SOME GEOMETRY in HIGH-DIMENSIONAL SPACES 11 Containing Cn(S) Tends to ∞ with N
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

History of Mathematics
Georgia Department of Education History of Mathematics K-12 Mathematics Introduction The Georgia Mathematics Curriculum focuses on actively engaging the students in the development of mathematical understanding by using manipulatives and a variety of representations, working independently and cooperatively to solve problems, estimating and computing efficiently, and conducting investigations and recording findings. There is a shift towards applying mathematical concepts and skills in the context of authentic problems and for the student to understand concepts rather than merely follow a sequence of procedures. In mathematics classrooms, students will learn to think critically in a mathematical way with an understanding that there are many different ways to a solution and sometimes more than one right answer in applied mathematics. Mathematics is the economy of information. The central idea of all mathematics is to discover how knowing some things well, via reasoning, permit students to know much else—without having to commit the information to memory as a separate fact. It is the reasoned, logical connections that make mathematics coherent. The implementation of the Georgia Standards of Excellence in Mathematics places a greater emphasis on sense making, problem solving, reasoning, representation, connections, and communication. History of Mathematics History of Mathematics is a one-semester elective course option for students who have completed AP Calculus or are taking AP Calculus concurrently. It traces the development of major branches of mathematics throughout history, specifically algebra, geometry, number theory, and methods of proofs, how that development was influenced by the needs of various cultures, and how the mathematics in turn influenced culture. The course extends the numbers and counting, algebra, geometry, and data analysis and probability strands from previous courses, and includes a new history strand. -

20. Geometry of the Circle (SC)
20. GEOMETRY OF THE CIRCLE PARTS OF THE CIRCLE Segments When we speak of a circle we may be referring to the plane figure itself or the boundary of the shape, called the circumference. In solving problems involving the circle, we must be familiar with several theorems. In order to understand these theorems, we review the names given to parts of a circle. Diameter and chord The region that is encompassed between an arc and a chord is called a segment. The region between the chord and the minor arc is called the minor segment. The region between the chord and the major arc is called the major segment. If the chord is a diameter, then both segments are equal and are called semi-circles. The straight line joining any two points on the circle is called a chord. Sectors A diameter is a chord that passes through the center of the circle. It is, therefore, the longest possible chord of a circle. In the diagram, O is the center of the circle, AB is a diameter and PQ is also a chord. Arcs The region that is enclosed by any two radii and an arc is called a sector. If the region is bounded by the two radii and a minor arc, then it is called the minor sector. www.faspassmaths.comIf the region is bounded by two radii and the major arc, it is called the major sector. An arc of a circle is the part of the circumference of the circle that is cut off by a chord. -
Geometry Topics
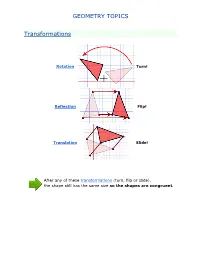
GEOMETRY TOPICS Transformations Rotation Turn! Reflection Flip! Translation Slide! After any of these transformations (turn, flip or slide), the shape still has the same size so the shapes are congruent. Rotations Rotation means turning around a center. The distance from the center to any point on the shape stays the same. The rotation has the same size as the original shape. Here a triangle is rotated around the point marked with a "+" Translations In Geometry, "Translation" simply means Moving. The translation has the same size of the original shape. To Translate a shape: Every point of the shape must move: the same distance in the same direction. Reflections A reflection is a flip over a line. In a Reflection every point is the same distance from a central line. The reflection has the same size as the original image. The central line is called the Mirror Line ... Mirror Lines can be in any direction. Reflection Symmetry Reflection Symmetry (sometimes called Line Symmetry or Mirror Symmetry) is easy to see, because one half is the reflection of the other half. Here my dog "Flame" has her face made perfectly symmetrical with a bit of photo magic. The white line down the center is the Line of Symmetry (also called the "Mirror Line") The reflection in this lake also has symmetry, but in this case: -The Line of Symmetry runs left-to-right (horizontally) -It is not perfect symmetry, because of the lake surface. Line of Symmetry The Line of Symmetry (also called the Mirror Line) can be in any direction. But there are four common directions, and they are named for the line they make on the standard XY graph. -

A CONCISE MINI HISTORY of GEOMETRY 1. Origin And
Kragujevac Journal of Mathematics Volume 38(1) (2014), Pages 5{21. A CONCISE MINI HISTORY OF GEOMETRY LEOPOLD VERSTRAELEN 1. Origin and development in Old Greece Mathematics was the crowning and lasting achievement of the ancient Greek cul- ture. To more or less extent, arithmetical and geometrical problems had been ex- plored already before, in several previous civilisations at various parts of the world, within a kind of practical mathematical scientific context. The knowledge which in particular as such first had been acquired in Mesopotamia and later on in Egypt, and the philosophical reflections on its meaning and its nature by \the Old Greeks", resulted in the sublime creation of mathematics as a characteristically abstract and deductive science. The name for this science, \mathematics", stems from the Greek language, and basically means \knowledge and understanding", and became of use in most other languages as well; realising however that, as a matter of fact, it is really an art to reach new knowledge and better understanding, the Dutch term for mathematics, \wiskunde", in translation: \the art to achieve wisdom", might be even more appropriate. For specimens of the human kind, \nature" essentially stands for their organised thoughts about sensations and perceptions of \their worlds outside and inside" and \doing mathematics" basically stands for their thoughtful living in \the universe" of their idealisations and abstractions of these sensations and perceptions. Or, as Stewart stated in the revised book \What is Mathematics?" of Courant and Robbins: \Mathematics links the abstract world of mental concepts to the real world of physical things without being located completely in either". -

A Brief History of Mathematics a Brief History of Mathematics
A Brief History of Mathematics A Brief History of Mathematics What is mathematics? What do mathematicians do? A Brief History of Mathematics What is mathematics? What do mathematicians do? http://www.sfu.ca/~rpyke/presentations.html A Brief History of Mathematics • Egypt; 3000B.C. – Positional number system, base 10 – Addition, multiplication, division. Fractions. – Complicated formalism; limited algebra. – Only perfect squares (no irrational numbers). – Area of circle; (8D/9)² Æ ∏=3.1605. Volume of pyramid. A Brief History of Mathematics • Babylon; 1700‐300B.C. – Positional number system (base 60; sexagesimal) – Addition, multiplication, division. Fractions. – Solved systems of equations with many unknowns – No negative numbers. No geometry. – Squares, cubes, square roots, cube roots – Solve quadratic equations (but no quadratic formula) – Uses: Building, planning, selling, astronomy (later) A Brief History of Mathematics • Greece; 600B.C. – 600A.D. Papyrus created! – Pythagoras; mathematics as abstract concepts, properties of numbers, irrationality of √2, Pythagorean Theorem a²+b²=c², geometric areas – Zeno paradoxes; infinite sum of numbers is finite! – Constructions with ruler and compass; ‘Squaring the circle’, ‘Doubling the cube’, ‘Trisecting the angle’ – Plato; plane and solid geometry A Brief History of Mathematics • Greece; 600B.C. – 600A.D. Aristotle; mathematics and the physical world (astronomy, geography, mechanics), mathematical formalism (definitions, axioms, proofs via construction) – Euclid; Elements –13 books. Geometry, -

A Diagrammatic Formal System for Euclidean Geometry
A DIAGRAMMATIC FORMAL SYSTEM FOR EUCLIDEAN GEOMETRY A Dissertation Presented to the Faculty of the Graduate School of Cornell University in Partial Fulfillment of the Requirements for the Degree of Doctor of Philosophy by Nathaniel Gregory Miller May 2001 c 2001 Nathaniel Gregory Miller ALL RIGHTS RESERVED A DIAGRAMMATIC FORMAL SYSTEM FOR EUCLIDEAN GEOMETRY Nathaniel Gregory Miller, Ph.D. Cornell University 2001 It has long been commonly assumed that geometric diagrams can only be used as aids to human intuition and cannot be used in rigorous proofs of theorems of Euclidean geometry. This work gives a formal system FG whose basic syntactic objects are geometric diagrams and which is strong enough to formalize most if not all of what is contained in the first several books of Euclid’s Elements.Thisformal system is much more natural than other formalizations of geometry have been. Most correct informal geometric proofs using diagrams can be translated fairly easily into this system, and formal proofs in this system are not significantly harder to understand than the corresponding informal proofs. It has also been adapted into a computer system called CDEG (Computerized Diagrammatic Euclidean Geometry) for giving formal geometric proofs using diagrams. The formal system FG is used here to prove meta-mathematical and complexity theoretic results about the logical structure of Euclidean geometry and the uses of diagrams in geometry. Biographical Sketch Nathaniel Miller was born on September 5, 1972 in Berkeley, California, and grew up in Guilford, CT, Evanston, IL, and Newtown, CT. After graduating from Newtown High School in 1990, he attended Princeton University and graduated cum laude in mathematics in 1994. -

Circle Geometry
Circle Geometry The BEST thing about Circle Geometry is…. you are given the Question and (mostly) the Answer as well. You just need to fill in the gaps in between! Mia David MA BSc Dip Ed UOW 24.06.2016 Topic: Circle Geometry Page 1 There are a number of definitions of the parts of a circle which you must know. 1. A circle consists of points which are equidistant from a fixed point (centre) The circle is often referred to as the circumference. 2. A radius is an interval which joins the centre to a point on the circumference. 3. A chord is an interval which joins two points on the circumference. 4. A diameter is a chord which passes through the centre. 5. An arc is a part of the circumference of a circle. 6. A segment is an area which is bounded by an arc and a chord. (We talk of the ALTERNATE segment, as being a segment on the OTHER side of a chord. We also refer to a MAJOR and a MINOR segment, according to the size.) 7. A semicircle is an area bounded by an arc and a diameter. 8. A sector is an area bounded by an arc and two radii. 9. A secant is an interval which intersects the circumference of a circle twice. 10. A tangent is a secant which intersects the circumference twice at the same point. (Usually we just say that a tangent TOUCHES the circle) 11. Concentric circles are circles which have the same centre. 12. Equal circles are circles which have the same radius. -

Unit 6 Lesson 1 Circle Geometry Properties Project Name______
Unit 6 Lesson 1 Circle Geometry Properties Project Name____________________ Part A Look up and define the following vocabulary words. Use an illustration where appropriate. Some of this vocabulary can be found in the glossary of your textbook, others will need additional online resources. Vocabulary Word Definition Drawing Circle Tangent to a circle Secant to a Circle Chord Central angle Major arc Minor arc Inscribed angle Intercepted arc Sector Part B (Geogebra lab must precede this part) Using geogebra, complete each construction. Verify it meets the definition of the construction by showing angle measures or lengths (ie. If the line is a perpendicular bisector…show that the part being bisected has equal lengths on either side, AND show the angle is 90 degrees). With the measurements on the diagram, take a screen shot or snip your picture into this document under each bullet point. Construct the perpendicular bisector of a chord. (Start with a circle…draw in a chord…make the perpendicular bisector to that chord.) Place drawing here…. Construct a midpoint to a chord. Place drawing here…. Draw a line segment AB, and then construct a perpendicular line through a point on that line segment. Use the circle compass technique you tried early this year found on page 33 or follow this picture Place your drawing here…. Draw a line segment AB, Construct a perpendicular line through a point not on a the line AB. Use the circle compass technique you tried early this year found on page 34 or follow this picture Place your drawing here…. Part C Important Theorems Usually we start with an interesting drawing…show a pattern…and prove a result. -

The Geometry of a Circle
The geometry of a circle mc-TY-circles-2009-1 In this unit we find the equation of a circle, when we are told its centre and its radius. There are two different forms of the equation, and you should be able to recognise both of them. We also look at some problems involving tangents to circles. In order to master the techniques explained here it is vital that you undertake plenty of practice exercises so that they become second nature. After reading this text, and/or viewing the video tutorial on this topic, you should be able to: • find the equation of a circle, given its centre and radius; • find the centre and radius of a circle, given its equation in standard form; • find the equation of the tangent to a circle through a given point on its circumference; • decide whether a given line is tangent to a given circle. Contents 1. Introduction 2 2. Theequationofacirclecentredattheorigin 2 3. Thegeneralequationofacircle 4 4. Theequationofatangenttoacircleatagivenpoint 7 www.mathcentre.ac.uk 1 c mathcentre 2009 1. Introduction The circle is a familiar shape and it has a host of geometric properties that can be proved using the traditional Euclidean format. But it is sometimes useful to work in co-ordinates and this requires us to know the standard equation of a circle, how to interpret that equation and how to find the equation of a tangent to a circle. This video will explore these particular facets of a circle, using co-ordinate geometry. 2. The equation of a circle centred at the origin The simplest case is that of a circle whose centre is at the origin. -

Euclidean Geometry
Euclidean Geometry Rich Cochrane Andrew McGettigan Fine Art Maths Centre Central Saint Martins http://maths.myblog.arts.ac.uk/ Reviewer: Prof Jeremy Gray, Open University October 2015 www.mathcentre.co.uk This work is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License. 2 Contents Introduction 5 What's in this Booklet? 5 To the Student 6 To the Teacher 7 Toolkit 7 On Geogebra 8 Acknowledgements 10 Background Material 11 The Importance of Method 12 First Session: Tools, Methods, Attitudes & Goals 15 What is a Construction? 15 A Note on Lines 16 Copy a Line segment & Draw a Circle 17 Equilateral Triangle 23 Perpendicular Bisector 24 Angle Bisector 25 Angle Made by Lines 26 The Regular Hexagon 27 © Rich Cochrane & Andrew McGettigan Reviewer: Jeremy Gray www.mathcentre.co.uk Central Saint Martins, UAL Open University 3 Second Session: Parallel and Perpendicular 30 Addition & Subtraction of Lengths 30 Addition & Subtraction of Angles 33 Perpendicular Lines 35 Parallel Lines 39 Parallel Lines & Angles 42 Constructing Parallel Lines 44 Squares & Other Parallelograms 44 Division of a Line Segment into Several Parts 50 Thales' Theorem 52 Third Session: Making Sense of Area 53 Congruence, Measurement & Area 53 Zero, One & Two Dimensions 54 Congruent Triangles 54 Triangles & Parallelograms 56 Quadrature 58 Pythagoras' Theorem 58 A Quadrature Construction 64 Summing the Areas of Squares 67 Fourth Session: Tilings 69 The Idea of a Tiling 69 Euclidean & Related Tilings 69 Islamic Tilings 73 Further Tilings -

A Geometric Introduction to Spacetime and Special Relativity
A GEOMETRIC INTRODUCTION TO SPACETIME AND SPECIAL RELATIVITY. WILLIAM K. ZIEMER Abstract. A narrative of special relativity meant for graduate students in mathematics or physics. The presentation builds upon the geometry of space- time; not the explicit axioms of Einstein, which are consequences of the geom- etry. 1. Introduction Einstein was deeply intuitive, and used many thought experiments to derive the behavior of relativity. Most introductions to special relativity follow this path; taking the reader down the same road Einstein travelled, using his axioms and modifying Newtonian physics. The problem with this approach is that the reader falls into the same pits that Einstein fell into. There is a large difference in the way Einstein approached relativity in 1905 versus 1912. I will use the 1912 version, a geometric spacetime approach, where the differences between Newtonian physics and relativity are encoded into the geometry of how space and time are modeled. I believe that understanding the differences in the underlying geometries gives a more direct path to understanding relativity. Comparing Newtonian physics with relativity (the physics of Einstein), there is essentially one difference in their basic axioms, but they have far-reaching im- plications in how the theories describe the rules by which the world works. The difference is the treatment of time. The question, \Which is farther away from you: a ball 1 foot away from your hand right now, or a ball that is in your hand 1 minute from now?" has no answer in Newtonian physics, since there is no mechanism for contrasting spatial distance with temporal distance. -

Chapter 4 Euclidean Geometry
Chapter 4 Euclidean Geometry Based on previous 15 axioms, The parallel postulate for Euclidean geometry is added in this chapter. 4.1 Euclidean Parallelism, Existence of Rectangles De¯nition 4.1 Two distinct lines ` and m are said to be parallel ( and we write `km) i® they lie in the same plane and do not meet. Terminologies: 1. Transversal: a line intersecting two other lines. 2. Alternate interior angles 3. Corresponding angles 4. Interior angles on the same side of transversal 56 Yi Wang Chapter 4. Euclidean Geometry 57 Theorem 4.2 (Parallelism in absolute geometry) If two lines in the same plane are cut by a transversal to that a pair of alternate interior angles are congruent, the lines are parallel. Remark: Although this theorem involves parallel lines, it does not use the parallel postulate and is valid in absolute geometry. Proof: Assume to the contrary that the two lines meet, then use Exterior Angle Inequality to draw a contradiction. 2 The converse of above theorem is the Euclidean Parallel Postulate. Euclid's Fifth Postulate of Parallels If two lines in the same plane are cut by a transversal so that the sum of the measures of a pair of interior angles on the same side of the transversal is less than 180, the lines will meet on that side of the transversal. In e®ect, this says If m\1 + m\2 6= 180; then ` is not parallel to m Yi Wang Chapter 4. Euclidean Geometry 58 It's contrapositive is If `km; then m\1 + m\2 = 180( or m\2 = m\3): Three possible notions of parallelism Consider in a single ¯xed plane a line ` and a point P not on it.