Intelligence Might Not Be Computational a Hierarchy of AI
Total Page:16
File Type:pdf, Size:1020Kb
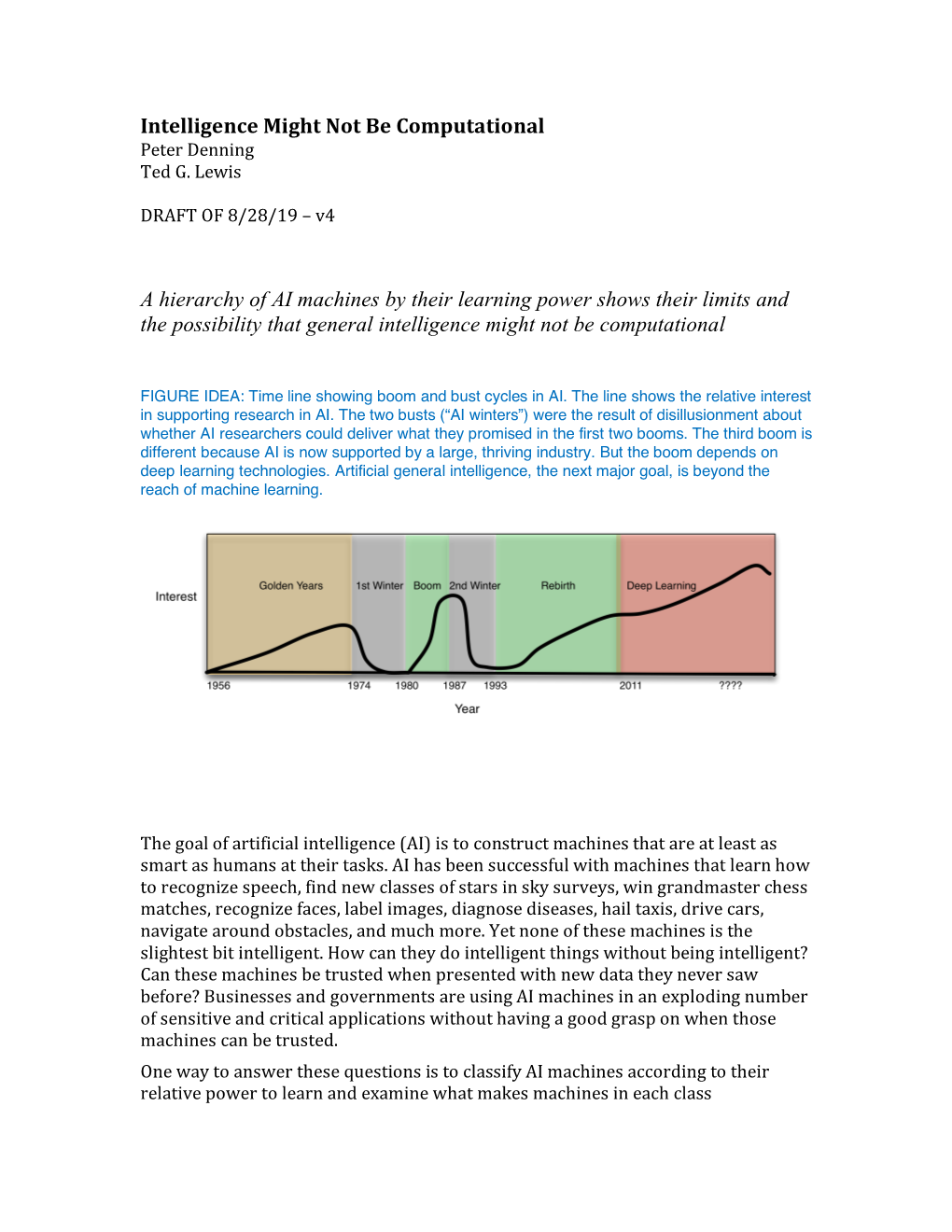
Load more
Recommended publications
-

University of Navarra Ecclesiastical Faculty of Philosophy
UNIVERSITY OF NAVARRA ECCLESIASTICAL FACULTY OF PHILOSOPHY Mark Telford Georges THE PROBLEM OF STORING COMMON SENSE IN ARTIFICIAL INTELLIGENCE Context in CYC Doctoral dissertation directed by Dr. Jaime Nubiola Pamplona, 2000 1 Table of Contents ABBREVIATIONS ............................................................................................................................. 4 INTRODUCTION............................................................................................................................... 5 CHAPTER I: A SHORT HISTORY OF ARTIFICIAL INTELLIGENCE .................................. 9 1.1. THE ORIGIN AND USE OF THE TERM “ARTIFICIAL INTELLIGENCE”.............................................. 9 1.1.1. Influences in AI................................................................................................................ 10 1.1.2. “Artificial Intelligence” in popular culture..................................................................... 11 1.1.3. “Artificial Intelligence” in Applied AI ............................................................................ 12 1.1.4. Human AI and alien AI....................................................................................................14 1.1.5. “Artificial Intelligence” in Cognitive Science................................................................. 16 1.2. TRENDS IN AI........................................................................................................................... 17 1.2.1. Classical AI .................................................................................................................... -

Udc 004.838.2 Irsti 20.19.21 Comparative Analysis Of
Comparative analysis of knowledge bases: ConceptNet vs CYC A. Y. Nuraliyeva, S. S. Daukishov, R.T. Nassyrova UDC 004.838.2 IRSTI 20.19.21 COMPARATIVE ANALYSIS OF KNOWLEDGE BASES: CONCEPTNET VS CYC A. Y. Nuraliyeva1, S. S. Daukishov2, R.T. Nassyrova3 1,2Kazakh-British Technical University, Almaty, Kazakhstan 3IT Analyst, Philip Morris Kazakhstan, Almaty, Kazakhstan [email protected], ORCID 0000-0001-6451-3743 [email protected], ORCID 0000-0002-3784-4456 [email protected], ORCID 0000-0002-7968-3195 Abstract. Data summarization, question answering, text categorization are some of the tasks knowledge bases are used for. A knowledge base (KB) is a computerized compilation of information about the world. They can be useful for complex tasks and problems in NLP and they comprise both entities and relations. We performed an analytical comparison of two knowledge bases which capture a wide variety of common-sense information - ConceptNet and Cyc. Manually curated knowledge base Cyc has invested more than 1,000 man-years over the last two decades building a knowledge base that is meant to capture a wide range of common-sense skills. On the other hand, ConceptNet is a free multilingual knowledge base and crowdsourced knowledge initiative that uses a large number of links to connect commonplace items. When looking for common sense logic and answers to questions, ConceptNet is a great place to start. In this research, two well-known knowledge bases were reviewed - ConceptNet and Cyc - their origin, differences, applications, benefits and disadvantages were covered. The authors hope this paper would be useful for researchers looking for more appropriate knowledge bases for word embedding, word sense disambiguation and natural-language communication. -

November 15, 2019, NIH Record, Vol. LXXI, No. 23
November 15, 2019 Vol. LXXI, No. 23 with a brain-controlled robotic exoskeleton who had been paralyzed for 9 years, “didn’t say, ‘I kicked the ball!’” said Nicolelis. More CLINICAL PROMISE SHOWN importantly, he said, “I felt the ball!” It took a team of 156 scientists from Nicolelis Outlines Progress in 25 countries on 5 continents to reach this Brain-Machine Interfaces moment for which neuroscientist Nicolelis BY RICH MCMANUS had been preparing for 20 years. He recruited the team by dangling field tickets to There is probably no other scientist in the World Cup in front of potential recruits. the world for whom peer review meant “It was a hard way to win a free ticket having his experiment succeed in front of a to the game, but that is the Brazilian way,” stadium full of 75,000 screaming Brazilians, quipped Nicolelis, a native of that country. with another 1.2 billion people watching on Now a professor of neuroscience at live television. Duke University School of Medicine, But at the start of the 2014 World Cup at Nicolelis, who won an NIH Pioneer Award Corinthians Arena in Sao Paulo, Dr. Miguel in 2010 for work he said couldn’t earn a Nicolelis witnessed his patient Juliano Pinto, penny of funding a decade earlier, spoke a paraplegic, not only kick a soccer ball to Oct. 16 at an NIH Director’s Lecture in start the tournament, but also “feel” his foot Masur Auditorium. striking the ball. In the late 1980s, Nicolelis, who has been Duke’s Dr. Miguel Nicolelis discusses his research on brain-machine interfaces. -

Automated Theory Formation in Mathematics1 1
AUTOMATED THEORY FORMATION IN MATHEMATICS1 Douglas B. Lenat Computer Science Department Carnegie-Mellon University Pittsburgh, Pa. 15213 Abstract of fully automatic theory formation in some scientific field. "1 his includes two activities: (i) discovering relationships A program called "AM" is described which cairies on simple among known concepts (e.g., by formal manipulations, or by mathematics research: defining, and studying new concepts noticing regularities in empirical data), and (ii) defining new under the guidance of a large body of heuiistic rules. The concepts for investigation. Meta-Dendral [Buchanan 75] 250 heurKtus communicate via an agenda mechanism, a performs only the first of these; most domain-independent global priority queue of small bisk', for the program to concept learning programs (Winston 70] perform only the pei foim and teasons why each task is plausible (e.g., "Find latter of these: while they do create new concepts, the PENCRAHZTION. of 'prnes', because turued out to be initiative is not theirs but rather is that of a human so useful a Conccpi"). Fach concept is an active, structured "teacher" who already has the concepts in mind. knowledge module. One bundled vei y incomplete modules are initially supplied, each one corresponding to an What we are describing is a computet program which elementary set theoretic concept (e.g., union). This defines new concepts, investigates them, notices provides a definite but immense space which AM begins to regularities in the data about them, and conjectures explore. In one boor, AM rediscovers hundreds of common relationships between them. This new information is used concepts (including singleton sets, natural numbers, by the program to evaluate the newly-defined concepts, arithmetic) and theorems (e.g., unique factorization). -

Cyc: a Midterm Report
AI Magazine Volume 11 Number 3 (1990) (© AAAI) Articles The majority of work After explicating the need for a large common- We have come a in knowledge repre- sense knowledge base spanning human consen- long way in this . an sentation has dealt sus knowledge, we report on many of the lessons time, and this article aversion to with the technicali- learned over the first five years of attempting its presents some of the ties of relating predi- construction. We have come a long way in terms lessons learned and a addressing cate calculus to of methodology, representation language, tech- description of where the problems niques for efficient inferencing, the ontology of other formalisms we are and briefly the knowledge base, and the environment and that arise in and with the details infrastructure in which the knowledge base is discusses our plans of various schemes being built. We describe the evolution of Cyc for the coming five actually for default reason- and its current state and close with a look at our years. We chose to representing ing. There has almost plans and expectations for the coming five years, focus on technical been an aversion to including an argument for how and why the issues in representa- large bodies addressing the prob- project might conclude at the end of this time. tion, inference, and of knowledge lems that arise in ontology rather than actually represent- infrastructure issues with content. ing large bodies of knowledge with content. such as user interfaces, the training of knowl- However, deep, important issues must be edge enterers, or existing collaborations and addressed if we are to ever have a large intelli- applications of Cyc. -

Artificial Intelligence Artificial Intelligence 80 (1996) 143-150
View metadata, citation and similar papers at core.ac.uk brought to you by CORE provided by Elsevier - Publisher Connector Artificial Intelligence Artificial Intelligence 80 (1996) 143-150 Book Review Hubert Dreyfus, What Computers Still Can’t Do* John McCarthy* Computer Science Department, Stanford University, Stanford, CA 94305, USA Received December 1994 1. Progress in logic-based AI Hubert Dreyfus claims that “symbolic AI” is a “degenerating research program”, i.e. is not making progress. It’s hard to see how he would know, since he makes no claim to have read much of the recent literature. In defending “symbolic AI”, I shall concentrate on just one part of symbolic AI-the logic-based approach. It was first proposed in [7], attracted only intermittent following at first, but has had an increasing number of workers since 1970.’ I think other approaches to AI will also eventually succeed, perhaps even connectio’nism. To contradict an earlier Dreyfus metaphor “AI at the Crossroads Again”, it isn’t a crossroads but a race including logic-based AI, SOAR, connectionism and several other contenders. How goes the logic-based runner? In fits and starts, as problems are identified and progress made. Within logic-based AI, I shall emphasize one development-formalized non- monotonic reasoning, because it illustrates intermittent but definite progress. It was first proposed in [8], gained momentum with the 1980 special issue of Artificial Intelligence, and summarized in the collection [3]. It has continued to develop, see e.g. [6]. Minsky [ll] mentioned the need for something like nonmonotonic reasoning, but used this fact as evidence for the inadequacy of logic-based approaches to AI and the need for approaches not based on logic. -

History of Artificial Intelligence 1 History of Artificial Intelligence
History of artificial intelligence 1 History of artificial intelligence The history of artificial intelligence began in antiquity, with myths, stories and rumors of artificial beings endowed with intelligence or consciousness by master craftsmen; as Pamela McCorduck writes, AI began with "an ancient wish to forge the gods."[1] The seeds of modern AI were planted by classical philosophers who attempted to describe the process of human thinking as the mechanical manipulation of symbols. This work culminated in the invention of the programmable digital computer in the 1940s, a machine based on the abstract essence of mathematical reasoning. This device and the ideas behind it inspired a handful of scientists to begin seriously discussing the possibility of building an electronic brain. The field of artificial intelligence research was founded at a conference on the campus of Dartmouth College in the summer of 1956. Those who attended would become the leaders of AI research for decades. Many of them predicted that a machine as intelligent as a human being would exist in no more than a generation and they were given millions of dollars to make this vision come true. Eventually it became obvious that they had grossly underestimated the difficulty of the project. In 1973, in response to the criticism of Sir James Lighthill and ongoing pressure from congress, the U.S. and British Governments stopped funding undirected research into artificial intelligence. Seven years later, a visionary initiative by the Japanese Government inspired governments and industry to provide AI with billions of dollars, but by the late 80s the investors became disillusioned and withdrew funding again. -

ARTIFICIAL INTELLIGENCE and CYC Ameer Hamza Khan, Amina Zaheer, Syeda Binish Zahra
LGURJCSIT Volume No. 1, Issue No. 4 (October- December), pp. 29-36 ARTIFICIAL INTELLIGENCE AND CYC Ameer Hamza Khan, Amina Zaheer, Syeda Binish Zahra Abstract: Since 1984, it is enormous work going on for the accomplishing of the project Cyc (‗Saik‘). This work is based on knowledge of ―Artificial Intelligence‖ which is developed by the Cycorpcompany and by Douglas Lenat at MCC. It‘s a Microelectronics and Computer Technology Corporation (MCC) part for so long. The dominant aim of Cycorp to develop this system is to just clarify anything in semantical determination rather than syntactically determination of words commands by the machine in which Cyc is installed to do some job. The other objective was in the building of Cyc is to codify, in a form which is usable by the machine, where knowledge‘s millions piece that composes common sense of a normal human or the common sense made in the human brain. Cyc presents a proprietary schema of knowledge representation that utilized first-order relationships. The relationships that presents between first-order logic (FOL) and first-order theory (FOT). After a long time, in1986, Cyc’s developer (Douglas Lenat) estimate that the total effort required to complete Cyc project would be 250,000 rules and 350 man-years. In 1994, Cyc Project was the reason behind creating independency into Cycorp, in Austin, Texas. As it is a common phrase that "Every tree is a plant" and "Plants die eventually" so that why by the mean of this some knowledge representing pieces which are in the database are like trees and plants like structures. -

By Eve M. Phillips Submitted to the Department of Electrical
If It Works, It's Not Al: A Commercial Look at Artificial Intelligence Startups by Eve M. Phillips Submitted to the Department of Electrical Engineering and Computer Science in Partial Fulfillment of the Requirements for the Degrees of Bachelor of Science in Computer Science and Engineering and Master of Engineering in Electrical Engineering and Computer Science at the Massachusetts Institute of Technology ,.ay7, 1999 @ Copyright 1999 Eve M. Phillips. All rights reserved. The author hereby grants to M.I.T. permission to reproduce and distribute publicly paper and electronic copies of this thesis and to grant others the right to do so. Author Department of Electrical Engineering and Computer Science May 7, 1999 Certified by_ Patrick Winston Thesis Supervisor Accepted by Arthur C. Smith Chairman, Department Committee on Graduate Theses If It Works, It's Not Al: A Commercial Look at Artificial Intelligence Startups by Eve M. Phillips Submitted to the Department of Electrical Engineering and Computer Science May 7, 1999 In Partial Fulfillment of the Requirements for the Degree of Bachelor of Science in Computer Science and Engineering and Master of Engineering in Electrical Engineering and Computer Science ABSTRACT The goal of this thesis is to learn from the successes and failure of a select group of artificial intelligence (AI) firms in bringing their products to market and creating lasting businesses. I have chosen to focus on Al firms from the 1980s in both the hardware and software industries because the flurry of activity during this time makes it particularly interesting. The firms I am spotlighting include the LISP machine makers Symbolics and Lisp Machines Inc.; Al languages firms, such as Gold Hill; and expert systems software companies including Teknowledge, IntelliCorp, and Applied Expert Systems. -

Common Sense Reasoning – from Cyc to Intelligent Assistant
Common Sense Reasoning – From Cyc to Intelligent Assistant Kathy Panton, Cynthia Matuszek, Douglas Lenat, Dave Schneider, Michael Witbrock, Nick Siegel, and Blake Shepard Cycorp, Inc. 3721 Executive Center Drive, Suite 100, Austin, TX 78731, USA {panton, cyndy, lenat, daves, witbrock, nsiegel, blake}@cyc.com Abstract. Semi-formally represented knowledge, such as the use of standardized keywords, is a traditional and valuable mechanism for helping people to access information. Extending that mechanism to include formally represented knowledge (based on a shared ontology) presents a more effective way of sharing large bodies of knowledge between groups; reasoning systems that draw on that knowledge are the logical counterparts to tools that perform well on a single, rigidly defined task. The underlying philosophy of the Cyc Project is that software will never reach its full potential until it can react flexibly to a variety of challenges. Furthermore, systems should not only handle tasks automatically, but also actively anticipate the need to perform them. A system that rests on a large, general-purpose knowledge base can potentially manage tasks that require world knowledge, or “common sense” – the knowledge that every person assumes his neighbors also possess. Until that knowledge is fully represented and integrated, tools will continue to be, at best, idiots savants. Accordingly, this paper will in part present progress made in the overall Cyc Project during its twenty-year lifespan – its vision, its achievements thus far, and the work that remains to be done. We will also describe how these capabilities can be brought together into a useful ambient assistant application. Ultimately, intelligent software assistants should dramatically reduce the time and cognitive effort spent on infrastructure tasks. -

Commonsense Reasoning, Commonsense Knowledge, and the SP Theory of Intelligence J Gerard Wolff
Commonsense reasoning, commonsense knowledge, and the SP Theory of Intelligence J Gerard Wolff To cite this version: J Gerard Wolff. Commonsense reasoning, commonsense knowledge, and the SP Theory of Intelligence. 2019. hal-01970147v3 HAL Id: hal-01970147 https://hal.archives-ouvertes.fr/hal-01970147v3 Preprint submitted on 5 Jun 2019 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. Commonsense reasoning, commonsense knowledge, and the SP Theory of Intelligence J Gerard Wolff∗ June 4, 2019 Abstract Commonsense reasoning (CSR) and commonsense knowledge (CSK) (to- gether abbreviated as CSRK) are areas of study concerned with problems which are trivially easy for adults but which are challenging for artificial systems. This paper describes how the SP System|meaning the SP Theory of Intelligence and its realisation in the SP Computer Model|has strengths and potential in several aspects of CSRK. A particular strength of the SP System is that it shows promise as an overarching theory for four areas of relative success with CSRK problems|described by other -

Forbes.Com - Magazine Article
Forbes.com - Magazine Article http://www.forbes.com/global/1998/1130/0118096a_print.html Artificial intelligence gets real On a recent visit to the doctor, Edward Feigenbaum had the eerie experience of seeing one of his inventions used in a way he never expected: His 25-year-old concept was being used to diagnose a problem with his own breathing. "It's using artificial intelligence," the doctor patiently explained about the spirometer, which measures airflow. "Oh, I see," said Feigenbaum. A professor of computer science and co-scientific director of the Knowledge Systems Laboratory at Stanford University, Feigenbaum is a pioneer of artificial intelligence (AI) -- the science of making machines think like humans. Dozens of applications have their roots in the Stanford lab he started in 1965 and in related software programs that solve complex problems the same way human experts do. Feigenbaum was the first person to realize that human intelligence springs not from rules of logic but from knowledge about particular problems (whether it's chemistry or auto mechanics) and about the world in general. For a computer to think the way a human does, Feigenbaum theorized, it would have to know all of the commonsense things that people take for granted -- that a ball thrown in the air will return to earth, for example; or that a cup holding liquid should be carried right-side up. There are millions of such "rules." Douglas Lenat, a Feigenbaum protg at Stanford, has spent 15 years coding commonsense rules into software. He figures it will take another 25 years for his company, Austin, Texas-based Cycorp, to finish the job.