Automating Question Generation Given the Correct Answer
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Mongol Invasions of Northeast Asia Korea and Japan
Eurasian Maritime History Case Study: Northeast Asia Thirteenth Century Mongol Invasions of Northeast Asia Korea and Japan Dr. Grant Rhode Boston University Mongol Invasions of Northeast Asia: Korea and Japan | 2 Maritime History Case Study: Northeast Asia Thirteenth Century Mongol Invasions of Northeast Asia Korea and Japan Contents Front piece: The Defeat of the Mongol Invasion Fleet Kamikaze, the ‘Divine Wind’ The Mongol Continental Vision Turns Maritime Mongol Naval Successes Against the Southern Song Korea’s Historic Place in Asian Geopolitics Ancient Pattern: The Korean Three Kingdoms Period Mongol Subjugation of Korea Mongol Invasions of Japan First Mongol Invasion of Japan, 1274 Second Mongol Invasion of Japan, 1281 Mongol Support for Maritime Commerce Reflections on the Mongol Maritime Experience Maritime Strategic and Tactical Lessons Limits on Mongol Expansion at Sea Text and Visual Source Evidence Texts T 1: Marco Polo on Kublai’s Decision to Invade Japan with Storm Description T 2: Japanese Traditional Song: The Mongol Invasion of Japan Visual Sources VS 1: Mongol Scroll: 1274 Invasion Battle Scene VS 2: Mongol bomb shells: earliest examples of explosive weapons from an archaeological site Selected Reading for Further Study Notes Maps Map 1: The Mongol Empire by 1279 Showing Attempted Mongol Conquests by Sea Map 2: Three Kingdoms Korea, Battle of Baekgang, 663 Map 3: Mongol Invasions of Japan, 1274 and 1281 Map 4: Hakata Bay Battles 1274 and 1281 Map 5: Takashima Bay Battle 1281 Mongol Invasions of Northeast Asia: Korea and -

VETO 2012, FARSIDE Team Tossups 1 of 6
VETO 2012, FARSIDE team tossups 1 of 6 VETO 2012, FARSIDE team tossups TOSSUP 1 It was a disappointing year for followers of self-proclaimed Jewish messiah Sabbatai Zevi, who was imprisoned in Constantinople and converted to Islam. In this same year, the Old Believers split from the Russian Orthodox Church because of the official adoption of Patriarch Nikon's reforms. More promisingly, Louis the Fourteenth founded the French Academy of Sciences, and Isaac Newton discovered differential and integral calculus and gravitation in this year that John Dryden called an Annus Mirabilis, though it was not so mirabilis in England's capital. For 10 points, what was this year of the great fire of London? Answer: the year 1666 TOSSUP 2 Free Proxy Server concealed the IP address that his associate named Jones used to make a PayPal purchase with RackNine, which he later called with his prepaid Virgin Mobile cell phone with area code 450, which is in Joliette, Quebec, though he bought his phone in Ontario on April 30, 2011. On the morning of May 2, he said that the Quebec Street Mall was the new polling location, in calls to over seven thousand voters in Guelph. A resident of the nonexistent "Separatist Street", for 10 points, who was this election-day robocaller? Answer: Pierre Poutine (prompt on "Poutine") TOSSUP 3 The fastest known algorithm for this operation, published in 2011 by Vassilevska Williams, takes time proportional to the order of the inputs raised to the power of two point three seven two seven, and is an extension of a divide-and-conquer method by Strassen, where the trick is to take one fewer scalar product at the cost of extra scalar sums in the base case of order two. -

2018 MS NHBB Nationals Bee Playoff Round 3
2018 NHBB Middle School National Bee 2017-2018 Playoff Round 3 Playoff Round 3 Regulation Tossups (1) This man rejected advice from Lew Walt to seek victory through placating civilians. This man insisted on using body counts at La Drang to show that he had been victorious. This man's forces were attacked at Khe Sanh just prior to a major New Year's attack. Though he repeatedly claimed victory was near, this man was replaced. For the point, the Tet Offensive led to the removal of what American general? ANSWER: William Westmoreland (2) This man and Arnold Harberger were invited to give speeches after a 1975 coup. This man listed inflation and the promotion of a healthy social market economy as the \key economic problems" of a country ruled by Augusto Pinochet. This economist advised Chile while working at the university where he wrote Capitalism and Freedom. For the point, name this economist associated with the University of Chicago. ANSWER: Milton Friedman (3) This province was home to a city where the 1279 Battle of Yamen took place. Hong Xiuquan, who led the Taiping Rebellion, was born in this province. While in this province, Lin Zexu wrote a letter to Queen Victoria calling for the end of a particular trade. During the First Opium War, the British captured this province's port of Canton. For the point, name this state of southern China containing the city of Guangzhou. ANSWER: Guangdong (4) This program was unveiled at an Ohio University speech where the speaker promised \no child will go unfed and no youngster will go unschooled." This program succeeded the New Frontier initiative. -

China Under Mongol Rule: the Yuan Dynasty
CHINA UNDER MONGOL RULE: THE YUAN DYNASTY The Yuan Dynasty, or Great Yuan Empire (Mongolian: Dai On Ulus; Mandarin: Dà Yuán Dìguó) was a ruling dynasty founded by the Mongol leader Kublai Khan, who ruled most of present‐day China, all of modern Mongolia and its surrounding areas, lasting officially from 1271 to 1368. It is considered both as a division of the Mongol Empire and as an imperial dynasty of China. Although the dynasty was established by Kublai Khan, he had his grandfather Genghis Khan placed on the official record as the founder of the dynasty, known as the Taizu. Besides Emperor of China, Kublai Khan also claimed the title of Great Khan and therefore supremacy over the other Mongol khanates spread over Eurasia ‐ the Chagatai Khanate of Turkestan, the Golden Horde of present day Russia and the Ilkhanate in Persia. Thus the Yuan Dynasty is sometimes referred to as the Empire of the Great Khan, as the Mongol Emperors of the Yuan held the title of Great Khan of all Mongol Khanates. MONGOLIAN ORIGINS In 1259, the Great Khan Mongke died while Kublai Khan, his brother, was campaigning against the Song Dynasty in South China. Meanwhile his other brother Ariq Boke commanded the Mongol homelands. After Mongke's demise, Ariq Boke decided to attempt to make himself Great Khan. Hearing of this, Kublai aborted his Chinese expedition and had himself elected as Great Khan in an assembly with a small number of attendees in April of 1260. Still, Ariq Boke had his supporters and was elected as a rival Great Khan to Kublai at Karakorum, then the capital of Mongol Empire. -

Nationalism, Feminism, and Martial Valor: Rewriting Biographies of Women in Nüzi Shijie (1904-1907)
Nationalism, Feminism, and Martial Valor: Rewriting Biographies of Women in Nüzi shijie (1904-1907) Eavan Cully Department of East Asian Studies McGill University, Montreal November 2008 A thesis submitted to McGill University in partial fulfillment of the requirements of the degree of Master of Arts. © Eavan Cully 2008. 1 Acknowledgements This thesis could not have been completed without the encouragement and helpful criticism of a number of people. I would like to thank my colleagues at McGill University, including Rongdao Lai, Afra Tucker, Ana Selles, Fiona Lau, Lin Fan and Chris Byrne for their constant encouragement and support. I especially would like to thank Fiona Lau and Afra Tucker: Fiona for her considerable help in translating these biographies and Afra for translating my abstract into French. Special thanks are owed to my advisor, Professor Grace Fong, for her useful suggestions and critiques over the numerous drafts of this thesis that she has been generous enough to read. Finally, however small an impact this thesis might have on the larger scholarship of late Qing feminisms, it has taken over a good part of my life for the past two years, and by unfortunate extension, it has also claimed much of the time and attention of my partner, Gregory Scott. To him I owe untold thanks for his incredible patience, endless cheer, and insightful criticisms. Although separated by uncompromising geography, he has been at my side for every step of this project. Although this thesis has benefited from the comments of many, I remain solely responsible for any lasting errors or inconsistencies. -
Playoff Round 3
USABB Regional Bowl 2016-2017 Playoff Round 3 Playoff Round 3 First Half (1) This man was unofficially advised by the Kitchen Cabinet, in contrast with an official cabinet that included John Eaton. This man tried to beat Richard Lawrence with a cane after Lawrence tried to shoot him. This man may have said (*) \John Marshall has made his decision; now let him enforce it!" before ordering the Trail of Tears. For ten points, name this 7th President of the United States, nicknamed Old Hickory. ANSWER: Andrew Jackson (1) Give the following about the Pragmatic Sanction of 1713, for ten points each. The Pragmatic Sanction was issued by Charles VI, a member of this royal family, to ensure that his land stayed within this family after his death. ANSWER: House of Habsburg (or Hapsburg; accept Habsburg family, etc.; prompt on House of Austria) Charles VI issued the Pragmatic Sanction as the ruler of this central European empire, whose leader was an elected position. ANSWER: Holy Roman Empire (prompt on HRE) The Pragmatic Sanction tried to guarantee that this daughter of his would calmly take over his land. She succeeded him, but it wasn't calm; this ruler was targeted in the War of the Austrian Succession. ANSWER: Maria Theresa (prompt on partial answer) (2) In a performance of this work for children, Leonard Bernstein skipped the fifth movement, noting that \old age" wouldn't be worth visiting. This piece's seven movements include others subtitled \the Mystic" and \the (*) Bringer of War," but this piece does not include a movement representing Earth. -

Bowl Round 9 Bowl Round 9 First Quarter
NHBB A-Set Bowl 2017-2018 Bowl Round 9 Bowl Round 9 First Quarter (1) In an effort to encourage dental health, this leader encouraged his population to chew on bones because dogs do so. This leader renamed the month of September after his book Ruhnama, whose study is required to obtain a driver's license in his country. This leader commissioned the construction of an Arch of Neutrality, which contained a golden statue of himself that rotated to face the sun in the city of Ashgabat. For ten points, name this totalitarian ruler of post-independence Turkmenistan from 1991 to his death in 2006. ANSWER: Saparmurat Niyazov (or Turkmenbashi) (2) Allison Janney earned an Oscar nomination for playing this woman's mother, the abusive LaVona Fay Golden. This woman followed Midori Ito to become the second woman to ever land a triple axel, but became infamous when her ex-husband, Jeff Gillooly, conspired to attack her rival before the 1994 Winter Olympics. A 2017 film by Craig Gillespie stars Margot Robbie as, for ten points, what American figure skater and rival of Nancy Kerrigan? ANSWER: Tonya Harding (accept Tonya Maxene Price) (3) The fourth and final section of a book by this man incorrectly tries to explain the origins of Earth's tides. This man supported one of his arguments by citing the phases of Venus and apparent motion of sunspots. This man introduced the idea of inertial reference frames with a thought experiment about a man below deck on a ship, and wrote a book consisting of conversations between the laymen Sagredo, Simplicio, and Salviati. -

Bowl Round 2 – MIDDLE SCHOOL First Quarter (1) This Country Has Been Historically Led by Members of the House of Al Thani
IHBB Asia Alpha Set Bowl 2018-2019 Bowl Round 2 Bowl Round 2 – MIDDLE SCHOOL First Quarter (1) This country has been historically led by members of the House of Al Thani. After the closure of BBC’s Arabic language television services, an emir in this country made a loan to found the moderate news channel Al-Jazeera. Set to host the 2022 World Cup, for ten points, name this small Arab country with capital at Doha. ANSWER: Qatar (Al-Jazeera and more) (2) One of these conflicts effectively ended with the capture of the Taku Forts. A letter that said, “Let us ask, where is your conscience?” was sent to the victorious monarch of these wars. One of these wars began when officials boarded and searched the Arrow. In the first of the Unequal Treaties, Hong Kong was ceded to the winner of these wars as part of the Treaty of Nanking. For ten points, name these 19th century wars in China over a British poppy export. ANSWER: Opium War(s) (3) In a story set in this country, Rasheed is angered when his wife Miriam asks what a communist is at the start of a revolution against Daoud Khan. This setting of A Thousand Splendid Suns serves as Amir’s home in one novel before he was forced to flee from a Soviet invasion. For ten points, name this country where Khaled Hosseini’s The Kite Runner is set in Kabul. ANSWER: Afghanistan (4) Until the death of his half-brother, this man jointly ruled with Ivan V. -

VHSL Regular Season Round #1
VHSL Regular Season Round 16 First Period, Fifteen Tossups 1. Fluid movement across these entities is calculated by the Starling equation. In the kidney, the glomerulus is formed of these entities, whose activity was first observed by Marcello Malphigi. A "fenestrated" type of these allows small amounts of protein and small molecules to diffuse through it. Many of these structures are only one cell thick. Oxygen is delivered to cells by diffusing across the walls of these vessels. For 10 points, name these smallest blood vessels in the human body. ANSWER: capillaries [or capillary; or capillary bed before mentioned] 032-09-2-01101 2. This President was nicknamed "Ice Veins" because of his cold personality. This man helped settle a boundary dispute between Great Britain and Venezuela. One controversial bill signed by this President gave disability pensions to veterans even if their injury was not from combat. This man worked with the "Billion Dollar Congress" and signed the Sherman Anti-Trust Act, the Sherman Silver Purchase Act, and the McKinley Tariff. For 10 points, name this President, the grandson of William Henry Harrison. ANSWER: Benjamin Harrison [prompt on Harrison] 021-09-2-01102 3. These particles can undergo an inelastic scattering process described by the Klein-Nishina formula; that process consists of them losing energy when they collide with matter due to Compton Scattering. When one of these particles imparts enough energy to an electron for it to exceed the work function, that electron may be emitted from the surface of a metal in an effect described in a 1905 Einstein paper. -

August Chinese History.Pdf
August 2007 DA C Q Study Guide: D ynasty A cademic C ompetition Chinese History Q uestions Chinese Dynasties A note on terms: Many dynasties are divided into various segments (Eastern Zhou, Western Han, etc.) that are sometimes considered different dynasties. Most often, this nomenclature refers to the location of the Chinese capital at the time and quite often a corresponding national strength. For the purposes of this guide, dynasties have been grouped together with major divisions annotated. Dynasty Description Three Sovereigns and Five This period was not a dynasty, and is not historical, but it is considered a Emperors (2852-2205 BCE) key pre-history in most texts. Its events are entirely mythological. The Five Emperors are: the Yellow Emperor (ancestor of the Han ethnic group, whose historian Cangjie invented language), Zhuanxu, Ku, Yao, and Shun. Xia (2070-1600 BCE) Substantial debate exists as to the existence of this dynasty. Modern archeology suggests something existed during this time, though it is uncertain whether or not it was the Xia. It was founded by Yu the Great and marks the transition from divine mandate to dynastic rule. Shang (1600-1046 BCE) The first historical dynasty, most of the earliest Chinese characters appear on oracle bones from this period. The high god Di was worshiped, and the capital was at Yin. Zhou (1122-256 BCE) It was founded by King Wu after the battle of Muye, though its inception is Western Zhou more due to the Duke of Zhou, who organized the kingdom and oversaw Eastern Zhou the creation of the I Jing. -

History Bowl Round 8
IHBB Championships 2018 Bowl Round 8 Bowl Round 8 First Quarter (1) In an effort to encourage dental health, this leader encouraged his population to chew on bones because dogs do so. This leader renamed the month of September after his book Ruhnama, whose study is required to obtain a driver’s license in his country. This leader commissioned the construction of an Arch of Neutrality, which contained a golden statue of himself that rotated to face the sun in the city of Ashgabat. For ten points, name this totalitarian ruler of post-independence Turkmenistan from 1991 to his death in 2006. ANSWER: Saparmurat Niyazov (or Turkmenbashi) (2) Five deities were born from this goddess's necklace of 500 jewels. To lure this deity out of hiding, a dawn goddess performed a strip tease on top of an overturned tub. This goddess's brother threw a flayed horse into a room containing her weavers, causing her to retreat into a cave in anger. This goddess, who was born when her father Izanagi washed his left eye, is worshiped at the Ise [ee- say] Shrine. The Emperor of Japan descended from, for ten points, what sun goddess of Shinto myth? ANSWER: Amaterasu (3) The fourth and final section of a book by this man incorrectly tries to explain the origins of Earth’s tides. This man supported one of his arguments by citing the phases of Venus and apparent motion of sunspots. This man introduced the idea of inertial reference frames with a thought experiment about a man below deck on a ship, and wrote a book consisting of conversations between the laymen Sagredo, Simplicio, and Salviati. -
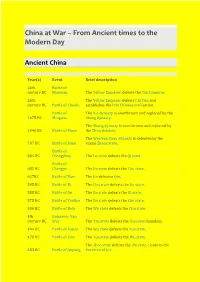
China at War – from Ancient Times to the Modern Day
China at War – From Ancient times to the Modern Day Ancient China Year(s) Event Brief description 26th Battle of century BC Banquan The Yellow Emperor defeats the Yan Emperor. 26th The Yellow Emperor defeats Chi You and century BC Battle of Zhuolu establishes the Han Chinese civilisation. Battle of The Xia dynasty is overthrown and replaced by the 1675 BC Mingtiao Shang dynasty. The Shang dynasty is overthrown and replaced by 1046 BC Battle of Muye the Zhou dynasty. The Western Zhou dynasty is defeated by the 707 BC Battle of Xuge vassal Zheng state. Battle of 684 BC Changshao The Lu state defeats the Qi state Battle of 632 BC Chengpu The Jin state defeats the Chu state. 627BC Battle of Xiao The Jin defeates Qin. 595 BC Battle of Bi The Chu state defeats the Jin state. 588 BC Battle of An The Jin state defeats the Qi state. 575 BC Battle of Yanling The Jin state defeats the Chu state. 506 BC Battle of Boju The Wu state defeats the Chu state. 4th Gojoseon–Yan century BC War The Yan state defeats the Gojoseon kingdom. 494 BC Battle of Fujiao The Wu state defeats the Yue state. 478 BC Battle of Lize The Yue state defeats the Wu state. The Zhao state defeats the Zhi state. Leads to the 453 BC Battle of Jinyang Partition of Jin. 353 BC Battle of Guiling The Qi state defeats the Wei state. 342 BC Battle of Maling The Qi state defeats the Wei state. Battle of 341 BC Guailing 293 BC Battle of Yique The Qin state defeats the Wei and Han states.