Efficient Path Planning for Multiple Agents in Agriculture Fields
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Vol 45 Ams / Maa Anneli Lax New Mathematical Library
45 AMS / MAA ANNELI LAX NEW MATHEMATICAL LIBRARY VOL 45 10.1090/nml/045 When Life is Linear From Computer Graphics to Bracketology c 2015 by The Mathematical Association of America (Incorporated) Library of Congress Control Number: 2014959438 Print edition ISBN: 978-0-88385-649-9 Electronic edition ISBN: 978-0-88385-988-9 Printed in the United States of America Current Printing (last digit): 10987654321 When Life is Linear From Computer Graphics to Bracketology Tim Chartier Davidson College Published and Distributed by The Mathematical Association of America To my parents, Jan and Myron, thank you for your support, commitment, and sacrifice in the many nonlinear stages of my life Committee on Books Frank Farris, Chair Anneli Lax New Mathematical Library Editorial Board Karen Saxe, Editor Helmer Aslaksen Timothy G. Feeman John H. McCleary Katharine Ott Katherine S. Socha James S. Tanton ANNELI LAX NEW MATHEMATICAL LIBRARY 1. Numbers: Rational and Irrational by Ivan Niven 2. What is Calculus About? by W. W. Sawyer 3. An Introduction to Inequalities by E. F.Beckenbach and R. Bellman 4. Geometric Inequalities by N. D. Kazarinoff 5. The Contest Problem Book I Annual High School Mathematics Examinations 1950–1960. Compiled and with solutions by Charles T. Salkind 6. The Lore of Large Numbers by P.J. Davis 7. Uses of Infinity by Leo Zippin 8. Geometric Transformations I by I. M. Yaglom, translated by A. Shields 9. Continued Fractions by Carl D. Olds 10. Replaced by NML-34 11. Hungarian Problem Books I and II, Based on the Eotv¨ os¨ Competitions 12. 1894–1905 and 1906–1928, translated by E. -

Taxicab Space, Inversion, Harmonic Conjugates, Taxicab Sphere
TAXICAB SPHERICAL INVERSIONS IN TAXICAB SPACE ADNAN PEKZORLU∗, AYS¸E BAYAR DEPARTMENT OF MATHEMATICS-COMPUTER UNIVERSITY OF ESKIS¸EHIR OSMANGAZI E-MAILS: [email protected], [email protected] (Received: 11 June 2019, Accepted: 29 May 2020) Abstract. In this paper, we define an inversion with respect to a taxicab sphere in the three dimensional taxicab space and prove several properties of this inversion. We also study cross ratio, harmonic conjugates and the inverse images of lines, planes and taxicab spheres in three dimensional taxicab space. AMS Classification: 40Exx, 51Fxx, 51B20, 51K99. Keywords: taxicab space, inversion, harmonic conjugates, taxicab sphere. 1. Introduction The inversion was introduced by Apollonius of Perga in his last book Plane Loci, and systematically studied and applied by Steiner about 1820s, [2]. During the following decades, many physicists and mathematicians independently rediscovered inversions, proving the properties that were most useful for their particular applica- tions by defining a central cone, ellipse and circle inversion. Some of these features are inversion compared to the classical circle. Inversion transformation and basic concepts have been presented in literature. The inversions with respect to the central conics in real Euclidean plane was in- troduced in [3]. Then the inversions with respect to ellipse was studied detailed in ∗ CORRESPONDING AUTHOR JOURNAL OF MAHANI MATHEMATICAL RESEARCH CENTER VOL. 9, NUMBERS 1-2 (2020) 45-54. DOI: 10.22103/JMMRC.2020.14232.1095 c MAHANI MATHEMATICAL RESEARCH CENTER 45 46 ADNAN PEKZORLU, AYS¸E BAYAR [13]. In three-dimensional space a generalization of the spherical inversion is given in [16]. Also, the inversions with respect to the taxicab distance, α-distance [18], [4], or in general a p-distance [11]. -

Taxicab Geometry, Or When a Circle Is a Square
Taxicab Geometry, or When a Circle is a Square Circle on the Road 2012, Math Festival Olga Radko (Los Angeles Math Circle, UCLA) April 14th, 2012 Abstract The distance between two points is the length of the shortest path connecting them. In plane Euclidean geometry such a path is along the straight line connecting the two points. In contrast, in a city consisting of a square grid of streets shortest paths between two points are no longer straight lines (as every cab driver knows). We will explore the geometry of this unusual distance and play several related games. 1 René Descartes (1596-1650) was a French mathematician, philosopher and writer. Among his many accomplishments, he developed a very convenient way to describe positions of points on a plane. This method was very important for fu- ture development of mathematics and physics. We will start learning about this invention today. The city of Descartes is a plane that extends infinitely in all directions: The center of the city is marked by point O. • The horizontal (West-East) line going through O is called • the x-axis. The vertical (South-North) line going through O is called • the y-axis. Each house in the city is represented by a point which • is the intersection of a vertical and a horizontal line. Each house has an address which consists of two whole numbers written inside of parenthesis. 2 Example. Point A shown below has coordinates (2, 3). The first number tells you the distance to the y-axis. • The distance is positive if you are on the right of the y-axis. -

Geometry of Some Taxicab Curves
GEOMETRY OF SOME TAXICAB CURVES Maja Petrović 1 Branko Malešević 2 Bojan Banjac 3 Ratko Obradović 4 Abstract In this paper we present geometry of some curves in Taxicab metric. All curves of second order and trifocal ellipse in this metric are presented. Area and perimeter of some curves are also defined. Key words: Taxicab metric, Conics, Trifocal ellipse 1. INTRODUCTION In this paper, taxicab and standard Euclidean metrics for a visual representation of some planar curves are considered. Besides the term taxicab, also used are Manhattan, rectangular metric and city block distance [4], [5], [7]. This metric is a special case of the Minkowski 1 MSc Maja Petrović, assistant at Faculty of Transport and Traffic Engineering, University of Belgrade, Serbia, e-mail: [email protected] 2 PhD Branko Malešević, associate professor at Faculty of Electrical Engineering, Department of Applied Mathematics, University of Belgrade, Serbia, e-mail: [email protected] 3 MSc Bojan Banjac, student of doctoral studies of Software Engineering, Faculty of Electrical Engineering, University of Belgrade, Serbia, assistant at Faculty of Technical Sciences, Computer Graphics Chair, University of Novi Sad, Serbia, e-mail: [email protected] 4 PhD Ratko Obradović, full professor at Faculty of Technical Sciences, Computer Graphics Chair, University of Novi Sad, Serbia, e-mail: [email protected] 1 metrics of order 1, which is for distance between two points , and , determined by: , | | | | (1) Minkowski metrics contains taxicab metric for value 1 and Euclidean metric for 2. The term „taxicab geometry“ was first used by K. Menger in the book [9]. -

LAB 9.1 Taxicab Versus Euclidean Distance
([email protected] LAB 9.1 Name(s) Taxicab Versus Euclidean Distance Equipment: Geoboard, graph or dot paper If you can travel only horizontally or vertically (like a taxicab in a city where all streets run North-South and East-West), the distance you have to travel to get from the origin to the point (2, 3) is 5.This is called the taxicab distance between (0, 0) and (2, 3). If, on the other hand, you can go from the origin to (2, 3) in a straight line, the distance you travel is called the Euclidean distance, or just the distance. Finding taxicab distance: Taxicab distance can be measured between any two points, whether on a street or not. For example, the taxicab distance from (1.2, 3.4) to (9.9, 9.9) is the sum of 8.7 (the horizontal component) and 6.5 (the vertical component), for a total of 15.2. 1. What is the taxicab distance from (2, 3) to the following points? a. (7, 9) b. (–3, 8) c. (2, –1) d. (6, 5.4) e. (–1.24, 3) f. (–1.24, 5.4) Finding Euclidean distance: There are various ways to calculate Euclidean distance. Here is one method that is based on the sides and areas of squares. Since the area of the square at right is y 13 (why?), the side of the square—and therefore the Euclidean distance from, say, the origin to the point (2,3)—must be ͙ෆ13,or approximately 3.606 units. 3 x 2 Geometry Labs Section 9 Distance and Square Root 121 © 1999 Henri Picciotto, www.MathEducationPage.org ([email protected] LAB 9.1 Name(s) Taxicab Versus Euclidean Distance (continued) 2. -
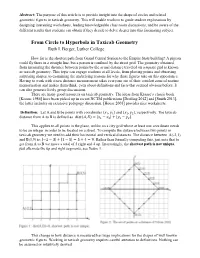
From Circle to Hyperbola in Taxicab Geometry
Abstract: The purpose of this article is to provide insight into the shape of circles and related geometric figures in taxicab geometry. This will enable teachers to guide student explorations by designing interesting worksheets, leading knowledgeable class room discussions, and be aware of the different results that students can obtain if they decide to delve deeper into this fascinating subject. From Circle to Hyperbola in Taxicab Geometry Ruth I. Berger, Luther College How far is the shortest path from Grand Central Station to the Empire State building? A pigeon could fly there in a straight line, but a person is confined by the street grid. The geometry obtained from measuring the distance between points by the actual distance traveled on a square grid is known as taxicab geometry. This topic can engage students at all levels, from plotting points and observing surprising shapes, to examining the underlying reasons for why these figures take on this appearance. Having to work with a new distance measurement takes everyone out of their comfort zone of routine memorization and makes them think, even about definitions and facts that seemed obvious before. It can also generate lively group discussions. There are many good resources on taxicab geometry. The ideas from Krause’s classic book [Krause 1986] have been picked up in recent NCTM publications [Dreiling 2012] and [Smith 2013], the latter includes an extensive pedagogy discussion. [House 2005] provides nice worksheets. Definition: Let A and B be points with coordinates (푥1, 푦1) and (푥2, 푦2), respectively. The taxicab distance from A to B is defined as 푑푖푠푡(퐴, 퐵) = |푥1 − 푥2| + |푦1 − 푦2|. -

Math 105 Workbook Exploring Mathematics
Math 105 Workbook Exploring Mathematics Douglas R. Anderson, Professor Fall 2018: MWF 11:50-1:00, ISC 101 Acknowledgment First we would like to thank all of our former Math 105 students. Their successes, struggles, and suggestions have shaped how we teach this course in many important ways. We also want to thank our departmental colleagues and several Concordia math- ematics majors for many fruitful discussions and resources on the content of this course and the makeup of this workbook. Some of the topics, examples, and exercises in this workbook are drawn from other works. Most significantly, we thank Samantha Briggs, Ellen Kramer, and Dr. Jessie Lenarz for their work in Exploring Mathematics, as well as other Cobber mathemat- ics professors. We have also used: • Taxicab Geometry: An Adventure in Non-Euclidean Geometry by Eugene F. Krause, • Excursions in Modern Mathematics, Sixth Edition, by Peter Tannenbaum. • Introductory Graph Theory by Gary Chartrand, • The Heart of Mathematics: An invitation to effective thinking by Edward B. Burger and Michael Starbird, • Applied Finite Mathematics by Edmond C. Tomastik. Finally, we want to thank (in advance) you, our current students. Your suggestions for this course and this workbook are always encouraged, either in person or over e-mail. Both the course and workbook are works in progress that will continue to improve each semester with your help. Let's have a great semester this fall exploring mathematics together and fulfilling Concordia's math requirement in 2018. Skol Cobbs! i ii Contents 1 Taxicab Geometry 3 1.1 Taxicab Distance . .3 Homework . .8 1.2 Taxicab Circles . -

Taxicab Geometry
TAXICAB GEOMETRY MICHAEL A. HALL 11/13/2011 EUCLIDEAN GEOMETRY In geometry the primary objects of study are points, lines, angles, and distances. We can identify each point in the plane by its Cartesian coordinates (x; y). The Euclidean distance between points A = (x1; y1) and B = (x2; y2) is p 2 2 dE(A; B) = (x2 − x1) + (y2 − y1) : (Euclidean distance formula) TAXICAB GEOMETRY In “taxicab” geometry, the points, lines, and angles are the same, but the notion of distance is different from the Euclidean distance. The taxicab distance between points A = (x1; y1) and B = (x2; y2) is dT (A; B) = jx2 − x1j + jy2 − y1j: (Taxicab distance formula) Exercises. (1) On a sheet of graph paper, mark each pair of points P and Q and find the both the Euclidean and taxicab distance between them: (a) P = (0; 0), Q = (1; 1) (b) P = (1; 2), Q = (2; 3) (c) P = (1; 0), Q = (5; 0) (2) (Taxi circles) Let A be the point with coordinates (2; 2). (a) Plot A on a piece of graph paper, and mark all points P such that dT (A; P ) = 1. The set of such points is written fP j dT (A; P ) = 1g. Also mark all points in fP j dT (A; P ) = 2g. (b) Graph the set of points which are a distance 2 from the point B = (1; 1). (3) (Lines) Recall that in taxicab geometry, the shapes we call lines are the same as the usual lines in Euclidean geometry. Graph the line ` that passes through the points (3; 0) and (0; 3). -

Taxi Cab Geometry: History and Applications!
The Mathematics Enthusiast Volume 2 Number 1 Article 6 4-2005 Taxi Cab Geometry: History and Applications! Chip Reinhardt Follow this and additional works at: https://scholarworks.umt.edu/tme Part of the Mathematics Commons Let us know how access to this document benefits ou.y Recommended Citation Reinhardt, Chip (2005) "Taxi Cab Geometry: History and Applications!," The Mathematics Enthusiast: Vol. 2 : No. 1 , Article 6. Available at: https://scholarworks.umt.edu/tme/vol2/iss1/6 This Article is brought to you for free and open access by ScholarWorks at University of Montana. It has been accepted for inclusion in The Mathematics Enthusiast by an authorized editor of ScholarWorks at University of Montana. For more information, please contact [email protected]. TMME, Vol2, no.1, p.38 Taxi Cab Geometry: History and Applications Chip Reinhardt Stevensville High School, Stevensville, Montana Paper submitted: December 9, 2003 Accepted with revisions: 27. July 2004 We will explore three real life situations proposed in Eugene F. Krause's book Taxicab Geometry. First a dispatcher for Ideal City Police Department receives a report of an accident at X = (-1,4). There are two police cars located in the area. Car C is at (2,1) and car D is at (-1,-1). Which car should be sent? Second there are three high schools in Ideal city. Roosevelt at (2,1), Franklin at ( -3,-3) and Jefferson at (-6,-1). Draw in school district boundaries so that each student in Ideal City attends the school closet to them. For the third problem a telephone company wants to set up payphone booths so that everyone living with in twelve blocks of the center of town is with in four blocks of a payphone. -

Digital Distance Geometry: a Survey
Sddhan& Vol. 18, Part 2, June 1993, pp. 159-187. © Printed in India. Digital distance geometry: A survey P P DAS t and B N CHATTERJI* Department of Computer Science and Engineering, and * Department of Electronics and Electrical Communication Engineering, Indian Institute of Technology, Kharagpur 721 302, India Abstract. Digital distance geometry (DDG) is the study of distances in the geometry of digitized spaces. This was introduced approximately 25 years ago, when the study of digital geometry itself began, for providing a theoretical background to digital picture processing algorithms. In this survey we focus our attention on the DDG of arbitrary dimensions and other related issues and compile an up-to-date list of references on the topic. Keywords. Digital space; neighbourhood; path; distance function; metric; digital distance geometry. 1. Introduction Digital geometry (DG) is the study of the geometry of discrete point (or lattice point, grid point) spaces where every point has integral coordinates. In its simplest form we talk about the DG of the two-dimensional (2-D) space which is an infinite array of equispaced points called pixels. Creation of this geometry was initiated in the sixties when it was realized that the digital analysis of visual patterns needed a proper understanding of the discrete space. Since a continuous space cannot be represented in the computer, an approximated digital model found extensive use. However, the digital model failed to capture many properties of Euclidean geometry (EG) and thus the formulation of a new geometrical paradigm was necessary. A similarity can be drawn here between the arithmetic of real numbers and that of integers to highlight the above point. -

On Some Regular Polygons in the Taxicab 3−Space
KoG•19–2015 S. Yuksel,¨ M. Ozcan:¨ On Some Regular Polygons in the Taxicab 3−Space Original scientific paper SULEYMAN¨ YUKSEL¨ Accepted 17. 12. 2015. MUNEVVER¨ O¨ ZCAN On Some Regular Polygons in the Taxicab 3−Space On Some Regular Polygons in the Taxicab O nekim pravilnim mnogokutima u taxicab trodi- 3−Space menzionalnom prostoru ABSTRACT SAZETAKˇ In this study, it has been researched which Euclidean reg- U ovom se radu prouˇcavakoji su euklidski pravilni mno- ular polygons are also taxicab regular and which are not. gokuti ujedno i taxicab pravilni, a koji to nisu. Takod-er se The existence of non-Euclidean taxicab regular polygons istraˇzujepostojanje taxicab pravinih mnogokuta koji nisu in the taxicab 3-space has also been investigated. pravilni u euklidskom smislu. Key words: taxicab geometry, Euclidean geometry, regu- lar polygons Kljuˇcnerijeˇci: taxicab geometrija, euklidska geometrija, pravilni mnogokuti MSC2010: 51K05, 51K99, 51N25 1 Introduction which is centered at M = (x0;y0) point with radius r. In 3, the equation of taxicab sphere is 3 R The taxicab 3-dimensional space RT is almost the same 3 jx − x j + jy − y j + jz − z j = r as the Euclidean analytical 3-dimensional space R . The 0 0 0 (4) points, lines and planes are the same in Euclidean and taxi- which is centered at M = (x0;y0;z0) point with radius r cab geometry and the angles are measured in the same way, (see [7], [8], [9]). Then, a taxicab circle can be defined by but the distance function is different. The taxicab metric is a plane and a taxicab sphere. -

Taxicab Geometry
PROJECT for Chapter 1 Taxicab Geometry OBJECTIVE Compare distances in taxicab geometry to distances in Euclidean geometry. Materials: ruler, graph paper, colored pencils, poster paper In taxicab geometry, distances are measured along paths that are made of horizontal and vertical segments. Diagonal paths are not allowed. This simulates the movement of taxicabs in a city, which can travel only on streets, never through buildings. FINDING TAXICAB DISTANCES Follow these steps to learn more about distance in taxicab geometry. B B 14 B 10 A A A 12 1 Copy points A and 2 Trace paths from A 3 Calculate the B on a piece of to B using the grid distances covered graph paper. lines. You may move by your paths. horizontally and vertically but not diagonally. INVESTIGATION Repeat Steps 2 and 3 above several times, then answer the exercises. 1. Compare your paths and those of your classmates. Are the distances always the same? What is the length of the shortest possible path from A to B? 2. The length of the shortest path from A to B is called the taxicab distance from A to B. Can you find other paths from A to B that have the same distance? 3. Use the Distance Formula to find the Euclidean distance from A to B. Which is greater, the taxicab distance from A to B or the Euclidean distance? 4. On another piece of graph paper, plot a new pair of points. Find the taxicab distance and Euclidean distance for the points. Repeat this for several pairs of points.