Making Containers Lazy with Docker and Cernvm-FS
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Refresh Your Data Lake to Cisco Data Intelligence Platform
Solution overview Cisco public Refresh Your Data Lake to Cisco Data Intelligence Platform The evolving Hadoop landscape Consideration in the journey In the beginning of 2019, providers of leading Hadoop distribution, Hortonworks and Cloudera of a Hadoop refresh merged together. This merger raised the bar on innovation in the big data space and the new Despite the capability gap between “Cloudera” launched Cloudera Data Platform (CDP) which combined the best of Hortonwork’s and Cloudera’s technologies to deliver the industry leading first enterprise data cloud. Recently, Hadoop 2.x and 3.x, it is estimated that Cloudera released the CDP Private Cloud Base, which is the on-premises version of CDP. This more than 80 percent of the Hadoop unified distribution brought in several new features, optimizations, and integrated analytics. installed base is still on either HDP2 or CDH5, which are built on Apache Hadoop CDP Private Cloud Base is built on Hadoop 3.x distribution. Hadoop developed several 2.0, and are getting close to end of capabilities since its inception. However, Hadoop 3.0 is an eagerly awaited major release support by the end of 2020. with several new features and optimizations. Upgrading from Hadoop 2.x to 3.0 is a paradigm shift as it enables diverse computing resources, (i.e., CPU, GPU, and FPGA) to work on data Amid those feature enrichments, and leverage AI/ML methodologies. It supports flexible and elastic containerized workloads, specialized computing resources, and managed either by Hadoop scheduler (i.e., YARN or Kubernetes), distributed deep learning, end of support, a Hadoop upgrade is a GPU-enabled Spark workloads, and more. -

Reference Architecture
REFERENCE ARCHITECTURE Service Providers Data Center Build a High-Performance Object Storage-as-a-Service Platform with Minio* Storage-as-a-service (STaaS) based on Minio* with Intel® technology simplifies object storage while providing high performance, scalability, and enhanced security features Executive Summary What You’ll Find in This Solution Reference Architecture: This Emerging cloud service providers (CSPs) have an opportunity to build or expand solution provides a starting point for their storage-as-a-service (STaaS) capabilities and tap into one of today’s fastest- developing a storage-as-a-service growing markets. However, CSPs who support this market face a substantial (STaaS) platform based on Minio*. challenge: how to cost effectively store an exponentially growing amount of If you are responsible for: data while exposing the data as a service with high performance, scalability • Investment decisions and and security. business strategy: You’ll learn how Minio-based STaaS can File and block protocols are complex, have legacy architectures that hold back help solve the pressing storage innovation, and are limited in their ability to scale. Object storage, which was challenges facing cloud service born in the cloud, solves these issues with a reduced set of storage APIs that are providers (CSPs) today. accessed over HTTP RESTful services. Hyperscalers have looked into many options • Figuring out how to implement when building the foundation of their cloud storage infrastructure and they all have STaaS and Minio: You’ll adopted object storage as their primary storage service. learn about the architecture components and how they work In this paper, we take a deeper look into an Amazon S3*-compatible object storage together to create a cohesive service architecture—a STaaS platform based on Minio* Object Storage and business solution. -

Continuous Delivery for Kubernetes Apps with Helm and Chartmuseum
Webinar Continuous Delivery for Kubernetes Apps with Helm and ChartMuseum Josh Dolitsky Stef Arnold Software Engineer Sr. Software Engineer Codefresh SUSE Webinar Outline Continuous Delivery for Kubernetes Apps 1. Intro to Helm with Helm and 2. Helm Commands 3. Intro to ChartMuseum ChartMuseum 4. ChartMuseum functions 5. CI/CD Pipeline 6. SUSE + Codefresh = <3 7. Demo Josh Dolitsky Stef Arnold Software Engineer Sr. Software Engineer Codefresh SUSE What is Helm? ● Helm is the package manager for Kubernetes ● Equivalent to “yum install <package>” ● Kubernetes manifest templates, packaged and versioned, referred to as charts Helm Use Cases ● Like other package managers Helm manages packages and their dependencies, and their installation. ● fetch, search, lint, and package are available client-side for authoring charts ● List, install, upgrade, delete, rollback for operations (makes use of server component Tiller) Helm use case mini demo See how we can interact with our application or just its configuration using helm. Helm Use Cases ● Where do the packages live? ● What is a Helm repository anyway? index.yaml! What’s the problem? How do multiple teams/devs publish their charts to a single repository at the same time? Team A Team B The Problem $ helm package charta/ $ helm package chartb/ $ aws s3 cp charta-0.1.0.tgz s3://mycharts/ possible $ aws s3 cp chartb-0.1.0.tgz s3://mycharts/ race condition $ aws s3 cp s3://mycharts/index.yaml stale.yaml $ aws s3 cp s3://mycharts/index.yaml stale.yaml $ helm repo index --merge stale.yaml . $ helm repo index --merge stale.yaml . $ aws s3 cp index.yaml s3://mycharts/ $ aws s3 cp index.yaml s3://mycharts/ Team A Team B The Solution $ helm package charta/ $ helm package chartb/ $ aws s3 cp charta-0.1.0.tgz s3://mycharts/ $ aws s3 cp chartb-0.1.0.tgz s3://mycharts/ Features - Multiple storage options ● Local filesystem ● Amazon S3 (and Minio) ● Google Cloud Storage ● Microsoft Azure Blob Storage ● Alibaba Cloud OSS Storage ● Openstack Object Storage Features - API for uploading charts etc. -

Security and Cryptography in GO
Masaryk University Faculty of Informatics Security and cryptography in GO Bachelor’s Thesis Lenka Svetlovská Brno, Spring 2017 Masaryk University Faculty of Informatics Security and cryptography in GO Bachelor’s Thesis Lenka Svetlovská Brno, Spring 2017 This is where a copy of the official signed thesis assignment and a copy ofthe Statement of an Author is located in the printed version of the document. Declaration Hereby I declare that this paper is my original authorial work, which I have worked out on my own. All sources, references, and literature used or excerpted during elaboration of this work are properly cited and listed in complete reference to the due source. Lenka Svetlovská Advisor: RNDr. Andriy Stetsko, Ph.D. i Acknowledgement I would like to thank RNDr. Andriy Stetsko, Ph.D. for the manage- ment of the bachelor thesis, valuable advice, and comments. I would also like to thank the consultant from Y Soft Corporation a.s., Mgr. Lenka Bačinská, for useful advice, dedicated time and patience in consultations and application development. Likewise, I thank my family and friends for their support through- out my studies and writing this thesis. iii Abstract The main goal of this bachelor thesis is an implementation of an ap- plication able to connect to a server using pre-shared key cipher suite, communicate with server and support of X.509 certificates, such as generation of asymmetric keys, certificate signing request and different formats. The application is implemented in language Go. The very first step involves looking for suitable Go library which can connect to a server using pre-shared key cipher suite, and work with cryptography and X.509 certificates. -

Minio Partners with Vmware to Bring Cloud-Native Object Storage to VCF with Tanzu Customers
REPORT REPRINT MinIO partners with VMware to bring cloud-native object storage to VCF with Tanzu customers SEPTEMBER 21 2020 By Liam Rogers, Steven Hill Software-defined object storage vendor MinIO supports cloud-native applications, including those running on Kubernetes. Now the vendor has unveiled a new partnership with VMware to provide object storage to customers using VMware Cloud Foundation with Tanzu. THIS REPORT, LICENSED TO MINIO, DEVELOPED AND AS PROVIDED BY 451 RESEARCH, LLC, WAS PUBLISHED AS PART OF OUR SYNDICATED MARKET INSIGHT SUBSCRIPTION SERVICE. IT SHALL BE OWNED IN ITS ENTIRETY BY 451 RESEARCH, LLC. THIS REPORT IS SOLELY INTENDED FOR USE BY THE RECIPIENT AND MAY NOT BE REPRODUCED OR RE-POSTED, IN WHOLE OR IN PART, BY THE RECIPIENT WITHOUT EXPRESS PERMISSION FROM 451 RESEARCH. ©2020 451 Research, LLC | WWW.451RESEARCH.COM REPORT REPRINT Introduction MinIO specializes in open source high-performance and highly scalable software-defined and cloud- native object storage. The company has continued to refine its software by adding enterprise-grade features such as object locking and key encryption as well as quality-of-life features such as a new management UI. Now MinIO has partnered with VMware to integrate MinIO object storage into the latest Tanzu release, which the vendor hopes will open up significant new go-to-market opportunities. 451 TAKE MinIO is not the only open source object storage software on the market, but where the vendor differentiates is its focus on performance and supporting cloud-native applications. Object storage, especially in the cloud, is often associated with the notion of being ‘cheap and deep.’ However, while MinIO has made its platform easily consumable like competing cloud object stores, the vendor has prioritized making the platform performant, enterprise ready and not just for read-only use cases. -

Full Stack Template Full Stack?
UNIVERSITY OF CRETE COMPUTER SCIENCE DEPARTMENT COURSE CS-469 (OPTIONAL) MODERN TOPICS IN HUMAN – COMPUTER INTERACTION Full Stack Template Full Stack? ▪ Full Stack development refers to the development of an application for both front-end and back-end ▪ A full stack developer usually knows how to program a webpage, a server and a database ▪ Popular Stacks: ▪ LAMP stack: JavaScript - Linux - Apache - MySQL - PHP ▪ LEMP stack: JavaScript - Linux - Nginx - MySQL - PHP ▪ MEAN stack: JavaScript - MongoDB - Express - AngularJS - Node.js ▪ Django stack: JavaScript - Python - Django - MySQL ▪ RuBy on Rails: JavaScript - RuBy - SQLite - PHP CS-469: Modern Topics in Human – Computer Interaction 2 MEAN stack ▪ We recommend to use our given full stack template that is based on the MEAN stack ▪ Mean stack stands for MongoDB, Express.js, Angular, and Node.js ▪ Front-end: Angular ▪ Back-end: NoDe.js with express framework ▪ Database: MongoDB CS-469: Modern Topics in Human – Computer Interaction 3 Fullstack template variants • Verbose • Docker-based (requires Win10 Professional) Verbose variant (1/6) ▪ Install LTS version of Node.js https://nodejs.org/en/ ▪ Install the Angular CLI running the command 'npm install -g @angular/cli’ on terminal (node.js should be installed first) ▪ Download Redis for Windows from https://github.com/microsoftarchive/redis/releases/tag/win-3.0.504 ▪ Download Minio server from https://min.io/download#/windows Verbose variant (2/6) ▪ MongoDB Download MongoDB community server https://www.mongodb.com/try/download/community and -

Minio in Healthcare
MinIO in Healthcare FEBRUARY 2020 1 The healthcare industry is unique in so many ways. To begin with, it lacks a common objective function on which to optimize. This is because different healthcare organizations, both payers and providers, value different things. Profitability is not the universal goal - there are teaching hospitals, faith-based hospitals and not-for-profit insurance plans. Consider also that a large portion of the industry is guided by a 2,500-year oath at the point of interaction. Further, healthcare is at once highly regulated and process-driven yet intensely personalized. The list goes on with each example underscoring how different healthcare is from other industries. Despite the uniqueness of the industry, it does share a common challenge with every other industry - that of managing and extracting value from their data. Healthcare produces a disproportionate share of the world’s data - estimated at 30% of electronic storage. More importantly, the rate of growth is stunning. An IDC/DellEMC report found that between 2016 and 2018, data grew from 1.45 PB to 9.70 PB or 878%. Assuming that growth rate has not abated - which is conservative - those healthcare organizations would now be managing close to 100 PB each. The volume of data and the attendant growth rate have required the healthcare industry to radically re-evaluate their storage architecture. What was a solved problem four years ago is now the primary challenge facing the industry - even larger than analytics. The most sophisticated payers, providers and technology vendors have come to the realization that object storage, whether in the cloud or on-premises is the answer. -
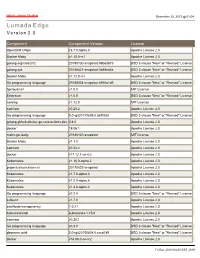
Lumada Edge Version
Hitachi - Inspire The Next December 20, 2019 @ 01:04 Lumada Edge V e r s i o n 3 . 0 Component Component Version License OpenShift Origin v3.7.0-alpha.0 Apache License 2.0 Docker Moby v1.10.0-rc1 Apache License 2.0 golang.org/x/oauth2 20190130-snapshot-99b60b75 BSD 3-clause "New" or "Revised" License golang sys 20180821-snapshot-3b58ed4a BSD 3-clause "New" or "Revised" License Docker Moby v1.12.0-rc1 Apache License 2.0 Go programming language 20180824-snapshot-4910a1d5 BSD 3-clause "New" or "Revised" License hpcloud-tail v1.0.0 MIT License Ethereum v1.5.0 BSD 3-clause "New" or "Revised" License zerolog v1.12.0 MIT License cadvisor v0.28.2 Apache License 2.0 Go programming language 0.0~git20170629.0.5ef0053 BSD 3-clause "New" or "Revised" License golang-github-docker-go-connections-dev 0.4.0 Apache License 2.0 docker 18.06.1 Apache License 2.0 mattn-go-isatty 20180120-snapshot MIT License Docker Moby v1.1.0 Apache License 2.0 cadvisor v0.23.4 Apache License 2.0 docker v17.12.1-ce-rc2 Apache License 2.0 Kubernetes v1.15.0-alpha.2 Apache License 2.0 projectcalico/calico-cni 20170522-snapshot Apache License 2.0 Kubernetes v1.7.0-alpha.3 Apache License 2.0 Kubernetes v1.2.0-alpha.6 Apache License 2.0 Kubernetes v1.4.0-alpha.2 Apache License 2.0 Go programming language v0.2.0 BSD 3-clause "New" or "Revised" License kubevirt v1.7.0 Apache License 2.0 certificate-transparency 1.0.21 Apache License 2.0 kubernetes/api kubernetes-1.15.0 Apache License 2.0 cadvisor v0.28.1 Apache License 2.0 Go programming language v0.3.0 BSD 3-clause "New" or "Revised" -

Autoscaling Ekyc Machine Learning Workloads to 2M+ Req/Day
One2n Consulting_ Case Study: AutoScaling eKYC Machine Learning workloads to 2M+ req/day Context: The client provides eKYC SaaS APIs (facematching, OCR, etc.) accessible via Android SDK to its B2B customers. This was deployed for a major Telecom in India and needed to scale upto 2M+ API requests per day. The tech stack consisted of a Golang based API, Python based Machine Learning models, a Message queue (RabbitMQ), Distributed blob storage (Minio) and PostgreSQL DB deployed via docker on Google Cloud using Hashicorp toolchain (Nomad, Consul). Problem Statement: ● Cost optimization. During the pilot phase, cloud costs were USD 5k per month. For go live, expected traffic was 20 to 30x of pilot traffic. Here, the cost of GPU VMs (for ML workloads) was a dominating factor (90% share). This would have pushed the cloud costs to USD 100k per month without auto scaling. ● Ensuring 99% availability of services during business hours (8am-10pm). ● Ensuring < 3 sec API latency for 95th percentile. Solution: In the final Auto Scaling solution, we needed a manual override option. At that time, both Nomad and Kubernetes did not provide this capability out of the box. Also, migrating to Kubernetes would have meant a lot of rework for the entire team. Hence, we decided to build a custom auto scaling solution on top of Nomad and existing toolchains used in the project. Autoscaler runs every 20 minutes, predicts the traffic for the next cycle and ensures that required ML workers are available. Same logic works for scale up as well as scale down. One2n Consulting_ Some of the other challenges we encountered were as follows: ● Eliminate single points of failure ○ Run RabbitMQ in High Availability mode with queue replication across three zones in GCP. -

Latest
deepforge Documentation Brian Broll Sep 17, 2021 Getting Started 1 Getting Started 1 2 Quick Start 3 3 Interface Overview 5 4 Custom Operations 13 5 Storage and Compute Adapters 19 6 Quick Start 21 7 Overview 23 8 Native Installation 25 9 Introduction 29 10 Creating Pipelines 31 11 Creating Operations 35 12 Creating Neural Networks 39 13 Executing Pipelines 45 14 Viewing Executions 49 15 CIFAR-10 Classifier 53 16 Redshift Estimator 69 17 Tutorial Project - Redshift 87 18 Redshift Estimation 95 19 Command Line Interface 99 20 Configuration 101 i 21 Operation Feedback 103 ii CHAPTER 1 Getting Started 1.1 What is DeepForge? Deep learning is a promising, yet complex, area of machine learning. This complexity can both create a barrier to entry for those wanting to get involved in deep learning as well as slow the development of those already comfortable in deep learning. DeepForge is a development environment for deep learning focused on alleviating these problems. Leveraging prin- ciples from Model-Driven Engineering, DeepForge is able to reduce the complexity of using deep learning while providing an opportunity for integrating with other domain specific modeling environments created with WebGME. 1.2 Design Goals As mentioned above, DeepForge focuses on two main goals: 1. Improving the efficiency of experienced data scientists/researchers in deep learning 2. Lowering the barrier to entry for newcomers to deep learning It is important to highlight that although one of the goals is focused on lowering the barrier to entry, DeepForge is intended to be more than simply an educational tool; that is, it is important not to compromise on flexibility and effectiveness as a research/industry tool in order to provide an easier experience for beginners (that’s what forks are for!). -

Modern Endpoint Management
Technical Documentation RayManageSoft Unified Endpoint Manager is part of RaySuite UEM Content Modern Endpoint Management ............................................................................................................ 3 Scope of functions .................................................................................................................................. 3 Architecture ........................................................................................................................................ 3 Console ............................................................................................................................................... 3 Software/Application Management .................................................................................................. 4 Connection Management .................................................................................................................. 4 PIM Management ............................................................................................................................... 4 Vulnerability Management ................................................................................................................. 4 Security Management ........................................................................................................................ 5 Content Management ........................................................................................................................ 5 Data Management ............................................................................................................................. -

There's Nothing 'Mini' About How Minio Approaches Object Storage
REPORT REPRINT There’s nothing ‘mini’ about how MinIO approaches object storage NOVEMBER 27 2019 By Steven Hill, Liam Rogers Thanks to vendors like MinIO, object storage is starting to be recognized as the flexible and powerful storage platform of the future as it combines metadata-rich visibility and governance with the performance needed for analytics and other data-intensive workloads. THIS REPORT, LICENSED TO MINIO, DEVELOPED AND AS PROVIDED BY 451 RESEARCH, LLC, WAS PUBLISHED AS PART OF OUR SYNDICATED MARKET INSIGHT SUBSCRIPTION SERVICE. IT SHALL BE OWNED IN ITS ENTIRETY BY 451 RESEARCH, LLC. THIS REPORT IS SOLELY INTENDED FOR USE BY THE RECIPIENT AND MAY NOT BE REPRODUCED OR RE-POSTED, IN WHOLE OR IN PART, BY THE RECIPIENT WITHOUT EXPRESS PERMISSION FROM 451 RESEARCH. ©2019 451 Research, LLC | WWW.451RESEARCH.COM REPORT REPRINT Introduction With its open source, distributed high-performance object storage platform, MinIO is directly targeting large-scale, unstructured data workloads, referencing high-end use cases such as big data and machine learning where the volumes of data involved can be very large. The company claims to provide native performance and efficiency that other object storage offerings aren’t geared for. 451 TAKE We believe that object storage is a technology still waiting to be used to its full potential, and that future enterprises will need to adopt a model that efficiently combines file and object to deal with the overwhelming challenges caused by unstructured data growth. MinIO’s open source object platform offers a highly efficient, lightweight and cloud- native approach to offering high-performance object storage, along with a substantial list of enterprise-class data protection and management capabilities.