Understanding the Evolution of HIV-1 Env Through Computational Analysis and Visualization of Long-Read Amplicon Sequences
Total Page:16
File Type:pdf, Size:1020Kb

Load more
Recommended publications
-

Our Immune System, Vaccines, and Vaccine Strategies for AIDS and COVID-19
Our Immune System, Vaccines, and Vaccine Strategies for AIDS and COVID-19 Dr. Bette Korber Los Alamos National Laboratory Constantly vigilant, our immune system recognizes and controls infections to protect us from disease. Furthermore, we have a capacity for immunological memory, which enables our immune system to “remember” a pathogen we have encountered in the past, and to make a more rapid and vigorous defensive response should we encounter that same disease again. Vaccines tap into this natural capacity for immunological memory. I’ll briefly review our ongoing work at Los Alamos National Laboratory to contribute to global vaccine efforts for HIV-1 and COVID-19. The rapid evolution and extraordinary diversity of HIV provides particular challenges for developing an AIDS vaccine, and our work focuses on strategies to contend with that diversity. By contrast, SARS-CoV-2, the virus that causes COVID-19, has evolved very slowly during the pandemic, although even this limited diversity can be important. We are tracking emerging viral diversity to help design appropriate reagents to ensure that COVID-19 vaccines and therapeutics currently under development will remain relevant over the coming year. Using our tracking tools, last April we identified a SARS-CoV-2 variant that appeared to be more transmissible than the original form. This viral variant was subsequently shown to be more infectious experimentally, and has now become the globally dominant form of the virus. Bio Dr. Bette Korber is a Laboratory Fellow at the Los Alamos National Laboratory in the Theoretical Biology and Biophysics Group. Her work focuses on viral evolution, the human immune response to infection, and vaccine design. -
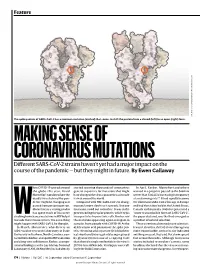
MAKING SENSE of CORONAVIRUS MUTATIONS Different SARS-Cov-2 Strains Haven’T Yet Had a Major Impact on the Course of the Pandemic — but They Might in Future
Feature SOURCE: STRUCTURAL DATA FROM K. SHEN & J. LUBAN K. SHEN FROM DATA STRUCTURAL SOURCE: The spike protein of SARS-CoV-2 has a common mutation (circled) that seems to shift the protein from a closed (left) to an open (right) form. MAKING SENSE OF CORONAVIRUS MUTATIONS Different SARS-CoV-2 strains haven’t yet had a major impact on the course of the pandemic — but they might in future. By Ewen Callaway hen COVID-19 spread around started scouring thousands of coronavirus In April, Korber, Montefiori and others the globe this year, David genetic sequences for mutations that might warned in a preprint posted to the bioRxiv Montefiori wondered how the have changed the virus’s properties as it made server that “D614G is increasing in frequency deadly virus behind the pan- its way around the world. at an alarming rate”1. It had rapidly become demic might be changing as it Compared with HIV, SARS-CoV-2 is chang- the dominant SARS-CoV-2 lineage in Europe passed from person to person. ing much more slowly as it spreads. But one and had then taken hold in the United States, Montefiori is a virologist who mutation stood out to Korber. It was in the Canada and Australia. D614G represented a has spent much of his career gene encoding the spike protein, which helps “more transmissible form of SARS-CoV-2”, Wstudying how chance mutations in HIV help it virus particles to penetrate cells. Korber saw the paper declared, one that had emerged as to evade the immune system. -

Local Ceremonies to Honor the Team Were Held This Spring in Santa Fe
ReflectionsLos Alamos National Laboratory Vol. 3, No. 5 • June 1998 … see pages 6 and 7 A Department of Energy/University of California Laboratory Reflections Inside this issue … Safety: month-long emphasis, Cover photo illustration by Edwin Vigil year-long concern Immunologist devotes life’s work to AIDS research . Page 3 June is National Safety Month, and a number of activities promoting safety are taking place at work sites, schools and other Making the Lab safer . Page 4 institutions across the country. No doubt there will be lots of Lab would rather pamphlets handed out, advice given, statistics recited and presen- give it away . Page 5 tations made during the monthly observance. But if calling attention to safety Nonproliferation . Pages 6 and 7 saves just one life or prevents just one person from being injured, it will be well worth the effort. People . Pages 8 and 9 Here at the Lab, Safety Month will be observed in July (see Page 4) as it was last Just for fun . Page 11 year. Still, it doesn’t hurt to get in the spirit of thinking about safety a month in Spotlight: advance. Actually, safety is something we should think about all the time, on or Really tough ladies . Page 12 off the job. This was noted recently by an employee in a Daily Newsbulletin letter to the editor (“Safe-living people vs. safely-operating employees,” April 21). The employee said he practices safety at work because he is a safety-conscious person all the time. “I think safety consciousness only gets internalized and personalized when it is not limited to the workplace,” he wrote. -
Croi 2021 Program Committee
General Information CONTENTS WELCOME . 2 General Information General Information OVERVIEW . 2 CONTINUING MEDICAL EDUCATION . 3 CONFERENCE SUPPORT . 4 VIRTUAL PLATFORM . 5 ON-DEMAND CONTENT AND WEBCASTS . 5 CONFERENCE SCHEDULE AT A GLANCE . 6 PRECONFERENCE SESSIONS . 9 LIVE PLENARY, ORAL, AND INTERACTIVE SESSIONS, AND ON-DEMAND SYMPOSIA BY DAY . 11 SCIENCE SPOTLIGHTS™ . 47 SCIENCE SPOTLIGHT™ SESSIONS BY CATEGORY . 109 CROI FOUNDATION . 112 IAS–USA . 112 CROI 2021 PROGRAM COMMITTEE . 113 Scientific Program Committee . 113 Community Liaison Subcommittee . 113 Former Members . 113 EXTERNAL REVIEWERS . .114 SCHOLARSHIP AWARDEES . 114 AFFILIATED OR PROXIMATE ACTIVITIES . 114 EMBARGO POLICIES AND SOCIAL MEDIA . 115 CONFERENCE ETIQUETTE . 115 ABSTRACT PROCESS Scientific Categories . 116 Abstract Content . 117 Presenter Responsibilities . 117 Abstract Review Process . 117 Statistics for Abstracts . 117 Abstracts Related to SARS-CoV-2 and Special Study Populations . 117. INDEX OF SPECIAL STUDY POPULATIONS . 118 INDEX OF PRESENTING AUTHORS . .122 . Version 9 .0 | Last Update on March 8, 2021 Printed in the United States of America . © Copyright 2021 CROI Foundation/IAS–USA . All rights reserved . ISBN #978-1-7320053-4-1 vCROI 2021 1 General Information WELCOME TO vCROI 2021 Welcome to vCROI 2021! The COVID-19 pandemic has changed the world for all of us in so many ways . Over the past year, we have had to put some of our HIV research on hold, learned to do our research in different ways using different tools, to communicate with each other in virtual formats, and to apply the many lessons in HIV research, care, and community advocacy to addressing the COVID-19 pandemic . Scientists and community stakeholders who have long been engaged in the endeavor to end the epidemic of HIV have pivoted to support and inform the unprecedented progress made in battle against SARS-CoV-2 . -

Regulation of Murine Class I Genes by Interferons Is Controlled by Regions
Proc. Nati. Acad. Sci. USA Vol. 84, pp. 3380-3384, May 1987 Immunology Regulation of murine class I genes by interferons is controlled by regions located both 5' and 3' to the transcription initiation site (interferon action/transplantation antigens/gene regulation) BETTE KORBER, LEROY HOOD, AND IWONA STROYNOWSKI Division of Biology, California Institute of Technology, Pasadena, CA 91125 Contributed by Leroy Hood, January 7, 1987 ABSTRACT Interferons regulate the expression of a large initiation site are independently involved in IFN-a and IFN-y number of mammalian genes, including the major histocom- regulation of murine class I genes and that the level of patibility antigen genes. To investigate the mechanisms in- induction controlled by the promoter region constitutes only volved in interferon action, we have analyzed the ability of a minor portion of the response in L cells. In addition, we murine H-2Ld and H-2Dd DNA sequences to control the present results suggesting that the response to IFN-y and -a responses to interferon. The results indicate that interferon may have different sequence requirements in the promoter regulation of class I gene expression is complex and involves at region. least two mechanisms that are dependent on class I sequences located upstream and downstream to the transcription initia- tion site. In transfected mouse L cells, both of these regions are MATERIALS AND METHODS required for full enhancement of class I gene expression, with DNA Constructs, Enzymes, and Reagents. Class I genes and the major portion of the response controlled by the sequences their derivatives were subcloned from BALB/c cosmid and located 3' to the transcription initiation site. -

BETTE KORBER for the Degree of Doctor of Philosophy Chemical
REGULATION OF GLASS I GENES BY INTERFERONS Thesis by BETTE KORBER In Partial Fulfillment of the Requirements for the Degree of Doctor of Philosophy Division of Chemistry and Chemical Engineering California Institute of Technology Pasadena, California 1988 (submitted May 17, 1988) 11 This thesis is dedicated to my shelter and my storm, James Theiler. Ill Through the years, a man peoples a space with images of provinces, kingdoms, mountains, bays, ships, islands, fishes, rooms, tools, stars, horses, and people. Shortly before his death, he discovers that the patient labyrinth of lines traces the image of his own face. Beyond my anxiety, beyond this writing, the universe waits, inexhaustible, inviting. — Jorge Luis Borges You see, one thing is, I can live with doubt and uncertainty and not knowing. I think it is much more interesting to live not knowing than to have answers which might be wrong. I have approximate answers and possible beliefs and different degrees of certainty about different things... I don’t feel frightened by not knowing things, by being lost in a mysterious universe without having any purpose, which is the way it really is, so far as I can tell... I don’t feel frightened. — Richard P. Feynman Don’t be blue, be determined. — Leroy Hood iV TABLE OF COHTEHTS Page Acknowledgements...........................................................................................................................................................'v Abstract............................................................................................................................................................................... -

HIV Vaccine-Research Team Shifts to SARS-Cov-2
HIV vaccine-research team shifts to SARS-CoV-2 May 7, 2020 Building on previous work designing an experimental HIV vaccine being tested in two human vaccine efficacy trials, the Los Alamos National Laboratory HIV team is now deploying its expertise in genetic databases and bioinformatics against the novel coronavirus SARS-CoV-2, the virus that causes the COVID-19 disease. Three main thrusts are underway from the HIV team: developing a T-cell response vaccine approach, tracking the origin of the pathogen, and building a robust bioinformatics pipeline to track the virus’s evolution. While this work focuses on attacking the virus itself, other bioinformatics and modeling efforts across the Laboratory aim at predicting disease spread to support decision making by government and health agencies. Developing a T-cell response vaccine approach Bette Korber, a computational biologist and the driving force behind the “mosaic” vaccine concept for HIV, together with fellow scientists Will Fischer and Sandrasegaram Gnanakaran, is shifting her attention from HIV, ebola, and influenza vaccines to developing a T-cell based vaccine design for the SARS CoV-2 coronavirus. Traditional antibody vaccines are primarily intended to reduce rates of infection. Korber says they hope that vaccine-elicited T-cell responses could help ameliorate disease severity if people do get infected, and so this approach could be used to complement antibody-based vaccines. Korber and the HIV team members are in the Laboratory’s Theoretical Biology and Biophysics group. Tracking the origin of the pathogen Elena Giorgi, also of the Theoretical Biology and Biophysics group, recently published a pre-print paper on the origins of the virus,“Emergence of SARS-CoV-2 through Recombination and Strong Purifying Selection.” “Our team demonstrated, by looking at the genetic sequence of the virus and comparing it to other known coronaviruses, that it originated from animals,” said Giorgi. -

Of Sciences of the UNITED STATES of AMERICA
Proceedings OF THE National Academy of Sciences OF THE UNITED STATES OF AMERICA May 1987 Volume 84, Number 10 pp. 3081-3536 Table of Contents AUTHOR INDEX vii Physical Sciences CHEMISTRY Phytotoxins from the pathogenic fungi Drechslera maydis and Drechslera F. Sugawara, G. Strobel, R. N. Strange, 3081 sorghicola J. N. Siedow, G. D. Van Duyne, and J. Clardy Accessible surface areas as a measure of the thermodynamic parameters of Tatsuo Ooi, Motohisa Oobatake, George 3086 hydration of peptides Ndmethy, and Harold A. Scheraga Discrete wave mechanics: Multidimensional systems Frederick T. Wall 3091 MATHEMATICS Algebraic K-theory of discrete subgroups of Lie groups F. T. Farrell and L. E. Jones 3095 Biological Sciences BIOCHEMISTRY Specific inhibition of Trypanosoma cruzi neuraminidase by the human plasma R. P. Prioli, I. Rosenberg, and M. E. A. 3097 glycoprotein "cruzin" Pereira Regulation of actomyositl ATPase activity by troponin-tropomyosin: Effect of Lois E. Greene, David L. Williams, Jr., 3102 the binding of the myosin subfragment 1 (S-1) ATP complex and Evan Eisenberg i Contents Deduced amino acid sequence of bovine retinal Go.,: Similarities to other Krisa P. Van Meurs, C. William Angus, 3107 guanine nucleotide-binding proteins Sukadev Lavu, Hsiang-Fu Kung, Susanne K. Czarnecki, Joel Moss, and Martha Vaughan Cloning and DNA sequence of the mercuric- and organomercurial-resistance Hugh G. Griffin, Timothy J. Foster, 3112 determinants of plasmid pDU1358 Simon Silver, and Tapan K. Misra Sequences from a prokaryotic genome or the mouse dihydrofolate reductase Alison Baker and Gottfried Schatz 3117 gene can restore the import of a truncated precursor protein into yeast mitochondria Thyroid hormone regulates expression of a transfected a-myosin heavy-chain Thomas A. -

Evaluation of Different V3 Peptides in an Enzyme Immunoassay for Specific HIV Type 1 Group O Antibody Detection
AIDS RESEARCH AM) HUMAN RETROVIRUSES Volume 14, Number 11,1998, pp. 963-972 Mary Ann Liebert, Inc. Evaluation of Different V3 Peptides in an Enzyme Immunoassay for Specific HIV Type 1 Group O Antibody Detection PASCALE ONDOA,' BE'ITY WELEMS,' KATRIEN FRANSEN,' JOHN NKENGASONG,' WOUTER JANSSENS,' LEO J3EYNDRICJSX,' LEOPOLD ZEKENG? PETER NDUMBE? FRANÇOIS SIMON: SENTOB SARAGOSTI: LUTZ GÜRTLER? JLART~PEETERS;~ BETTE KORBER? JAAP GOUDSMIT,9 and GUIDO VAN DER GROEN' ABSTRACT Strategies to discriminate group O from group M infections need to be improved. We have developed and evaluated an HN-1 group O V3 peptide-based enzyme immunoassay (PEW) for specific HIvl group O an- tibody detection among HIV-l-infected patients. Synthetic peptides, derived from the amino acid sequences of the V3 loop of 15 different group O strains and 7 group O consensus sequences, were evaluated in a PEIA against a panel of genetically confirmed group O (n = 33), group M (n = go), and HIV-1 antibody-negative sera (n = 17). The best-performing PEIA(s) were then used to screen 134 sera of European and 336 sera of Cameroonian origin for the presence of anti-HIV-1 group O antibodies. The reactivity of reference ("gold standard") sera to individual peptides in the PEIA resulted in the selection of five different peptides with sen- sitivities (sens), specificities (spec), and test efficiencies (TES) in the range of 90 to 100%. Improvement of the PEIA was obtained with simultaneous reactivity of at least two different peptides in separate wells of an ELISA plate, together with stringent criteria for positivity. -

Simulations Reveal How Dominant SARS- Cov-2 Strain Binds to Host, Succumbs to Antibodies
Simulations reveal how dominant SARS- CoV-2 strain binds to host, succumbs to antibodies April 16, 2021 EMBARGOED UNTIL FRIDAY, 4/16/21 AT 12 P.M. EDT/10 A.M. MDT LOS ALAMOS, N.M., April 16, 2021—Large-scale supercomputer simulations at the atomic level show that the dominant G form variant of the COVID-19-causing virus is more infectious partly because of its greater ability to readily bind to its target host receptor in the body, compared to other variants. These research results from a Los Alamos National Laboratory–led team illuminate the mechanism of both infection by the G form and antibody resistance against it, which could help in future vaccine development. “We found that the interactions among the basic building blocks of the Spike protein become more symmetrical in the G form, and that gives it more opportunities to bind to the receptors in the host — in us,” said Gnana Gnanakaran, corresponding author of the paper published today in Science Advances. “But at the same time, that means antibodies can more easily neutralize it. In essence, the variant puts its head up to bind to the receptor, which gives antibodies the chance to attack it.” Researchers knew that the variant, also known as D614G, was more infectious and could be neutralized by antibodies, but they didn’t know how. Simulating more than a million individual atoms and requiring about 24 million CPU hours of supercomputer time, the new work provides molecular-level detail about the behavior of this variant’s Spike. Current vaccines for SARS-CoV-2, the virus that causes COVID-19, are based on the original D614 form of the virus. -
The Next Big Idea
Richard P. Feynman Center for Innovation PROGRESS REPORTREPORT the next big idea LA-UR-XX-XXXXX1 Transitioning Los Alamos’ Top Innovations Depends on researchers who want to take their scientific discoveries beyond the laboratory and create technologies that can change the world. We do this by inventing, innovating, disrupting and partnering to deploy Los Alamos technology. Inventing Los Alamos National Laboratory has been inventing for the past 75 years to accomplish the difficult, the unexpected and at times, what seems impossible. In 2017, Los Alamos was granted a patent on average every 4 days. Innovating Los Alamos’ immense contributions in leading edge science and technology research and de- velopment are directed into solving complex and forthcoming national security challenges. This year we honor the Los Alamos researchers who have exceptional and longstanding con- tributions to scientific discovery, innovation, and collaborations to deploy their technology. Disrupting Los Alamos has a long history of disruptive innovations starting with the first nuclear weapon. This year we highlight big and small science behind the next disruptive innovations; “mosaic” vaccine for HIV, innovation in small nuclear reactor technology, software suite that pushes boundaries for modeling fluid flow and contaminant transport in fractured rock, and the development of augmented reality tools for nuclear criticality safety. Partnering Los Alamos science has assisted partners big and small with their toughest challenges, this year we had four postdocs who took on a challenge to reach out to potential partners to test their technology’s commercial potential. Contact Information: Phone: 505.665.9090 Email: [email protected] Web: www/lanl.gov/feynmancenter fci.lanl.gov 2 The people powering innovation The Richard P. -
Coping with Viral Diversity in HIV Vaccine Design: a Response to Nickle Et Al
Correspondence recombined natural sequences, the algorithm proceeds by a Coping with Viral Diversity in series of iterations of recombination and selection, HIV Vaccine Design: optimizing for 9-mer coverage of the input sequences. The result is a small set of full-length protein sequences that A Response to Nickle et al. collectively approach the upper bound on coverage Will Fischer, H. X. Liao, Barton F. Haynes, attainable for a given number of proteins [2]. Norman L. Letvin, Bette Korber We designed a three-mosaic protein set using the same input data as Nickle et al. to directly compare the two Nickle et al. [1] recently reported a computational method methods using the same metric as Nickle et al. The mosaic set, for HIV-1 vaccine antigen design; here we compare this despite being constrained to use full-length proteins, method with our previously published vaccine antigen design performed slightly better in terms of 9-mer coverage than method [2], using several criteria that we believe to be three protein lengths using COTþ (Figure 2). The mosaics important for a successful vaccine candidate [2]. The intent of used three full-length protein sequences, however, compared both approaches is to design a set of vaccine antigens that to 38 fragments for Gag and 15 for Nef included in the could protect against diverse circulating strains of HIV-1 by optimal coverage COTþ antigen design (Figure 1, Table 1). eliciting broad T cell responses. T cells recognize short The processing of antigens that ultimately results in the peptides of 8–12 amino acids, called epitopes, that are presentation of epitopes is not completely understood.