JETIR Research Journal
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
![LIST of NOSQL DATABASES [Currently 150]](https://docslib.b-cdn.net/cover/8918/list-of-nosql-databases-currently-150-418918.webp)
LIST of NOSQL DATABASES [Currently 150]
Your Ultimate Guide to the Non - Relational Universe! [the best selected nosql link Archive in the web] ...never miss a conceptual article again... News Feed covering all changes here! NoSQL DEFINITION: Next Generation Databases mostly addressing some of the points: being non-relational, distributed, open-source and horizontally scalable. The original intention has been modern web-scale databases. The movement began early 2009 and is growing rapidly. Often more characteristics apply such as: schema-free, easy replication support, simple API, eventually consistent / BASE (not ACID), a huge amount of data and more. So the misleading term "nosql" (the community now translates it mostly with "not only sql") should be seen as an alias to something like the definition above. [based on 7 sources, 14 constructive feedback emails (thanks!) and 1 disliking comment . Agree / Disagree? Tell me so! By the way: this is a strong definition and it is out there here since 2009!] LIST OF NOSQL DATABASES [currently 150] Core NoSQL Systems: [Mostly originated out of a Web 2.0 need] Wide Column Store / Column Families Hadoop / HBase API: Java / any writer, Protocol: any write call, Query Method: MapReduce Java / any exec, Replication: HDFS Replication, Written in: Java, Concurrency: ?, Misc: Links: 3 Books [1, 2, 3] Cassandra massively scalable, partitioned row store, masterless architecture, linear scale performance, no single points of failure, read/write support across multiple data centers & cloud availability zones. API / Query Method: CQL and Thrift, replication: peer-to-peer, written in: Java, Concurrency: tunable consistency, Misc: built-in data compression, MapReduce support, primary/secondary indexes, security features. -

Implementation of the BOLARE Programming Language
Implementation of the BOLARE Programming Language Viktor Pavlu ([email protected]) Institute of Computer Languages, Vienna University of Technology, Argentinierstrasse 8/E185, 1040 "ien, Austria ABSTRACT REBOL is a very flexible, dynamic, reflective programming language that clearly differs from the dynamic languages currently in popular use! The idea behind REBOL is that different problems should be attacked with different languages that have varying levels of granularity, each specifi- cally tailored to its problem domain. These domain-specific languages should give the program- mer the power to #rite programs that are closer to the problem and more expressive, thus shorter and easier to read, maintain and extend than would be possible in today’s dynamic programming languages. Despite its promising features, REBOL has not gained wide acceptance. Above all, this is due to the following: )*+ The language is merely defined by means o its only implementation, ),+ this implementation is closed-source and has many flaws, and )-+ the flaws are here to stay! .e therefore started project BOLARE. Aim o this project is to build an interpreter for a lan- guage that very closely resembles REBOL but leaves out all unintentional behavior that only stems from artifacts of the original implementation. After an introduction to REBOL/BOLARE in general, the three areas currently being #orked on are presented: Parser Generator: REBOL has a large set o built-in datatypes that have their own literal form making it easy to embed dates, times, email-addresses, tag structures, coordinates, binary data, etc. in scripts. The BOLARE parser is dynamically generated from a declarative de- scription of literal forms. -

Learning Key-Value Store Design
Learning Key-Value Store Design Stratos Idreos, Niv Dayan, Wilson Qin, Mali Akmanalp, Sophie Hilgard, Andrew Ross, James Lennon, Varun Jain, Harshita Gupta, David Li, Zichen Zhu Harvard University ABSTRACT We introduce the concept of design continuums for the data Key-Value Stores layout of key-value stores. A design continuum unifies major Machine Databases K V K V … K V distinct data structure designs under the same model. The Table critical insight and potential long-term impact is that such unifying models 1) render what we consider up to now as Learning Data Structures fundamentally different data structures to be seen as \views" B-Tree Table of the very same overall design space, and 2) allow \seeing" Graph LSM new data structure designs with performance properties that Store Hash are not feasible by existing designs. The core intuition be- hind the construction of design continuums is that all data Performance structures arise from the very same set of fundamental de- Update sign principles, i.e., a small set of data layout design con- Data Trade-offs cepts out of which we can synthesize any design that exists Access Patterns in the literature as well as new ones. We show how to con- Hardware struct, evaluate, and expand, design continuums and we also Cloud costs present the first continuum that unifies major data structure Read Memory designs, i.e., B+tree, Btree, LSM-tree, and LSH-table. Figure 1: From performance trade-offs to data structures, The practical benefit of a design continuum is that it cre- key-value stores and rich applications. -

Obstacles to Compilation of Rebol Programs
Obstacles to Compilation of Rebol Programs Viktor Pavlu TU Wien Institute of Computer Aided Automation, Computer Vision Lab A-1040 Vienna, Favoritenstr. 9/183-2, Austria [email protected] Abstract. Rebol’s syntax has no explicit delimiters around function arguments; all values in Rebol are first-class; Rebol uses fexprs as means of dynamic syntactic abstraction; Rebol thus combines the advantages of syntactic abstraction and a common language concept for both meta-program and object-program. All of the above are convenient attributes from a programmer’s point of view, yet at the same time pose severe challenges when striving to compile Rebol into reasonable code. An approach to compiling Rebol code that is still in its infancy is sketched, expected outcomes are presented. Keywords: first-class macros, dynamic syntactic abstraction, $vau calculus, fexpr, Ker- nel, Rebol 1 Introduction A meta-program is a program that can analyze (read), transform (read/write), or generate (write) another program, called the object-program. Static techniques for syntactic abstraction (macro systems, preprocessors) resolve all abstraction during compilation, so the expansion of abstractions incurs no cost at run-time. Static techniques are, however, conceptionally burdensome as they lead to staged systems with phases that are isolated from each other. In systems where different syntax is used for the phases (e. g., C++), it results in a multitude of programming languages following different sets of rules. In systems where the same syntax is shared between phases (e. g., Lisp), the separa- tion is even more unnatural: two syntactically largely identical-looking pieces of code cannot interact with each other as they are assigned to different execution stages. -

Riak KV Performance in Sensor Data Storage Application
ISSN 2079-3316 PROGRAM SYSTEMS: THEORY AND APPLICATIONS no.3(34), 2017, pp. 61–85 N. S. Zhivchikova, Y. V. Shevchuk Riak KV performance in sensor data storage application Abstract. A sensor data storage system is an important part of data analysis systems. The duty of sensor data storage is to accept time series data from remote sources, store them and provide access to retrospective data on demand. As the number of sensors grows, the storage system scaling becomes a concern. In this article we experimentally evaluate Riak KV|a scalable distributed key-value data store as a backend for a sensor data storage system. Key words and phrases: sensor data, write performance, distributed storage, time series, Riak, Erlang. 2010 Mathematics Subject Classification: 68M20 Introduction The purpose of a sensor data storage is to store data coming in small portions from a large number of sensors. The data should be stored so as to facilitate efficient retrieval of a (possibly large) data array by sensor identifier and time interval, e.g. to draw a graph. The system is described by three parameters: the number of sensors S, incoming data rate in megabytes per second A, and the storage period Y . In single-computer implementation there are limits on S, A, Y that can't be achieved without computer upgrade to non-commodity hardware which involves disproportional system cost increase. When the system design goals exceed the S, A, Y limits reachable by a single commodity computer, a viable solution is to move to distributed architecture | using multiple commodity computers to meet the design goals. -

Introducing Myself…
IntroducingIntroducing myselfmyself …… Nenad aka "DocKimbel" Rakocevic, Programming for 25 years: C/C++, *Basic, ASM, REBOL, web client -side languages, … Founder of a software company in Paris: Softinnov Author of several libraries for REBOL: MySQL, PostgresQL, LDAP native drivers UniServe: asynchronous, event -driven network engine Cheyenne Web Server: full -featured web application server CureCode: very fast web -based bug tracker (Mantis -like) Various others tools, game, demos … Was a happy Amiga user and registered BeOS developer WhyWhy amam II usingusing REBOLREBOL forfor 1111 years?years? Great scripting language Great prototyping tool Simple cross -platform graphic engine (View) Symbolic & Meta -programming Code / Data duality DSL -oriented Great designer behind: Carl Sassenrath WhyWhy II don'tdon't wantwant toto useuse REBOLREBOL anymore?anymore? Closed source Slow ( benchmark ) No multithreading support Mostly glue language, not general -purpose enough Not (easily) embeddable in third -party apps Can't run on popular VM (JVM, CLR) Sometimes designed for " Bob the artist ", rather than "John the programmer " WhatWhat isis thethe statestate ofof REBOLREBOL world?world? (1/2)(1/2) How REBOL began 14 years ago … WhatWhat isis thethe statestate ofof REBOLREBOL world?world? (2/2)(2/2) …and where it is today WhatWhat toto dodo then?then? Give up and pick up another language? Build an alternative? I chose the 2 nd option! MyMy answeranswer is:is: RReded !! Red[uced] REBOL dialect Fully open source (MIT/BSD) Statically compiled -

Download Slides
Working with MIG • Our robust technology has been used by major broadcasters and media clients for over 7 years • Voting, Polling and Real-time Interactivity through second screen solutions • Incremental revenue generating services integrated with TV productions • Facilitate 10,000+ interactions per second as standard across our platforms • Platform and services have been audited by Deloitte and other compliant bodies • High capacity throughput for interactions, voting and transactions on a global scale • Partner of choice for BBC, ITV, Channel 5, SKY, MTV, Endemol, Fremantle and more: 1 | © 2012 Mobile Interactive Group @ QCON London mVoy Products High volume mobile messaging campaigns & mobile payments Social Interactivity & Voting via Facebook, iPhone, Android & Web Create, build, host & manage mobile commerce, mobile sites & apps Interactive messaging & multi-step marketing campaigns 2 | © 2012 Mobile Interactive Group @ QCON London MIG Technologies • Erlang • RIAK & leveldb • Redis • Ubuntu • Ruby on Rails • Java • Node.js • MongoDB • MySQL 3 | © 2012 Mobile Interactive Group @ QCON London Battle Stories • Building a wallet • Optimizing your hardware stack • Building a robust queue 4 | © 2012 Mobile Interactive Group @ QCON London Building a wallet • Fast – Over 10,000 debits / sec ( votes ) – Over 1,000 credits / sec • Scalable – Double hardware == Double performance • Robust / Recoverable – Transactions can not be lost – Wallet balances recoverable in the event of multi-server failure • Auditable – Complete transaction history -

Big Data: a Survey the New Paradigms, Methodologies and Tools
Big Data: A Survey The New Paradigms, Methodologies and Tools Enrico Giacinto Caldarola1,2 and Antonio Maria Rinaldi1,3 1Department of Electrical Engineering and Information Technologies, University of Naples Federico II, Napoli, Italy 2Institute of Industrial Technologies and Automation, National Research Council, Bari, Italy 3IKNOS-LAB Intelligent and Knowledge Systems, University of Naples Federico II, LUPT 80134, via Toledo, 402-Napoli, Italy Keywords: Big Data, NoSQL, NewSQL, Big Data Analytics, Data Management, Map-reduce. Abstract: For several years we are living in the era of information. Since any human activity is carried out by means of information technologies and tends to be digitized, it produces a humongous stack of data that becomes more and more attractive to different stakeholders such as data scientists, entrepreneurs or just privates. All of them are interested in the possibility to gain a deep understanding about people and things, by accurately and wisely analyzing the gold mine of data they produce. The reason for such interest derives from the competitive advantage and the increase in revenues expected from this deep understanding. In order to help analysts in revealing the insights hidden behind data, new paradigms, methodologies and tools have emerged in the last years. There has been a great explosion of technological solutions that arises the need for a review of the current state of the art in the Big Data technologies scenario. Thus, after a characterization of the new paradigm under study, this work aims at surveying the most spread technologies under the Big Data umbrella, throughout a qualitative analysis of their characterizing features. -

Your Data Always Available for Applications and Users
DATASHEET RIAK® KV ENTERPRISE YOUR DATA ALWAYS AVAILABLE FOR APPLICATIONS AND USERS Companies rely on data to power their day-to- day operations. It is imperative that this data be always available. Even minutes of application RIAK KV BENEFITS downtime can mean lost sales, a poor user experience, and a bruised brand. This can add up GLOBAL AVAILABILITY to millions in lost revenue. Most databases work A distributed database with advanced local and multi-cluster at small scale, but how do you scale out, up, and replication means your data is always available. down predictably and linearly as your data grows? MASSIVE SCALABILITY You need a different database. Basho Riak® KV Automatic data distribution in the cluster and the ease of adding Enterprise is a distributed NoSQL database nodes mean near-linear performance increase as your data grows. architected to meet your application needs. Riak KV provides high availability and massive OPERATIONAL SIMPLICITY scalability. Riak KV can be operationalized at lower Easy to run, easy to add nodes to your cluster. Operations are costs than traditional relational databases and is powerful yet simple. Ensure your operations team sleeps better. easy to manage at scale. FAULT TOLERANCE Riak KV integrates with Apache Spark, Redis A masterless, multi-node architecture ensures no data loss in the event Caching, Apache Solr, and Apache Mesos of network or hardware failures. to reduce the complexity of integrating and deploying other Big Data technologies. FAST DATA ACCESS Your users expect your application to be fast. Low latency means your data requests are served predictably even during peak times. -
“Consistent Hashing”
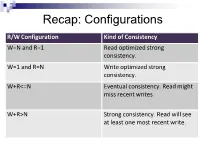
Recap: Configurations R/W Configuration Kind of Consistency W=N and R=1 Read optimized strong consistency. W=1 and R=N Write optimized strong consistency. W+R<=N Eventual consistency. Read might miss recent writes. W+R>N Strong consistency. Read will see at least one most recent write. Consistency Levels • Is there something between the extreme configurations “strong consistency” and “eventual consistency”? • Consider a client is working with a key value store Recap: Distributed Setup • N copies per record/object, spread across servers Client node4 node1 node2 node… node … node3 Client-Centric Consistency and Seen Writes Client-Centric Consistency: provides guarantees for a single client concerning the consistency of the accesses to a data store by that client. A client reading a value for a key is seeing a subset of the writes to this key; given the past history of writes by itself and other clients. Client-Centric Read Consistency Guarantees Guarantee Explanation Strong Consistency See all previous writes. Eventual Consistency See (any) subset of previous writes. Consistent Prefix See initial sequence of writes. Bounded Staleness See all “old” writes. E.g., everything older than 10 minutes. Monotonic Reads See increasing subset of writes. Read My Writes See all writes performed by reader. Causal Consistency • Consistency issues…. Our dog, Charlie, ran away today. Can’t find him, Alice we are afraid he got overrun by a car! Posted at 9:30am Thank God! I am so glad to hear this! Bob Posted at 10:20am Causal Consistency (2) • How it was supposed to appear…. Our dog, Charlie, ran away today. -

Generating Non-Verbal Communication from Speech
Manuel Rebol, MSc. Generating Non-Verbal Communication From Speech Master's Thesis to achieve the university degree of Master of Science Master's degree programme: Computer Science submitted to Graz University of Technology Supervisor Christian G¨utl,Assoc.Prof. Dipl.-Ing. Dr.techn. Supervisor Krzysztof Pietroszek, Ass.Prof. M.Sc. Ph.D. In cooperation with American University, Washington, DC This work was supported by the Austrian Marshall Plan Foundation Graz, November 2020 Abstract The communication between human and virtual agents is becoming more important because of the increased usage of virtual environments in everyday life. Applications such as virtual learning platforms, online meetings and virtual assistance are gaining popularity. However, communication with virtual agents is often unintuitive and does not feel similar to talking with a person. Therefore, we focus on improving natural non-verbal human-agent communication in our work. We develop a speaker-specific model that predicts hand and arm gestures given input speech. We model the non-deterministic relationship between speech and gestures with a Generative Adversarial Network (GAN). Inside the GAN, a motion discriminator forces the generator to predict only gestures that have human-like motion. To provide data for our model, we extract the gestures from in-the- wild videos using 3D human pose estimation algorithms. This allows us to automatically create a large speaker-specific dataset despite the lack of motion capture data. We train our gesture model on speakers from show business and academia using publicly available video data. Once generated by our GAN, we animate the gestures on a virtual character. We evaluate the generated gestures by conducting a human user study. -

Object-Oriented Javascript
Object-Oriented JavaScript In this chapter, you'll learn about OOP (Object-Oriented Programming) and how it relates to JavaScript. As an ASP.NET developer, you probably have some experience working with objects, and you may even be familiar with concepts such as inheritance. However, unless you're already an experienced JavaScript programmer, you probably aren't familiar with the way JavaScript objects and functions really work. This knowledge is necessary in order to understand how the Microsoft AJAX Library works, and this chapter will teach you the necessary foundations. More specifi cally, you will learn: • What encapsulation, inheritance, and polymorphism mean • How JavaScript functions work • How to use anonymous functions and closures • How to read a class diagram, and implement it using JavaScript code • How to work with JavaScript prototypes • How the execution context and scope affect the output of JavaScript functions • How to implement inheritance using closures and prototypes • What JSON is, and what a JSON structure looks like In the next chapters you'll use this theory to work effectively with the Microsoft AJAX Library. Concepts of Object-Oriented Programming Most ASP.NET developers are familiar with the fundamental OOP principles because this knowledge is important when developing for the .NET development. Similarly, to develop client-side code using the Microsoft AJAX Library, you need to be familiar with JavaScript's OOP features. Although not particularly diffi cult, understanding these features can be a bit challenging at fi rst, because JavaScript's OOP model is different than that of languages such as C#, VB.NET, C++, or Java.