Project 3: Writing a Kernel from Scratch 15-410 Operating Systems October 3, 2008
Total Page:16
File Type:pdf, Size:1020Kb

Load more
Recommended publications
-

I386-Engine™ Technical Manual
i386-Engine™ C/C++ Programmable, 32-bit Microprocessor Module Based on the Intel386EX Technical Manual 1950 5 th Street, Davis, CA 95616, USA Tel: 530-758-0180 Fax: 530-758-0181 Email: [email protected] http://www.tern.com Internet Email: [email protected] http://www.tern.com COPYRIGHT i386-Engine, VE232, A-Engine, A-Core, C-Engine, V25-Engine, MotionC, BirdBox, PowerDrive, SensorWatch, Pc-Co, LittleDrive, MemCard, ACTF, and NT-Kit are trademarks of TERN, Inc. Intel386EX and Intel386SX are trademarks of Intel Coporation. Borland C/C++ are trademarks of Borland International. Microsoft, MS-DOS, Windows, and Windows 95 are trademarks of Microsoft Corporation. IBM is a trademark of International Business Machines Corporation. Version 2.00 October 28, 2010 No part of this document may be copied or reproduced in any form or by any means without the prior written consent of TERN, Inc. © 1998-2010 1950 5 th Street, Davis, CA 95616, USA Tel: 530-758-0180 Fax: 530-758-0181 Email: [email protected] http://www.tern.com Important Notice TERN is developing complex, high technology integration systems. These systems are integrated with software and hardware that are not 100% defect free. TERN products are not designed, intended, authorized, or warranted to be suitable for use in life-support applications, devices, or systems, or in other critical applications. TERN and the Buyer agree that TERN will not be liable for incidental or consequential damages arising from the use of TERN products. It is the Buyer's responsibility to protect life and property against incidental failure. TERN reserves the right to make changes and improvements to its products without providing notice. -
Xv6 Booting: Transitioning from 16 to 32 Bit Mode
238P Operating Systems, Fall 2018 xv6 Boot Recap: Transitioning from 16 bit mode to 32 bit mode 3 November 2018 Aftab Hussain University of California, Irvine BIOS xv6 Boot loader what it does Sets up the hardware. Transfers control to the Boot Loader. BIOS xv6 Boot loader what it does Sets up the hardware. Transfers control to the Boot Loader. how it transfers control to the Boot Loader Boot loader is loaded from the 1st 512-byte sector of the boot disk. This 512-byte sector is known as the boot sector. Boot loader is loaded at 0x7c00. Sets processor’s ip register to 0x7c00. BIOS xv6 Boot loader 2 source source files bootasm.S - 16 and 32 bit assembly code. bootmain.c - C code. BIOS xv6 Boot loader 2 source source files bootasm.S - 16 and 32 bit assembly code. bootmain.c - C code. executing bootasm.S 1. Disable interrupts using cli instruction. (Code). > Done in case BIOS has initialized any of its interrupt handlers while setting up the hardware. Also, BIOS is not running anymore, so better to disable them. > Clear segment registers. Use xor for %ax, and copy it to the rest (Code). 2. Switch from real mode to protected mode. (References: a, b). > Note the difference between processor modes and kernel privilege modes > We do the above switch to increase the size of the memory we can address. BIOS xv6 Boot loader 2 source source file executing bootasm.S m. Let’s 2. Switch from real mode to protected mode. expand on this a little bit Addressing in Real Mode In real mode, the processor sends 20-bit addresses to the memory. -

Protected Mode - Wikipedia
2/12/2019 Protected mode - Wikipedia Protected mode In computing, protected mode, also called protected virtual address mode,[1] is an operational mode of x86- compatible central processing units (CPUs). It allows system software to use features such as virtual memory, paging and safe multi-tasking designed to increase an operating system's control over application software.[2][3] When a processor that supports x86 protected mode is powered on, it begins executing instructions in real mode, in order to maintain backward compatibility with earlier x86 processors.[4] Protected mode may only be entered after the system software sets up one descriptor table and enables the Protection Enable (PE) bit in the control register 0 (CR0).[5] Protected mode was first added to the x86 architecture in 1982,[6] with the release of Intel's 80286 (286) processor, and later extended with the release of the 80386 (386) in 1985.[7] Due to the enhancements added by protected mode, it has become widely adopted and has become the foundation for all subsequent enhancements to the x86 architecture,[8] although many of those enhancements, such as added instructions and new registers, also brought benefits to the real mode. Contents History The 286 The 386 386 additions to protected mode Entering and exiting protected mode Features Privilege levels Real mode application compatibility Virtual 8086 mode Segment addressing Protected mode 286 386 Structure of segment descriptor entry Paging Multitasking Operating systems See also References External links History https://en.wikipedia.org/wiki/Protected_mode -

Chapter 2 Powerpc Register Set
Chapter 2 PowerPC Register Set 20 20 This chapter describes the register organization defined by the three levels of the PowerPC U architecture—user instruction set architecture (UISA), virtual environment architecture V (VEA), and operating environment architecture (OEA). The PowerPC architecture defines O register-to-register operations for all computational instructions. Source data for these instructions are accessed from the on-chip registers or are provided as immediate values embedded in the opcode. The three-register instruction format allows specification of a target register distinct from the two source registers, thus preserving the original data for use by other instructions and reducing the number of instructions required for certain operations. Data is transferred between memory and registers with explicit load and store instructions only. Note that the handling of reserved bits in any register is implementation-dependent. Software is permitted to write any value to a reserved bit in a register. However, a subsequent reading of the reserved bit returns 0 if the value last written to the bit was 0 and returns an undefined value (may be 0 or 1) otherwise. This means that even if the last value written to a reserved bit was 1, reading that bit may return 0. 2.1 PowerPC UISA Register Set The PowerPC UISA registers, shown in Figure 2-1, can be accessed by either user- or U supervisor-level instructions (the architecture specification refers to user-level and supervisor-level as problem state and privileged state respectively). The general-purpose registers (GPRs) and floating-point registers (FPRs) are accessed as instruction operands. -

A Comparison of Protection Lookaside Buffers and the PA-RISC
rI3 HEWLETT ~~PACKARD A Comparison ofProtection Lookaside Buffers and the PA·RISC Protection Architecture John Wilkes, Bart Sears Computer Systems Laboratory HPL-92-55 March 1992 processor architecture, Eric Koldinger and others at the University of single address space, 64 Washington Department of Computer Science have bitaddressing, protection, proposed a new model for memory protection in PA-RISe, protection single-address-space architectures. This paper lookaside buffers, PLB, compares the Washington proposal with what translation lookaside already exists in PA-RISC, and suggests some buffers,TLB, cache incremental improvements to the latter that would indexing, virtually provide most of the benefits of the former. addressed caches Internal Accession Date Only © Copyright Hewlett-Packard Company 1992 1 Introduction A recent technical report by Eric Koldinger and others [Koldinger91] proposes a new model for managing protectioninformationinsingle address space processors. This paper is one outcome of discussions withthe authors about the real differences betweentheir proposal and the scheme usedinPA-RISC[Lee89,HPPA90]:it offers a restatement of the newproposal, a comparisonwith the existing PA-RISCarchitecture, and some thoughts onhow the PA-RISCarchitecture mightbe extended in the future to provide some of the benefits that the PLBidea was trying to achieve. The reader is assumed to be familiar withmodem TLB,cache and processor architectures; with luck, sufficient information is provided in this paper that detailed prior knowledge about either the Washington proposal or PA-RISCisn't required. Example To help illustrate some of the finer points of the different protectionmodels, anexample based on the LRPC work of Brian Bershad is used [Bershad90] (see Figure 1). -

Intel® 64 and IA-32 Architectures Software Developer's Manual
Intel® 64 and IA-32 Architectures Software Developer’s Manual Volume 3B: System Programming Guide, Part 2 NOTE: The Intel® 64 and IA-32 Architectures Software Developer's Manual consists of five volumes: Basic Architecture, Order Number 253665; Instruction Set Reference A-M, Order Number 253666; Instruction Set Reference N-Z, Order Number 253667; System Programming Guide, Part 1, Order Number 253668; System Programming Guide, Part 2, Order Number 253669. Refer to all five volumes when evaluating your design needs. Order Number: 253669-029US November 2008 INFORMATION IN THIS DOCUMENT IS PROVIDED IN CONNECTION WITH INTEL PRODUCTS. NO LICENSE, EXPRESS OR IMPLIED, BY ESTOPPEL OR OTHERWISE, TO ANY INTELLECTUAL PROPERTY RIGHTS IS GRANT- ED BY THIS DOCUMENT. EXCEPT AS PROVIDED IN INTEL'S TERMS AND CONDITIONS OF SALE FOR SUCH PRODUCTS, INTEL ASSUMES NO LIABILITY WHATSOEVER AND INTEL DISCLAIMS ANY EXPRESS OR IMPLIED WARRANTY, RELATING TO SALE AND/OR USE OF INTEL PRODUCTS INCLUDING LIABILITY OR WARRANTIES RELATING TO FITNESS FOR A PARTICULAR PURPOSE, MERCHANTABILITY, OR INFRINGEMENT OF ANY PATENT, COPYRIGHT OR OTHER INTELLECTUAL PROPERTY RIGHT. UNLESS OTHERWISE AGREED IN WRITING BY INTEL, THE INTEL PRODUCTS ARE NOT DESIGNED NOR IN- TENDED FOR ANY APPLICATION IN WHICH THE FAILURE OF THE INTEL PRODUCT COULD CREATE A SITUA- TION WHERE PERSONAL INJURY OR DEATH MAY OCCUR. Intel may make changes to specifications and product descriptions at any time, without notice. Designers must not rely on the absence or characteristics of any features or instructions marked "reserved" or "unde- fined." Intel reserves these for future definition and shall have no responsibility whatsoever for conflicts or incompatibilities arising from future changes to them. -

AMD 64-Bit Technology
Preliminary Information AMD 64-Bit Technology The AMD x86-64™ Architecture Programmers Overview Publication # 24108 Rev: A Issue Date: August 2000 Preliminary Information © 2000 Advanced Micro Devices, Inc. All rights reserved. The contents of this document are provided in connection with Advanced Micro Devices, Inc. (“AMD”) products. AMD makes no representations or warranties with respect to the accuracy or completeness of the contents of this publication and reserves the right to make changes to specifications and product descriptions at any time without notice. No license, whether express, implied, arising by estoppel or otherwise, to any intellectual property rights is granted by this publication. Except as set forth in AMD’s Standard Terms and Conditions of Sale, AMD assumes no liability whatsoever, and disclaims any express or implied warranty, relating to its products including, but not limited to, the implied warranty of merchantability, fitness for a particular purpose, or infringement of any intellectual property right. AMD’s products are not designed, intended, authorized or warranted for use as components in systems intended for surgical implant into the body, or in other applications intended to support or sustain life, or in any other applica- tion in which the failure of AMD’s product could create a situation where per- sonal injury, death, or severe property or environmental damage may occur. AMD reserves the right to discontinue or make changes to its products at any time without notice. Trademarks AMD, the AMD logo, x86-64, AMD Athlon, and combinations thereof are trademarks of Advanced Micro Devices, Inc. MMX is a trademark of Intel Corporation. -

Chapter 3 Protected-Mode Memory Management
CHAPTER 3 PROTECTED-MODE MEMORY MANAGEMENT This chapter describes the Intel 64 and IA-32 architecture’s protected-mode memory management facilities, including the physical memory requirements, segmentation mechanism, and paging mechanism. See also: Chapter 5, “Protection” (for a description of the processor’s protection mechanism) and Chapter 20, “8086 Emulation” (for a description of memory addressing protection in real-address and virtual-8086 modes). 3.1 MEMORY MANAGEMENT OVERVIEW The memory management facilities of the IA-32 architecture are divided into two parts: segmentation and paging. Segmentation provides a mechanism of isolating individual code, data, and stack modules so that multiple programs (or tasks) can run on the same processor without interfering with one another. Paging provides a mech- anism for implementing a conventional demand-paged, virtual-memory system where sections of a program’s execution environment are mapped into physical memory as needed. Paging can also be used to provide isolation between multiple tasks. When operating in protected mode, some form of segmentation must be used. There is no mode bit to disable segmentation. The use of paging, however, is optional. These two mechanisms (segmentation and paging) can be configured to support simple single-program (or single- task) systems, multitasking systems, or multiple-processor systems that used shared memory. As shown in Figure 3-1, segmentation provides a mechanism for dividing the processor’s addressable memory space (called the linear address space) into smaller protected address spaces called segments. Segments can be used to hold the code, data, and stack for a program or to hold system data structures (such as a TSS or LDT). -

18-447: Computer Architecture Lecture 18: Virtual Memory III
18-447: Computer Architecture Lecture 18: Virtual Memory III Yoongu Kim Carnegie Mellon University Spring 2013, 3/1 Upcoming Schedule • Today: Lab 3 Due • Today: Lecture/Recitation • Monday (3/4): Lecture – Q&A Session • Wednesday (3/6): Midterm 1 – 12:30 – 2:20 – Closed book – One letter-sized cheat sheet • Can be double-sided • Can be either typed or written Readings • Required – P&H, Chapter 5.4 – Hamacher et al., Chapter 8.8 • Recommended – Denning, P. J. Virtual Memory. ACM Computing Surveys. 1970 – Jacob, B., & Mudge, T. Virtual Memory in Contemporary Microprocessors. IEEE Micro. 1998. • References – Intel Manuals for 8086/80286/80386/IA32/Intel64 – MIPS Manual Review of Last Lecture • Two approaches to virtual memory 1. Segmentation • Not as popular today 2. Paging • What is usually meant today by “virtual memory” • Virtual memory requires HW+SW support – HW component is called the MMU • Memory management unit – How to translate: virtual ↔ physical addresses? Review of Last Lecture (cont’d) 1. Segmentation – Divide the address space into segments • Physical Address = BASE + Virtual Address – Case studies: Intel 8086, 80286, x86, x86-64 – Advantages • Modularity/Isolation/Protection • Translation is simple – Disadvantages • Complicated management • Fragmentation • Only a few segments are addressable at the same time Review of Last Lecture (cont’d) 2. Paging – Virtual address space: Large, contiguous, imaginary – Page: A fixed-sized chunk of the address space – Mapping: Virtual pages → physical pages – Page table: The data structure that stores the mappings • Problem #1: Too large – Solution: Hierarchical page tables • Problem #2: Large latency – Solution: Translation Lookaside Buffer (TLB) – Case study: Intel 80386 – Today, we’ll talk more about paging .. -
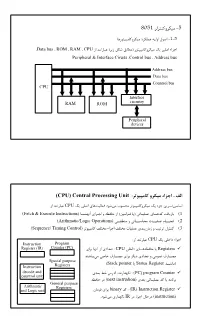
5 8051 : (CPU) Central Processing Unit
Mechatronics 1387Spring 8051 +P+KJ1+@8$ O5 >.K8$J1+@8$ %+@F(! 28P1 -.S O1O5 YData bus Y ROM Y RAM Y CPU ! (+' l@C E,G$) .K8Š$J1+@8$ u' "FS •Dc Peripheral & Interface Ciruits YControl bus Y Address bus Address bus Data bus Countrol bus CPU Interface RAM ROM circuitry Peripheral devices (CPU) Central Processing Unit :$%&' ( )$* + , #!" ! CPU u' "FS *>7 8P/^ %.C"$ •.`T$ +.8Š$J1+@8$ u' •Dc 9'+hh "33 (Fetch & Execute Instructions) hhhhm); *+hc 1 2[^y (98$+h^ ') "h8F(! *hh>J 7^', (1 (Arithmatic/Logic Operations) "hh?G$ 1 "hh 3T$ Rhh8F(! whhh<) (2 (Sequence/ Timing Control) +.8Š$J jFKk$ •Dc jFKk$ R8F(! *, B$ 1 ˆ8+ -+KJ (3 : ! CPU u' "F:% •Dc Instruction Program Register (IR) Counter (PC) *+, m); *%/ : CPU "F:% *hh>2[^y ' Registers Ch,"$ "S: \hhŽ$ *+, +p'% *%/ 1 "$.(! \hhŽ$ Special purpose (Stack pointer ' Status Register hh)$) Instruction Registers decode and */, v: a%; I)mp) : (PC) program Counter countrol unit 2[^y % (next instrudion) */, "h8F(! J ' 2$)+, General purpose Arithmatic Registers and Logic unit B$+^ *+, binary J : (IR) Instruction Register .%.C "$ *mp) IR % Y+c -y% (instruction) G.R. Vossoughi, Sharif Univ. of Tech. 5 Mechatronics 1387Spring instruction *+, binary hJ (2h(c+) +8 / lh$! : Instruction Decode/Control unit instruction B%1;% +hhc 2, 7mc (I+8€ 1 "hhP+KJ R8F(!) 8) %.$ R8F(! w<) 1 IR % %.c.$ +[)%.$ 98$+^ E z +,) "_' 1 "?G$ R8F(! B%1;% +hhc 2, l$! : Arithmatic Logic Unit (ALU) (Instruction decoder / Control unit "K^'% *+c 1 2[^y 98$+^ ' "8F(! *hhhh>J ",', CPU J 9'+ I(! C IhhC •A H 2J .G)hh(> .%.C "$ 2K#W fetching 2[^y "8F(! *>J ' instruction ",', 2, . -

X86 Assembly Language: AT&T and Intel
x86_16 real mode (or at least enough for cos318 project 1) Overview Preliminary information - How to find help The toolchain The machine If you only remember one thing: gcc -S the -S (capital S) flag causes gcc to ouput assembly. Preliminary Information Assembly can be hard Development strategies conquer risk: Write small test cases. Write functions, test each separately. Print diagnostics frequently. Think defensively! and the interweb is helpful too. The Interwebs as a resource. The internet offers much information that seems confusing or contradictory. How do you sort out information "in the wild?" Syntax There are (at least) two different syntaxes for x86 assembly language: AT&T and Intel. AT&T: opcodes have a suffix to denote data type, use sigils, and place the destination operand on the right. Intel: operands use a keyword to denote data type, no sigils, destination operand is leftmost. Example: AT&T vs Intel push %bp push bp mov %sp,%bp mov bp,sp sub $0x10,%sp sub sp,0x10 movw mov si,WORD 0x200b(%bx),%si PTR [bx+0x200b] mov $0x4006,%di mov di,0x4006 mov $0x0,%ax mov ax,0x0 call printf call printf leaveq leave retq ret In this class, use AT&T! Versions of the architecture x86 won't die. All backwards compatible. 8086 -> 16bit, Real 80386 / ia32 -> 32bit, Protected x86_64 -> 64bit, Protected If you find an example: For which architecture was it written? The Register Test If you see "%rax", then 64-bit code; else If you see "%eax", then 32-bit code; else You are looking at 16-bit code. -

Intel X86 Assembly Language & Microarchitecture
Intel x86 Assembly Language & Microarchitecture #x86 Table of Contents About 1 Chapter 1: Getting started with Intel x86 Assembly Language & Microarchitecture 2 Remarks 2 Examples 2 x86 Assembly Language 2 x86 Linux Hello World Example 3 Chapter 2: Assemblers 6 Examples 6 Microsoft Assembler - MASM 6 Intel Assembler 6 AT&T assembler - as 7 Borland's Turbo Assembler - TASM 7 GNU assembler - gas 7 Netwide Assembler - NASM 8 Yet Another Assembler - YASM 9 Chapter 3: Calling Conventions 10 Remarks 10 Resources 10 Examples 10 32-bit cdecl 10 Parameters 10 Return Value 11 Saved and Clobbered Registers 11 64-bit System V 11 Parameters 11 Return Value 11 Saved and Clobbered Registers 11 32-bit stdcall 12 Parameters 12 Return Value 12 Saved and Clobbered Registers 12 32-bit, cdecl — Dealing with Integers 12 As parameters (8, 16, 32 bits) 12 As parameters (64 bits) 12 As return value 13 32-bit, cdecl — Dealing with Floating Point 14 As parameters (float, double) 14 As parameters (long double) 14 As return value 15 64-bit Windows 15 Parameters 15 Return Value 16 Saved and Clobbered Registers 16 Stack alignment 16 32-bit, cdecl — Dealing with Structs 16 Padding 16 As parameters (pass by reference) 17 As parameters (pass by value) 17 As return value 17 Chapter 4: Control Flow 19 Examples 19 Unconditional jumps 19 Relative near jumps 19 Absolute indirect near jumps 19 Absolute far jumps 19 Absolute indirect far jumps 20 Missing jumps 20 Testing conditions 20 Flags 21 Non-destructive tests 21 Signed and unsigned tests 22 Conditional jumps 22 Synonyms and terminology 22 Equality 22 Greater than 23 Less than 24 Specific flags 24 One more conditional jump (extra one) 25 Test arithmetic relations 25 Unsigned integers 25 Signed integers 26 a_label 26 Synonyms 27 Signed unsigned companion codes 27 Chapter 5: Converting decimal strings to integers 28 Remarks 28 Examples 28 IA-32 assembly, GAS, cdecl calling convention 28 MS-DOS, TASM/MASM function to read a 16-bit unsigned integer 29 Read a 16-bit unsigned integer from input.