Performance Aspects of Object-Based Storage Services on Single Board Computers Christian Baun, Henry-Norbert Cocos, Rosa-Maria Spanou
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

JETIR Research Journal
© 2018 JETIR October 2018, Volume 5, Issue 10 www.jetir.org (ISSN-2349-5162) QUALITATIVE COMPARISON OF KEY-VALUE BIG DATA DATABASES 1Ahmad Zia Atal, 2Anita Ganpati 1M.Tech Student, 2Professor, 1Department of computer Science, 1Himachal Pradesh University, Shimla, India Abstract: Companies are progressively looking to big data to convey valuable business insights that cannot be taken care by the traditional Relational Database Management System (RDBMS). As a result, a variety of big data databases options have developed. From past 30 years traditional Relational Database Management System (RDBMS) were being used in companies but now they are replaced by the big data. All big bata technologies are intended to conquer the limitations of RDBMS by enabling organizations to extract value from their data. In this paper, three key-value databases are discussed and compared on the basis of some general databases features and system performance features. Keywords: Big data, NoSQL, RDBMS, Riak, Redis, Hibari. I. INTRODUCTION Systems that are designed to store big data are often called NoSQL databases since they do not necessarily depend on the SQL query language used by RDBMS. NoSQL today is the term used to address the class of databases that do not follow Relational Database Management System (RDBMS) principles and are specifically designed to handle the speed and scale of the likes of Google, Facebook, Yahoo, Twitter and many more [1]. Many types of NoSQL database are designed for different use cases. The major categories of NoSQL databases consist of Key-Values store, Column family stores, Document databaseand graph database. Each of these technologies has their own benefits individually but generally Big data use cases are benefited by these technologies. -

Refresh Your Data Lake to Cisco Data Intelligence Platform
Solution overview Cisco public Refresh Your Data Lake to Cisco Data Intelligence Platform The evolving Hadoop landscape Consideration in the journey In the beginning of 2019, providers of leading Hadoop distribution, Hortonworks and Cloudera of a Hadoop refresh merged together. This merger raised the bar on innovation in the big data space and the new Despite the capability gap between “Cloudera” launched Cloudera Data Platform (CDP) which combined the best of Hortonwork’s and Cloudera’s technologies to deliver the industry leading first enterprise data cloud. Recently, Hadoop 2.x and 3.x, it is estimated that Cloudera released the CDP Private Cloud Base, which is the on-premises version of CDP. This more than 80 percent of the Hadoop unified distribution brought in several new features, optimizations, and integrated analytics. installed base is still on either HDP2 or CDH5, which are built on Apache Hadoop CDP Private Cloud Base is built on Hadoop 3.x distribution. Hadoop developed several 2.0, and are getting close to end of capabilities since its inception. However, Hadoop 3.0 is an eagerly awaited major release support by the end of 2020. with several new features and optimizations. Upgrading from Hadoop 2.x to 3.0 is a paradigm shift as it enables diverse computing resources, (i.e., CPU, GPU, and FPGA) to work on data Amid those feature enrichments, and leverage AI/ML methodologies. It supports flexible and elastic containerized workloads, specialized computing resources, and managed either by Hadoop scheduler (i.e., YARN or Kubernetes), distributed deep learning, end of support, a Hadoop upgrade is a GPU-enabled Spark workloads, and more. -

Learning Key-Value Store Design
Learning Key-Value Store Design Stratos Idreos, Niv Dayan, Wilson Qin, Mali Akmanalp, Sophie Hilgard, Andrew Ross, James Lennon, Varun Jain, Harshita Gupta, David Li, Zichen Zhu Harvard University ABSTRACT We introduce the concept of design continuums for the data Key-Value Stores layout of key-value stores. A design continuum unifies major Machine Databases K V K V … K V distinct data structure designs under the same model. The Table critical insight and potential long-term impact is that such unifying models 1) render what we consider up to now as Learning Data Structures fundamentally different data structures to be seen as \views" B-Tree Table of the very same overall design space, and 2) allow \seeing" Graph LSM new data structure designs with performance properties that Store Hash are not feasible by existing designs. The core intuition be- hind the construction of design continuums is that all data Performance structures arise from the very same set of fundamental de- Update sign principles, i.e., a small set of data layout design con- Data Trade-offs cepts out of which we can synthesize any design that exists Access Patterns in the literature as well as new ones. We show how to con- Hardware struct, evaluate, and expand, design continuums and we also Cloud costs present the first continuum that unifies major data structure Read Memory designs, i.e., B+tree, Btree, LSM-tree, and LSH-table. Figure 1: From performance trade-offs to data structures, The practical benefit of a design continuum is that it cre- key-value stores and rich applications. -

Reference Architecture
REFERENCE ARCHITECTURE Service Providers Data Center Build a High-Performance Object Storage-as-a-Service Platform with Minio* Storage-as-a-service (STaaS) based on Minio* with Intel® technology simplifies object storage while providing high performance, scalability, and enhanced security features Executive Summary What You’ll Find in This Solution Reference Architecture: This Emerging cloud service providers (CSPs) have an opportunity to build or expand solution provides a starting point for their storage-as-a-service (STaaS) capabilities and tap into one of today’s fastest- developing a storage-as-a-service growing markets. However, CSPs who support this market face a substantial (STaaS) platform based on Minio*. challenge: how to cost effectively store an exponentially growing amount of If you are responsible for: data while exposing the data as a service with high performance, scalability • Investment decisions and and security. business strategy: You’ll learn how Minio-based STaaS can File and block protocols are complex, have legacy architectures that hold back help solve the pressing storage innovation, and are limited in their ability to scale. Object storage, which was challenges facing cloud service born in the cloud, solves these issues with a reduced set of storage APIs that are providers (CSPs) today. accessed over HTTP RESTful services. Hyperscalers have looked into many options • Figuring out how to implement when building the foundation of their cloud storage infrastructure and they all have STaaS and Minio: You’ll adopted object storage as their primary storage service. learn about the architecture components and how they work In this paper, we take a deeper look into an Amazon S3*-compatible object storage together to create a cohesive service architecture—a STaaS platform based on Minio* Object Storage and business solution. -

Continuous Delivery for Kubernetes Apps with Helm and Chartmuseum
Webinar Continuous Delivery for Kubernetes Apps with Helm and ChartMuseum Josh Dolitsky Stef Arnold Software Engineer Sr. Software Engineer Codefresh SUSE Webinar Outline Continuous Delivery for Kubernetes Apps 1. Intro to Helm with Helm and 2. Helm Commands 3. Intro to ChartMuseum ChartMuseum 4. ChartMuseum functions 5. CI/CD Pipeline 6. SUSE + Codefresh = <3 7. Demo Josh Dolitsky Stef Arnold Software Engineer Sr. Software Engineer Codefresh SUSE What is Helm? ● Helm is the package manager for Kubernetes ● Equivalent to “yum install <package>” ● Kubernetes manifest templates, packaged and versioned, referred to as charts Helm Use Cases ● Like other package managers Helm manages packages and their dependencies, and their installation. ● fetch, search, lint, and package are available client-side for authoring charts ● List, install, upgrade, delete, rollback for operations (makes use of server component Tiller) Helm use case mini demo See how we can interact with our application or just its configuration using helm. Helm Use Cases ● Where do the packages live? ● What is a Helm repository anyway? index.yaml! What’s the problem? How do multiple teams/devs publish their charts to a single repository at the same time? Team A Team B The Problem $ helm package charta/ $ helm package chartb/ $ aws s3 cp charta-0.1.0.tgz s3://mycharts/ possible $ aws s3 cp chartb-0.1.0.tgz s3://mycharts/ race condition $ aws s3 cp s3://mycharts/index.yaml stale.yaml $ aws s3 cp s3://mycharts/index.yaml stale.yaml $ helm repo index --merge stale.yaml . $ helm repo index --merge stale.yaml . $ aws s3 cp index.yaml s3://mycharts/ $ aws s3 cp index.yaml s3://mycharts/ Team A Team B The Solution $ helm package charta/ $ helm package chartb/ $ aws s3 cp charta-0.1.0.tgz s3://mycharts/ $ aws s3 cp chartb-0.1.0.tgz s3://mycharts/ Features - Multiple storage options ● Local filesystem ● Amazon S3 (and Minio) ● Google Cloud Storage ● Microsoft Azure Blob Storage ● Alibaba Cloud OSS Storage ● Openstack Object Storage Features - API for uploading charts etc. -

Riak KV Performance in Sensor Data Storage Application
ISSN 2079-3316 PROGRAM SYSTEMS: THEORY AND APPLICATIONS no.3(34), 2017, pp. 61–85 N. S. Zhivchikova, Y. V. Shevchuk Riak KV performance in sensor data storage application Abstract. A sensor data storage system is an important part of data analysis systems. The duty of sensor data storage is to accept time series data from remote sources, store them and provide access to retrospective data on demand. As the number of sensors grows, the storage system scaling becomes a concern. In this article we experimentally evaluate Riak KV|a scalable distributed key-value data store as a backend for a sensor data storage system. Key words and phrases: sensor data, write performance, distributed storage, time series, Riak, Erlang. 2010 Mathematics Subject Classification: 68M20 Introduction The purpose of a sensor data storage is to store data coming in small portions from a large number of sensors. The data should be stored so as to facilitate efficient retrieval of a (possibly large) data array by sensor identifier and time interval, e.g. to draw a graph. The system is described by three parameters: the number of sensors S, incoming data rate in megabytes per second A, and the storage period Y . In single-computer implementation there are limits on S, A, Y that can't be achieved without computer upgrade to non-commodity hardware which involves disproportional system cost increase. When the system design goals exceed the S, A, Y limits reachable by a single commodity computer, a viable solution is to move to distributed architecture | using multiple commodity computers to meet the design goals. -

Download Slides
Working with MIG • Our robust technology has been used by major broadcasters and media clients for over 7 years • Voting, Polling and Real-time Interactivity through second screen solutions • Incremental revenue generating services integrated with TV productions • Facilitate 10,000+ interactions per second as standard across our platforms • Platform and services have been audited by Deloitte and other compliant bodies • High capacity throughput for interactions, voting and transactions on a global scale • Partner of choice for BBC, ITV, Channel 5, SKY, MTV, Endemol, Fremantle and more: 1 | © 2012 Mobile Interactive Group @ QCON London mVoy Products High volume mobile messaging campaigns & mobile payments Social Interactivity & Voting via Facebook, iPhone, Android & Web Create, build, host & manage mobile commerce, mobile sites & apps Interactive messaging & multi-step marketing campaigns 2 | © 2012 Mobile Interactive Group @ QCON London MIG Technologies • Erlang • RIAK & leveldb • Redis • Ubuntu • Ruby on Rails • Java • Node.js • MongoDB • MySQL 3 | © 2012 Mobile Interactive Group @ QCON London Battle Stories • Building a wallet • Optimizing your hardware stack • Building a robust queue 4 | © 2012 Mobile Interactive Group @ QCON London Building a wallet • Fast – Over 10,000 debits / sec ( votes ) – Over 1,000 credits / sec • Scalable – Double hardware == Double performance • Robust / Recoverable – Transactions can not be lost – Wallet balances recoverable in the event of multi-server failure • Auditable – Complete transaction history -

Your Data Always Available for Applications and Users
DATASHEET RIAK® KV ENTERPRISE YOUR DATA ALWAYS AVAILABLE FOR APPLICATIONS AND USERS Companies rely on data to power their day-to- day operations. It is imperative that this data be always available. Even minutes of application RIAK KV BENEFITS downtime can mean lost sales, a poor user experience, and a bruised brand. This can add up GLOBAL AVAILABILITY to millions in lost revenue. Most databases work A distributed database with advanced local and multi-cluster at small scale, but how do you scale out, up, and replication means your data is always available. down predictably and linearly as your data grows? MASSIVE SCALABILITY You need a different database. Basho Riak® KV Automatic data distribution in the cluster and the ease of adding Enterprise is a distributed NoSQL database nodes mean near-linear performance increase as your data grows. architected to meet your application needs. Riak KV provides high availability and massive OPERATIONAL SIMPLICITY scalability. Riak KV can be operationalized at lower Easy to run, easy to add nodes to your cluster. Operations are costs than traditional relational databases and is powerful yet simple. Ensure your operations team sleeps better. easy to manage at scale. FAULT TOLERANCE Riak KV integrates with Apache Spark, Redis A masterless, multi-node architecture ensures no data loss in the event Caching, Apache Solr, and Apache Mesos of network or hardware failures. to reduce the complexity of integrating and deploying other Big Data technologies. FAST DATA ACCESS Your users expect your application to be fast. Low latency means your data requests are served predictably even during peak times. -
“Consistent Hashing”
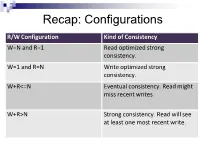
Recap: Configurations R/W Configuration Kind of Consistency W=N and R=1 Read optimized strong consistency. W=1 and R=N Write optimized strong consistency. W+R<=N Eventual consistency. Read might miss recent writes. W+R>N Strong consistency. Read will see at least one most recent write. Consistency Levels • Is there something between the extreme configurations “strong consistency” and “eventual consistency”? • Consider a client is working with a key value store Recap: Distributed Setup • N copies per record/object, spread across servers Client node4 node1 node2 node… node … node3 Client-Centric Consistency and Seen Writes Client-Centric Consistency: provides guarantees for a single client concerning the consistency of the accesses to a data store by that client. A client reading a value for a key is seeing a subset of the writes to this key; given the past history of writes by itself and other clients. Client-Centric Read Consistency Guarantees Guarantee Explanation Strong Consistency See all previous writes. Eventual Consistency See (any) subset of previous writes. Consistent Prefix See initial sequence of writes. Bounded Staleness See all “old” writes. E.g., everything older than 10 minutes. Monotonic Reads See increasing subset of writes. Read My Writes See all writes performed by reader. Causal Consistency • Consistency issues…. Our dog, Charlie, ran away today. Can’t find him, Alice we are afraid he got overrun by a car! Posted at 9:30am Thank God! I am so glad to hear this! Bob Posted at 10:20am Causal Consistency (2) • How it was supposed to appear…. Our dog, Charlie, ran away today. -

Making Containers Lazy with Docker and Cernvm-FS
Making containers lazy with Docker and CernVM-FS N Hardi, J Blomer, G Ganis and R Popescu CERN E-mail: [email protected] Abstract. Containerization technology is becoming more and more popular because it provides an efficient way to improve deployment flexibility by packaging up code into software micro-environments. Yet, containerization has limitations and one of the main ones is the fact that entire container images need to be transferred before they can be used. Container images can be seen as software stacks and High Energy Physics has long solved the distribution problem for large software stacks with CernVM-FS. CernVM-FS provides a global, shared software area, where clients only load the small subset of binaries that are accessed for any given compute job. In this paper, we propose a solution to the problem of efficient image distribution using CernVM-FS for storage and transport of container images. We chose to implement our solution for the Docker platform, due to its popularity and widespread use. To minimize the impact on existing workflows our implementation comes as a Docker plugin, meaning that users will continue to pull, run, modify, and store Docker images using standard Docker tools. We introduce the concept of a thin image, whose contents are served on demand from CernVM-FS repositories. Such behavior closely reassembles the lazy evaluation strategy in programming language theory. Our measurements confirm that the time before a task starts executing depends only on the size of the files actually used, minimizing the cold start-up time in all cases. 1. Introduction Linux process isolation with containers became very popular with the advent of convenient container management tools such as Docker [1], rkt [2] or Singularity [3]. -

Memcached, Redis, and Aerospike Key-Value Stores Empirical
Memcached, Redis, and Aerospike Key-Value Stores Empirical Comparison Anthony Anthony Yaganti Naga Malleswara Rao University of Waterloo University of Waterloo 200 University Ave W 200 University Ave W Waterloo, ON, Canada Waterloo, ON, Canada +1 (226) 808-9489 +1 (226) 505-5900 [email protected] [email protected] ABSTRACT project. Thus, the results are somewhat biased as the tested DB The popularity of NoSQL database and the availability of larger setup might be set to give more advantage of one of the systems. DRAM have generated a great interest in in-memory key-value We will discuss more in Section 8 (Related Work). stores (kv-store) in the recent years. As a consequence, many In this work, we conduct a thorough experimental evaluation by similar kv-store store projects/products has emerged. Besides the comparing three major key-value stores nowadays, namely Redis, benchmarking results provided by the KV-store developers which Memcached, and Aerospike. We first elaborate the databases that are usually tested under their favorable setups and scenario, there we tested in Section 3. Then, the evaluation methodology are very limited comprehensive resources for users to decide comprises experimental setups, i.e., single and cluster mode; which kv-store to choose given a specific workload/use-case. To benchmark setups including the description of YCSB, dataset provide users with an unbiased and up-to-date insight in selecting configurations, types workloads (i.e., read-heavy, balanced, in-memory kv-stores, we conduct a study to empirically compare write-heavy), and concurrent access; and evaluation metrics will Redis, Memcached and Aerospike on equal ground by trying to be discussed in Section 4. -

Security and Cryptography in GO
Masaryk University Faculty of Informatics Security and cryptography in GO Bachelor’s Thesis Lenka Svetlovská Brno, Spring 2017 Masaryk University Faculty of Informatics Security and cryptography in GO Bachelor’s Thesis Lenka Svetlovská Brno, Spring 2017 This is where a copy of the official signed thesis assignment and a copy ofthe Statement of an Author is located in the printed version of the document. Declaration Hereby I declare that this paper is my original authorial work, which I have worked out on my own. All sources, references, and literature used or excerpted during elaboration of this work are properly cited and listed in complete reference to the due source. Lenka Svetlovská Advisor: RNDr. Andriy Stetsko, Ph.D. i Acknowledgement I would like to thank RNDr. Andriy Stetsko, Ph.D. for the manage- ment of the bachelor thesis, valuable advice, and comments. I would also like to thank the consultant from Y Soft Corporation a.s., Mgr. Lenka Bačinská, for useful advice, dedicated time and patience in consultations and application development. Likewise, I thank my family and friends for their support through- out my studies and writing this thesis. iii Abstract The main goal of this bachelor thesis is an implementation of an ap- plication able to connect to a server using pre-shared key cipher suite, communicate with server and support of X.509 certificates, such as generation of asymmetric keys, certificate signing request and different formats. The application is implemented in language Go. The very first step involves looking for suitable Go library which can connect to a server using pre-shared key cipher suite, and work with cryptography and X.509 certificates.