Integrated Analysis of the Gene Expression Profiling and Copy Number Aberration of the Ovarian Cancer
Total Page:16
File Type:pdf, Size:1020Kb

Load more
Recommended publications
-

Genetic Variation Across the Human Olfactory Receptor Repertoire Alters Odor Perception
bioRxiv preprint doi: https://doi.org/10.1101/212431; this version posted November 1, 2017. The copyright holder for this preprint (which was not certified by peer review) is the author/funder, who has granted bioRxiv a license to display the preprint in perpetuity. It is made available under aCC-BY 4.0 International license. Genetic variation across the human olfactory receptor repertoire alters odor perception Casey Trimmer1,*, Andreas Keller2, Nicolle R. Murphy1, Lindsey L. Snyder1, Jason R. Willer3, Maira Nagai4,5, Nicholas Katsanis3, Leslie B. Vosshall2,6,7, Hiroaki Matsunami4,8, and Joel D. Mainland1,9 1Monell Chemical Senses Center, Philadelphia, Pennsylvania, USA 2Laboratory of Neurogenetics and Behavior, The Rockefeller University, New York, New York, USA 3Center for Human Disease Modeling, Duke University Medical Center, Durham, North Carolina, USA 4Department of Molecular Genetics and Microbiology, Duke University Medical Center, Durham, North Carolina, USA 5Department of Biochemistry, University of Sao Paulo, Sao Paulo, Brazil 6Howard Hughes Medical Institute, New York, New York, USA 7Kavli Neural Systems Institute, New York, New York, USA 8Department of Neurobiology and Duke Institute for Brain Sciences, Duke University Medical Center, Durham, North Carolina, USA 9Department of Neuroscience, University of Pennsylvania School of Medicine, Philadelphia, Pennsylvania, USA *[email protected] ABSTRACT The human olfactory receptor repertoire is characterized by an abundance of genetic variation that affects receptor response, but the perceptual effects of this variation are unclear. To address this issue, we sequenced the OR repertoire in 332 individuals and examined the relationship between genetic variation and 276 olfactory phenotypes, including the perceived intensity and pleasantness of 68 odorants at two concentrations, detection thresholds of three odorants, and general olfactory acuity. -

Produktinformation
Produktinformation Diagnostik & molekulare Diagnostik Laborgeräte & Service Zellkultur & Verbrauchsmaterial Forschungsprodukte & Biochemikalien Weitere Information auf den folgenden Seiten! See the following pages for more information! Lieferung & Zahlungsart Lieferung: frei Haus Bestellung auf Rechnung SZABO-SCANDIC Lieferung: € 10,- HandelsgmbH & Co KG Erstbestellung Vorauskassa Quellenstraße 110, A-1100 Wien T. +43(0)1 489 3961-0 Zuschläge F. +43(0)1 489 3961-7 [email protected] • Mindermengenzuschlag www.szabo-scandic.com • Trockeneiszuschlag • Gefahrgutzuschlag linkedin.com/company/szaboscandic • Expressversand facebook.com/szaboscandic SANTA CRUZ BIOTECHNOLOGY, INC. OR2M5 siRNA (h): sc-88564 BACKGROUND STORAGE AND RESUSPENSION Olfactory receptors are G protein-coupled receptor proteins that localize to the Store lyophilized siRNA duplex at -20° C with desiccant. Stable for at least cilia of olfactory sensory neurons where they display affinity for and bind to one year from the date of shipment. Once resuspended, store at -20° C, a variety of odor molecules. The genes encoding olfactory receptors comprise avoid contact with RNAses and repeated freeze thaw cycles. the largest family in the human genome. The binding of olfactory receptor Resuspend lyophilized siRNA duplex in 330 µl of the RNAse-free water proteins to odor molecules triggers a signal transduction cascade that leads provided. Resuspension of the siRNA duplex in 330 µl of RNAse-free water to the production of cAMP via an olfactory-enriched adenylate cyclase. This makes a 10 µM solution in a 10 µM Tris-HCl, pH 8.0, 20 mM NaCl, 1 mM event ultimately leads to transmission of action potentials to the brain and EDTA buffered solution. the subsequent perception of smell. -

Supplementary Figure S4
18DCIS 18IDC Supplementary FigureS4 22DCIS 22IDC C D B A E (0.77) (0.78) 16DCIS 14DCIS 28DCIS 16IDC 28IDC (0.43) (0.49) 0 ADAMTS12 (p.E1469K) 14IDC ERBB2, LASP1,CDK12( CCNE1 ( NUTM2B SDHC,FCGR2B,PBX1,TPR( CD1D, B4GALT3, BCL9, FLG,NUP21OL,TPM3,TDRD10,RIT1,LMNA,PRCC,NTRK1 0 ADAMTS16 (p.E67K) (0.67) (0.89) (0.54) 0 ARHGEF38 (p.P179Hfs*29) 0 ATG9B (p.P823S) (0.68) (1.0) ARID5B, CCDC6 CCNE1, TSHZ3,CEP89 CREB3L2,TRIM24 BRAF, EGFR (7p11); 0 ABRACL (p.R35H) 0 CATSPER1 (p.P152H) 0 ADAMTS18 (p.Y799C) 19q12 0 CCDC88C (p.X1371_splice) (0) 0 ADRA1A (p.P327L) (10q22.3) 0 CCNF (p.D637N) −4 −2 −4 −2 0 AKAP4 (p.G454A) 0 CDYL (p.Y353Lfs*5) −4 −2 Log2 Ratio Log2 Ratio −4 −2 Log2 Ratio Log2 Ratio 0 2 4 0 2 4 0 ARID2 (p.R1068H) 0 COL27A1 (p.G646E) 0 2 4 0 2 4 2 EDRF1 (p.E521K) 0 ARPP21 (p.P791L) ) 0 DDX11 (p.E78K) 2 GPR101, p.A174V 0 ARPP21 (p.P791T) 0 DMGDH (p.W606C) 5 ANP32B, p.G237S 16IDC (Ploidy:2.01) 16DCIS (Ploidy:2.02) 14IDC (Ploidy:2.01) 14DCIS (Ploidy:2.9) -3 -2 -1 -3 -2 -1 -3 -2 -1 -3 -2 -1 -3 -2 -1 -3 -2 -1 Log Ratio Log Ratio Log Ratio Log Ratio 12DCIS 0 ASPM (p.S222T) Log Ratio Log Ratio 0 FMN2 (p.G941A) 20 1 2 3 2 0 1 2 3 2 ERBB3 (p.D297Y) 2 0 1 2 3 20 1 2 3 0 ATRX (p.L1276I) 20 1 2 3 2 0 1 2 3 0 GALNT18 (p.F92L) 2 MAPK4, p.H147Y 0 GALNTL6 (p.E236K) 5 C11orf1, p.Y53C (10q21.2); 0 ATRX (p.R1401W) PIK3CA, p.H1047R 28IDC (Ploidy:2.0) 28DCIS (Ploidy:2.0) 22IDC (Ploidy:3.7) 22DCIS (Ploidy:4.1) 18IDC (Ploidy:3.9) 18DCIS (Ploidy:2.3) 17q12 0 HCFC1 (p.S2025C) 2 LCMT1 (p.S34A) 0 ATXN7L2 (p.X453_splice) SPEN, p.P677Lfs*13 CBFB 1 2 3 4 5 6 7 8 9 10 11 -

The Genetic Basis of Dupuytren's Disease Gloria Sue Yale School of Medicine, [email protected]
Yale University EliScholar – A Digital Platform for Scholarly Publishing at Yale Yale Medicine Thesis Digital Library School of Medicine January 2014 The Genetic Basis Of Dupuytren's Disease Gloria Sue Yale School of Medicine, [email protected] Follow this and additional works at: http://elischolar.library.yale.edu/ymtdl Recommended Citation Sue, Gloria, "The Genetic Basis Of Dupuytren's Disease" (2014). Yale Medicine Thesis Digital Library. 1926. http://elischolar.library.yale.edu/ymtdl/1926 This Open Access Thesis is brought to you for free and open access by the School of Medicine at EliScholar – A Digital Platform for Scholarly Publishing at Yale. It has been accepted for inclusion in Yale Medicine Thesis Digital Library by an authorized administrator of EliScholar – A Digital Platform for Scholarly Publishing at Yale. For more information, please contact [email protected]. The Genetic Basis of Dupuytren’s Disease A Thesis Submitted to the Yale University School of Medicine In Partial Fulfillment of the Requirements for the Degree of Doctor of Medicine by Gloria R. Sue 2014 THE GENETIC BASIS OF DUPUYTREN’S DISEASE. Gloria R. Sue, Deepak Narayan. Section of Plastic and Reconstructive Surgery, Department of Surgery, Yale University School of Medicine, New Haven, CT. Dupuytren’s disease is a common heritable connective tissue disorder of poorly understood etiology. It is thought that oxidative stress pathways may play a critical role in the development of Dupuytren’s disease, given the various disease associations that have been observed. We sought to sequence the mitochondrial and nuclear genomes of patients affected with Dupuytren’s disease using next-generation sequencing technology to potentially identify genes of potential pathogenetic interest. -

Olfactory Receptors in Non-Chemosensory Organs: the Nervous System in Health and Disease
View metadata, citation and similar papers at core.ac.uk brought to you by CORE provided by Sissa Digital Library REVIEW published: 05 July 2016 doi: 10.3389/fnagi.2016.00163 Olfactory Receptors in Non-Chemosensory Organs: The Nervous System in Health and Disease Isidro Ferrer 1,2,3*, Paula Garcia-Esparcia 1,2,3, Margarita Carmona 1,2,3, Eva Carro 2,4, Eleonora Aronica 5, Gabor G. Kovacs 6, Alice Grison 7 and Stefano Gustincich 7 1 Institute of Neuropathology, Bellvitge University Hospital, Hospitalet de Llobregat, University of Barcelona, Barcelona, Spain, 2 Center for Biomedical Research in Neurodegenerative Diseases (CIBERNED), Madrid, Spain, 3 Bellvitge Biomedical Research Institute (IDIBELL), Hospitalet de Llobregat, Barcelona, Spain, 4 Neuroscience Group, Research Institute Hospital, Madrid, Spain, 5 Department of Neuropathology, Academic Medical Center, University of Amsterdam, Amsterdam, Netherlands, 6 Institute of Neurology, Medical University of Vienna, Vienna, Austria, 7 Scuola Internazionale Superiore di Studi Avanzati (SISSA), Area of Neuroscience, Trieste, Italy Olfactory receptors (ORs) and down-stream functional signaling molecules adenylyl cyclase 3 (AC3), olfactory G protein a subunit (Gaolf), OR transporters receptor transporter proteins 1 and 2 (RTP1 and RTP2), receptor expression enhancing protein 1 (REEP1), and UDP-glucuronosyltransferases (UGTs) are expressed in neurons of the human and murine central nervous system (CNS). In vitro studies have shown that these receptors react to external stimuli and therefore are equipped to be functional. However, ORs are not directly related to the detection of odors. Several molecules delivered from the blood, cerebrospinal fluid, neighboring local neurons and glial cells, distant cells through the extracellular space, and the cells’ own self-regulating internal homeostasis Edited by: Filippo Tempia, can be postulated as possible ligands. -

Identification of Candidate Biomarkers and Pathways Associated with Type 1 Diabetes Mellitus Using Bioinformatics Analysis
bioRxiv preprint doi: https://doi.org/10.1101/2021.06.08.447531; this version posted June 9, 2021. The copyright holder for this preprint (which was not certified by peer review) is the author/funder. All rights reserved. No reuse allowed without permission. Identification of candidate biomarkers and pathways associated with type 1 diabetes mellitus using bioinformatics analysis Basavaraj Vastrad1, Chanabasayya Vastrad*2 1. Department of Biochemistry, Basaveshwar College of Pharmacy, Gadag, Karnataka 582103, India. 2. Biostatistics and Bioinformatics, Chanabasava Nilaya, Bharthinagar, Dharwad 580001, Karnataka, India. * Chanabasayya Vastrad [email protected] Ph: +919480073398 Chanabasava Nilaya, Bharthinagar, Dharwad 580001 , Karanataka, India bioRxiv preprint doi: https://doi.org/10.1101/2021.06.08.447531; this version posted June 9, 2021. The copyright holder for this preprint (which was not certified by peer review) is the author/funder. All rights reserved. No reuse allowed without permission. Abstract Type 1 diabetes mellitus (T1DM) is a metabolic disorder for which the underlying molecular mechanisms remain largely unclear. This investigation aimed to elucidate essential candidate genes and pathways in T1DM by integrated bioinformatics analysis. In this study, differentially expressed genes (DEGs) were analyzed using DESeq2 of R package from GSE162689 of the Gene Expression Omnibus (GEO). Gene ontology (GO) enrichment analysis, REACTOME pathway enrichment analysis, and construction and analysis of protein-protein interaction (PPI) network, modules, miRNA-hub gene regulatory network and TF-hub gene regulatory network, and validation of hub genes were then performed. A total of 952 DEGs (477 up regulated and 475 down regulated genes) were identified in T1DM. GO and REACTOME enrichment result results showed that DEGs mainly enriched in multicellular organism development, detection of stimulus, diseases of signal transduction by growth factor receptors and second messengers, and olfactory signaling pathway. -

WO 2019/068007 Al Figure 2
(12) INTERNATIONAL APPLICATION PUBLISHED UNDER THE PATENT COOPERATION TREATY (PCT) (19) World Intellectual Property Organization I International Bureau (10) International Publication Number (43) International Publication Date WO 2019/068007 Al 04 April 2019 (04.04.2019) W 1P O PCT (51) International Patent Classification: (72) Inventors; and C12N 15/10 (2006.01) C07K 16/28 (2006.01) (71) Applicants: GROSS, Gideon [EVIL]; IE-1-5 Address C12N 5/10 (2006.0 1) C12Q 1/6809 (20 18.0 1) M.P. Korazim, 1292200 Moshav Almagor (IL). GIBSON, C07K 14/705 (2006.01) A61P 35/00 (2006.01) Will [US/US]; c/o ImmPACT-Bio Ltd., 2 Ilian Ramon St., C07K 14/725 (2006.01) P.O. Box 4044, 7403635 Ness Ziona (TL). DAHARY, Dvir [EilL]; c/o ImmPACT-Bio Ltd., 2 Ilian Ramon St., P.O. (21) International Application Number: Box 4044, 7403635 Ness Ziona (IL). BEIMAN, Merav PCT/US2018/053583 [EilL]; c/o ImmPACT-Bio Ltd., 2 Ilian Ramon St., P.O. (22) International Filing Date: Box 4044, 7403635 Ness Ziona (E.). 28 September 2018 (28.09.2018) (74) Agent: MACDOUGALL, Christina, A. et al; Morgan, (25) Filing Language: English Lewis & Bockius LLP, One Market, Spear Tower, SanFran- cisco, CA 94105 (US). (26) Publication Language: English (81) Designated States (unless otherwise indicated, for every (30) Priority Data: kind of national protection available): AE, AG, AL, AM, 62/564,454 28 September 2017 (28.09.2017) US AO, AT, AU, AZ, BA, BB, BG, BH, BN, BR, BW, BY, BZ, 62/649,429 28 March 2018 (28.03.2018) US CA, CH, CL, CN, CO, CR, CU, CZ, DE, DJ, DK, DM, DO, (71) Applicant: IMMP ACT-BIO LTD. -

Sean Raspet – Molecules
1. Commercial name: Fructaplex© IUPAC Name: 2-(3,3-dimethylcyclohexyl)-2,5,5-trimethyl-1,3-dioxane SMILES: CC1(C)CCCC(C1)C2(C)OCC(C)(C)CO2 Molecular weight: 240.39 g/mol Volume (cubic Angstroems): 258.88 Atoms number (non-hydrogen): 17 miLogP: 4.43 Structure: Biological Properties: Predicted Druglikenessi: GPCR ligand -0.23 Ion channel modulator -0.03 Kinase inhibitor -0.6 Nuclear receptor ligand 0.15 Protease inhibitor -0.28 Enzyme inhibitor 0.15 Commercial name: Fructaplex© IUPAC Name: 2-(3,3-dimethylcyclohexyl)-2,5,5-trimethyl-1,3-dioxane SMILES: CC1(C)CCCC(C1)C2(C)OCC(C)(C)CO2 Predicted Olfactory Receptor Activityii: OR2L13 83.715% OR1G1 82.761% OR10J5 80.569% OR2W1 78.180% OR7A2 77.696% 2. Commercial name: Sylvoxime© IUPAC Name: N-[4-(1-ethoxyethenyl)-3,3,5,5tetramethylcyclohexylidene]hydroxylamine SMILES: CCOC(=C)C1C(C)(C)CC(CC1(C)C)=NO Molecular weight: 239.36 Volume (cubic Angstroems): 252.83 Atoms number (non-hydrogen): 17 miLogP: 4.33 Structure: Biological Properties: Predicted Druglikeness: GPCR ligand -0.6 Ion channel modulator -0.41 Kinase inhibitor -0.93 Nuclear receptor ligand -0.17 Protease inhibitor -0.39 Enzyme inhibitor 0.01 Commercial name: Sylvoxime© IUPAC Name: N-[4-(1-ethoxyethenyl)-3,3,5,5tetramethylcyclohexylidene]hydroxylamine SMILES: CCOC(=C)C1C(C)(C)CC(CC1(C)C)=NO Predicted Olfactory Receptor Activity: OR52D1 71.900% OR1G1 70.394% 0R52I2 70.392% OR52I1 70.390% OR2Y1 70.378% 3. Commercial name: Hyperflor© IUPAC Name: 2-benzyl-1,3-dioxan-5-one SMILES: O=C1COC(CC2=CC=CC=C2)OC1 Molecular weight: 192.21 g/mol Volume -
Supplementary Table S1. Genes Printed in the HC5 Microarray Employed in the Screening Phase of the Present Work
Supplementary material Ann Rheum Dis Supplementary Table S1. Genes printed in the HC5 microarray employed in the screening phase of the present work. CloneID Plate Position Well Length GeneSymbol GeneID Accession Description Vector 692672 HsxXG013989 2 B01 STK32A 202374 null serine/threonine kinase 32A pANT7_cGST 692675 HsxXG013989 3 C01 RPS10-NUDT3 100529239 null RPS10-NUDT3 readthrough pANT7_cGST 692678 HsxXG013989 4 D01 SPATA6L 55064 null spermatogenesis associated 6-like pANT7_cGST 692679 HsxXG013989 5 E01 ATP1A4 480 null ATPase, Na+/K+ transporting, alpha 4 polypeptide pANT7_cGST 692689 HsxXG013989 6 F01 ZNF816-ZNF321P 100529240 null ZNF816-ZNF321P readthrough pANT7_cGST 692691 HsxXG013989 7 G01 NKAIN1 79570 null Na+/K+ transporting ATPase interacting 1 pANT7_cGST 693155 HsxXG013989 8 H01 TNFSF12-TNFSF13 407977 NM_172089 TNFSF12-TNFSF13 readthrough pANT7_cGST 693161 HsxXG013989 9 A02 RAB12 201475 NM_001025300 RAB12, member RAS oncogene family pANT7_cGST 693169 HsxXG013989 10 B02 SYN1 6853 NM_133499 synapsin I pANT7_cGST 693176 HsxXG013989 11 C02 GJD3 125111 NM_152219 gap junction protein, delta 3, 31.9kDa pANT7_cGST 693181 HsxXG013989 12 D02 CHCHD10 400916 null coiled-coil-helix-coiled-coil-helix domain containing 10 pANT7_cGST 693184 HsxXG013989 13 E02 IDNK 414328 null idnK, gluconokinase homolog (E. coli) pANT7_cGST 693187 HsxXG013989 14 F02 LYPD6B 130576 null LY6/PLAUR domain containing 6B pANT7_cGST 693189 HsxXG013989 15 G02 C8orf86 389649 null chromosome 8 open reading frame 86 pANT7_cGST 693194 HsxXG013989 16 H02 CENPQ 55166 -

Chromophobe Renal Cell Carcinoma with and Without Sarcomatoid Change: a Clinicopathological, Comparative Genomic Hybridization, and Whole-Exome Sequencing Study
Am J Transl Res 2015;7(11):2482-2499 www.ajtr.org /ISSN:1943-8141/AJTR0014993 Original Article Chromophobe renal cell carcinoma with and without sarcomatoid change: a clinicopathological, comparative genomic hybridization, and whole-exome sequencing study Yuan Ren1*, Kunpeng Liu1*, Xueling Kang3, Lijuan Pang1, Yan Qi1, Zhenyan Hu1, Wei Jia1, Haijun Zhang1, Li Li1, Jianming Hu1, Weihua Liang1, Jin Zhao1, Hong Zou1*, Xianglin Yuan2, Feng Li1* 1Department of Pathology, School of Medicine, First Affiliated Hospital, Shihezi University, Key Laboratory of Xinjiang Endemic and Ethnic Diseases, Ministry of Education of China, Shihezi, China; 2Tongji Hospital Cancer Center, Tongji Medical College, Huazhong University of Science and Technology, Wuhan, China; 3Department of Pathology, Shanghai General Hospital, Shanghai, China. *Equal contributors. Received August 24, 2015; Accepted October 13, 2015; Epub November 15, 2015; Published November 30, 2015 Abstract: Chromophobe renal cell carcinomas (CRCC) with and without sarcomatoid change have different out- comes; however, fewstudies have compared their genetic profiles. Therefore, we identified the genomic alteration- sin CRCC common type (CRCC C) (n=8) and CRCC with sarcomatoid change (CRCC S) (n=4) using comparative genomic hybridization (CGH) and whole-exome sequencing. The CGH profiles showed that the CRCC C group had more chromosomal losses (72 vs. 18) but fewer chromosomal gains (23 vs. 57) than the CRCC S group. Losses of chromosomes 1p, 8p21-23, 10p16-20, 10p12-ter, 13p20-30, and 17p13 and gains of chromosomes 1q11, 1q21-23, 1p13-15, 2p23-24, and 3p21-ter differed between the groups. Whole-exome sequencing showed that the mutational status of 270 genes differed between CRCC (n=12) and normal renal tissues (n=18). -
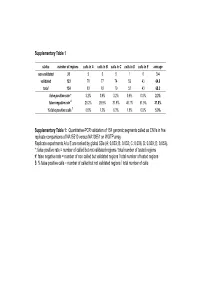
Quantitative-PCR Validation of 154 Genomic Segments Called As Cnvs in Five Replicat
Supplementary Table 1 status number of regions calls in A calls in B calls in C calls in D calls in E average non validated 31 5 6 5 1 0 3.4 validated 123 78 77 74 52 43 64.8 total 154 83 83 79 53 43 68.2 false positive rate * 3.2% 3.9% 3.2% 0.6% 0.0% 2.2% false negative rate # 29.2% 29.9% 31.8% 46.1% 51.9% 37.8% % false positive calls $ 6.0% 7.2% 6.3% 1.9% 0.0% 5.0% Supplementary Table 1: Quantitative-PCR validation of 154 genomic segments called as CNVs in five replicate comparisons of NA15510 versus NA10851 on WGTP array Replicate experiments A to E are ranked by global SDe (A: 0.033; B: 0.033; C: 0.036; D: 0.039; E: 0.053). *: false positive rate = number of called but not validated regions / total number of tested regions #: false negative rate = number of non called but validated regions / total number of tested regions $: % false positive calls = number of called but not validated regions / total number of calls False positive estimates for 500K EA CNV calls Total Rep1 Rep2 Rep3 Avg (unique) Validated 33 28 32 31 38 Not validated 2 2 2 2 5 Total 35 30 34 33 43 % False positive 5.71% 6.67% 5.88% 6.09% - % False negative 13.16% 26.32% 15.79% 18.42% - Supplementary Table 2A : Quantitative PCR validation of 43 unique CNV regions called as CNVs in three replicate comparisons of NA15510 versus NA10851 using the 500K EA array. -

Clinical, Molecular, and Immune Analysis of Dabrafenib-Trametinib
Supplementary Online Content Chen G, McQuade JL, Panka DJ, et al. Clinical, molecular and immune analysis of dabrafenib-trametinib combination treatment for metastatic melanoma that progressed during BRAF inhibitor monotherapy: a phase 2 clinical trial. JAMA Oncology. Published online April 28, 2016. doi:10.1001/jamaoncol.2016.0509. eMethods. eReferences. eTable 1. Clinical efficacy eTable 2. Adverse events eTable 3. Correlation of baseline patient characteristics with treatment outcomes eTable 4. Patient responses and baseline IHC results eFigure 1. Kaplan-Meier analysis of overall survival eFigure 2. Correlation between IHC and RNAseq results eFigure 3. pPRAS40 expression and PFS eFigure 4. Baseline and treatment-induced changes in immune infiltrates eFigure 5. PD-L1 expression eTable 5. Nonsynonymous mutations detected by WES in baseline tumors This supplementary material has been provided by the authors to give readers additional information about their work. © 2016 American Medical Association. All rights reserved. Downloaded From: https://jamanetwork.com/ on 09/30/2021 eMethods Whole exome sequencing Whole exome capture libraries for both tumor and normal samples were constructed using 100ng genomic DNA input and following the protocol as described by Fisher et al.,3 with the following adapter modification: Illumina paired end adapters were replaced with palindromic forked adapters with unique 8 base index sequences embedded within the adapter. In-solution hybrid selection was performed using the Illumina Rapid Capture Exome enrichment kit with 38Mb target territory (29Mb baited). The targeted region includes 98.3% of the intervals in the Refseq exome database. Dual-indexed libraries were pooled into groups of up to 96 samples prior to hybridization.