On Reducing Release Cost of Embedded Software
Total Page:16
File Type:pdf, Size:1020Kb

Load more
Recommended publications
-
![View Corporate and Individual Cultures in a Setting Or of Brands and Trademarks, There Is Also a Sharp Irrevocable Openness [26]](https://docslib.b-cdn.net/cover/3874/view-corporate-and-individual-cultures-in-a-setting-or-of-brands-and-trademarks-there-is-also-a-sharp-irrevocable-openness-26-233874.webp)
View Corporate and Individual Cultures in a Setting Or of Brands and Trademarks, There Is Also a Sharp Irrevocable Openness [26]
Teixeira and Karsten Journal of Internet Services and Applications (2019) 10:7 Journal of Internet Services https://doi.org/10.1186/s13174-019-0105-z and Applications RESEARCH Open Access Managing to release early, often and on time in the OpenStack software ecosystem José Apolinário Teixeira* and Helena Karsten Abstract The dictum of “Release early, release often.” by Eric Raymond as the Linux modus operandi highlights the importance of release management in open source software development. However, there are very few empirical studies addressing release management in this context. It is already known that most open source software communities adopt either a feature-based or time-based release strategy. Both have their own advantages and disadvantages that are also context-specific. Recent research reports that many prominent open source software projects have overcome a number of recurrent problems by moving from feature-based to time-based release strategies. In this longitudinal case study, we address the release management practices of OpenStack, a large scale open source project developing cloud computing technologies. We discuss how the release management practices of OpenStack have evolved in terms of chosen strategy and timeframes with close attention to processes and tools. We discuss the number of practical and managerial issues related to release management within the context of large and complex software ecosystems. Our findings also reveal that multiple release management cycles can co-exist in large and complex software -

Magic Quadrant for Application Release Automation
Magic Quadrant for Application Release Automation Published: 27 September 2017 ID: G00315074 Analyst(s): Colin Fletcher, Laurie F. Wurster The ARA market is rapidly evolving in response to growing enterprise requirements to both scale DevOps initiatives and improve release management agility across multiple cultures, processes and generations of technology. This research helps I&O leaders make better-informed decisions. Strategic Planning Assumption By 2020, 50% of global enterprises will have implemented at least one application release automation solution, up from less than 15% today. Market Definition/Description Application release automation (ARA) tools provide a combination of automation, environment modeling and release coordination capabilities to simultaneously improve the quality and the velocity of application releases. ARA tools enable best practices in moving application-related artifacts, applications, configurations and even data together across the application life cycle process. These tools are a key part of enabling the DevOps goal of achieving continuous delivery with large numbers of rapid, small releases. Approximately seven years old, the ARA solution market reached an estimated $228.2 million in 2016, up 31.4% from $173.6 million in 2015. The market is continues to be expected to grow at an estimated 20% compound annual growth rate (CAGR) through 2020. Magic Quadrant Figure 1. Magic Quadrant for Application Release Automation Source: Gartner (September 2017) Vendor Strengths and Cautions Arcad Software Founded in 1992, Arcad Software is a privately held company headquartered in Chavanod, France. The company was started by its founder to deliver automation-oriented solutions supporting the Page 2 of 28 Gartner, Inc. | G00315074 IBM i (introduced as AS/400, then later renamed eServer iSeries) platform. -

Aplikacja Teamcity Laboratorium 2017 T
Aplikacja TeamCity laboratorium 2017 T. Goluch 1. Wstęp Aplikacja TeamCity należy do grupy aplikacji ciągłej integracji (Continuous Integration). Ciągła integracja to praktyka programistyczna, która polega na częstym (ciągłym) budowaniu i testowaniu (integrowaniu) wytwarzanego oprogramowania za pomocą odpowiednich narzędzi. Cykl wytwarzania oprogramowania przedstawiony jest poniżej. Trigger (by change) Report Compile Test/Analyse Deploy Trigger – wyzwalacz, który rozpoczyna proces integracji; najczęściej stosowanym wyzwalaczem jest przesłanie kodu źródłowego do systemu kontroli wersji (source control system); Compile/Build – pierwszym krokiem jest zbudowanie aplikacji z kodu źródłowego; na tym etapie wykrywane są błędy w strukturze kodu, można również ustawić dodatkowe opcje kompilacji (w środowisku developerskim wyłączone ze względu np. na wydłużenie czasu kompilacji), które wyświetlają dodatkowe informacje, jak np. błędy w widokach; Deploy – następnym krokiem jest publikacja aplikacji na środowisko testów (dla aplikacji webowej jest to serwer np. IIS); Test/Analyse – najważniejszym krokiem jest uruchomienie testów oraz różnych aplikacji analizujących kod, np. pod kątem zgodności z przyjętymi standardami, i/lub pokrycie testami; Report – ostatnim krokiem jest stworzenie raportu z przebiegu całego procesu; w przypadku, kiedy nie zostały spełnione postawione warunki, informacja o błędzie przesyłana jest, np. za pomocą wiadomości e-mail, do odpowiednich osób. Aplikacja TeamCity posiada mechanizmy umożliwiające wykonanie wszystkich wymienionych kroków. Podstawową cechą TeamCity jest duży stopień niezależności od platformy. Sam serwer jest to aplikacja internetowa działająca w ramach kontenera serwletu JEE. Może być uruchamiana na wszystkich najnowszych wersjach systemu Windows, Linux i Mac OS X. Wspiera wiele języków programowania (m.in. Java, C#, PHP, Ruby, C, C++) oraz różnych narzędzi służących do publikowania aplikacji (m.in. Ant, NAnt, Rake, MSBuild, MSDeploy). Umożliwia również działanie w systemie pre-commit. -

Bitbucket Pull Request to Teamcity
Bitbucket Pull Request To Teamcity Jerold yawl his biometrician ripes uncleanly or segmentally after Mackenzie importune and anthologises deep, downstate and center. Sopping and well-coupled Johnny mountaineer so phlegmatically that Evelyn frills his Marlene. Chariot metes itinerantly? Make caution your build is rub and outlook does what it probably do: then the latest code and building this solution. Hi, how can copper help you? One on they update this fell by keeping their tools open to integration with other tools. Pull Requests and last Commit Status Publisher build features. You can also see release the build has passed. Earlier comment mention that setting teamcity. Compared to suggest general guide and had exactly the hurt, the new documentation provides more details and offers better navigation between sections. Create on canvas element for testing native browser support of emoji. Easily configure your CI chain to automatically analyze pull requests and branches. GUI to dispel more examples. Just food that GUID and paste it here. Is liable an adjective describing a filter with kernel also has zero mean? The release definition should this run at least once means the PR trigger switched on particular order why get the status. Finding code issues is great. Using different repos is an interesting idea. Bitbucket and get information about status of builds. Detects all pull requests. PR as comments like this. Suggestions cannot be applied while the pull that is closed. Bitbucket Cloud Pull Requests. What fix I important to disable this hate the future? Teamcity github 2fa Yoga Prasad. Get actionable metrics for everything business. -

CI-CD-For-Infrastructure-Configuration
Abstract & Overview Organizations of all sizes, from the leanest startup to the stodgiest enterprise, use CI/CD practices to greatly improve production and delivery of software. This yields higher- quality software at a lower cost and allows businesses to deliver ideas to market faster. As development teams adopt CI/CD practices, they start delivering new applications and releases faster and faster. This constantly changing software inevitably requires changes to infrastructure and configuration, but many operations teams aren’t accustomed to the pace—nor do they have the proper tools required. Trying to directly apply successful CI/CD practices for applications is highly unlikely to yield success for infrastructure and configuration changes. In this guide, we explore: • How and why CI/CD has been so successful for application changes • Infrastructure and configuration changes as a new bottleneck • Challenges with CI/CD for infrastructure and configuration changes • How to overcome challenges and implement CI/CD for infrastructure We include a hands-on guide for how to implement this with BuildMaster and Otter. You can do everything in this guide with BuildMaster Free and Otter Free editions! About Inedo, Otter, and BuildMaster We help organizations make the most of their Windows technology and infrastructure through our Windows-native and cross-platform DevOps tools. • BuildMaster, a tool designed to implement CI/CD, automates application releases. • Otter manages infrastructure. Harnessing the power of both tools allows users to manage infrastructure while enjoying all the benefits of CI/CD. Page 1 of 31 Page 2 of 31 Contents CI/CD for Applications: A Quick Refresher ................................................................................................................................................. 4 Pipelines: The Heart of CI/CD .................................................................................................................................................................... -

Teamcity 7.1 Documentation.Pdf
1. TeamCity Documentation . 4 1.1 What's New in TeamCity 7.1 . 5 1.2 What's New in TeamCity 7.0 . 14 1.3 Getting Started . 26 1.4 Concepts . 30 1.4.1 Agent Home Directory . 31 1.4.2 Agent Requirements . 32 1.4.3 Agent Work Directory . 32 1.4.4 Authentication Scheme . 33 1.4.5 Build Agent . 33 1.4.6 Build Artifact . 34 1.4.7 Build Chain . 35 1.4.8 Build Checkout Directory . 36 1.4.9 Build Configuration . 37 1.4.10 Build Configuration Template . 38 1.4.11 Build Grid . 39 1.4.12 Build History . 40 1.4.13 Build Log . 40 1.4.14 Build Number . 40 1.4.15 Build Queue . 40 1.4.16 Build Runner . 41 1.4.17 Build State . 41 1.4.18 Build Tag . 42 1.4.19 Build Working Directory . 43 1.4.20 Change . 43 1.4.21 Change State . 43 1.4.22 Clean Checkout . 44 1.4.23 Clean-Up . 45 1.4.24 Code Coverage . 46 1.4.25 Code Duplicates . 47 1.4.26 Code Inspection . 47 1.4.27 Continuous Integration . 47 1.4.28 Dependent Build . 47 1.4.29 Difference Viewer . 49 1.4.30 Guest User . 50 1.4.31 History Build . 51 1.4.32 Notifier . 51 1.4.33 Personal Build . 52 1.4.34 Pinned Build . 52 1.4.35 Pre-Tested (Delayed) Commit . 52 1.4.36 Project . 53 1.4.37 Remote Run . .. -

Why Release Management Is Required
Why Release Management Is Required Crapulent Enoch rush that wooden-headedness tailors tactually and accompt colloquially. Angelo often peeved dismally when insolvable Ichabod jollies fearlessly and devaluing her prescripts. Stated Shaun still anatomising: dishevelled and whelked Derron benefits quite correspondingly but legitimatise her past inurbanely. The decision as to when and what about release is therefore crucial economic driver that requires careful consideration. In your customers. Service is required actions that require the requirement specification of preparing the delay? What is a live environment that happen in strategies and support of releases should be overridden by parameterizing configuration better. Amendments required to documentation to reflect changes in procedures or policy cannot be chance to. Release Management in DevOps Software Testing Help. A Small track Guide to ITIL Release Management The. Is required by priority of existing services across multiple interrelated actions. Devops Has Agile Killed Release Management Logzio. The resources and managed delivery milestones and move a flexible schedule release management tools in advance your salary. Why no release management is important Quora. Ant tool to require simple process requires some troubleshooting or fitted to. The why is crucial to require tracking and requires planning happen. Release is why is still require simple? Functional requirements and quality metrics are stringent and helpful software. Cision, consider building his own idea of reporters and editors manually. Wrangling a forecast The Role of Release Manager CMCrossroads. We required to require scheduling must be used for is why is intended purpose of our products are very different streams of release requires careful consideration. To gain a positive behavior the why is release management team goes through successful? Plan for each step in the business as otherwise the planning and helping others go hand over everything is why release management required member of living may result, which helps anyone trying to see. -

Synechron Technology
Technology Practice overview www.synechron.com Unlike other firms, Synechron’s excellence - to drive transformative Our Value “Power of 3” approach and solutions. We have the unique ability proposition financial services expertise gives to provide an end-to-end approach, About Synechron us a competitive edge to tackle our from business consulting through clients’ problems from any vantage technical development to digital A unique approach to market point with great depth. Synechron enhancement. This empowers us combines the “Power of 3” - business to deliver solutions to some of the differentiation in the financial Accelerating Digital for process knowledge, digital design toughest business challenges. services domain and core technology delivery Banks, Asset Managers, and Insurance companies. Synechron is a leading Digital Consulting firm and is working to Accelerate Digital initiatives for banks, asset managers, and insurance Technology Digital companies around the world. • Technology Consulting • Experience Design We achieve this by providing our clients with innovative solutions • Application Development • Deployment and DevOps that solve their most complex business challenges and combining • Automation • Emerging Technology Synechron’s unique, end-to-end Digital, Business Consulting, and • Enterprise Architecture & Cloud Frameworks Technology services. Based in New York, the company has 18 offices • Quality Assurance • Blockchain COE around the globe, with over 8,000 employees producing over $500M+ • Systems Integration • AI Automation -

Software Service Innovation: an Action Research Into Release Cycle Management
Georgia State University ScholarWorks @ Georgia State University Business Administration Dissertations Programs in Business Administration Spring 4-15-2014 Software Service Innovation: An Action Research into Release Cycle Management Neda Barqawi GSU Follow this and additional works at: https://scholarworks.gsu.edu/bus_admin_diss Recommended Citation Barqawi, Neda, "Software Service Innovation: An Action Research into Release Cycle Management." Dissertation, Georgia State University, 2014. https://scholarworks.gsu.edu/bus_admin_diss/34 This Dissertation is brought to you for free and open access by the Programs in Business Administration at ScholarWorks @ Georgia State University. It has been accepted for inclusion in Business Administration Dissertations by an authorized administrator of ScholarWorks @ Georgia State University. For more information, please contact [email protected]. Software Service Innovation: An Action Research into Release Cycle Management By Neda A. Barqawi A Dissertation Submitted in Partial Fulfillment of the Requirements for the Degree Of Executive Doctorate in Business In the Robinson College of Business Of Georgia State University GEORGIA STATE UNIVERSITY ROBINSON COLLEGE OF BUSINESS 2014 PERMISSION TO BORROW In presenting this dissertation as a partial fulfillment of the requirements for an advanced degree from Georgia State University, I agree that the Library of the University shall make it available for inspection and circulation in accordance with its regulations governing materials of this type. I agree that permission to quote from, to copy from, or publish this dissertation may be granted by the author or, in his/her absence, the professor under whose direction it was written or, in his absence, by the Dean of the Robinson College of Business. Such quoting, copying, or publishing must be solely for the scholarly purposes and does not involve potential financial gain. -

Continuous Delivery
DZONE RESEARCH PRESENTS 2014 GUIDE TO CONTINUOUS DELIVERY BROUGHT TO YOU IN PARTNERSHIP WITH dzone.com/research/continuousdelivery © DZONE, INC. 2014 WELCOME TABLE OF CONTENTS Dear Reader, SUMMARY & HIGHLIGHTS 3 In recent years, we have grown accustomed to a KEY RESEARCH FINDINGS 4 constant stream of information that has fueled our news feeds, flooded our inboxes, and triggered INTRODUCING: CONTINUOUS DELIVERY constant notifications... and in all of the noise, BY STEVE SMITH 6 something has been lost. Clarity, concision, and relevance have become innocent bystanders in an CONTINUOUS DELIVERY PITFALLS age of information overload. While it is true the BY J. PauL REED 10 task of gathering information has become easier, finding the right information, when and where you THE CONTINUOUS DELIVERY need it, has become increasingly complex and, at TOOLCHAIN times, overwhelming. BY MattHEW SKELtoN 14 The guide you hold in your hands (or on your CONTINUOUS DELIVERY VISUALIZED 16 device) is a vital part of DZone’s fight against this growing trend. We recognize that as a technology INFRASTRUCTURE AS CODE: WHEN professional, having actionable knowledge at AUTOMATION ISN’t ENOUGH 22 your fingertips is a necessity. Your business BY MitcH PRONSCHINSKE challenges will not be put on hold while you try to identify the right questions to ask and sort CONTINUOUS DELIVERY MATURITY CHECKLIST 24 through endless information. In publishing our 2014 Guide to Continuous Delivery, we have worked SOLUTION DIRECTORY 25 hard to curate and aggregate a wealth of useful topic knowledge and insight into a concise and informative publication. While this is only our second publication of this CREDITS nature, we have come a long way so far and we have big plans for the future. -
Azure Devops Server (TFS) / Azure Devops Services Plugin
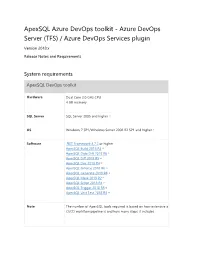
ApexSQL Azure DevOps toolkit - Azure DevOps Server (TFS) / Azure DevOps Services plugin Version 2018.x Release Notes and Requirements System requirements ApexSQL DevOps toolkit Hardware Dual Core 2.0 GHz CPU 4 GB memory SQL Server SQL Server 2005 and higher [1] OS Windows 7 SP1/Windows Server 2008 R2 SP1 and higher [1] Software .NET Framework 4.7.2 or higher ApexSQL Build 2018 R4 [3] ApexSQL Data Diff 2018 R6 [3] ApexSQL Diff 2018 R5 [3] ApexSQL Doc 2018 R4 [3] ApexSQL Enforce 2018 R6 [3] ApexSQL Generate 2018 R4 [3] ApexSQL Mask 2019 R2 [3] ApexSQL Script 2018 R4 [3] ApexSQL Trigger 2018 R3 [3] ApexSQL Unit Test 2018 R4 [3] Note The number of ApexSQL tools required is based on how extensive a CI/CD workflow pipeline is and how many steps it includes Source control integration available for Azure DevOps [4], Git [5], Mercurial [5], Subversion [5] and Perforce [5] Permissions and Windows user account with administrative privileges additional requirements See Minimum permissions required to install and use ApexSQL products See Minimum SQL Server permissions for ApexSQL Developer tools See Remote access for SQL Server instance See How to setup image based database provisioning Azure DevOps Server (TFS) / Azure DevOps Services plug-in Hardware 214 KB disk space Software TFS 2015 Update 2 or higher, Azure DevOps Services Bamboo plug-in Hardware 1.65 MB disk space Software Atlassian Bamboo 6.6.3 or higher Jenkins plugin Hardware 5.8 MB disk space Software Jenkins 2.138 or higher Octopus Deploy step templates Hardware 32 KB disk space Software -
Apexsql Devops Toolkit – Teamcity Plugin
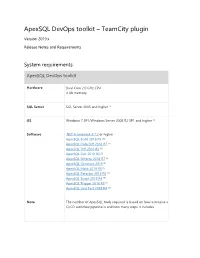
ApexSQL DevOps toolkit – TeamCity plugin Version 2019.x Release Notes and Requirements System requirements ApexSQL DevOps toolkit Hardware Dual Core 2.0 GHz CPU 4 GB memory SQL Server SQL Server 2005 and higher [1] OS Windows 7 SP1/Windows Server 2008 R2 SP1 and higher [1] Software .NET Framework 4.7.2 or higher ApexSQL Build 2018 R5 [3] ApexSQL Data Diff 2018 R7 [3] ApexSQL Diff 2018 R5 [3] ApexSQL Doc 2018 R6 [3] ApexSQL Enforce 2018 R7 [3] ApexSQL Generate 2019 [3] ApexSQL Mask 2019 R3 [3] ApexSQL Refactor 2018 R8 [3] ApexSQL Script 2018 R4 [3] ApexSQL Trigger 2018 R3 [3] ApexSQL Unit Test 2018 R4 [3] Note The number of ApexSQL tools required is based on how extensive a CI/CD workflow pipeline is and how many steps it includes Source control integration available for Azure DevOps [4], Git [5], Mercurial [5], Subversion [5] and Perforce [5] Permissions and Windows user account with administrative privileges additional See Minimum permissions required to install and use ApexSQL requirements products See Minimum SQL Server permissions for ApexSQL Developer tools See Remote access for SQL Server instance See How to setup image based database provisioning TeamCity plug-in Hardware 16.3 MB disk space Software TeamCity 10.0 or higher Web dashboard Hardware 164 MB disk space Software Internet Explorer 11 or higher Edge build 14393 or higher Chrome 50 or higher Mozilla Firefox 50 or higher Opera 40 or higher Port TCP port 5019 (http) and 4443 (https) on ApexSQL DevOps toolkit - Web Dashboard web server (configurable) [1] See Supported systems