Distributed File Systems
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
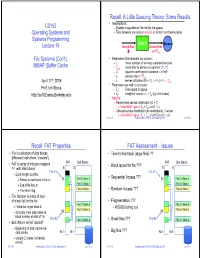
Some Results Recall: FAT Properties FAT Assessment – Issues
Recall: A Little Queuing Theory: Some Results • Assumptions: CS162 – System in equilibrium; No limit to the queue Operating Systems and – Time between successive arrivals is random and memoryless Systems Programming Queue Server Lecture 19 Arrival Rate Service Rate μ=1/Tser File Systems (Con’t), • Parameters that describe our system: MMAP, Buffer Cache – : mean number of arriving customers/second –Tser: mean time to service a customer (“m1”) –C: squared coefficient of variance = 2/m12 –μ: service rate = 1/Tser th April 11 , 2019 –u: server utilization (0u1): u = /μ = Tser • Parameters we wish to compute: Prof. Ion Stoica –Tq: Time spent in queue http://cs162.eecs.Berkeley.edu –Lq: Length of queue = Tq (by Little’s law) • Results: –Memoryless service distribution (C = 1): » Called M/M/1 queue: Tq = Tser x u/(1 – u) –General service distribution (no restrictions), 1 server: » Called M/G/1 queue: Tq = Tser x ½(1+C) x u/(1 – u)) 4/11/19 Kubiatowicz CS162 © UCB Spring 2019 Lec 19.2 Recall: FAT Properties FAT Assessment – Issues • File is collection of disk blocks • Time to find block (large files) ?? (Microsoft calls them “clusters”) FAT Disk Blocks FAT Disk Blocks • FAT is array of integers mapped • Block layout for file ??? 1-1 with disk blocks 0: 0: 0: 0: File #1 File #1 – Each integer is either: • Sequential Access ??? » Pointer to next block in file; or 31: File 31, Block 0 31: File 31, Block 0 » End of file flag; or File 31, Block 1 File 31, Block 1 » Free block flag File 63, Block 1 • Random Access ??? File 63, Block 1 • File Number -

Recent Filesystem Optimisations in Freebsd
Recent Filesystem Optimisations in FreeBSD Ian Dowse <[email protected]> Corvil Networks. David Malone <[email protected]> CNRI, Dublin Institute of Technology. Abstract 2.1 Soft Updates In this paper we summarise four recent optimisations Soft updates is one solution to the problem of keeping to the FFS implementation in FreeBSD: soft updates, on-disk filesystem metadata recoverably consistent. Tra- dirpref, vmiodir and dirhash. We then give a detailed ex- ditionally, this has been achieved by using synchronous position of dirhash’s implementation. Finally we study writes to order metadata updates. However, the perfor- these optimisations under a variety of benchmarks and mance penalty of synchronous writes is high. Various look at their interactions. Under micro-benchmarks, schemes, such as journaling or the use of NVRAM, have combinations of these optimisations can offer improve- been devised to avoid them [14]. ments of over two orders of magnitude. Even real-world workloads see improvements by a factor of 2–10. Soft updates, proposed by Ganger and Patt [4], allows the reordering and coalescing of writes while maintain- ing consistency. Consequently, some operations which have traditionally been durable on system call return are 1 Introduction no longer so. However, any applications requiring syn- chronous updates can still use fsync(2) to force specific changes to be fully committed to disk. The implementa- Over the last few years a number of interesting tion of soft updates is relatively complicated, involving filesystem optimisations have become available under tracking of dependencies and the roll forward/back of FreeBSD. In this paper we have three goals. -

Sys/Sys/Bio.H 1 1 /* 65 Void *Bio Caller2; /* Private Use by the Caller
04/21/04 16:54:59 sys/sys/bio.h 1 1 /* 65 void *bio_caller2; /* Private use by the caller. */ 2 * Copyright (c) 1982, 1986, 1989, 1993 66 TAILQ_ENTRY(bio) bio_queue; /* Disksort queue. */ 3 * The Regents of the University of California. All rights reserved. 67 const char *bio_attribute; /* Attribute for BIO_[GS]ETATTR */ 4 * (c) UNIX System Laboratories, Inc. 68 struct g_consumer *bio_from; /* GEOM linkage */ 5 * All or some portions of this file are derived from material licensed 69 struct g_provider *bio_to; /* GEOM linkage */ 6 * to the University of California by American Telephone and Telegraph 70 off_t bio_length; /* Like bio_bcount */ 7 * Co. or Unix System Laboratories, Inc. and are reproduced herein with 71 off_t bio_completed; /* Inverse of bio_resid */ 8 * the permission of UNIX System Laboratories, Inc. 72 u_int bio_children; /* Number of spawned bios */ 9 * 73 u_int bio_inbed; /* Children safely home by now */ 10 * Redistribution and use in source and binary forms, with or without 74 struct bio *bio_parent; /* Pointer to parent */ 11 * modification, are permitted provided that the following conditions 75 struct bintime bio_t0; /* Time request started */ 12 * are met: 76 13 * 1. Redistributions of source code must retain the above copyright 77 bio_task_t *bio_task; /* Task_queue handler */ 14 * notice, this list of conditions and the following disclaimer. 78 void *bio_task_arg; /* Argument to above */ 15 * 2. Redistributions in binary form must reproduce the above copyright 79 16 * notice, this list of conditions and the following disclaimer in the 80 /* XXX: these go away when bio chaining is introduced */ 17 * documentation and/or other materials provided with the distribution. 81 daddr_t bio_pblkno; /* physical block number */ 18 * 3. -

Operating Systems in Depth This Page Intentionally Left Blank OPERATING SYSTEMS in DEPTH
This page intentionally left blank Operating Systems in Depth This page intentionally left blank OPERATING SYSTEMS IN DEPTH Thomas W. Doeppner Brown University JOHN WILEY & SONS, INC. vice-president & executive publisher Donald Fowley executive editor Beth Lang Golub executive marketing manager Christopher Ruel production editor Barbara Russiello editorial program assistant Mike Berlin senior marketing assistant Diana Smith executive media editor Thomas Kulesa cover design Wendy Lai cover photo Thomas W. Doeppner Cover photo is of Banggai Cardinalfi sh (Pterapogon kauderni), taken in the Lembeh Strait, North Sulawesi, Indonesia. This book was set in 10/12 Times Roman. The book was composed by MPS Limited, A Macmillan Company and printed and bound by Hamilton Printing Company. This book is printed on acid free paper. ϱ Founded in 1807, John Wiley & Sons, Inc. has been a valued source of knowledge and understanding for more than 200 years, helping people around the world meet their needs and fulfi ll their aspirations. Our company is built on a foundation of principles that include responsibility to the communities we serve and where we live and work. In 2008, we launched a Corporate Citizenship Initiative, a global effort to address the environmental, social, economic, and ethical challenges we face in our business. Among the issues we are addressing are carbon impact, paper specifi cations and procurement, ethical conduct within our business and among our vendors, and community and charitable support. For more information, please visit our -

Conference Reports From
THE MAGAZINE OF USENIX & SAGE August 2002 volume 27 • number 5 inside: CONFERENCE REPORTS USENIX 2002 & The Advanced Computing Systems Association & The System Administrators Guild conference reports 2002 USENIX Annual KEYNOTE ADDRESS Technical Conference THE INTERNET’S COMING SILENT SPRING Lawrence Lessig, Stanford University MONTEREY, CALIFORNIA, USA OUR THANKS TO THE SUMMARIZERS: Summarized by David E. Ott JUNE 10-15, 2002 For the USENIX Annual Technical Conference: In a talk that received a standing ova- Josh Simon, who organized the collecting of ANNOUNCEMENTS tion, Lawrence Lessig pointed out the the summaries in his usual flawless fashion Summarized by Josh Simon recent legal crisis that is stifling innova- Steve Bauer tion by extending notions of private Florian Buchholz The 2002 USENIX Annual Technical Matt Butner Conference was very exciting. The gen- ownership of technology beyond rea- Pradipta De eral track had 105 papers submitted (up sonable limits. Xiaobo Fan 28% from 82 in 2001) and accepted 25 Hai Huang Several lessons from history are instruc- Scott Kilroy (19 from students); the FREENIX track tive: (1) Edwin Armstrong, the creator Teri Lampoudi had 53 submitted (up from 52 in 2001) of FM radio technology, became an Josh Lothian and accepted 26 (7 from students). enemy to RCA, which launched a legal Bosko Milekic campaign to suppress the technology; Juan Navarro The two annual USENIX-given awards David E. Ott were presented by outgoing USENIX (2) packet switching networks, proposed Amit Purohit Board President Dan Geer. The USENIX by Paul Baron, were seen by AT&T as a Brennan Reynolds Lifetime Achievement Award (also new, competing technology that had to Matt Selsky known as the be suppressed; (3) Disney took Grimm J.D. -

Freebsd Documentation Release 10.1
FreeBSD Documentation Release 10.1 Claudia Mane July 12, 2015 Contents 1 &title; 3 1.1 What is FreeBSD?............................................3 1.2 Cutting edge features...........................................3 1.3 Powerful Internet solutions........................................3 1.4 Advanced Embedded Platform......................................3 1.5 Run a huge number of applications...................................3 1.6 Easy to install..............................................4 1.7 FreeBSD is free .............................................4 1.8 Contributing to FreeBSD.........................................4 2 &title; 5 2.1 Introduction...............................................5 3 &title; 15 3.1 Experience the possibilities with FreeBSD............................... 15 3.2 FreeBSD is a true open system with full source code........................... 15 3.3 FreeBSD runs thousands of applications................................. 15 3.4 FreeBSD is an operating system that will grow with your needs..................... 16 3.5 What experts have to say . ........................................ 16 4 &title; 17 4.1 BSD Daemon............................................... 17 4.2 “Powered by FreeBSD” Logos...................................... 19 4.3 Old Advertisement Banners....................................... 19 4.4 Graphics Use............................................... 19 4.5 Trademarks................................................ 20 5 &title; 21 6 &title; 23 6.1 Subversion............................................... -

Debugging Kernel Problems
Debugging Kernel Problems by Greg Lehey Edition for EuroBSDCon 2005 Basel, 25 November 2005 Debugging Kernel Problems by Greg Lehey ([email protected], [email protected], [email protected]) Copyright © 1995-2005 Greg Lehey $Id: handout.mm,v 1.14 2005/11/05 02:36:32 grog Exp $ This book is licensed under the Creative Commons Attribution-NonCommer cial-ShareAlike license, Version 2.5. (http://cr eativecommons.org/licenses/by-nc-sa/2.5/). The following is a slightly refor matted version of the license specified there. Any dif ferences arenot intended to change the meaning of the license. Youare free: • to copy, distribute, display, and perfor m the work, and • to make derivative works under the following conditions: • Attribution: You must attribute the work in the manner specified by the author or licensor. • Non-commercial: You may not use this work for commercial purposes. • Shar e Alike: If you alter,transfor m, or build upon this work, you may distribute the resulting work only under a license identical to this one. • For any reuse or distribution, you must make clear to others the license terms of this work. • Any of these conditions can be modified if you get permission from the copyright holder. Your fair use and other rights areinnoway affected by the above. The latest version of this document is available at http://www.lemis.com/gr og/Papers/Debug-tutorial/tutori- al.pdf. The latest version of the accompanying slides is at http://www.lemis.com/gr og/Papers/Debug-tutori- al/slides.pdf. Debugging Kernel Problems 3 Preface Debugging kernel problems is a black art. -

ZFS and Freebsd
������� ���������������������������� ������������� ��������������� � ������������������������������������ ������������������������������������������������������������ �������������������������������������������������� ����������������������������������������������������������� ������������������������� ���������������������������������������������������������������� � ����������������������������������� �������������������������������������������������������� ����������������������������� �������������������������������������������� �������������������������������������������������������� � ���������������������������������� ��������������������������� �������������������������������������������������������������� � ������������������������������ ���������������������������������������������������������� ���������������������������������������� �������������������� �������������������� � ��������������������������������������������� ������������������������������������������������ ������������������������������������������ ��������������������������������������������������������� � ���������������������������������������� �������������������������������������� �������������������������������������������������� ���������������������������������������������� ������������������� � ���������������������� � ������������������������������������� ��������������������������� � �������� ������������������������������ �������� � ����������������������������������� ��������� ���������� ������������� �������� ���������������������������������������������������� -

Debugging Kernel Problems
Debugging Kernel Problems by Greg Lehey Edition for BSDCan 2006 Ottawa, 11 May 2006 Debugging Kernel Problems by Greg Lehey ([email protected], [email protected], [email protected]) Copyright © 1995-2005 Greg Lehey $Id: handout.mm,v 1.14 2005/11/05 02:36:32 grog Exp grog $ This book is licensed under the Creative Commons Attribution-NonCommer cial-ShareAlike license, Version 2.5. (http://cr eativecommons.org/licenses/by-nc-sa/2.5/). The following is a slightly refor matted version of the license specified there. Any dif ferences arenot intended to change the meaning of the license. Youare free: • to copy, distribute, display, and perfor m the work, and • to make derivative works under the following conditions: • Attribution: You must attribute the work in the manner specified by the author or licensor. • Non-commercial: You may not use this work for commercial purposes. • Shar e Alike: If you alter,transfor m, or build upon this work, you may distribute the resulting work only under a license identical to this one. • For any reuse or distribution, you must make clear to others the license terms of this work. • Any of these conditions can be modified if you get permission from the copyright holder. Your fair use and other rights areinnoway affected by the above. The latest version of this document is available at http://www.lemis.com/gr og/Papers/Debug-tutorial/tutori- al.pdf. The latest version of the accompanying slides is at http://www.lemis.com/gr og/Papers/Debug-tutori- al/slides.pdf. Debugging Kernel Problems 3 Preface Debugging kernel problems is a black art. -

Scaleengine and Freebsd
SEE TEXT ONLY and FreeBSD When ScaleEngine was founded, it was based on FreeBSD because that is what the principals were most familiar with. Throughout the past eight years, the decision to use FreeBSD has served us well and provided us with distinct competitive advantages. How ScaleEngine Started Bandwidth in most colocation, and in Internet transit in general, is measured at ScaleEngine started its CDN (Content “95th percentile.” The basic concept is that Distribution Network) entirely by accident. the amount of traffic pushed to the Internet is Originally, ScaleEngine was an auto-scaling measured every 5 minutes throughout the application environment designed to host month. At the end of the month, the meas- forums, large web apps, and other high-com- urements are sorted, and the top 5% are dis- plexity high-traffic sites. After a short time, we carded. The peak amount of usage that quickly started to push too much bandwidth remains determines your bill. Usually there are out of our primary colocation facility. In work- two prices involved. The customer has a com- ing around this problem, we quickly grew into mitment level—a minimum amount of band- a CDN and eventually pivoted our business to width they buy each month—at a fixed price. focus on that market. e d u J n a l l A y B 18 FreeBSD Journal Then there is a burst or overage price. The then you pay for that peak amount of traffic customer is able to use more than the com- as if you had used that rate for the entire mitted amount of bandwidth, but if their month. -

A Dynamic Aspect-Oriented System for Data-Driven Profiling of OS Kernels
A Dissertation Submitted to Department of Mathematical and Computing Sciences, Graduate School of Information Science and Engineering, Tokyo Institute of Technology In Partial Fulfillment of the Requirements for the Degree of Doctor of Science in Mathematical and Computing Sciences A Dynamic Aspect-oriented System for Data-driven Profiling of OS Kernels データ主導のプロファイリングのための カーネル用動的アスペクト指向システム Yoshisato YANAGISAWA Dissertation Chair: Shigeru CHIBA February 2008, Copyright °c 2008 Yoshisato YANAGISAWA. All Rights Reserved. Abstract We propose a data-driven dynamic aspect-oriented system for pro¯ling OS kernels. A dynamic aspect-oriented system can change a running OS kernel without recompiling and rebooting it. This improves e±ciency of develop- ment since the developers can avoid waiting until some problems occur again. The ability to change the execution points and code is crucial. Developers would ¯rst measure the execution time of a large code section and then they would gradually narrow the range of that code section to ¯nd a performance bottleneck. As the investigation continues, they will also change interesting data for getting a log. For pro¯ling OS kernels, we added the access pointcut and the xflow point- cut to a dynamic aspect orientation for the C language. Since the C language does not have a language mechanism to make a module like a package or a class in an object-oriented language, the access pointcut is important. It selects a member access of a structure as a join point. We used a tech- nique named source-based binary-level dynamic weaving for implementing this feature. The technique collects richer symbol information at compile time to use it at run time for getting a memory address of a member access. -

Windows+BSD+Linux Installation Guide, V1.1 Windows+BSD+Linux Installation Guide
Windows+BSD+Linux Installation Guide, v1.1 Windows+BSD+Linux Installation Guide Subhasish Ghosh [email protected]: v1.1Last updated: August 21st, 2003 Revision History: ♦ v1.0: Initial release, reviewed by Linux Documentation Project (LDP). A few structural changes and minor corrections made; Chapters "Troubleshooting" and "Installing OpenBSD 3.2−RELEASE" added. ♦ v1.1: Corrections made and info added. Information on FreeBSD −RELEASE updated to cover 4.8−RELEASE. Chapter "Installing NetBSD 1.6.1" added and a few minor modifications made to the guide. Welcome! This document explains how three different operating systems can be installed and configured on the same hard disk of a computer. The reader may choose from: Microsoft Windows 95/98(Second Edition)/Millennium Edition(ME)/NT/2K/XP + FreeBSD 4.8−RELEASE/OpenBSD 3.2−RELEASE/NetBSD 1.6.1 + Linux. Only Intel architecture multi−booting is discussed and GNU GRUB is the boot loader of choice. If you have any questions or comments, feel free to contact me by e−mail at this address: [email protected]. Thank you! Note: In the Organization section, readers must choose to execute Chapter 3 or Chapter 4 or Chapter 5. 1. Introduction ♦ 1.1 Purpose of this Guide ♦ 1.2 What is Multiple−booting? ♦ 1.3 Multi−booting Pros and Cons ♦ 1.4 List of Assumptions ♦ 1.5 Acknowledgements ♦ 1.6 Legalese ♦ 1.7 About the Author 2. FAQ 3. Organization ♦ 3.1 Chapter 1: About the operating systems ◊ 3.1.1 Microsoft Windows ◊ 3.1.2 Linux ◊ 3.1.3 FreeBSD ◊ 3.1.4 OpenBSD ◊ 3.1.5 NetBSD ♦ 3.2 Chapter 2: Installing Microsoft Windows ◊ Section A: Installing MS Windows 95 3.