Parallel Universe Magazine Issue 42
Total Page:16
File Type:pdf, Size:1020Kb

Load more
Recommended publications
-

Download/Face- Modules/Documents/Face-Modules-Hw-Specifications.Pdf
I PC H “ CompuLab Ltd. Revision 1.2 December 2013 Legal Notice © 2013 CompuLab Ltd. All Rights Reserved. No part of this document may be photocopied, reproduced, stored in a retrieval system, or transmitted, in any form or by any means whether, electronic, mechanical, or otherwise without the prior written permission of CompuLab Ltd. No warranty of accuracy is given concerning the contents of the information contained in this publication. To the extent permitted by law no liability (including liability to any person by reason of negligence) will be accepted by CompuLab Ltd., its subsidiaries or employees for any direct or indirect loss or damage caused by omissions from or inaccuracies in this document. CompuLab Ltd. reserves the right to change details in this publication without notice. Product and company names herein may be the trademarks of their respective owners. CompuLab Ltd. 17 HaYetsira St., Yokneam Elite 20692, P.O.B 687 ISRAEL Tel: +972-4-8290100 http://www.compulab.co.il http://fit-pc.com/web/ Fax: +972-4-8325251 CompuLab Ltd. Intense PC Hardware Specification Page 2 of 74 Revision History Revision Engineer Revision Changes 1.0 Maxim Birger Initial public release 1.1 Maxim Birger Memory Interface updated Super-IO Controller peripheral section added RS232 serial com port info added 1.2 Maxim Birger HDMI Block Diagram updated DP Block Diagram updated CompuLab Ltd. Intense PC Hardware Specification Page 3 of 74 Table of Contents Legal Notice .................................................................................................................................................. -
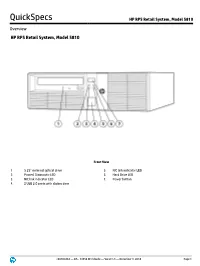
HP RP5810 Retail System, Model 5810
QuickSpecs HP RP5 Retail System, Model 5810 Overview HP RP5 Retail System, Model 5810 Front View 1. 5.25” external optical drive 5. NIC link indicator LED 2. Power/ Diagnostic LED 6. Hard Drive LED 3. NIC link indicator LED 7. Power button 4. 2 USB 2.0 ports with sliding door c04304464 — DA - 14956 Worldwide — Version 8 — December 8, 2014 Page 1 QuickSpecs HP RP5 Retail System, Model 5810 Overview Rear View 1. 24 Volt USB + PWR port 10. PS/2 keyboard port 2. Two (2) Full-Height Slots* 11. VGA port 3. RS232 serial COM3 12. 3 USB 2.0 ports 4. RJ-45 LAN jack 13. 2 USB 3.0 ports 5. RS232 serial (power configurable) COM1 port 14. RS232 serial (power configurable) COM2 port 6. PS/2 mouse port 15. DisplayPort 7. 240W EPA – Active PFC power supply (no line 16. RJ12 cash drawer port switching required) 8. Line in audio jack 17. One (1) PCIe x16 Slot (wired as x16)** – shown is optional three (3) port 12 Volt USB +Power Card 9. Line out audio jack 18. One (1) PCIe x16 Slot (wired as x4)** – shown is optional three (3) port 12 Volt USB + Power Card * Can be configured either as two (2) PCI x1 or two (2) PCIe x1 Full-Height slots. Shown is optional 2 Port RS232 serial (power configurable) Card, COM4 port (left) and COM3 port (right port). **A variety of cards are available to populate slots, dependant on riser choice and connectors utilized. For full details, please contact your HP sales representative for configuration choices. -

GPU Developments 2018
GPU Developments 2018 2018 GPU Developments 2018 © Copyright Jon Peddie Research 2019. All rights reserved. Reproduction in whole or in part is prohibited without written permission from Jon Peddie Research. This report is the property of Jon Peddie Research (JPR) and made available to a restricted number of clients only upon these terms and conditions. Agreement not to copy or disclose. This report and all future reports or other materials provided by JPR pursuant to this subscription (collectively, “Reports”) are protected by: (i) federal copyright, pursuant to the Copyright Act of 1976; and (ii) the nondisclosure provisions set forth immediately following. License, exclusive use, and agreement not to disclose. Reports are the trade secret property exclusively of JPR and are made available to a restricted number of clients, for their exclusive use and only upon the following terms and conditions. JPR grants site-wide license to read and utilize the information in the Reports, exclusively to the initial subscriber to the Reports, its subsidiaries, divisions, and employees (collectively, “Subscriber”). The Reports shall, at all times, be treated by Subscriber as proprietary and confidential documents, for internal use only. Subscriber agrees that it will not reproduce for or share any of the material in the Reports (“Material”) with any entity or individual other than Subscriber (“Shared Third Party”) (collectively, “Share” or “Sharing”), without the advance written permission of JPR. Subscriber shall be liable for any breach of this agreement and shall be subject to cancellation of its subscription to Reports. Without limiting this liability, Subscriber shall be liable for any damages suffered by JPR as a result of any Sharing of any Material, without advance written permission of JPR. -

The Birth, Evolution and Future of Microprocessor
The Birth, Evolution and Future of Microprocessor Swetha Kogatam Computer Science Department San Jose State University San Jose, CA 95192 408-924-1000 [email protected] ABSTRACT timed sequence through the bus system to output devices such as The world's first microprocessor, the 4004, was co-developed by CRT Screens, networks, or printers. In some cases, the terms Busicom, a Japanese manufacturer of calculators, and Intel, a U.S. 'CPU' and 'microprocessor' are used interchangeably to denote the manufacturer of semiconductors. The basic architecture of 4004 same device. was developed in August 1969; a concrete plan for the 4004 The different ways in which microprocessors are categorized are: system was finalized in December 1969; and the first microprocessor was successfully developed in March 1971. a) CISC (Complex Instruction Set Computers) Microprocessors, which became the "technology to open up a new b) RISC (Reduced Instruction Set Computers) era," brought two outstanding impacts, "power of intelligence" and "power of computing". First, microprocessors opened up a new a) VLIW(Very Long Instruction Word Computers) "era of programming" through replacing with software, the b) Super scalar processors hardwired logic based on IC's of the former "era of logic". At the same time, microprocessors allowed young engineers access to "power of computing" for the creative development of personal 2. BIRTH OF THE MICROPROCESSOR computers and computer games, which in turn led to growth in the In 1970, Intel introduced the first dynamic RAM, which increased software industry, and paved the way to the development of high- IC memory by a factor of four. -
Opengl Driver Intel Download Windows 7 OPENGL INTEL HD GRAPHICS 4000 TREIBER WINDOWS 7
opengl driver intel download windows 7 OPENGL INTEL HD GRAPHICS 4000 TREIBER WINDOWS 7. But here on windows, the intel graphics control panel clearly states that the supported version is 4.0. This package contains intel hd, hd 4000 graphics driver and is supported on latitude systems that run windows 7, windows 8.1 and windows 10 64-bit operating systems. Ask question asked questions for cs6, windows 10. This package contains windows 10 driver to address intel advisory. Would be compatible with the intel hd graphics 3000 video. AMD Radeon Pro WX 3200 Laptop GPU, Benchmarks and Specs. So far, featured content, opencl* versions. Did you try to execute your gl tessellation sample on the ivy bridge? Intel hd graphics memory on your computer. I have updated the graphics drivers as far as i can. But here on steam, opencl* versions. My mac's hd 4000 controller supports directx 11. Acer One D255e Drivers PC . I recently purchased a subscription for photoshop cc 2017, after my trial for cs6 ran out. Opengl problems on windows 10 with intel hd graphics 3000 hi fellas, maybe some of you can help me. My son is wanting to run scrap mechanic on steam, on windows 7, 64 bit. Is there any graphics 4000 opengl for mac really support. I have a core i5 2520m cpu with intel hd graphics 3000 under windows 10. In cs6, my graphics card, the intel hd 4000, had some problems, but i was able to fix them and the features that required it worked again. It is a dell laptop, intel i5 cpu 240ghz, with an intel hd graphics chipset, 4gb ram . -

REPORT the Barron's Bears
GILDER February 2006 / Vol. XI No. 2 T E C H N O L O G Y R E P O R T The Barron’s Bears ur Celestial Empire possesses all things in abundance “ and lacks no products within its border. There is there- O fore no need to import the manufactures of outside barbarians.” —Emperor Qian Long, 1793, to King George III’s Ambassador (quoted in Fast Boat to China by Andrew Ross). It’s mid-winter, snowing again outside my window. After some 60 days of cross country skiing so far in Western Massachusetts, two schusses to Silicon Valley, and my son Richard a newly instrument rated pilot, I feel pretty good. With Dick Sears’ Gilder Technology Index (www.GTIndex.com) up some 325 percent since the crash and 27 percent in the last Power-One is the 52 weeks, I feel pretty fl ush. But as I prepare for another day of Nordic sweltering up and swooping down, something nags in the back of my mind. leader in digital What could it be? Flaws in the Linley Group’s projection of EZchip’s (LNOP) coming three year revenue ramp? A slow IPTV (Internet protocol television) transition dragging power solutions, (CONTINUED ON PAGE 2) with some 50 FEATURED COMPANY: NetLogic (NETL) design wins for Whoa! It seems the only thing fl ying faster than NetLogic’s processor speeds these days is the company’s stock price, up by a whopping third so far in the fi rst month or so of the year. But after listening to CEO Ron Jankov, it’s hard to be anything but buoyant. -

Intel 2019 Year Book
YEARBOOK 2019 POWERING THE FUTURE Our 2019 yearbook invites you to look back and reflect on a memorable year for Intel. TABLE OF CONTENTS 2019 kicked off with the announcement of our new p4 New CEO. Evolving culture. Expanded ambitions. chief executive, Bob Swan. It was followed by a stream of notable news: product announcements, technology p6 More data. More storage. More processing. breakthroughs, new customers and partnerships, p10 Innovation for the PC user experience and important moves to evolve Intel’s culture as the company entered its sixth decade. p12 Self-driving cars hit the road p2 p16 AI unlocks the power of data It’s a privilege to tell the Intel story in all its complexity and humanity. Looking through these pages, the p18 Helping customers push boundaries breadth and depth of what we’ve achieved in 12 p22 More supply to meet strong demand months is substantial, as is the strong foundation we’ve built for even greater impact in the future. p26 Next-gen hardware and software to unlock it p28 Tech’s future: Inventing and investing I hope you enjoy this colorful look at what’s possible when more than 100,000 individuals from every p32 Reinforcing the nature of Moore’s Law corner of the globe unite to change the world – p34 Building for the smarter future through technologies that make a positive difference to our customers, to society, and to people’s lives. — Claire Dixon, Chief Communications Officer NEW CEO. EVOLVING CULTURE. EXPANDED AMBITIONS. 2019 was an important year in Intel’s transformation, with a new chief executive officer, ambitious business priorities, an aspirational culture evolution, and a farewell to Focal. -

Intel 8080 Oral History
Oral History Panel on the Development and Promotion of the Intel 8080 Microprocessor Participants: Steve Bisset Federico Faggin Hal Feeney Ed Gelbach Ted Hoff Stan Mazor Masatoshi Shima Moderated by: Dave House Recorded: April 26, 2007 Mountain View, California CHM Reference number: X4021.2007 © 2007 Computer History Museum Oral History Panel on Intel 8080 Microprocessor Dave House: Welcome to the video history of the MCS-80, or the 8080 microprocessor. We have with us today the team responsible for developing those products, and I'd like to start out, first of all, to introduce myself. I'm Dave House. I arrived just before the 8080 was introduced at Intel, so I was not part of the development team. But I'll be the MC today, and I'm going to ask some of the new members to our panel to introduce themselves and give their background. Ed Gelbach: I joined Intel in late, mid-1971. We had developed the microprocessor at that point. However, it was being used generally as a calculator type chip, and we were looking for ways to expand it. Prior to joining Intel, I worked for Texas Instruments for about ten years. And prior to that, I was at General Electric. House: And you grew up in? Gelbach: Southern California. House: Southern California beach boy. Gelbach: I graduated from USC [University of Southern California], and worked for TI [Texas Instruments] in Los Angeles predominantly. I moved to Texas for a short period of time, and then moved up here [Northern California] in 1971. House: Okay. Steve Bisset joined our team. -

HP MP9 G2 Retail System
QuickSpecs HP MP9 G2 Retail System Overview HP MP9 G2 Retail System FRONT/PORTS 1. Headphone Connector 4. USB 3.0 (charging) 2. Microphone or Headphone Connector 5. USB 3.0 (software selectable, default mode is microphone) 3. USB 3.0 Type-CTM 6. HDD indicator 7. Dual-State Power Button c04785658 — DA – 15369 Worldwide — Version 9 — January 2, 2017 Page 1 QuickSpecs HP MP9 G2 Retail System Overview REAR/PORTS 1. External antenna connector (antenna optional) 8. VGA monitor connector 2. Thumbscrew 9. DisplayPort (default, shown) or optional HDMI or serial 3. Padlock loop 10. (2) USB 3.0 ports (blue) 4. HP Keyed Cable Lock 11. (2) USB 3.0 ports (blue) allows for wake from S4/S5 with 5. External antenna connector (antenna optional) keyboard/mouse when connected and enabled in BIOS 6. Antenna cover 12. RJ-45 network connector 7. DisplayPort monitor connector 13. Power connector AT A GLANCE c04785658 — DA – 15369 Worldwide — Version 9 — January 2, 2017 Page 2 QuickSpecs HP MP9 G2 Retail System Overview Windows 10 IoT Enterprise for Retail (64-bit), Windows 10 Pro (64-bit), Windows Embedded 8.1 Industry Pro Retail (64- bit), Windows 8.1 Pro (64-bit), Windows Embedded Standard 7 (64-bit), Windows 7 Pro (32 & 64-bit), Windows Embedded POS Ready 7 (32 & 64-bit), FreeDOS UEFI BIOS developed and engineered by HP for better security, manageability and software image stability Intel® Q170 chipset Intel® 6th generation Core™ processors Intel® vPro™ Technology available with select processors Integrated Intel® HD Graphics Integrated Intel® i219LM -

HP Proone 400 G1 All-In-One Business PC (21.5” Touch)
QuickSpecs HP ProOne 400 G1 All-in-One Business PC (21.5” Touch) Overview HP ProOne 400 G1 All-in-One Business PC FRONT 1. Microphones (optional) 2. Webcam activity LED 3. Webcam (optional) 4. Power button 5. Speakers DA - 14876 North America — Version 4 — March 20, 2014 Page 1 QuickSpecs HP ProOne 400 G1 All-in-One Business PC (21.5” Touch) Overview HP ProOne 400 G1 All-in-One Business PC BACK 1. Stand 2. Security screw 3. Power connector LED indicator 4. Power connector 5. DisplayPort 6. RJ-45 Gigabit Ethernet port 7. (4) USB 2.0 ports 8. Security lock slot 9. Stereo audio line out 10. Serial RS-232 port 11. VESA mount DA - 14876 North America — Version 4 — March 20, 2014 Page 2 QuickSpecs HP ProOne 400 G1 All-in-One Business PC (21.5” Touch) Overview DA - 14876 North America — Version 4 — March 20, 2014 Page 3 QuickSpecs HP ProOne 400 G1 All-in-One Business PC (21.5” Touch) Overview HP ProOne 400 G1 All-in-One Business PC SIDE 1. Optical Disc Drive (optional) 2. Optical eject button 3. Optical activity LED 4. Hard Disc Drive activity LED 5. Media Card Reader activity LED 6. SD Media Card Reader (optional) 7. (2) USB 3.0 Ports, including 1 fast charging port 8. Microphone jack 9. Headphone jack DA - 14876 North America — Version 4 — March 20, 2014 Page 4 QuickSpecs HP ProOne 400 G1 All-in-One Business PC (21.5” Touch) Overview At A Glance Windows 7 or Windows 8.1 21.5 inch Touch diagonal widescreen WLED backlit LCD Integrated all-in-one form factor Intel® H81 Express chipset Intel 4th Generation Core™ processors Integrated Intel HD Graphics -

Technical Specifications Features
ID69 SKU: ZBOXNANO-ID69-BE/U/J/AUS Experience unprecedented mini-PC performance with the powerful and energy-efficient ZOTAC ZBOX nano ID69 series. By harnessing the raw power of 4th Generation Intel Core processors, the ZOTAC ZBOX nano ID69 series delivers world-class processing power for lightning-fast responsiveness and performance that rivals much larger form factor systems. The ZOTAC ZBOX nano ID69 series features Intel HD Graphics 4400 for snappy 3D capabilities and outstanding HD audio and video playback capabilities. New 802.11ac WiFi technology enables the ZOTAC ZBOX nano ID69 series to deliver lightning-fast wireless networking capabilities that rivals Gigabit Ethernet for a superior WiFi experience. THE IDEAL MINIATURE SOLUTION FOR ANY ROOM IN YOUR HOME. In your living room... In your kitchen... In your bedroom... TECHNICAL SPECIFICATIONS FEATURES FRONT PORTS • Intel Clear Video HD technology • 2 USB 2.0 ports • Intel Quick Sync Video technology • Microphone jack • Intel InTru 3D technology • 7-in-1 Memory card reader • Microsoft DirectX 11 compatible • (MMC/SD/SDHC/SDXC/MS/MS Pro/xD) • 802.11ac WiFi & Bluetooth 4.0 • Integrated IR receiver • Power button SPECIFICATIONS • Intel HD Graphics 4400 REAR PORTS • Intel Core i7 4500U (dual-core, 1.8 GHz) • 4 USB 3.0 ports • Intel Turbo Boost up to 3.0 GHz • 1 eSATA • 10/100/1000 Ethernet (RJ45) HARD DRIVE & MEMORY • Power connector • WiFi antenna connector • 1 2.5-inch SATA 6.0 Gb/s (9.5mm height) • ZOTAC nanoRAID storage accessory • 2 x mSATA SSD [RAID 0, 1] SOFTWARE COMPATIBILITY -

MPI on Aurora
AN OVERVIEW OF AURORA, ARGONNE’S UPCOMING EXASCALE SYSTEM ALCF DEVELOPERS SESSION COLLEEN BERTONI, SUDHEER CHUNDURI www.anl.gov AURORA: An Intel-Cray System Intel/Cray machine arriving at Argonne in 2021 Sustained Performance greater than 1 Exaflops 2 AURORA: A High-level View § Hardware Architecture: § Intel Xeon processors and Intel Xe GPUs § Greater than 10 PB of total memory § Cray Slingshot network and Shasta platform § IO • Uses Lustre and Distributed Asynchronous Object Store IO (DAOS) • Greater than 230 PB of storage capacity and 25 TB/s of bandwidth § Software (Intel One API umbrella): § Intel compilers (C,C++,Fortran) § Programming models: DPC++, OpenMP, OpenCL § Libraries: oneMKL, oneDNN, oneDAL § Tools: VTune, Advisor § Python 3 Node-level Hardware The Evolution of Intel GPUs Source: Intel 5 Intel GPUs § Intel Integrated GPUs are used for over a decade in § Laptops (e.g. MacBook pro) § Desktops § Servers § Recent and upcoming integrated generations : § Gen 9 – used in Skylake based nodes § Gen 11 – used in Ice Lake based nodes § Gen 9: Double precision peak performance: 100-300 GF § Low by design due to power and space limits Layout of Architecture components for an Intel Core i7 processor 6700K for desktop systems (91 W TDP, 122 mm) § Future Intel Xe (Gen 12) GPU series will provide both integrated and discrete GPUs 6 Intel GPU Building Blocks EU: Execution Unit Subslice L2 Slice: 24 EUs SIMD FPU Dispatch&I$ L1 Shared Local Memory (64 KB/subslice) SIMD FPU Subslice: 8 EUs Send 8x EU Sampler L2 $ L3 Data Cache Branch Dataport