Protein Interaction Network-Based Deep Learning Framework for Identifying Disease-Associated Human Proteins
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

The Kyoto Encyclopedia of Genes and Genomes (KEGG)
Kyoto Encyclopedia of Genes and Genome Minoru Kanehisa Institute for Chemical Research, Kyoto University HFSPO Workshop, Strasbourg, November 18, 2016 The KEGG Databases Category Database Content PATHWAY KEGG pathway maps Systems information BRITE BRITE functional hierarchies MODULE KEGG modules KO (KEGG ORTHOLOGY) KO groups for functional orthologs Genomic information GENOME KEGG organisms, viruses and addendum GENES / SSDB Genes and proteins / sequence similarity COMPOUND Chemical compounds GLYCAN Glycans Chemical information REACTION / RCLASS Reactions / reaction classes ENZYME Enzyme nomenclature DISEASE Human diseases DRUG / DGROUP Drugs / drug groups Health information ENVIRON Health-related substances (KEGG MEDICUS) JAPIC Japanese drug labels DailyMed FDA drug labels 12 manually curated original DBs 3 DBs taken from outside sources and given original annotations (GENOME, GENES, ENZYME) 1 computationally generated DB (SSDB) 2 outside DBs (JAPIC, DailyMed) KEGG is widely used for functional interpretation and practical application of genome sequences and other high-throughput data KO PATHWAY GENOME BRITE DISEASE GENES MODULE DRUG Genome Molecular High-level Practical Metagenome functions functions applications Transcriptome etc. Metabolome Glycome etc. COMPOUND GLYCAN REACTION Funding Annual budget Period Funding source (USD) 1995-2010 Supported by 10+ grants from Ministry of Education, >2 M Japan Society for Promotion of Science (JSPS) and Japan Science and Technology Agency (JST) 2011-2013 Supported by National Bioscience Database Center 0.8 M (NBDC) of JST 2014-2016 Supported by NBDC 0.5 M 2017- ? 1995 KEGG website made freely available 1997 KEGG FTP site made freely available 2011 Plea to support KEGG KEGG FTP academic subscription introduced 1998 First commercial licensing Contingency Plan 1999 Pathway Solutions Inc. -

The Rat Genome Database at 20: a Multi-Species Knowledgebase and Analysis Platform Jennifer R
Published online 12 November 2019 Nucleic Acids Research, 2020, Vol. 48, Database issue D731–D742 doi: 10.1093/nar/gkz1041 The Year of the Rat: The Rat Genome Database at 20: a multi-species knowledgebase and analysis platform Jennifer R. Smith 1,*, G. Thomas Hayman1, Shur-Jen Wang1, Stanley J.F. Laulederkind 1, Matthew J. Hoffman1,2, Mary L. Kaldunski 1, Monika Tutaj1, Jyothi Thota1,Harika S. Nalabolu1, Santoshi L.R. Ellanki1, Marek A. Tutaj1, Jeffrey L. De Pons1, Anne E. Kwitek2, Melinda R. Dwinell2 and Mary E. Shimoyama1 1Rat Genome Database, Department of Biomedical Engineering, Medical College of Wisconsin, Milwaukee, WI 53226, USA and 2Genomic Sciences and Precision Medicine Center and Department of Physiology, Medical College of Wisconsin, Milwaukee, WI 53226, USA Received September 15, 2019; Revised October 21, 2019; Editorial Decision October 22, 2019; Accepted October 24, 2019 ABSTRACT In contrast to the current wealth of data and tools, the ‘bare bones’ first iteration (Figure 1,Table1) focused on just a few Formed in late 1999, the Rat Genome Database (RGD, data types––most notably a handful of known genes, plus https://rgd.mcw.edu) will be 20 in 2020, the Year of the EST and SSLP markers––localized only on genetic and RH Rat. Because the laboratory rat, Rattus norvegicus, maps, and offered a minimal number of tools for searching has been used as a model for complex human dis- and analyzing that data. eases such as cardiovascular disease, diabetes, can- Even before the first public release of the rat reference cer, neurological disorders and arthritis, among oth- genome in 2002 (1), RGD was focused on mapping disease- ers, for >150 years, RGD has always been disease- related regions and on comparative genomics between rat, focused and committed to providing data and tools human and mouse to support the use of rat as a model for for researchers doing comparative genomics and human disease. -

Protein Identities in Evs Isolated from U87-MG GBM Cells As Determined by NG LC-MS/MS
Protein identities in EVs isolated from U87-MG GBM cells as determined by NG LC-MS/MS. No. Accession Description Σ Coverage Σ# Proteins Σ# Unique Peptides Σ# Peptides Σ# PSMs # AAs MW [kDa] calc. pI 1 A8MS94 Putative golgin subfamily A member 2-like protein 5 OS=Homo sapiens PE=5 SV=2 - [GG2L5_HUMAN] 100 1 1 7 88 110 12,03704523 5,681152344 2 P60660 Myosin light polypeptide 6 OS=Homo sapiens GN=MYL6 PE=1 SV=2 - [MYL6_HUMAN] 100 3 5 17 173 151 16,91913397 4,652832031 3 Q6ZYL4 General transcription factor IIH subunit 5 OS=Homo sapiens GN=GTF2H5 PE=1 SV=1 - [TF2H5_HUMAN] 98,59 1 1 4 13 71 8,048185945 4,652832031 4 P60709 Actin, cytoplasmic 1 OS=Homo sapiens GN=ACTB PE=1 SV=1 - [ACTB_HUMAN] 97,6 5 5 35 917 375 41,70973209 5,478027344 5 P13489 Ribonuclease inhibitor OS=Homo sapiens GN=RNH1 PE=1 SV=2 - [RINI_HUMAN] 96,75 1 12 37 173 461 49,94108966 4,817871094 6 P09382 Galectin-1 OS=Homo sapiens GN=LGALS1 PE=1 SV=2 - [LEG1_HUMAN] 96,3 1 7 14 283 135 14,70620005 5,503417969 7 P60174 Triosephosphate isomerase OS=Homo sapiens GN=TPI1 PE=1 SV=3 - [TPIS_HUMAN] 95,1 3 16 25 375 286 30,77169764 5,922363281 8 P04406 Glyceraldehyde-3-phosphate dehydrogenase OS=Homo sapiens GN=GAPDH PE=1 SV=3 - [G3P_HUMAN] 94,63 2 13 31 509 335 36,03039959 8,455566406 9 Q15185 Prostaglandin E synthase 3 OS=Homo sapiens GN=PTGES3 PE=1 SV=1 - [TEBP_HUMAN] 93,13 1 5 12 74 160 18,68541938 4,538574219 10 P09417 Dihydropteridine reductase OS=Homo sapiens GN=QDPR PE=1 SV=2 - [DHPR_HUMAN] 93,03 1 1 17 69 244 25,77302971 7,371582031 11 P01911 HLA class II histocompatibility antigen, -

Precise Generation of Systems Biology Models from KEGG Pathways Clemens Wrzodek*,Finjabuchel,¨ Manuel Ruff, Andreas Drager¨ and Andreas Zell
Wrzodek et al. BMC Systems Biology 2013, 7:15 http://www.biomedcentral.com/1752-0509/7/15 METHODOLOGY ARTICLE OpenAccess Precise generation of systems biology models from KEGG pathways Clemens Wrzodek*,FinjaBuchel,¨ Manuel Ruff, Andreas Drager¨ and Andreas Zell Abstract Background: The KEGG PATHWAY database provides a plethora of pathways for a diversity of organisms. All pathway components are directly linked to other KEGG databases, such as KEGG COMPOUND or KEGG REACTION. Therefore, the pathways can be extended with an enormous amount of information and provide a foundation for initial structural modeling approaches. As a drawback, KGML-formatted KEGG pathways are primarily designed for visualization purposes and often omit important details for the sake of a clear arrangement of its entries. Thus, a direct conversion into systems biology models would produce incomplete and erroneous models. Results: Here, we present a precise method for processing and converting KEGG pathways into initial metabolic and signaling models encoded in the standardized community pathway formats SBML (Levels 2 and 3) and BioPAX (Levels 2 and 3). This method involves correcting invalid or incomplete KGML content, creating complete and valid stoichiometric reactions, translating relations to signaling models and augmenting the pathway content with various information, such as cross-references to Entrez Gene, OMIM, UniProt ChEBI, and many more. Finally, we compare several existing conversion tools for KEGG pathways and show that the conversion from KEGG to BioPAX does not involve a loss of information, whilst lossless translations to SBML can only be performed using SBML Level 3, including its recently proposed qualitative models and groups extension packages. -

The Function of NM23-H1/NME1 and Its Homologs in Major Processes Linked to Metastasis
University of Dundee The Function of NM23-H1/NME1 and Its Homologs in Major Processes Linked to Metastasis Mátyási, Barbara; Farkas, Zsolt; Kopper, László; Sebestyén, Anna; Boissan, Mathieu; Mehta, Anil Published in: Pathology and Oncology Research DOI: 10.1007/s12253-020-00797-0 Publication date: 2020 Licence: CC BY Document Version Publisher's PDF, also known as Version of record Link to publication in Discovery Research Portal Citation for published version (APA): Mátyási, B., Farkas, Z., Kopper, L., Sebestyén, A., Boissan, M., Mehta, A., & Takács-Vellai, K. (2020). The Function of NM23-H1/NME1 and Its Homologs in Major Processes Linked to Metastasis. Pathology and Oncology Research, 26(1), 49-61. https://doi.org/10.1007/s12253-020-00797-0 General rights Copyright and moral rights for the publications made accessible in Discovery Research Portal are retained by the authors and/or other copyright owners and it is a condition of accessing publications that users recognise and abide by the legal requirements associated with these rights. • Users may download and print one copy of any publication from Discovery Research Portal for the purpose of private study or research. • You may not further distribute the material or use it for any profit-making activity or commercial gain. • You may freely distribute the URL identifying the publication in the public portal. Take down policy If you believe that this document breaches copyright please contact us providing details, and we will remove access to the work immediately and investigate your -

Biocuration 2016 - Posters
Biocuration 2016 - Posters Source: http://www.sib.swiss/events/biocuration2016/posters 1 RAM: A standards-based database for extracting and analyzing disease-specified concepts from the multitude of biomedical resources Jinmeng Jia and Tieliu Shi Each year, millions of people around world suffer from the consequence of the misdiagnosis and ineffective treatment of various disease, especially those intractable diseases and rare diseases. Integration of various data related to human diseases help us not only for identifying drug targets, connecting genetic variations of phenotypes and understanding molecular pathways relevant to novel treatment, but also for coupling clinical care and biomedical researches. To this end, we built the Rare disease Annotation & Medicine (RAM) standards-based database which can provide reference to map and extract disease-specified information from multitude of biomedical resources such as free text articles in MEDLINE and Electronic Medical Records (EMRs). RAM integrates disease-specified concepts from ICD-9, ICD-10, SNOMED-CT and MeSH (http://www.nlm.nih.gov/mesh/MBrowser.html) extracted from the Unified Medical Language System (UMLS) based on the UMLS Concept Unique Identifiers for each Disease Term. We also integrated phenotypes from OMIM for each disease term, which link underlying mechanisms and clinical observation. Moreover, we used disease-manifestation (D-M) pairs from existing biomedical ontologies as prior knowledge to automatically recognize D-M-specific syntactic patterns from full text articles in MEDLINE. Considering that most of the record-based disease information in public databases are textual format, we extracted disease terms and their related biomedical descriptive phrases from Online Mendelian Inheritance in Man (OMIM), National Organization for Rare Disorders (NORD) and Orphanet using UMLS Thesaurus. -

Genome Sequence of the Brown Norway Rat Yields Insights Into Mammalian Evolution
articles Genome sequence of the Brown Norway rat yields insights into mammalian evolution Rat Genome Sequencing Project Consortium* *Lists of participants and affiliations appear at the end of the paper ........................................................................................................................................................................................................................... The laboratory rat (Rattus norvegicus) is an indispensable tool in experimental medicine and drug development, having made inestimable contributions to human health. We report here the genome sequence of the Brown Norway (BN) rat strain. The sequence represents a high-quality ‘draft’ covering over 90% of the genome. The BN rat sequence is the third complete mammalian genome to be deciphered, and three-way comparisons with the human and mouse genomes resolve details of mammalian evolution. This first comprehensive analysis includes genes and proteins and their relation to human disease, repeated sequences, comparative genome-wide studies of mammalian orthologous chromosomal regions and rearrangement breakpoints, reconstruc- tion of ancestral karyotypes and the events leading to existing species, rates of variation, and lineage-specific and lineage- independent evolutionary events such as expansion of gene families, orthology relations and protein evolution. Darwin believed that “natural selection will always act very slowly, primate: (1) These rodent genomic changes include approximately often only at long intervals of time”1. -

Development and Validation of a Protein-Based Risk Score for Cardiovascular Outcomes Among Patients with Stable Coronary Heart Disease
Supplementary Online Content Ganz P, Heidecker B, Hveem K, et al. Development and validation of a protein-based risk score for cardiovascular outcomes among patients with stable coronary heart disease. JAMA. doi: 10.1001/jama.2016.5951 eTable 1. List of 1130 Proteins Measured by Somalogic’s Modified Aptamer-Based Proteomic Assay eTable 2. Coefficients for Weibull Recalibration Model Applied to 9-Protein Model eFigure 1. Median Protein Levels in Derivation and Validation Cohort eTable 3. Coefficients for the Recalibration Model Applied to Refit Framingham eFigure 2. Calibration Plots for the Refit Framingham Model eTable 4. List of 200 Proteins Associated With the Risk of MI, Stroke, Heart Failure, and Death eFigure 3. Hazard Ratios of Lasso Selected Proteins for Primary End Point of MI, Stroke, Heart Failure, and Death eFigure 4. 9-Protein Prognostic Model Hazard Ratios Adjusted for Framingham Variables eFigure 5. 9-Protein Risk Scores by Event Type This supplementary material has been provided by the authors to give readers additional information about their work. Downloaded From: https://jamanetwork.com/ on 10/02/2021 Supplemental Material Table of Contents 1 Study Design and Data Processing ......................................................................................................... 3 2 Table of 1130 Proteins Measured .......................................................................................................... 4 3 Variable Selection and Statistical Modeling ........................................................................................ -

Assessing the Human Canonical Protein Count[Version 1; Peer Review
F1000Research 2017, 6:448 Last updated: 15 JUL 2020 REVIEW Last rolls of the yoyo: Assessing the human canonical protein count [version 1; peer review: 1 approved, 2 approved with reservations] Christopher Southan IUPHAR/BPS Guide to Pharmacology, Centre for Integrative Physiology, University of Edinburgh, Edinburgh, EH8 9XD, UK First published: 07 Apr 2017, 6:448 Open Peer Review v1 https://doi.org/10.12688/f1000research.11119.1 Latest published: 07 Apr 2017, 6:448 https://doi.org/10.12688/f1000research.11119.1 Reviewer Status Abstract Invited Reviewers In 2004, when the protein estimate from the finished human genome was 1 2 3 only 24,000, the surprise was compounded as reviewed estimates fell to 19,000 by 2014. However, variability in the total canonical protein counts version 1 (i.e. excluding alternative splice forms) of open reading frames (ORFs) in 07 Apr 2017 report report report different annotation portals persists. This work assesses these differences and possible causes. A 16-year analysis of Ensembl and UniProtKB/Swiss-Prot shows convergence to a protein number of ~20,000. The former had shown some yo-yoing, but both have now plateaued. Nine 1 Michael Tress, Spanish National Cancer major annotation portals, reviewed at the beginning of 2017, gave a spread Research Centre (CNIO), Madrid, Spain of counts from 21,819 down to 18,891. The 4-way cross-reference concordance (within UniProt) between Ensembl, Swiss-Prot, Entrez Gene 2 Elspeth A. Bruford , European Molecular and the Human Gene Nomenclature Committee (HGNC) drops to 18,690, Biology Laboratory, Hinxton, UK indicating methodological differences in protein definitions and experimental existence support between sources. -

The Candida Genome Database: the New Homology Information Page Highlights Protein Similarity and Phylogeny Jonathan Binkley, Martha B
Published online 31 October 2013 Nucleic Acids Research, 2014, Vol. 42, Database issue D711–D716 doi:10.1093/nar/gkt1046 The Candida Genome Database: The new homology information page highlights protein similarity and phylogeny Jonathan Binkley, Martha B. Arnaud*, Diane O. Inglis, Marek S. Skrzypek, Prachi Shah, Farrell Wymore, Gail Binkley, Stuart R. Miyasato, Matt Simison and Gavin Sherlock Department of Genetics, Stanford University Medical School, Stanford, CA 94305-5120, USA Received September 12, 2013; Revised October 9, 2013; Accepted October 10, 2013 ABSTRACT mammalian hosts as well as a pathogen that causes painful opportunistic mucosal infections in otherwise The Candida Genome Database (CGD, http://www. healthy individuals and causes severe and deadly blood- candidagenome.org/) is a freely available online stream infections in the susceptible severely ill and/or im- resource that provides gene, protein and sequence munocompromised patient population (2). This fungus information for multiple Candida species, along with exhibits a number of properties associated with the web-based tools for accessing, analyzing and ability to invade host tissue, to resist the effects of exploring these data. The goal of CGD is to facilitate antifungal therapeutic drugs and the human immune and accelerate research into Candida pathogenesis system and to alternately cause disease or coexist with and biology. The CGD Web site is organized around the host as a commensal, including the ability to grow in Locus pages, which display information collected multiple morphological forms and to switch between about individual genes. Locus pages have multiple them, and the ability to grow as drug-resistant biofilms (3–7). -

1 Proposal for Discovering Snps from Eight Commonly Used Inbred Rat
Proposal for Discovering SNPs from Eight Commonly Used Inbred Rat Strains Tim Aitman1, Richard Gibbs2, George Weinstock2, Norbert Huebner3, Michael Jensen- Seaman4, Daniel Maloney5 and Howard J. Jacob5 1Physiological Genomics and Medicine Group, MRC Clinical Sciences Centre, Imperial College Faculty of Medicine, Hammersmith Hospital, Ducane Road, London W12 0NN, UK. 2Human Genome Sequencing Center, Baylor College of Medicine, Houston, Texas 77030, USA. 3Max-Delbruck-Center for Molecular Medicine (MDC), Robert-Rossle-Str. 10, 13092 Berlin-Buch, Germany. 4Dept. of Biological Sciences, Mellon Hall, Duquesne University, 600 Forbes Ave., Pittsburgh PA 15282. 5Human and Molecular Genetics Center, Medical College of Wisconsin, 8710 Watertown Plank Road, Milwaukee WI 53236. For Correspondence: Howard Jacob, Ph. D. Director, Human and Molecular Genetics Center and Warren Knowles Professor Department of Physiology Medical College of Wisconsin 8710 Watertown Plank Road Milwaukee WI 53236 [email protected] Ph. (414) 456-4887 Fax (414) 456-6516 1 Table of Contents Importance of the organism 3 Research community 4 Current SNP resources and discovery efforts 5 A SNP HapMap 6 Required number of SNPs 6 Strain Selection 7 Literature cited 11 2 Importance of the organism: The importance of the laboratory rat in biomedical research is well established. Since 1966, there have been on average over 28,000 publications per year using rat (PubMed search, key word: rat); in the last eight years (1996-2003) there have been on average almost 37,000 publications annually. The initiation of the rat genome project has yielded a tremendous wealth of genomic resources including genetic maps; radiation hybrid (RH) cell lines and the associated RH maps (over 6,000 genetic markers and 16,000 genes and ESTs mapped); cDNA libraries generating more than 593,880 ESTs (with more being generated) clustered into over 63,000 UniGenes; over 10,033 genetic markers; and a published draft (~6.8 X) sequence of the genome based on the inbred BN (Brown Norway) strain. -
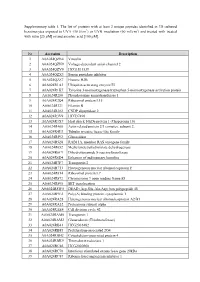
Supplementary Table 1. the List of Proteins with at Least 2 Unique
Supplementary table 1. The list of proteins with at least 2 unique peptides identified in 3D cultured keratinocytes exposed to UVA (30 J/cm2) or UVB irradiation (60 mJ/cm2) and treated with treated with rutin [25 µM] or/and ascorbic acid [100 µM]. Nr Accession Description 1 A0A024QZN4 Vinculin 2 A0A024QZN9 Voltage-dependent anion channel 2 3 A0A024QZV0 HCG1811539 4 A0A024QZX3 Serpin peptidase inhibitor 5 A0A024QZZ7 Histone H2B 6 A0A024R1A3 Ubiquitin-activating enzyme E1 7 A0A024R1K7 Tyrosine 3-monooxygenase/tryptophan 5-monooxygenase activation protein 8 A0A024R280 Phosphoserine aminotransferase 1 9 A0A024R2Q4 Ribosomal protein L15 10 A0A024R321 Filamin B 11 A0A024R382 CNDP dipeptidase 2 12 A0A024R3V9 HCG37498 13 A0A024R3X7 Heat shock 10kDa protein 1 (Chaperonin 10) 14 A0A024R408 Actin related protein 2/3 complex, subunit 2, 15 A0A024R4U3 Tubulin tyrosine ligase-like family 16 A0A024R592 Glucosidase 17 A0A024R5Z8 RAB11A, member RAS oncogene family 18 A0A024R652 Methylenetetrahydrofolate dehydrogenase 19 A0A024R6C9 Dihydrolipoamide S-succinyltransferase 20 A0A024R6D4 Enhancer of rudimentary homolog 21 A0A024R7F7 Transportin 2 22 A0A024R7T3 Heterogeneous nuclear ribonucleoprotein F 23 A0A024R814 Ribosomal protein L7 24 A0A024R872 Chromosome 9 open reading frame 88 25 A0A024R895 SET translocation 26 A0A024R8W0 DEAD (Asp-Glu-Ala-Asp) box polypeptide 48 27 A0A024R9E2 Poly(A) binding protein, cytoplasmic 1 28 A0A024RA28 Heterogeneous nuclear ribonucleoprotein A2/B1 29 A0A024RA52 Proteasome subunit alpha 30 A0A024RAE4 Cell division cycle 42 31