OR BUNDLES OTHER TIBCO SOFTWARE. USE OF SUCH EMBEDDED OR BUNDLED TIBCO SOFTWARE IS SOLELY TO ENABLE THE FUNCTIONALITY (OR PROVIDE LIMITED ADD-ON FUNCTIONALITY) OF THE LICENSED TIBCO SOFTWARE. THE EMBEDDED OR BUNDLED SOFTWARE IS NOT LICENSED TO BE USED OR ACCESSED BY ANY OTHER TIBCO SOFTWARE OR FOR ANY OTHER PURPOSE. USE OF TIBCO SOFTWARE AND THIS DOCUMENT IS SUBJECT TO THE TERMS AND CONDITIONS OF A LICENSE AGREEMENT FOUND IN EITHER A SEPARATELY EXECUTED SOFTWARE LICENSE AGREEMENT, OR, IF THERE IS NO SUCH SEPARATE AGREEMENT, THE CLICKWRAP END USER LICENSE AGREEMENT WHICH IS DISPLAYED DURING DOWNLOAD OR INSTALLATION OF THE SOFTWARE (AND WHICH IS DUPLICATED IN THE LICENSE FILE) OR IF THERE IS NO SUCH SOFTWARE LICENSE AGREEMENT OR CLICKWRAP END USER LICENSE AGREEMENT, THE LICENSE(S) LOCATED IN THE “LICENSE” FILE(S) OF THE SOFTWARE. USE OF THIS DOCUMENT IS SUBJECT TO THOSE TERMS AND CONDITIONS, AND YOUR USE HEREOF SHALL CONSTITUTE ACCEPTANCE OF AND AN AGREEMENT TO BE BOUND BY THE SAME. ANY SOFTWARE ITEM IDENTIFIED AS THIRD PARTY LIBRARY IS AVAILABLE UNDER SEPARATE SOFTWARE LICENSE TERMS AND IS NOT PART OF A TIBCO PRODUCT. AS SUCH, THESE SOFTWARE ITEMS ARE NOT COVERED BY THE TERMS OF YOUR AGREEMENT WITH TIBCO, INCLUDING ANY TERMS CONCERNING SUPPORT, MAINTENANCE, WARRANTIES, AND INDEMNITIES. DOWNLOAD AND USE OF THESE ITEMS IS SOLELY AT YOUR OWN DISCRETION AND SUBJECT TO THE LICENSE TERMS APPLICABLE TO THEM. -

Rubrik for Physical Applications, Databases, and Operating Systems
Rubrik for Physical Applications, Databases, and Operating Systems Rubrik simplifies backup and recovery for hybrid cloud environments. It eliminates legacy backup complexity by integrating data orchestration, catalog management, and deduplicated storage into a single software platform. With Rubrik, enterprises can unlock cloud for long-term data retention or DR and deliver automation with an API-first software platform. Designed to be vendor-agnostic, Rubrik supports the leading operating systems, databases, hypervisors, clouds, and SaaS applications. INSTANT RECOVERY FOR SQL BARE METAL RECOVERY SINGLE PANE OF GLASS Deliver instant database recoveries and Migrate Windows Servers to any hypervisor Use the same easy interface to manage your clones in minutes without a storage penalty. or cloud instance for full system recovery. physical, virtual, and cloud workloads. ORACLE AND SQL DATABASES: • Live Mount for Test/Dev: Provision multiple point-in-time copies to developers in seconds. Automate test, iterate, and tear down workflows without provisioning additional storage. • Instant Recovery: Deliver near-zero RTOs by mounting Oracle and SQL directly on Rubrik. Recover down to a single object or tablespace in seconds. • Policy-driven Automation: Eliminate painful scripting and job scheduling. Manage large-scale environments with one SLA policy engine. • Automated Database Discovery: Rubrik automatically discovers all your Oracle and SQL clusters, hosts, databases, and instances. • Incremental-forever Backups: Rubrik delivers incremental-forever backups to drive capacity savings and network efficiencies. SAP HANA® DATABASES: • Policy-driven Simplicity: Mobilize your data to your cloud pro- vider of choice for cost-effective long-term retention. Automate • Native Integrations: Use existing backup and recovery workflows with Rubrik’s direct integration with SAP HANA replication and cloud archival via Rubrik’s SLA policy engine.