Learning Key-Value Store Design
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

JETIR Research Journal
© 2018 JETIR October 2018, Volume 5, Issue 10 www.jetir.org (ISSN-2349-5162) QUALITATIVE COMPARISON OF KEY-VALUE BIG DATA DATABASES 1Ahmad Zia Atal, 2Anita Ganpati 1M.Tech Student, 2Professor, 1Department of computer Science, 1Himachal Pradesh University, Shimla, India Abstract: Companies are progressively looking to big data to convey valuable business insights that cannot be taken care by the traditional Relational Database Management System (RDBMS). As a result, a variety of big data databases options have developed. From past 30 years traditional Relational Database Management System (RDBMS) were being used in companies but now they are replaced by the big data. All big bata technologies are intended to conquer the limitations of RDBMS by enabling organizations to extract value from their data. In this paper, three key-value databases are discussed and compared on the basis of some general databases features and system performance features. Keywords: Big data, NoSQL, RDBMS, Riak, Redis, Hibari. I. INTRODUCTION Systems that are designed to store big data are often called NoSQL databases since they do not necessarily depend on the SQL query language used by RDBMS. NoSQL today is the term used to address the class of databases that do not follow Relational Database Management System (RDBMS) principles and are specifically designed to handle the speed and scale of the likes of Google, Facebook, Yahoo, Twitter and many more [1]. Many types of NoSQL database are designed for different use cases. The major categories of NoSQL databases consist of Key-Values store, Column family stores, Document databaseand graph database. Each of these technologies has their own benefits individually but generally Big data use cases are benefited by these technologies. -

An Opinionated Guide to Technology Frontiers
TECHNOLOGY RADARVOL. 21 An opinionated guide to technology frontiers thoughtworks.com/radar #TWTechRadar Rebecca Martin Fowler Bharani Erik Evan Parsons (CTO) (Chief Scientist) Subramaniam Dörnenburg Bottcher Fausto Hao Ian James Jonny CONTRIBUTORS de la Torre Xu Cartwright Lewis LeRoy The Technology Radar is prepared by the ThoughtWorks Technology Advisory Board — This edition of the ThoughtWorks Technology Radar is based on a meeting of the Technology Advisory Board in San Francisco in October 2019 Ketan Lakshminarasimhan Marco Mike Neal Padegaonkar Sudarshan Valtas Mason Ford Ni Rachel Scott Shangqi Zhamak Wang Laycock Shaw Liu Dehghani TECHNOLOGY RADAR | 2 © ThoughtWorks, Inc. All Rights Reserved. ABOUT RADAR AT THE RADAR A GLANCE ThoughtWorkers are passionate about ADOPT technology. We build it, research it, test it, 1 open source it, write about it, and constantly We feel strongly that the aim to improve it — for everyone. Our industry should be adopting mission is to champion software excellence these items. We use them and revolutionize IT. We create and share when appropriate on our the ThoughtWorks Technology Radar in projects. HOLD ASSESS support of that mission. The ThoughtWorks TRIAL Technology Advisory Board, a group of senior technology leaders at ThoughtWorks, 2 TRIAL ADOPT creates the Radar. They meet regularly to ADOPT Worth pursuing. It’s 108 discuss the global technology strategy for important to understand how 96 ThoughtWorks and the technology trends TRIAL to build up this capability. ASSESS 1 that significantly impact our industry. Enterprises can try this HOLD 2 technology on a project that The Radar captures the output of the 3 can handle the risk. -

Accordion: Better Memory Organization for LSM Key-Value Stores
Accordion: Better Memory Organization for LSM Key-Value Stores Edward Bortnikov Anastasia Braginsky Eshcar Hillel Yahoo Research Yahoo Research Yahoo Research [email protected] [email protected] [email protected] Idit Keidar Gali Sheffi Technion and Yahoo Research Yahoo Research [email protected] gsheffi@oath.com ABSTRACT of applications for which they are used continuously in- Log-structured merge (LSM) stores have emerged as the tech- creases. A small sample of recently published use cases in- nology of choice for building scalable write-intensive key- cludes massive-scale online analytics (Airbnb/ Airstream [2], value storage systems. An LSM store replaces random I/O Yahoo/Flurry [7]), product search and recommendation (Al- with sequential I/O by accumulating large batches of writes ibaba [13]), graph storage (Facebook/Dragon [5], Pinter- in a memory store prior to flushing them to log-structured est/Zen [19]), and many more. disk storage; the latter is continuously re-organized in the The leading approach for implementing write-intensive background through a compaction process for efficiency of key-value storage is log-structured merge (LSM) stores [31]. reads. Though inherent to the LSM design, frequent com- This technology is ubiquitously used by popular key-value pactions are a major pain point because they slow down storage platforms [9, 14, 16, 22,4,1, 10, 11]. The premise data store operations, primarily writes, and also increase for using LSM stores is the major disk access bottleneck, disk wear. Another performance bottleneck in today's state- exhibited even with today's SSD hardware [14, 33, 34]. -

Table of Contents
Table of Contents Introduction and Motivation Theoretical Foundations Distributed Programming Languages Distributed Operating Systems Distributed Communication Distributed Data Management Reliability Applications Conclusions Appendix Distributed Operating Systems Key issues Communication primitives Naming and protection Resource management Fault tolerance Services: file service, print service, process service, terminal service, file service, mail service, boot service, gateway service Distributed operating systems vs. network operating systems Commercial and research prototypes Wiselow, Galaxy, Amoeba, Clouds, and Mach Distributed File Systems A file system is a subsystem of an operating system whose purpose is to provide long-term storage. Main issues: Merge of file systems Protection Naming and name service Caching Writing policy Research prototypes: UNIX United, Coda, Andrew (AFS), Frangipani, Sprite, Plan 9, DCE/DFS, and XFS Commercial: Amazon S3, Google Cloud Storage, Microsoft Azure, SWIFT (OpenStack) Distributed Shared Memory A distributed shared memory is a shared memory abstraction what is implemented on a loosely coupled system. Distributed shared memory. Focus 24: Stumm and Zhou's Classification Central-server algorithm (nonmigrating and nonreplicated): central server (Client) Sends a data request to the central server. (Central server) Receives the request, performs data access and sends a response. (Client) Receives the response. Focus 24 (Cont’d) Migration algorithm (migrating and non- replicated): single-read/single-write (Client) If the needed data object is not local, determines the location and then sends a request. (Remote host) Receives the request and then sends the object. (Client) Receives the response and then accesses the data object (read and /or write). Focus 24 (Cont’d) Read-replication algorithm (migrating and replicated): multiple-read/single-write (Client) If the needed data object is not local, determines the location and sends a request. -

Artificial Intelligence for Understanding Large and Complex
Artificial Intelligence for Understanding Large and Complex Datacenters by Pengfei Zheng Department of Computer Science Duke University Date: Approved: Benjamin C. Lee, Advisor Bruce M. Maggs Jeffrey S. Chase Jun Yang Dissertation submitted in partial fulfillment of the requirements for the degree of Doctor of Philosophy in the Department of Computer Science in the Graduate School of Duke University 2020 Abstract Artificial Intelligence for Understanding Large and Complex Datacenters by Pengfei Zheng Department of Computer Science Duke University Date: Approved: Benjamin C. Lee, Advisor Bruce M. Maggs Jeffrey S. Chase Jun Yang An abstract of a dissertation submitted in partial fulfillment of the requirements for the degree of Doctor of Philosophy in the Department of Computer Science in the Graduate School of Duke University 2020 Copyright © 2020 by Pengfei Zheng All rights reserved except the rights granted by the Creative Commons Attribution-Noncommercial Licence Abstract As the democratization of global-scale web applications and cloud computing, under- standing the performance of a live production datacenter becomes a prerequisite for making strategic decisions related to datacenter design and optimization. Advances in monitoring, tracing, and profiling large, complex systems provide rich datasets and establish a rigorous foundation for performance understanding and reasoning. But the sheer volume and complexity of collected data challenges existing techniques, which rely heavily on human intervention, expert knowledge, and simple statistics. In this dissertation, we address this challenge using artificial intelligence and make the case for two important problems, datacenter performance diagnosis and datacenter workload characterization. The first thrust of this dissertation is the use of statistical causal inference and Bayesian probabilistic model for datacenter straggler diagnosis. -

Riak KV Performance in Sensor Data Storage Application
ISSN 2079-3316 PROGRAM SYSTEMS: THEORY AND APPLICATIONS no.3(34), 2017, pp. 61–85 N. S. Zhivchikova, Y. V. Shevchuk Riak KV performance in sensor data storage application Abstract. A sensor data storage system is an important part of data analysis systems. The duty of sensor data storage is to accept time series data from remote sources, store them and provide access to retrospective data on demand. As the number of sensors grows, the storage system scaling becomes a concern. In this article we experimentally evaluate Riak KV|a scalable distributed key-value data store as a backend for a sensor data storage system. Key words and phrases: sensor data, write performance, distributed storage, time series, Riak, Erlang. 2010 Mathematics Subject Classification: 68M20 Introduction The purpose of a sensor data storage is to store data coming in small portions from a large number of sensors. The data should be stored so as to facilitate efficient retrieval of a (possibly large) data array by sensor identifier and time interval, e.g. to draw a graph. The system is described by three parameters: the number of sensors S, incoming data rate in megabytes per second A, and the storage period Y . In single-computer implementation there are limits on S, A, Y that can't be achieved without computer upgrade to non-commodity hardware which involves disproportional system cost increase. When the system design goals exceed the S, A, Y limits reachable by a single commodity computer, a viable solution is to move to distributed architecture | using multiple commodity computers to meet the design goals. -

Myrocks in Mariadb
MyRocks in MariaDB Sergei Petrunia <[email protected]> MariaDB Shenzhen Meetup November 2017 2 What is MyRocks ● #include <Yoshinori’s talk> ● This talk is about MyRocks in MariaDB 3 MyRocks lives in Facebook’s MySQL branch ● github.com/facebook/mysql-5.6 – Will call this “FB/MySQL” ● MyRocks lives there in storage/rocksdb ● FB/MySQL is easy to use if you are Facebook ● Not so easy if you are not :-) 4 FB/mysql-5.6 – user perspective ● No binaries, no packages – Compile yourself from source ● Dependencies, etc. ● No releases – (Is the latest git revision ok?) ● Has extra features – e.g. extra counters “confuse” monitoring tools. 5 FB/mysql-5.6 – dev perspective ● Targets a CentOS-type OS – Compiler, cmake version, etc. – Others may or may not [periodically] work ● MariaDB/Percona file pull requests to fix ● Special command to compile – https://github.com/facebook/mysql-5.6/wiki/Build-Steps ● Special command to run tests – Test suite assumes a big machine ● Some tests even a release build 6 Putting MyRocks in MariaDB ● Goals – Wider adoption – Ease of use – Ease of development – Have MyRocks in MariaDB ● Use it with MariaDB features ● Means – Port MyRocks into MariaDB – Provide binaries and packages 7 Status of MyRocks in MariaDB 8 Status of MyRocks in MariaDB ● MariaDB 10.2 is GA (as of May, 2017) ● It includes an ALPHA version of MyRocks plugin – Working to improve maturity ● It’s a loadable plugin (ha_rocksdb.so) ● Packages – Bintar, deb, rpm, win64 zip + MSI – deb/rpm have MyRocks .so and tools in a separate package. 9 Packaging for MyRocks in MariaDB 10 MyRocks and RocksDB library ● MyRocks is tied RocksDB@revno MariaDB – RocksDB is a github submodule – No compatibility with other versions MyRocks ● RocksDB is always compiled with RocksDB MyRocks S Z n ● l i And linked-in statically a b p ● p Distros have a RocksDB package y – Not using it. -

Download Slides
Working with MIG • Our robust technology has been used by major broadcasters and media clients for over 7 years • Voting, Polling and Real-time Interactivity through second screen solutions • Incremental revenue generating services integrated with TV productions • Facilitate 10,000+ interactions per second as standard across our platforms • Platform and services have been audited by Deloitte and other compliant bodies • High capacity throughput for interactions, voting and transactions on a global scale • Partner of choice for BBC, ITV, Channel 5, SKY, MTV, Endemol, Fremantle and more: 1 | © 2012 Mobile Interactive Group @ QCON London mVoy Products High volume mobile messaging campaigns & mobile payments Social Interactivity & Voting via Facebook, iPhone, Android & Web Create, build, host & manage mobile commerce, mobile sites & apps Interactive messaging & multi-step marketing campaigns 2 | © 2012 Mobile Interactive Group @ QCON London MIG Technologies • Erlang • RIAK & leveldb • Redis • Ubuntu • Ruby on Rails • Java • Node.js • MongoDB • MySQL 3 | © 2012 Mobile Interactive Group @ QCON London Battle Stories • Building a wallet • Optimizing your hardware stack • Building a robust queue 4 | © 2012 Mobile Interactive Group @ QCON London Building a wallet • Fast – Over 10,000 debits / sec ( votes ) – Over 1,000 credits / sec • Scalable – Double hardware == Double performance • Robust / Recoverable – Transactions can not be lost – Wallet balances recoverable in the event of multi-server failure • Auditable – Complete transaction history -

Your Data Always Available for Applications and Users
DATASHEET RIAK® KV ENTERPRISE YOUR DATA ALWAYS AVAILABLE FOR APPLICATIONS AND USERS Companies rely on data to power their day-to- day operations. It is imperative that this data be always available. Even minutes of application RIAK KV BENEFITS downtime can mean lost sales, a poor user experience, and a bruised brand. This can add up GLOBAL AVAILABILITY to millions in lost revenue. Most databases work A distributed database with advanced local and multi-cluster at small scale, but how do you scale out, up, and replication means your data is always available. down predictably and linearly as your data grows? MASSIVE SCALABILITY You need a different database. Basho Riak® KV Automatic data distribution in the cluster and the ease of adding Enterprise is a distributed NoSQL database nodes mean near-linear performance increase as your data grows. architected to meet your application needs. Riak KV provides high availability and massive OPERATIONAL SIMPLICITY scalability. Riak KV can be operationalized at lower Easy to run, easy to add nodes to your cluster. Operations are costs than traditional relational databases and is powerful yet simple. Ensure your operations team sleeps better. easy to manage at scale. FAULT TOLERANCE Riak KV integrates with Apache Spark, Redis A masterless, multi-node architecture ensures no data loss in the event Caching, Apache Solr, and Apache Mesos of network or hardware failures. to reduce the complexity of integrating and deploying other Big Data technologies. FAST DATA ACCESS Your users expect your application to be fast. Low latency means your data requests are served predictably even during peak times. -
“Consistent Hashing”
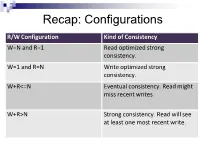
Recap: Configurations R/W Configuration Kind of Consistency W=N and R=1 Read optimized strong consistency. W=1 and R=N Write optimized strong consistency. W+R<=N Eventual consistency. Read might miss recent writes. W+R>N Strong consistency. Read will see at least one most recent write. Consistency Levels • Is there something between the extreme configurations “strong consistency” and “eventual consistency”? • Consider a client is working with a key value store Recap: Distributed Setup • N copies per record/object, spread across servers Client node4 node1 node2 node… node … node3 Client-Centric Consistency and Seen Writes Client-Centric Consistency: provides guarantees for a single client concerning the consistency of the accesses to a data store by that client. A client reading a value for a key is seeing a subset of the writes to this key; given the past history of writes by itself and other clients. Client-Centric Read Consistency Guarantees Guarantee Explanation Strong Consistency See all previous writes. Eventual Consistency See (any) subset of previous writes. Consistent Prefix See initial sequence of writes. Bounded Staleness See all “old” writes. E.g., everything older than 10 minutes. Monotonic Reads See increasing subset of writes. Read My Writes See all writes performed by reader. Causal Consistency • Consistency issues…. Our dog, Charlie, ran away today. Can’t find him, Alice we are afraid he got overrun by a car! Posted at 9:30am Thank God! I am so glad to hear this! Bob Posted at 10:20am Causal Consistency (2) • How it was supposed to appear…. Our dog, Charlie, ran away today. -

Myrocks Deployment at Facebook and Roadmaps
MyRocks deployment at Facebook and Roadmaps Yoshinori Matsunobu Production Engineer / MySQL Tech Lead, Facebook Feb/2018, #FOSDEM #mysqldevroom Agenda ▪ MySQL at Facebook ▪ MyRocks overview ▪ Production Deployment ▪ Future Plans MySQL “User Database (UDB)” at Facebook▪ Storing Social Graph ▪ Massively Sharded ▪ Low latency ▪ Automated Operations ▪ Pure Flash Storage (Constrained by space, not by CPU/IOPS) What is MyRocks ▪ MySQL on top of RocksDB (RocksDB storage engine) ▪ Open Source, distributed from MariaDB and Percona as well MySQL Clients SQL/Connector Parser Optimizer Replication etc InnoDB RocksDB MySQL http://myrocks.io/ MyRocks Initial Goal at Facebook InnoDB in main database MyRocks in main database CPU IO Space CPU IO Space Machine limit Machine limit 45% 90% 21% 15% 45% 20% 15% 21% 15% MyRocks features ▪ Clustered Index (same as InnoDB) ▪ Bloom Filter and Column Family ▪ Transactions, including consistency between binlog and RocksDB ▪ Faster data loading, deletes and replication ▪ Dynamic Options ▪ TTL ▪ Online logical and binary backup MyRocks vs InnoDB ▪ MyRocks pros ▪ Much smaller space (half compared to compressed InnoDB) ▪ Gives better cache hit rate ▪ Writes are faster = Faster Replication ▪ Much smaller bytes written (can use more afordable fash storage) ▪ MyRocks cons (improvements in progress) ▪ Lack of several features ▪ No SBR, Gap Lock, Foreign Key, Fulltext Index, Spatial Index support. Need to use case sensitive collation for perf ▪ Reads are slower, especially if your data fts in memory ▪ More dependent on flesystem -

Etriks Analytical Environment: a Practical Platform for Medical Big Data Analysis
Imperial College of Science, Technology and Medicine Department of Computing eTRIKS Analytical Environment: A Practical Platform for Medical Big Data Analysis Axel Oehmichen Submitted in part fulfilment of the requirements for the degree of Doctor of Philosophy in Computing of Imperial College London December 2018 Abstract Personalised medicine and translational research have become sciences driven by Big Data. Healthcare and medical research are generating more and more complex data, encompassing clinical investigations, 'omics, imaging, pharmacokinetics, Next Generation Sequencing and beyond. In addition to traditional collection methods, economical and numerous information sensing IoT devices such as mobile devices, smart sensors, cameras or connected medical de- vices have created a deluge of data that research institutes and hospitals have difficulties to deal with. While the collection of data is greatly accelerating, improving patient care by devel- oping personalised therapies and new drugs depends increasingly on an organization's ability to rapidly and intelligently leverage complex molecular and clinical data from that variety of large-scale heterogeneous data sources. As a result, the analysis of these datasets has become increasingly computationally expensive and has laid bare the limitations of current systems. From the patient perspective, the advent of electronic medical records coupled with so much personal data being collected have raised concerns about privacy. Many countries have intro- duced laws to protect people's privacy, however, many of these laws have proven to be less effective in practice. Therefore, along with the capacity to process the humongous amount of medical data, the addition of privacy preserving features to protect patients' privacy has become a necessity.