“Why Is Europe More Equal Than the United States?”, World
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
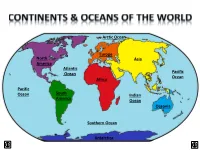
North America Other Continents
Arctic Ocean Europe North Asia America Atlantic Ocean Pacific Ocean Africa Pacific Ocean South Indian America Ocean Oceania Southern Ocean Antarctica LAND & WATER • The surface of the Earth is covered by approximately 71% water and 29% land. • It contains 7 continents and 5 oceans. Land Water EARTH’S HEMISPHERES • The planet Earth can be divided into four different sections or hemispheres. The Equator is an imaginary horizontal line (latitude) that divides the earth into the Northern and Southern hemispheres, while the Prime Meridian is the imaginary vertical line (longitude) that divides the earth into the Eastern and Western hemispheres. • North America, Earth’s 3rd largest continent, includes 23 countries. It contains Bermuda, Canada, Mexico, the United States of America, all Caribbean and Central America countries, as well as Greenland, which is the world’s largest island. North West East LOCATION South • The continent of North America is located in both the Northern and Western hemispheres. It is surrounded by the Arctic Ocean in the north, by the Atlantic Ocean in the east, and by the Pacific Ocean in the west. • It measures 24,256,000 sq. km and takes up a little more than 16% of the land on Earth. North America 16% Other Continents 84% • North America has an approximate population of almost 529 million people, which is about 8% of the World’s total population. 92% 8% North America Other Continents • The Atlantic Ocean is the second largest of Earth’s Oceans. It covers about 15% of the Earth’s total surface area and approximately 21% of its water surface area. -

Fresh- and Brackish-Water Cold-Tolerant Species of Southern Europe: Migrants from the Paratethys That Colonized the Arctic
water Review Fresh- and Brackish-Water Cold-Tolerant Species of Southern Europe: Migrants from the Paratethys That Colonized the Arctic Valentina S. Artamonova 1, Ivan N. Bolotov 2,3,4, Maxim V. Vinarski 4 and Alexander A. Makhrov 1,4,* 1 A. N. Severtzov Institute of Ecology and Evolution, Russian Academy of Sciences, 119071 Moscow, Russia; [email protected] 2 Laboratory of Molecular Ecology and Phylogenetics, Northern Arctic Federal University, 163002 Arkhangelsk, Russia; [email protected] 3 Federal Center for Integrated Arctic Research, Russian Academy of Sciences, 163000 Arkhangelsk, Russia 4 Laboratory of Macroecology & Biogeography of Invertebrates, Saint Petersburg State University, 199034 Saint Petersburg, Russia; [email protected] * Correspondence: [email protected] Abstract: Analysis of zoogeographic, paleogeographic, and molecular data has shown that the ancestors of many fresh- and brackish-water cold-tolerant hydrobionts of the Mediterranean region and the Danube River basin likely originated in East Asia or Central Asia. The fish genera Gasterosteus, Hucho, Oxynoemacheilus, Salmo, and Schizothorax are examples of these groups among vertebrates, and the genera Magnibursatus (Trematoda), Margaritifera, Potomida, Microcondylaea, Leguminaia, Unio (Mollusca), and Phagocata (Planaria), among invertebrates. There is reason to believe that their ancestors spread to Europe through the Paratethys (or the proto-Paratethys basin that preceded it), where intense speciation took place and new genera of aquatic organisms arose. Some of the forms that originated in the Paratethys colonized the Mediterranean, and overwhelming data indicate that Citation: Artamonova, V.S.; Bolotov, representatives of the genera Salmo, Caspiomyzon, and Ecrobia migrated during the Miocene from I.N.; Vinarski, M.V.; Makhrov, A.A. -

1 Executive Summary Mauritius Is an Upper Middle-Income Island Nation
Executive Summary Mauritius is an upper middle-income island nation of 1.2 million people and one of the most competitive, stable, and successful economies in Africa, with a Gross Domestic Product (GDP) of USD 11.9 billion and per capita GDP of over USD 9,000. Mauritius’ small land area of only 2,040 square kilometers understates its importance to the Indian Ocean region as it controls an Exclusive Economic Zone of more than 2 million square kilometers, one of the largest in the world. Emerging from the British colonial period in 1968 with a monoculture economy based on sugar production, Mauritius has since successfully diversified its economy into manufacturing and services, with a vibrant export sector focused on textiles, apparel, and jewelry as well as a growing, modern, and well-regulated offshore financial sector. Recently, the government of Mauritius has focused its attention on opportunities in three areas: serving as a platform for investment into Africa, moving the country towards renewable sources of energy, and developing economic activity related to the country’s vast oceanic resources. Mauritius actively seeks investment and seeks to service investment in the region, having signed more than forty Double Taxation Avoidance Agreements and maintaining a legal and regulatory framework that keeps Mauritius highly-ranked on “ease of doing business” and good governance indices. 1. Openness To, and Restrictions Upon, Foreign Investment Attitude Toward FDI Mauritius actively seeks and prides itself on being open to foreign investment. According to the World Bank report “Investing Across Borders,” Mauritius has one of the world’s most open economies to foreign ownership and is one of the highest recipients of FDI per capita. -

Countries and Continents of the World: a Visual Model
Countries and Continents of the World http://geology.com/world/world-map-clickable.gif By STF Members at The Crossroads School Africa Second largest continent on earth (30,065,000 Sq. Km) Most countries of any other continent Home to The Sahara, the largest desert in the world and The Nile, the longest river in the world The Sahara: covers 4,619,260 km2 The Nile: 6695 kilometers long There are over 1000 languages spoken in Africa http://www.ecdc-cari.org/countries/Africa_Map.gif North America Third largest continent on earth (24,256,000 Sq. Km) Composed of 23 countries Most North Americans speak French, Spanish, and English Only continent that has every kind of climate http://www.freeusandworldmaps.com/html/WorldRegions/WorldRegions.html Asia Largest continent in size and population (44,579,000 Sq. Km) Contains 47 countries Contains the world’s largest country, Russia, and the most populous country, China The Great Wall of China is the only man made structure that can be seen from space Home to Mt. Everest (on the border of Tibet and Nepal), the highest point on earth Mt. Everest is 29,028 ft. (8,848 m) tall http://craigwsmall.wordpress.com/2008/11/10/asia/ Europe Second smallest continent in the world (9,938,000 Sq. Km) Home to the smallest country (Vatican City State) There are no deserts in Europe Contains mineral resources: coal, petroleum, natural gas, copper, lead, and tin http://www.knowledgerush.com/wiki_image/b/bf/Europe-large.png Oceania/Australia Smallest continent on earth (7,687,000 Sq. -

Past and Current Trends of Balkan Migrations
ESPACE, POPULATIONS, SOCIETES, 2004-3 pp. 519-531 Corrado BONIFAZI Istituto di Ricerche sulla Popolazione e le Politiche Marija MAMOLO Sociali IRPPS via Nizza, 128 Roma Italie [email protected] Past and Current Trends of Balkan Migrations INTRODUCTION There is hardly another region of the world aspects of the Balkans [Prévélakis, 1994], where the current situation of migrations is affecting their specific nature also with still considerably influenced by the past his- regard to migration. However, the migration tory as in the Balkans. Migrations have been outlook of the Balkans does not just involve a fundamental element in the history of the these flows, which in some respects tend to Balkans, accompanying its stormy events reflect the movements de l’histoire de [Her√ak and Mesi´c, 1990] and obviously longue durée, but it is rather much more continuing to do so, even at the start of the structured and complex. Focusing for the new millennium. For centuries, invasions, moment on the most recent period, together wars, military defeats and victories have with the forced migrations caused by the been a more or less direct cause of popula- ethnic conflicts in the former Yugoslavia tion movements, in a continuous and still and the ethnic migrations followed by the ongoing transformation of the distribution collapse of the regimes created by “real and the overlapping of religions, languages, socialism”, we find both forms of labour ethnic groups and cultures [Sardon, 2001]. migration and transit migration. Therefore, Since the arrival of the Slav populations in the Balkans are also characterised by many the 7th century, the Ottoman expansion, the of the typical elements of the current forms extension of the Hapsburg domain, the rise of mobility in Eastern and Central Europe and growth of national states, the two World [Okólski, 1998; Bonifazi, 2003]. -

Geography Notes.Pdf
THE GLOBE What is a globe? a small model of the Earth Parts of a globe: equator - the line on the globe halfway between the North Pole and the South Pole poles - the northern-most and southern-most points on the Earth 1. North Pole 2. South Pole hemispheres - half of the earth, divided by the equator (North & South) and the prime meridian (East and West) 1. Northern Hemisphere 2. Southern Hemisphere 3. Eastern Hemisphere 4. Western Hemisphere continents - the largest land areas on Earth 1. North America 2. South America 3. Europe 4. Asia 5. Africa 6. Australia 7. Antarctica oceans - the largest water areas on Earth 1. Atlantic Ocean 2. Pacific Ocean 3. Indian Ocean 4. Arctic Ocean 5. Antarctic Ocean WORLD MAP ** NOTE: Our textbooks call the “Southern Ocean” the “Antarctic Ocean” ** North America The three major countries of North America are: 1. Canada 2. United States 3. Mexico Where Do We Live? We live in the Western & Northern Hemispheres. We live on the continent of North America. The other 2 large countries on this continent are Canada and Mexico. The name of our country is the United States. There are 50 states in it, but when it first became a country, there were only 13 states. The name of our state is New York. Its capital city is Albany. GEOGRAPHY STUDY GUIDE You will need to know: VOCABULARY: equator globe hemisphere continent ocean compass WORLD MAP - be able to label 7 continents and 5 oceans 3 Large Countries of North America 1. United States 2. Canada 3. -

Gender, the Status of Women, and Family Structure in Malaysia
Malaysian Journal of EconomicGender, Studies the Status 53(1): of Women,33 - 50, 2016 and Family Structure in Malaysia ISSN 1511-4554 Gender, the Status of Women, and Family Structure in Malaysia Charles Hirschman* University of Washington, Seattle Abstract: This paper addresses the question of whether the relatively high status of women in pre-colonial South-east Asia is still evident among Malay women in twentieth century Peninsular Malaysia. Compared to patterns in East and South Asia, Malay family structure does not follow the typical patriarchal patterns of patrilineal descent, patrilocal residence of newly married couples, and preference for male children. Empirical research, including ethnographic studies of gender roles in rural villages and demographic surveys, shows that women were often economically active in agricultural production and trade, and that men occasionally participated in domestic roles. These findings do not mean a complete absence of patriarchy, but there is evidence of continuity of some aspects of the historical pattern of relative gender equality. The future of gender equality in Malaysia may depend as much on understanding its past as well as drawing lessons from abroad. Keywords: Family, gender, marriage, patriarchy, women JEL classification: I3, J12, J16, N35 1. Introduction In the introduction to her book onWomen, Politics, and Change, Lenore Manderson (1980) said that the inspiration for her study was the comment by a British journalist that the participation of Malay women in rallies, demonstrations, and the nationalist movement during the late 1940s was the most remarkable feature of post-World War II Malayan politics. The British journalist described the role of Malay women in the nationalist movement as “challenging, dominant, and vehement in their emergence from meek, quiet roles in the kampongs, rice fields, the kitchens, and nurseries” (Miller, 1982, p. -

ICS South Africa
Integrated Country Strategy South Africa FOR PUBLIC RELEASE FOR PUBLIC RELEASE Table of Contents 1. Chief of Mission Priorities ................................................................................................................ 2 2. Mission Strategic Framework .......................................................................................................... 4 3. Mission Goals and Objectives .......................................................................................................... 6 4. Management Objectives ................................................................................................................ 12 FOR PUBLIC RELEASE Approved: August 22, 2018 1 FOR PUBLIC RELEASE 1. Chief of Mission Priorities There are tremendous opportunities to broaden U.S. engagement in South Africa which stand to benefit both countries. Over 600 U.S. companies already operate in South Africa, some for over 100 years; furthermore, many of them use South Africa as a platform for operations and a springboard for expansion into the rest of Africa. South Africa is therefore the single most critical market hub to a population expecting to double to two billion people in the next 30 years. While some resentment of the United States continues from the apartheid era, there is also recognition of American activism that helped end apartheid. In polls, the United States is seen very favorably by every day South Africans, who respond positively to American politics, culture, and goods. South Africa’s economy is the most -

Popular Sweeteners and Their Health Effects Based Upon Valid Scientific Data
Popular Sweeteners and Their Health Effects Interactive Qualifying Project Report Submitted to the Faculty of the WORCESTER POLYTECHNIC INSTITUTE in partial fulfillment of the requirements for the Degree of Bachelor of Science By __________________________________ Ivan Lebedev __________________________________ Jayyoung Park __________________________________ Ross Yaylaian Date: Approved: __________________________________ Professor Satya Shivkumar Abstract Perceived health risks of artificial sweeteners are a controversial topic often supported solely by anecdotal evidence and distorted media hype. The aim of this study was to examine popular sweeteners and their health effects based upon valid scientific data. Information was gathered through a sweetener taste panel, interviews with doctors, and an on-line survey. The survey revealed the public’s lack of appreciation for sweeteners. It was observed that artificial sweeteners can serve as a low-risk alternative to natural sweeteners. I Table of Contents Abstract .............................................................................................................................................. I Table of Contents ............................................................................................................................... II List of Figures ................................................................................................................................... IV List of Tables ................................................................................................................................... -

Sweeteners Georgia Jones, Extension Food Specialist
® ® KFSBOPFQVLCB?O>PH>¨ FK@LIKUQBKPFLK KPQFQRQBLCDOF@RIQROB>KA>QRO>IBPLRO@BP KLTELT KLTKLT G1458 (Revised May 2010) Sweeteners Georgia Jones, Extension Food Specialist Consumers have a choice of sweeteners, and this NebGuide helps them make the right choice. Sweeteners of one kind or another have been found in human diets since prehistoric times and are types of carbohy- drates. The role they play in the diet is constantly debated. Consumers satisfy their “sweet tooth” with a variety of sweeteners and use them in foods for several reasons other than sweetness. For example, sugar is used as a preservative in jams and jellies, it provides body and texture in ice cream and baked goods, and it aids in fermentation in breads and pickles. Sweeteners can be nutritive or non-nutritive. Nutritive sweeteners are those that provide calories or energy — about Sweeteners can be used not only in beverages like coffee, but in baking and as an ingredient in dry foods. four calories per gram or about 17 calories per tablespoon — even though they lack other nutrients essential for growth and health maintenance. Nutritive sweeteners include sucrose, high repair body tissue. When a diet lacks carbohydrates, protein fructose corn syrup, corn syrup, honey, fructose, molasses, and is used for energy. sugar alcohols such as sorbitol and xytilo. Non-nutritive sweet- Carbohydrates are found in almost all plant foods and one eners do not provide calories and are sometimes referred to as animal source — milk. The simpler forms of carbohydrates artificial sweeteners, and non-nutritive in this publication. are called sugars, and the more complex forms are either In fact, sweeteners may have a variety of terms — sugar- starches or dietary fibers.Table I illustrates the classification free, sugar alcohols, sucrose, corn sweeteners, etc. -

Changing Political Cleavages in 21 Western Democracies, 1948-2020 Amory Gethin, Clara Martínez-Toledano, Thomas Piketty
Brahmin Left versus Merchant Right: Changing Political Cleavages in 21 Western Democracies, 1948-2020 Amory Gethin, Clara Martínez-Toledano, Thomas Piketty To cite this version: Amory Gethin, Clara Martínez-Toledano, Thomas Piketty. Brahmin Left versus Merchant Right: Changing Political Cleavages in 21 Western Democracies, 1948-2020. 2021. halshs-03226118 HAL Id: halshs-03226118 https://halshs.archives-ouvertes.fr/halshs-03226118 Preprint submitted on 14 May 2021 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. World Inequality Lab – Working Paper N° 2021/15 Brahmin Left versus Merchant Right: Changing Political Cleavages in 21 Western Democracies, 1948-2020 Amory Gethin Clara Martínez-Toledano Thomas Piketty May 2021 Brahmin Left versus Merchant Right: Changing Political Cleavages in 21 Western Democracies, 1948-2020 Amory Gethin Clara Martínez-Toledano Thomas Piketty May 5, 2021 Abstract This paper provides new evidence on the long-run evolution of political cleavages in 21 Western democracies by exploiting a new database on the vote by socioeconomic characteristic covering over 300 elections held between 1948 and 2020. In the 1950s-1960s, the vote for democratic, labor, social democratic, socialist, and affiliated parties was associated with lower-educated and low-income voters. -

Global Income Inequality, 1820-2020: the Persistence and Mutation of Extreme Inequality Lucas Chancel, Thomas Piketty
Global Income Inequality, 1820-2020: The Persistence and Mutation of Extreme Inequality Lucas Chancel, Thomas Piketty To cite this version: Lucas Chancel, Thomas Piketty. Global Income Inequality, 1820-2020: The Persistence and Mutation of Extreme Inequality. 2021. halshs-03321887 HAL Id: halshs-03321887 https://halshs.archives-ouvertes.fr/halshs-03321887 Preprint submitted on 18 Aug 2021 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. World Inequality Lab – Working Paper N° 2021/19 Global Income Inequality, 1820-2020: The Persistence and Mutation of Extreme Inequality Lucas Chancel Thomas Piketty This version: July 2021 World Inequality Lab 1 Global Income Inequality, 1820-2020: The Persistence and Mutation of Extreme Inequality Lucas Chancel1,2, Thomas Piketty1,3 This version: July 2021 Abstract. In this paper, we mobilize newly available historical series from the World Inequality Database to construct world income distribution estimates from 1820 to 2020. We find that the level of global income inequality has always been very large, reflecting the persistence of a highly hierarchical world economic system. Global inequality increased between 1820 and 1910, in the context of the rise of Western dominance and colonial empires, and then stabilized at a very high level between 1910 and 2020.