Spring 2012 Volume II, Number II
Total Page:16
File Type:pdf, Size:1020Kb

Load more
Recommended publications
-
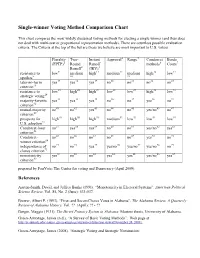
Single-Winner Voting Method Comparison Chart
Single-winner Voting Method Comparison Chart This chart compares the most widely discussed voting methods for electing a single winner (and thus does not deal with multi-seat or proportional representation methods). There are countless possible evaluation criteria. The Criteria at the top of the list are those we believe are most important to U.S. voters. Plurality Two- Instant Approval4 Range5 Condorcet Borda (FPTP)1 Round Runoff methods6 Count7 Runoff2 (IRV)3 resistance to low9 medium high11 medium12 medium high14 low15 spoilers8 10 13 later-no-harm yes17 yes18 yes19 no20 no21 no22 no23 criterion16 resistance to low25 high26 high27 low28 low29 high30 low31 strategic voting24 majority-favorite yes33 yes34 yes35 no36 no37 yes38 no39 criterion32 mutual-majority no41 no42 yes43 no44 no45 yes/no 46 no47 criterion40 prospects for high49 high50 high51 medium52 low53 low54 low55 U.S. adoption48 Condorcet-loser no57 yes58 yes59 no60 no61 yes/no 62 yes63 criterion56 Condorcet- no65 no66 no67 no68 no69 yes70 no71 winner criterion64 independence of no73 no74 yes75 yes/no 76 yes/no 77 yes/no 78 no79 clones criterion72 81 82 83 84 85 86 87 monotonicity yes no no yes yes yes/no yes criterion80 prepared by FairVote: The Center for voting and Democracy (April 2009). References Austen-Smith, David, and Jeffrey Banks (1991). “Monotonicity in Electoral Systems”. American Political Science Review, Vol. 85, No. 2 (June): 531-537. Brewer, Albert P. (1993). “First- and Secon-Choice Votes in Alabama”. The Alabama Review, A Quarterly Review of Alabama History, Vol. ?? (April): ?? - ?? Burgin, Maggie (1931). The Direct Primary System in Alabama. -

A Treasury System for Cryptocurrencies: Enabling Better Collaborative Intelligence ⋆
A Treasury System for Cryptocurrencies: Enabling Better Collaborative Intelligence ? Bingsheng Zhang1, Roman Oliynykov2, and Hamed Balogun3 1 Lancaster University, UK [email protected] 2 Input Output Hong Kong Ltd. [email protected] 3 Lancaster University, UK [email protected] Abstract. A treasury system is a community controlled and decentralized collaborative decision- making mechanism for sustainable funding of the blockchain development and maintenance. During each treasury period, project proposals are submitted, discussed, and voted for; top-ranked projects are funded from the treasury. The Dash governance system is a real-world example of such kind of systems. In this work, we, for the first time, provide a rigorous study of the treasury system. We modelled, designed, and implemented a provably secure treasury system that is compatible with most existing blockchain infrastructures, such as Bitcoin, Ethereum, etc. More specifically, the proposed treasury system supports liquid democracy/delegative voting for better collaborative intelligence. Namely, the stake holders can either vote directly on the proposed projects or delegate their votes to experts. Its core component is a distributed universally composable secure end-to-end verifiable voting protocol. The integrity of the treasury voting decisions is guaranteed even when all the voting committee members are corrupted. To further improve efficiency, we proposed the world's first honest verifier zero-knowledge proof for unit vector encryption with logarithmic size communication. This partial result may be of independent interest to other cryptographic protocols. A pilot system is implemented in Scala over the Scorex 2.0 framework, and its benchmark results indicate that the proposed system can support tens of thousands of treasury participants with high efficiency. -

Ranked-Choice Voting from a Partisan Perspective
Ranked-Choice Voting From a Partisan Perspective Jack Santucci December 21, 2020 Revised December 22, 2020 Abstract Ranked-choice voting (RCV) has come to mean a range of electoral systems. Broadly, they can facilitate (a) majority winners in single-seat districts, (b) majority rule with minority representation in multi-seat districts, or (c) majority sweeps in multi-seat districts. Such systems can be combined with other rules that encourage/discourage slate voting. This paper describes five major versions used in U.S. public elections: Al- ternative Vote (AV), single transferable vote (STV), block-preferential voting (BPV), the bottoms-up system, and AV with numbered posts. It then considers each from the perspective of a `political operative.' Simple models of voting (one with two parties, another with three) draw attention to real-world strategic issues: effects on minority representation, importance of party cues, and reasons for the political operative to care about how voters rank choices. Unsurprisingly, different rules produce different outcomes with the same votes. Specific problems from the operative's perspective are: majority reversal, serving two masters, and undisciplined third-party voters (e.g., `pure' independents). Some of these stem from well-known phenomena, e.g., ballot exhaus- tion/ranking truncation and inter-coalition \vote leakage." The paper also alludes to vote-management tactics, i.e., rationing nominations and ensuring even distributions of first-choice votes. Illustrative examples come from American history and comparative politics. (209 words.) Keywords: Alternative Vote, ballot exhaustion, block-preferential voting, bottoms- up system, exhaustive-preferential system, instant runoff voting, ranked-choice voting, sequential ranked-choice voting, single transferable vote, strategic coordination (10 keywords). -

Game Theory and Democracy Homework Problems
Game Theory and Democracy Homework Problems PAGE 82 Challenge Problem: Show that any voting model (such as the Unit Interval Model or the Unit Square Model) which has a point symmetry always has a Condorcet winner for every election, namely the candidate who is closest to the point of symmetry! PAGE 93 Exercise: Show that if there are not any cycles of any length in the preferences of the voters, then there must be a Condorcet winner. (Don’t worry about making your proof rigorous, just convince yourself of this fact, to the point you could clearly explain your ideas to someone else.) PAGE 105 Exercise: Prove that the strongest chain strength of a chain from Candidate Y to Candidate X is 3. (If you can convince a skeptical friend that it is true, then that is a proof.) Exercise: Prove that it is never necessary to use a candidate more than once to find a chain with the strongest chain strength between two candidates. Hint: Show that whenever there is a loop, like the one shown in red Y (7) Z (3) W (9) Y (7) Z (3) W (11) X, we can consider a shortened chain by simply deleting the red loop Y (7) Z (3) W (11) X which is at least as strong as the original loop. Exercises: Prove that all of the chains above are in fact strongest chains, as claimed. Hint: The next figure, which has all of the information of the margin of victory matrix, will be useful, and is the type of figure you may choose to draw for yourself for other elections, from time to time. -

Democracy Without Elections Mainz
Democracy without Elections: Is electoral accountability essential for democracy? Felix Gerlsbeck [email protected] Paper prepared for the workshop “Democratic Anxiety. Democratic Resilience.” Mainz, 15-17 June 2017 DRAFT VERSION, PLEASE DO NOT CITE WITHOUT AUTHOR’S PERMISSION 1. Introduction The idea of choosing political decision-makers by sortition, that is, choosing them randomly from a pool of the entire population or from some qualified subset, through some form of lottery or other randomizing procedure, is familiar to democrats at least since ancient Athens. Apart from the selection of trial juries, however, sortition has all but disappeared from official decision-making procedures within contemporary democratic systems, and free, equal, and regular election through voting by the entire qualified population of candidates who put themselves forward for political office, has taken its place. Nevertheless, there has been renewed interest in the idea of reviving sortition-based elements within modern democratic systems over the last years: a number of democratic theorists see great promise in complementing elected decision-making institutions with those selected randomly. These proposals variously go under the names mini-publics, citizen juries, citizen assemblies, lottocracy, enfranchisement lottery, and even Machiavellian Democracy.1 The roots of this practice go back to ancient Athens. During the 5th century Athenian democracy, the equivalent of the parliamentary body tasked with deliberating 1 See for instance, Guerrero 2014; Fishkin 2009; Warren & Gastil 2015; Ryan & Smith 2014; Saunders 2012; López-Guerra 2014; López-Guerra 2011; McCormick 2011. 1 and drafting policy proposals, the boule, was chosen by lot from the citizens of Athens through a complex system of randomization. -

2016 US Presidential Election Herrade Igersheim, François Durand, Aaron Hamlin, Jean-François Laslier
Comparing Voting Methods: 2016 US Presidential Election Herrade Igersheim, François Durand, Aaron Hamlin, Jean-François Laslier To cite this version: Herrade Igersheim, François Durand, Aaron Hamlin, Jean-François Laslier. Comparing Voting Meth- ods: 2016 US Presidential Election. 2018. halshs-01972097 HAL Id: halshs-01972097 https://halshs.archives-ouvertes.fr/halshs-01972097 Preprint submitted on 7 Jan 2019 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. WORKING PAPER N° 2018 – 55 Comparing Voting Methods: 2016 US Presidential Election Herrade Igersheim François Durand Aaron Hamlin Jean-François Laslier JEL Codes: D72, C93 Keywords : Approval voting, range voting, instant runoff, strategic voting, US Presidential election PARIS-JOURDAN SCIENCES ECONOMIQUES 48, BD JOURDAN – E.N.S. – 75014 PARIS TÉL. : 33(0) 1 80 52 16 00= www.pse.ens.fr CENTRE NATIONAL DE LA RECHERCHE SCIENTIFIQUE – ECOLE DES HAUTES ETUDES EN SCIENCES SOCIALES ÉCOLE DES PONTS PARISTECH – ECOLE NORMALE SUPÉRIEURE INSTITUT NATIONAL DE LA RECHERCHE AGRONOMIQUE – UNIVERSITE PARIS 1 Comparing Voting Methods: 2016 US Presidential Election Herrade Igersheim☦ François Durand* Aaron Hamlin✝ Jean-François Laslier§ November, 20, 2018 Abstract. Before the 2016 US presidential elections, more than 2,000 participants participated to a survey in which they were asked their opinions about the candidates, and were also asked to vote according to different alternative voting rules, in addition to plurality: approval voting, range voting, and instant runoff voting. -

City Council Election Methods in Order to Ensure That the Election Please Do Not Hesitate to Contact Us
The Center for Voting and Democracy City 6930 Carroll Avenue, Suite 610 – Takoma Park, MD 20912 Phone: (301) 270-4616 – Fax: (301) 270-4133 Council Email: [email protected] Website: http://www.fairvote.org Election This Manual is intended to assist Charter Review Comissions, city officials, and other community Methods leaders in determining what electoral systems will best meet the needs and goals of their community. Given that no system can accomplish every goal, this manual will help you analyze the INTRODUCTION consequences of adopting one system over The range of options that exists for electing a municipal government is broader than many people realize. Voting systems can have a another and will aid you in comparing the features striking impact on the type of candidates who run for office, how of various electoral systems. representative the council is, which candidates are elected, which parties control the city council, which voters feel well represented, Should you desire more information about any of and so on. This booklet is intended to aid in the evaluation of possible the voting systems discussed within this manual, city council election methods in order to ensure that the election please do not hesitate to contact us. method is determined by conscious choice, not inertia. A separate companion booklet, Mayoral Election Methods , deals with the selection of an executive. A summary of this booklet can be found in the city council election method evaluation grid at Page 11. 1 CRITERIA FOR EVALUATING CITY COUNCIL ELECTION METHODS 1. VOTER CHOICE Different election methods will encourage different numbers of It is important to recognize from the outset that no election candidates to run, and will thus impact the level of choice which method is perfect. -

Computational Perspectives on Democracy
Computational Perspectives on Democracy Anson Kahng CMU-CS-21-126 August 2021 Computer Science Department School of Computer Science Carnegie Mellon University Pittsburgh, PA 15213 Thesis Committee: Ariel Procaccia (Chair) Chinmay Kulkarni Nihar Shah Vincent Conitzer (Duke University) David Pennock (Rutgers University) Submitted in partial fulfillment of the requirements for the degree of Doctor of Philosophy. Copyright c 2021 Anson Kahng This research was sponsored by the National Science Foundation under grant numbers IIS-1350598, CCF- 1525932, and IIS-1714140, the Department of Defense under grant number W911NF1320045, the Office of Naval Research under grant number N000141712428, and the JP Morgan Research grant. The views and conclusions contained in this document are those of the author and should not be interpreted as representing the official policies, either expressed or implied, of any sponsoring institution, the U.S. government or any other entity. Keywords: Computational Social Choice, Theoretical Computer Science, Artificial Intelligence For Grandpa and Harabeoji. iv Abstract Democracy is a natural approach to large-scale decision-making that allows people affected by a potential decision to provide input about the outcome. However, modern implementations of democracy are based on outdated infor- mation technology and must adapt to the changing technological landscape. This thesis explores the relationship between computer science and democracy, which is, crucially, a two-way street—just as principles from computer science can be used to analyze and design democratic paradigms, ideas from democracy can be used to solve hard problems in computer science. Question 1: What can computer science do for democracy? To explore this first question, we examine the theoretical foundations of three democratic paradigms: liquid democracy, participatory budgeting, and multiwinner elections. -

Democracy in the Age of Pandemic – Fair Vote UK Report June 2020
Democracy in the Age of Pandemic How to Safeguard Elections & Ensure Government Continuity APPENDICES fairvote.uk Published June 2020 Appendix 1 - 86 1 Written Evidence, Responses to Online Questionnaire During the preparation of this report, Fair Vote UK conducted a call for written evidence through an online questionnaire. The questionnaire was open to all members of the public. This document contains the unedited responses from that survey. The names and organisations for each entry have been included in the interest of transparency. The text of the questionnaire is found below. It indicates which question each response corresponds to. Name Organisation (if applicable) Question 1: What weaknesses in democratic processes has Covid-19 highlighted? Question 2: Are you aware of any good articles/publications/studies on this subject? Or of any countries/regions that have put in place mediating practices that insulate it from the social distancing effects of Covid-19? Question 3: Do you have any ideas on how to address democratic shortcomings exposed by the impact of Covid-19? Appendix 1 - 86 2 Appendix 1 Name S. Holledge Organisation Question 1 Techno-phobia? Question 2 Estonia's e-society Question 3 Use technology and don't be frightened by it 2 Appendix 1 - 86 3 Appendix 2 Name S. Page Organisation Yes for EU (Scotland) Question 1 The Westminster Parliament is not fit for purpose Question 2 Scottish Parliament Question 3 Use the internet and electronic voting 3 Appendix 1 - 86 4 Appendix 3 Name J. Sanders Organisation emergency legislation without scrutiny removing civil liberties railroading powers through for example changes to mental health act that impact on individual rights (A) Question 1 I live in Wales, and commend Mark Drakeford for his quick response to the crisis by enabling the Assembly to continue to meet and debate online Question 2 no, not until you asked. -

An Optimal Single-Winner Preferential Voting System Based on Game Theory∗
An Optimal Single-Winner Preferential Voting System Based on Game Theory∗ Ronald L. Rivest and Emily Shen Abstract • The election winner is determined by a random- ized method, based for example on the use of We present an optimal single-winner preferential vot- ten-sided dice, that picks outcome x with prob- ing system, called the \GT method" because of its in- ability p∗(x). If there is a Condorcet winner x, teresting use of symmetric two-person zero-sum game then p∗(x) = 1, and no dice are needed. We theory to determine the winner. Game theory is not also briefly discuss a deterministic variant of GT, used to describe voting as a multi-player game be- which we call GTD. tween voters, but rather to define when one voting system is better than another one. The cast ballots The GT system, essentially by definition, is opti- determine the payoff matrix, and optimal play corre- mal: no other voting system can produce election sponds to picking winners optimally. outcomes that are liked better by the voters, on the The GT method is quite simple and elegant, and average, than those of the GT system. We also look works as follows: at whether the GT system has several standard prop- erties, such as monotonicity, consistency, etc. • Voters cast ballots listing their rank-order pref- The GT system is not only theoretically interest- erences of the alternatives. ing and optimal, but simple to use in practice; it is probably easier to implement than, say, IRV. We feel • The margin matrix M is computed so that for that it can be recommended for practical use. -

Download Legal Document
Case: 4:14-cv-02077-RWS Doc. #: 212 Filed: 11/21/16 Page: 1 of 26 PageID #: 9139 UNITED STATES DISTRICT COURT EASTERN DISTRICT OF MISSOURI EASTERN DIVISION MISSOURI STATE CONFERENCE ) OF THE NATIONAL ASSOCIATION ) FOR THE ADVANCEMENT OF ) COLORED PEOPLE, et al., ) ) Plaintiffs, ) ) vs. ) Case No. 4:14 CV 2077 RWS ) FERGUSON-FLORISSANT ) SCHOOL DISTRICT, et al., ) ) Defendants. ) REMEDIAL ORDER Plaintiffs Doris Bailey, Redditt Hudson, F. Willis Johnson, and the Missouri State Conference of the National Association for the Advancement of Colored People filed suit against Defendants Ferguson-Florissant School District (the School District) and the St. Louis County Board of Election Commissioners (the Election Board) under Section 2 of the Voting Rights Act of 1965, 52 U.S.C. § 10301. Plaintiffs alleged that the electoral structures used in Ferguson-Florissant School Board elections, together with historical and socioeconomic conditions, deprive African American voters in the School District of an equal opportunity to elect representatives of their choice. After a six-day non-jury trial and post-trial briefing, I concluded Plaintiffs established a Section 2 violation. I enjoined Defendants from conducting any elections for the Ferguson-Florissant School Case: 4:14-cv-02077-RWS Doc. #: 212 Filed: 11/21/16 Page: 2 of 26 PageID #: 9140 Board until a new system is properly implemented. See Mem. Op. & Order, ECF No. 185. At a status conference held to discuss remedies, Defendants were afforded the first opportunity to submit a remedial plan, but the School District stated it preferred that Plaintiffs, rather than the School District, submit initial remedial proposals for the Court’s consideration. -

Selecting the Runoff Pair
Selecting the runoff pair James Green-Armytage New Jersey State Treasury Trenton, NJ 08625 [email protected] T. Nicolaus Tideman Department of Economics, Virginia Polytechnic Institute and State University Blacksburg, VA 24061 [email protected] This version: May 9, 2019 Accepted for publication in Public Choice on May 27, 2019 Abstract: Although two-round voting procedures are common, the theoretical voting literature rarely discusses any such rules beyond the traditional plurality runoff rule. Therefore, using four criteria in conjunction with two data-generating processes, we define and evaluate nine “runoff pair selection rules” that comprise two rounds of voting, two candidates in the second round, and a single final winner. The four criteria are: social utility from the expected runoff winner (UEW), social utility from the expected runoff loser (UEL), representativeness of the runoff pair (Rep), and resistance to strategy (RS). We examine three rules from each of three categories: plurality rules, utilitarian rules and Condorcet rules. We find that the utilitarian rules provide relatively high UEW and UEL, but low Rep and RS. Conversely, the plurality rules provide high Rep and RS, but low UEW and UEL. Finally, the Condorcet rules provide high UEW, high RS, and a combination of UEL and Rep that depends which Condorcet rule is used. JEL Classification Codes: D71, D72 Keywords: Runoff election, two-round system, Condorcet, Hare, Borda, approval voting, single transferable vote, CPO-STV. We are grateful to those who commented on an earlier draft of this paper at the 2018 Public Choice Society conference. 2 1. Introduction Voting theory is concerned primarily with evaluating rules for choosing a single winner, based on a single round of voting.