Who Is the Centre of the Movie Universe? Using Python and Networkx to Analyse the Social Network of Movie Stars
Total Page:16
File Type:pdf, Size:1020Kb

Load more
Recommended publications
-

Not Your Mother's Library Transcript Episode 11: Mamma Mia! and More Musicals (Brief Intro Music) Rachel: Hello, and Welcome T
Not Your Mother’s Library Transcript Episode 11: Mamma Mia! and More Musicals (Brief intro music) Rachel: Hello, and welcome to Not Your Mother’s Library, a readers’ advisory podcast from the Oak Creek Public Library. I’m Rachel, and once again since Melody’s departure I am without a co-host. This is where you would stick a crying-face emoji. Luckily for everyone, though, today we have a brand new guest! This is most excellent, truly, because we are going to be talking about musicals, and I do not have any sort of expertise in that area. So, to balance the episode out with a more professional perspective, I would like to welcome to the podcast Oak Creek Library’s very own Technical Services Librarian! Would you like to introduce yourself? Joanne: Hello, everyone. I am a new guest! Hooray! (laughs) Rachel: Yeah! Joanne: So, I am the Technical Services Librarian here at the Oak Creek Library. My name is Joanne. I graduated from Carroll University with a degree in music, which was super helpful for libraries. Not so much. Rachel: (laughs) Joanne: And then went to UW-Milwaukee to get my masters in library science, and I’ve been working in public libraries ever since. I’ve always had a love of music since I've been in a child. My mom is actually a church organist, and so I think that’s where I get it from. Rachel: Wow, yeah. Joanne: I used to play piano—I did about 10 years and then quit. (laughs) So, I might be able to read some sheet music but probably not very well. -

Mumbai Macbeth: Gender and Identity in Bollywood Adaptations Rashmila Maiti University of Arkansas, Fayetteville
University of Arkansas, Fayetteville ScholarWorks@UARK Theses and Dissertations 8-2018 Mumbai Macbeth: Gender and Identity in Bollywood Adaptations Rashmila Maiti University of Arkansas, Fayetteville Follow this and additional works at: http://scholarworks.uark.edu/etd Part of the Asian Studies Commons, Comparative Literature Commons, and the Literature in English, British Isles Commons Recommended Citation Maiti, Rashmila, "Mumbai Macbeth: Gender and Identity in Bollywood Adaptations" (2018). Theses and Dissertations. 2905. http://scholarworks.uark.edu/etd/2905 This Dissertation is brought to you for free and open access by ScholarWorks@UARK. It has been accepted for inclusion in Theses and Dissertations by an authorized administrator of ScholarWorks@UARK. For more information, please contact [email protected], [email protected]. Mumbai Macbeth: Gender and Identity in Bollywood Adaptations A dissertation submitted in partial fulfillment of the requirements for the degree of Doctor of Philosophy in Comparative Literature and Cultural Studies by Rashmila Maiti Jadavpur University Bachelor of Arts in English Literature, 2007 Jadavpur University Master of Arts in English Literature, 2009 August 2018 University of Arkansas This dissertation is approved for recommendation to the Graduate Council. M. Keith Booker, PhD Dissertation Director Yajaira M. Padilla, PhD Frank Scheide, PhD Committee Member Committee Member Abstract This project analyzes adaptation in the Hindi film industry and how the concepts of gender and identity have changed from the original text to the contemporary adaptation. The original texts include religious epics, Shakespeare’s plays, Bengali novels which were written pre- independence, and Hollywood films. This venture uses adaptation theory as well as postmodernist and postcolonial theories to examine how women and men are represented in the adaptations as well as how contemporary audience expectations help to create the identity of the characters in the films. -

An Actor's Life and Backstage Strife During WWII
Media Release For immediate release June 18, 2021 An actor’s life and backstage strife during WWII INSPIRED by memories of his years working as a dresser for actor-manager Sir Donald Wolfit, Ronald Harwood’s evocative, perceptive and hilarious portrait of backstage life comes to Melville Theatre this July. Directed by Jacob Turner, The Dresser is set in England against the backdrop of World War II as a group of Shakespearean actors tour a seaside town and perform in a shabby provincial theatre. The actor-manager, known as “Sir”, struggles to cast his popular Shakespearean productions while the able-bodied men are away fighting. With his troupe beset with problems, he has become exhausted – and it’s up to his devoted dresser Norman, struggling with his own mortality, and stage manager Madge to hold things together. The Dresser scored playwright Ronald Harwood, also responsible for the screenplays Australia, Being Julia and Quartet, best play nominations at the 1982 Tony and Laurence Olivier Awards. He adapted it into a 1983 film, featuring Albert Finney and Tom Courtenay, and received five Academy Award nominations. Another adaptation, featuring Ian McKellen and Anthony Hopkins, made its debut in 2015. “The Dresser follows a performance and the backstage conversations of Sir, the last of the dying breed of English actor-managers, as he struggles through King Lear with the aid of his dresser,” Jacob said. “The action takes place in the main dressing room, wings, stage and backstage corridors of a provincial English theatre during an air raid. “At its heart, the show is a love letter to theatre and the people who sacrifice so much to make it possible.” Jacob believes The Dresser has a multitude of challenges for it to be successful. -

Vol XXV Issue 21 Feb 04 2016
Volume XXV No. 21 Hometown Newspaper for Glen Cove, Sea Cliff, Glen Head, Glenwood, Locust Valley and Brookville Week of 2/4/16 75C Glen Cove Senior Center and North Coast Subaru Support Free Medical Transport for Residents Volunteer Drivers Wanted For almost ten years, the Glen Cove Senior Center and North Coast Subaru have partnered on a unique transportation initiative for Glen Cove residents. The Glen Cove Medical Transport program provides free transportation to all Glen Cove residents for doctor appointments, physical therapy sessions and any other non-emergency doctor, hospital, lab or medical center visits. “Due to the popularity of this program, we are looking for more volunteer drivers – individuals with a valid driver’s license and a big heart,” said Carol Waldman, Executive Director of the Glen Cove Senior Center. “The program runs from 10:00 a.m. to 2:00 p.m. three days a week; with more volunteer drivers, we would like to expand the program from 9:00 a.m. to 5:00 p.m. Monday through Friday.” While Glen Cove’s Medical Transport program began years earlier, in 2007 North Coast Subaru donated a vehicle to provide additional help to meet the community’s non-emergency transportation needs. As the program grew in popularity, a larger vehicle was required to help residents with wheelchairs and through program Photo (L to R) Interim coordinator Phyllis Burnett with volunteer drivers Linda Thompson and Gwen Cullen join Senior Center Executive Director Carol Waldman, Deputy Mayor Barbara Peebles and North coast Subaru’s Bill Santoro and Jesse Liang. -

31 Days of Oscar® 2010 Schedule
31 DAYS OF OSCAR® 2010 SCHEDULE Monday, February 1 6:00 AM Only When I Laugh (’81) (Kevin Bacon, James Coco) 8:15 AM Man of La Mancha (’72) (James Coco, Harry Andrews) 10:30 AM 55 Days at Peking (’63) (Harry Andrews, Flora Robson) 1:30 PM Saratoga Trunk (’45) (Flora Robson, Jerry Austin) 4:00 PM The Adventures of Don Juan (’48) (Jerry Austin, Viveca Lindfors) 6:00 PM The Way We Were (’73) (Viveca Lindfors, Barbra Streisand) 8:00 PM Funny Girl (’68) (Barbra Streisand, Omar Sharif) 11:00 PM Lawrence of Arabia (’62) (Omar Sharif, Peter O’Toole) 3:00 AM Becket (’64) (Peter O’Toole, Martita Hunt) 5:30 AM Great Expectations (’46) (Martita Hunt, John Mills) Tuesday, February 2 7:30 AM Tunes of Glory (’60) (John Mills, John Fraser) 9:30 AM The Dam Busters (’55) (John Fraser, Laurence Naismith) 11:30 AM Mogambo (’53) (Laurence Naismith, Clark Gable) 1:30 PM Test Pilot (’38) (Clark Gable, Mary Howard) 3:30 PM Billy the Kid (’41) (Mary Howard, Henry O’Neill) 5:15 PM Mr. Dodd Takes the Air (’37) (Henry O’Neill, Frank McHugh) 6:45 PM One Way Passage (’32) (Frank McHugh, William Powell) 8:00 PM The Thin Man (’34) (William Powell, Myrna Loy) 10:00 PM The Best Years of Our Lives (’46) (Myrna Loy, Fredric March) 1:00 AM Inherit the Wind (’60) (Fredric March, Noah Beery, Jr.) 3:15 AM Sergeant York (’41) (Noah Beery, Jr., Walter Brennan) 5:30 AM These Three (’36) (Walter Brennan, Marcia Mae Jones) Wednesday, February 3 7:15 AM The Champ (’31) (Marcia Mae Jones, Walter Beery) 8:45 AM Viva Villa! (’34) (Walter Beery, Donald Cook) 10:45 AM The Pubic Enemy -

Glengarry Glen Ross Free
FREE GLENGARRY GLEN ROSS PDF David Mamet | 144 pages | 26 Aug 2004 | Bloomsbury Publishing PLC | 9780413774187 | English | London, United Kingdom Glengarry Glen Ross movie review () | Roger Ebert When an office full of New York City real estate salesmen is given the news that all but the top two will be fired at the end of the week, the atmosphere begins to heat up. Shelley Levene, who has a sick daughter, does everything in his Glengarry Glen Ross to get better leads from his boss, John Williamson, but to no avail. When his coworker Dave Moss comes up with a plan to steal the leads, things get complicated for the tough-talking Glengarry Glen Ross. Joseph M. Caracciolo Jr. Jerry Tokofsky Stanley R. William Barclay Bob Shaw. Five minutes into the picture and there's so much awesomeness on the screen that it's almost overwhelming. Second time through and just as enjoyable as the first. First-rate cast, first-rate dialogue. Feels like a modernized Glengarry Glen Ross of a Salesman, with matching commentary on working class life "we work too hard"on shifting power structures the young managing the oldand on the emotional economics of capitalism subjection vs satisfaction. I didn't remember the characters being so consistently foul-mouthed, and this time through was slightly distracted by the film's heavy reliance on vulgarity. Nonetheless, this is an absolutely captivating film recommended to anyone who loves great actors, great characters, or great dialogue. It's amazing how a film focused exclusively on people talking can be so engrossing. -

View Centro's Film List
About the Centro Film Collection The Centro Library and Archives houses one of the most extensive collections of films documenting the Puerto Rican experience. The collection includes documentaries, public service news programs; Hollywood produced feature films, as well as cinema films produced by the film industry in Puerto Rico. Presently we house over 500 titles, both in DVD and VHS format. Films from the collection may be borrowed, and are available for teaching, study, as well as for entertainment purposes with due consideration for copyright and intellectual property laws. Film Lending Policy Our policy requires that films be picked-up at our facility, we do not mail out. Films maybe borrowed by college professors, as well as public school teachers for classroom presentations during the school year. We also lend to student clubs and community-based organizations. For individuals conducting personal research, or for students who need to view films for class assignments, we ask that they call and make an appointment for viewing the film(s) at our facilities. Overview of collections: 366 documentary/special programs 67 feature films 11 Banco Popular programs on Puerto Rican Music 2 films (rough-cut copies) Roz Payne Archives 95 copies of WNBC Visiones programs 20 titles of WNET Realidades programs Total # of titles=559 (As of 9/2019) 1 Procedures for Borrowing Films 1. Reserve films one week in advance. 2. A maximum of 2 FILMS may be borrowed at a time. 3. Pick-up film(s) at the Centro Library and Archives with proper ID, and sign contract which specifies obligations and responsibilities while the film(s) is in your possession. -

The 48 Stars That People Like Less Than Anne Hathaway by Nate Jones
The 48 Stars That People Like Less Than Anne Hathaway By Nate Jones Spend a few minutes reading blog comments, and you might assume that Anne Hathaway’s approval rating falls somewhere between that of Boko Haram and paper cuts — but you'd actually be completely wrong. According to E-Poll likability data we factored into Vulture's Most Valuable Stars list, the braying hordes of Hathaway haters are merely a very vocal minority. The numbers say that most people actually like her. Even more shocking? Who they like her more than. In calculating their E-Score Celebrity rankings, E-Poll asked people how much they like a particular celebrity on a six-point scale, which ranged from "like a lot" to "dislike a lot." The resulting Likability percentage is the number of respondents who indicated they either "like" Anne Hathaway or "like Anne Hathaway a lot." Hathaway's 2014 Likability percentage was 67 percent — up from 66 percent in 2013 — which doesn't quite make her Will Smith (85 percent), Sandra Bullock (83 percent), Jennifer Lawrence (76 percent), or even Liam Neeson (79 percent), but it does put her well above plenty of stars whose appeal has never been so furiously impugned on Twitter. Why? Well, why not? Anne Hathaway is a talented actress and seemingly a nice person. The objections to her boiled down to two main points: She tries too hard, and she's overexposed. But she's been absent from the screen since 2012'sLes Misérables, so it's hard to call her overexposed now. And trying too hard isn't the worst thing in the world, especially when you consider the alternative. -
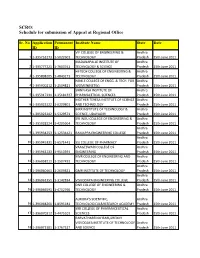
Schedule for Submission of Appeal at Regional Office
SCRO: Schedule for submission of Appeal at Regional Office Sr. No Application Permanent Institute Name State Date ID ID VIF COLLEGE OF ENGINEERING & Andhra 1 1-395751273 1-5022601 TECHNOLOGY Pradesh 15th June 2011 MADANAPALLE INSTITUTE OF Andhra 2 1-395777221 1-7603741 TECHNOLOGY & SCIENCE Pradesh 15th June 2011 HI-TECH COLLEGE OF ENGINEERING & Andhra 3 1-395898205 1-4843271 TECHNOLOGY Pradesh 15th June 2011 NOBLE COLLEGE OF ENGG. & TECH. FOR Andhra 4 1-395900212 1-2504821 WOMEN(NETW) Pradesh 15th June 2011 SRINIVASA INSTITUTE OF Andhra 5 1-395917231 1-25181337 PHARMACETICAL SCIENCES Pradesh 15th June 2011 MOTHER TERESA INSTITUTE OF SCIENCE Andhra 6 1-395923222 1-6209801 AND TECHNOLOGY Pradesh 15th June 2011 MRR INSTITUTE OF TECHNOLOGY & Andhra 7 1-395923242 1-5329571 SCIENCE, UDAYAGIRI Pradesh 15th June 2011 SRI INDU COLLEGE OF ENGINEERING & Andhra 8 1-395928224 1-4205664 TECHNOLOGY Pradesh 15th June 2011 Andhra 9 1-395934253 1-12534421 RAMAPPA ENGINEERING COLLEGE Pradesh 15th June 2011 Andhra 10 1-395945331 1-6571441 SSJ COLLEGE OF PHARMACY Pradesh 15th June 2011 VAAGESWARI COLLEGE OF Andhra 11 1-395961233 1-9513591 ENGINEERING Pradesh 15th June 2011 MVR COLLEGE OF ENGINEERING AND Andhra 12 1-396058211 1-2507491 TECHNOLOGY Pradesh 15th June 2011 Andhra 13 1-396060461 1-2609821 GMR INSTITUTE OF TECHNOLOGY Pradesh 15th June 2011 Andhra 14 1-396061351 1-3142834 VISVODAYA ENGINEERING COLLEGE Pradesh 15th June 2011 DNR COLLEGE OF ENGINEERING & Andhra 15 1-396066591 1-4702766 TECHNOLOGY Pradesh 15th June 2011 AURORA'S SCIENTIFIC, Andhra 16 -

Clare M. Wilkinson-Weber
Clare M. Wilkinson-Weber TAILORING EXPECTATIONS How film costumes become the audience’s clothes ‘Bollywood’ film costume has inspired clothing trends for many years. Female consumers have managed their relation to film costume through negotiations with their tailor as to how film outfits can be modified. These efforts have coincided with, and reinforced, a semiotic of female film costume where eroticized Indian clothing, and most forms of western clothing set the vamp apart from the heroine. Since the late 1980s, consumer capitalism in India has flourished, as have films that combine the display of material excess with conservative moral values. New film costume designers, well connected to the fashion industry, dress heroines in lavish Indian outfits and western clothes; what had previously symbolized the excessive and immoral expression of modernity has become an acceptable marker of global cosmopolitanism. Material scarcity made earlier excessive costume display difficult to achieve. The altered meaning of women’s costume in film corresponds with the availability of ready-to-wear clothing, and the desire and ability of costume designers to intervene in fashion retailing. Most recently, as the volume and diversity of commoditised clothing increases, designers find that sartorial choices ‘‘on the street’’ can inspire them, as they in turn continue to shape consumer choice. Introduction Film’s ability to stimulate consumption (responding to, and further stimulating certain kinds of commodity production) has been amply explored in the case of Hollywood (Eckert, 1990; Stacey, 1994). That the pleasures associated with film going have influenced consumption in India is also true; the impact of film on various fashion trends is recognized by scholars (Dwyer and Patel, 2002, pp. -
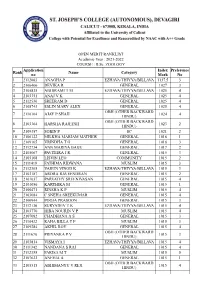
2021-2022 COURSE : B.Sc. ZOOLOGY Rank Application No Name
OPEN MERIT RANKLIST Academic Year : 2021-2022 COURSE : B.Sc. ZOOLOGY Application Index Preference Rank Name Category no Mark No 1 2112083 ANAGHA P EZHAVA/THIYYA/BILLAVA 1137.5 3 2 2106406 DEVIKA R GENERAL 1027 3 3 2105835 ABHIRAMI T M EZHAVA/THIYYA/BILLAVA 1025 4 4 2103351 ANAJ V K GENERAL 1025 4 5 2112536 SREERAM D GENERAL 1025 4 6 2108743 ESLIN MARY ALEX GENERAL 1025 4 OBH (OTHER BACKWARD 7 2110104 AJAY P SHAJI 1024 4 HINDU) OBH (OTHER BACKWARD 8 2103364 HARSHA RAJEESH 1023 2 HINDU) 9 2109357 SOBIN P SC 1021 2 10 2106122 MILKHA MARIAM MATHEW GENERAL 1018 1 11 2109165 VRINDHA T G GENERAL 1018 3 12 2112734 ANN MARIYA BAIJU GENERAL 1017 2 13 2105067 PAVITHRA J R GENERAL 1015 3 14 2105108 LISVIN LEO COMMUNITY 1015 2 15 2111419 FATHIMA RIDWANA MUSLIM 1015 3 16 2112305 VARUN VINOD K EZHAVA/THIYYA/BILLAVA 1015 3 17 2103187 ARDRA RAVEENDRAN GENERAL 1015 2 18 2101037 PARVATHY SREENIVASAN GENERAL 1015 4 19 2101056 KARTHIKA M GENERAL 1015 1 20 2100471 RINSHA K P MUSLIM 1015 4 21 2103084 C SNEHA SREEKUMAR GENERAL 1015 4 22 2100944 POOJA PRASOON GENERAL 1015 3 23 2112136 SURYADEV T K EZHAVA/THIYYA/BILLAVA 1015 4 24 2103770 HIBA NOURIN V P MUSLIM 1015 4 25 2107082 CHADHANA A S GENERAL 1015 3 26 2110432 RAHA BILLA T P MUSLIM 1015 3 27 2109284 AKHIL ROY GENERAL 1015 4 OBH (OTHER BACKWARD 28 2111670 PRIYANKA P V 1015 3 HINDU) 29 2103814 VISMAYA I EZHAVA/THIYYA/BILLAVA 1015 4 30 2111342 NANDANA S RAJ GENERAL 1015 4 31 2112355 FARISA M T MUSLIM 1015 5 32 2107623 ANEEJA A GENERAL 1015 1 OBH (OTHER BACKWARD 33 2105515 ABHIMANYU V REJI 1015 4 HINDU) 34 2107677 -

Transcript Sidney Lumet
TRANSCRIPT A PINEWOOD DIALOGUE WITH SIDNEY LUMET Sidney Lumet’s critically acclaimed 2007 film Before the Devil Knows You’re Dead, a dark family comedy and crime drama, was the latest triumph in a remarkable career as a film director that began 50 years earlier with 12 Angry Men and includes such classics as Serpico, Dog Day Afternoon, and Network. This tribute evening included remarks by the three stars of Before the Devil Knows Your Dead, Ethan Hawke, Marissa Tomei, and Philip Seymour Hoffman, and a lively conversation with Lumet about his many collaborations with great actors and his approach to filmmaking. A Pinewood Dialogue with Sidney Lumet shooting, “I feel that there’s another film crew on moderated by Chief Curator David Schwartz the other side of town with the same script and a (October 25, 2007): different cast, and we’re trying to beat them.” (Laughter) “You know, trying to wrap the movie DAVID SCHWARTZ: (Applause) Thank you, and ahead of them. It’s like a race.” I remember welcome, everybody. Sidney Lumet, as I think all saying that “you know if this movie works, then of you know, has received a number of salutes I’m going to have to rethink my whole idea of and awards over the years that could be process, because I can not imagine that this will considered lifetime achievement awards—which work!” (Laughter) I’ve never seen such a might sometimes imply that they’re at the end of deliberate—I’m going to steal your words, Phil, their career. But that’s certainly far from the case, but—a focus of energy, and use of energy.