"Morphemes Or Lexemes?", in Morphology and Linguistic Typology
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Words and Alternative Basic Units for Linguistic Analysis
Words and alternative basic units for linguistic analysis 1 Words and alternative basic units for linguistic analysis Jens Allwood SCCIIL Interdisciplinary Center, University of Gothenburg A. P. Hendrikse, Department of Linguistics, University of South Africa, Pretoria Elisabeth Ahlsén SCCIIL Interdisciplinary Center, University of Gothenburg Abstract The paper deals with words and possible alternative to words as basic units in linguistic theory, especially in interlinguistic comparison and corpus linguistics. A number of ways of defining the word are discussed and related to the analysis of linguistic corpora and to interlinguistic comparisons between corpora of spoken interaction. Problems associated with words as the basic units and alternatives to the traditional notion of word as a basis for corpus analysis and linguistic comparisons are presented and discussed. 1. What is a word? To some extent, there is an unclear view of what counts as a linguistic word, generally, and in different language types. This paper is an attempt to examine various construals of the concept “word”, in order to see how “words” might best be made use of as units of linguistic comparison. Using intuition, we might say that a word is a basic linguistic unit that is constituted by a combination of content (meaning) and expression, where the expression can be phonetic, orthographic or gestural (deaf sign language). On closer examination, however, it turns out that the notion “word” can be analyzed and specified in several different ways. Below we will consider the following three main ways of trying to analyze and define what a word is: (i) Analysis and definitions building on observation and supposed easy discovery (ii) Analysis and definitions building on manipulability (iii) Analysis and definitions building on abstraction 2. -

ON SOME CATEGORIES for DESCRIBING the SEMOLEXEMIC STRUCTURE by Yoshihiko Ikegami
ON SOME CATEGORIES FOR DESCRIBING THE SEMOLEXEMIC STRUCTURE by Yoshihiko Ikegami 1. A lexeme is the minimum unit that carries meaning. Thus a lexeme can be a "word" as well as an affix (i.e., something smaller than a word) or an idiom (i.e,, something larger than a word). 2. A sememe is a unit of meaning that can be realized as a single lexeme. It is defined as a structure constituted by those features having distinctive functions (i.e., serving to distinguish the sememe in question from other semernes that contrast with it).' A question that arises at this point is whether or not one lexeme always corresponds to just one serneme and no more. Three theoretical positions are foreseeable: (I) one which holds that one lexeme always corresponds to just one sememe and no more, (2) one which holds that one lexeme corresponds to an indefinitely large number of sememes, and (3) one which holds that one lexeme corresponds to a certain limited number of sememes. These three positions wiIl be referred to as (1) the "Grundbedeutung" theory, (2) the "use" theory, and (3) the "polysemy" theory, respectively. The Grundbedeutung theory, however attractive in itself, is to be rejected as unrealistic. Suppose a preliminary analysis has revealed that a lexeme seems to be used sometimes in an "abstract" sense and sometimes in a "concrete" sense. In order to posit a Grundbedeutung under such circumstances, it is to be assumed that there is a still higher level at which "abstract" and "concrete" are neutralized-this is certainly a theoretical possibility, but it seems highly unlikely and unrealistic from a psychological point of view. -

Social & Behavioural Sciences SCTCMG 2019 International
The European Proceedings of Social & Behavioural Sciences EpSBS ISSN: 2357-1330 https://doi.org/10.15405/epsbs.2019.12.04.33 SCTCMG 2019 International Scientific Conference «Social and Cultural Transformations in the Context of Modern Globalism» INTERLEXICOGRAPHY IN TEACHING RUSSIAN AS A SECOND LANGUAGE Elena Baryshnikova (a)*, Dmitrii Kazhuro (b) *Corresponding author (a) Peoples’ Friendship University of Russia, 6, Miklukho-Maklaya str., Moscow, Russia, [email protected], +7 (968) 812-64-61 (b) Peoples’ Friendship University of Russia, 6, Miklukho-Maklaya str., Moscow, Russia, [email protected], +7 (977) 946-74-63 Abstract The paper is concerned with the use of dictionaries of international words by foreign students studying the Russian language. It considers the phenomenon of defining international vocabulary in a dictionary in the context of a scientific field. The authors outline the growth of cross-cultural and cross-language contacts in the history of human civilization. They provide the definition of interlexicography as the method to carry out interlexicological study of international words in various linguistic systems. The paper analyses the issues related to the choice of an illustrative part in the interlexicographic source with regard to qualifying a lexeme as international. There is a background of interlexicographic development based on bi- and multilingual dictionaries of some national languages. The authors analyze the target and goal focus of existing dictionaries of international words, the principles of making up a glossary, its organization and representation in dictionary entries. Through descriptive and comparative methods, along with methodological parameters of linguodidactic representation of the material in line with the educational lexicography, the paper identifies some linguistic and methodological advantages and disadvantages of the existing internationalism dictionaries and their linguodidactic value for teaching Russian as a second language to international students. -

12 Morphology and Lexical Semantics
248 Beth Levin and Malka Rappaport Hovav 12 Morphology and Lexical Semantics BETH LEVIN AND MALKA RAPPAPORT HOVAV The relation between lexical semantics and morphology has not been the subject of much study. This may seem surprising, since a morpheme is often viewed as a minimal Saussurean sign relating form and meaning: it is a concept with a phonologically composed name. On this view, morphology has both a semantic side and a structural side, the latter sometimes called “morphological realization” (Aronoff 1994, Zwicky 1986b). Since morphology is the study of the structure and derivation of complex signs, attention could be focused on the semantic side (the composition of complex concepts) and the structural side (the composition of the complex names for the concepts) and the relation between them. In fact, recent work in morphology has been concerned almost exclusively with the composition of complex names for concepts – that is, with the struc- tural side of morphology. This dissociation of “form” from “meaning” was foreshadowed by Aronoff’s (1976) demonstration that morphemes are not necessarily associated with a constant meaning – or any meaning at all – and that their nature is basically structural. Although in early generative treat- ments of word formation, semantic operations accompanied formal morpho- logical operations (as in Aronoff’s Word Formation Rules), many subsequent generative theories of morphology, following Lieber (1980), explicitly dissoci- ate the lexical semantic operations of composition from the formal structural -

CS474 Natural Language Processing Semantic Analysis Caveats Introduction to Lexical Semantics
CS474 Natural Language Processing Semantic analysis Last class Assigning meanings to linguistic utterances – History Compositional semantics: we can derive the – Tiny intro to semantic analysis meaning of the whole sentence from the meanings of the parts. Next lectures – Max ate a green apple. – Word sense disambiguation Relies on knowing: » Background from linguistics – the meaning of individual words Lexical semantics – how the meanings of individual words combine to form » On-line resources the meaning of groups of words » Computational approaches [next class] – how it all fits in with syntactic analysis Caveats Introduction to lexical semantics Problems with a compositional approach Lexical semantics is the study of – the systematic meaning-related connections among – a former congressman words and – a toy elephant – the internal meaning-related structure of each word – kicked the bucket Lexeme – an individual entry in the lexicon – a pairing of a particular orthographic and phonological form with some form of symbolic meaning representation Sense: the lexeme’s meaning component Lexicon: a finite list of lexemes Lexical semantic relations: Dictionary entries homonymy right adj. located nearer the right hand esp. Homonyms: words that have the same form and unrelated being on the right when facing the same direction meanings – Instead, a bank1 can hold the investments in a custodial account as the observer. in the client’s name. – But as agriculture burgeons on the east bank2, the river will shrink left adj. located nearer to this side of the body even more. than the right. Homophones: distinct lexemes with a shared red n. the color of blood or a ruby. pronunciation – E.g. -

Studies in the Linguistic Sciences
UNIVERSITY OF ILLINOIS Llb'RARY AT URBANA-CHAMPAIGN MODERN LANGUAGE NOTICE: Return or renew all Library Materialsl The Minimum Fee (or each Lost Book is $50.00. The person charging this material is responsible for its return to the library from which it was withdrawn on or before the Latest Date stamped below. Theft, mutilation, and underlining of books are reasons for discipli- nary action and may result in dismissal from the University. To renew call Telephone Center, 333-8400 UNIVERSITY OF ILLINOIS LIBRARY AT URBANA-CHAMPAIGN ModeriJLanp & Lb Library ^rn 425 333-0076 L161—O-I096 Che Linguistic Sciences PAPERS IN GENERAL LINGUISTICS ANTHONY BRITTI Quantifier Repositioning SUSAN MEREDITH BURT Remarks on German Nominalization CHIN-CHUAN CHENG AND CHARLES KISSEBERTH Ikorovere Makua Tonology (Part 1) PETER COLE AND GABRIELLA HERMON Subject to Object Raising in an Est Framework: Evidence from Quechua RICHARD CURETON The Inclusion Constraint: Description and Explanation ALICE DAVISON Some Mysteries of Subordination CHARLES A. FERGUSON AND APIA DIL The Sociolinguistic Valiable (s) in Bengali: A Sound Change in Progress GABRIELLA HERMON Rule Ordering Versus Globality: Evidencefrom the Inversion Construction CHIN-W. KIM Neutralization in Korean Revisited DAVID ODDEN Principles of Stress Assignment: A Crosslinguistic View PAULA CHEN ROHRBACH The Acquisition of Chinese by Adult English Speakers: An Error Analysis MAURICE K.S. WONG Origin of the High Rising Changed Tone in Cantonese SORANEE WONGBIASAJ On the Passive in Thai Department of Linguistics University of Illinois^-^ STUDIES IN THE LINGUISTIC SCIENCES PUBLICATION OF THE DEPARTMENT OF LINGUISTICS UNIVERSITY OF ILLINOIS AT URBANA-CHAMPAIGN EDITORS: Charles W. Kisseberth, Braj B. -

Morphemes by Kirsten Mills Student, University of North Carolina at Pembroke, 1998
Morphemes by Kirsten Mills http://www.uncp.edu/home/canada/work/caneng/morpheme.htm Student, University of North Carolina at Pembroke, 1998 Introduction Morphemes are what make up words. Often, morphemes are thought of as words but that is not always true. Some single morphemes are words while other words have two or more morphemes within them. Morphemes are also thought of as syllables but this is incorrect. Many words have two or more syllables but only one morpheme. Banana, apple, papaya, and nanny are just a few examples. On the other hand, many words have two morphemes and only one syllable; examples include cats, runs, and barked. Definitions morpheme: a combination of sounds that have a meaning. A morpheme does not necessarily have to be a word. Example: the word cats has two morphemes. Cat is a morpheme, and s is a morpheme. Every morpheme is either a base or an affix. An affix can be either a prefix or a suffix. Cat is the base morpheme, and s is a suffix. affix: a morpheme that comes at the beginning (prefix) or the ending (suffix) of a base morpheme. Note: An affix usually is a morpheme that cannot stand alone. Examples: -ful, -ly, -ity, -ness. A few exceptions are able, like, and less. base: a morpheme that gives a word its meaning. The base morpheme cat gives the word cats its meaning: a particular type of animal. prefix: an affix that comes before a base morpheme. The in in the word inspect is a prefix. suffix: an affix that comes after a base morpheme. -

From Phoneme to Morpheme Author(S): Zellig S
Linguistic Society of America From Phoneme to Morpheme Author(s): Zellig S. Harris Source: Language, Vol. 31, No. 2 (Apr. - Jun., 1955), pp. 190-222 Published by: Linguistic Society of America Stable URL: http://www.jstor.org/stable/411036 Accessed: 09/02/2009 08:03 Your use of the JSTOR archive indicates your acceptance of JSTOR's Terms and Conditions of Use, available at http://www.jstor.org/page/info/about/policies/terms.jsp. JSTOR's Terms and Conditions of Use provides, in part, that unless you have obtained prior permission, you may not download an entire issue of a journal or multiple copies of articles, and you may use content in the JSTOR archive only for your personal, non-commercial use. Please contact the publisher regarding any further use of this work. Publisher contact information may be obtained at http://www.jstor.org/action/showPublisher?publisherCode=lsa. Each copy of any part of a JSTOR transmission must contain the same copyright notice that appears on the screen or printed page of such transmission. JSTOR is a not-for-profit organization founded in 1995 to build trusted digital archives for scholarship. We work with the scholarly community to preserve their work and the materials they rely upon, and to build a common research platform that promotes the discovery and use of these resources. For more information about JSTOR, please contact [email protected]. Linguistic Society of America is collaborating with JSTOR to digitize, preserve and extend access to Language. http://www.jstor.org FROM PHONEME TO MORPHEME ZELLIG S. HARRIS University of Pennsylvania 0.1. -
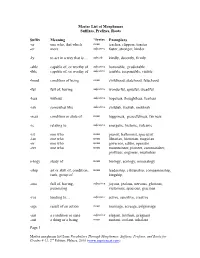
Morpheme Master List
Master List of Morphemes Suffixes, Prefixes, Roots Suffix Meaning *Syntax Exemplars -er one who, that which noun teacher, clippers, toaster -er more adjective faster, stronger, kinder -ly to act in a way that is… adverb kindly, decently, firmly -able capable of, or worthy of adjective honorable, predictable -ible capable of, or worthy of adjective terrible, responsible, visible -hood condition of being noun childhood, statehood, falsehood -ful full of, having adjective wonderful, spiteful, dreadful -less without adjective hopeless, thoughtless, fearless -ish somewhat like adjective childish, foolish, snobbish -ness condition or state of noun happiness, peacefulness, fairness -ic relating to adjective energetic, historic, volcanic -ist one who noun pianist, balloonist, specialist -ian one who noun librarian, historian, magician -or one who noun governor, editor, operator -eer one who noun mountaineer, pioneer, commandeer, profiteer, engineer, musketeer o-logy study of noun biology, ecology, mineralogy -ship art or skill of, condition, noun leadership, citizenship, companionship, rank, group of kingship -ous full of, having, adjective joyous, jealous, nervous, glorious, possessing victorious, spacious, gracious -ive tending to… adjective active, sensitive, creative -age result of an action noun marriage, acreage, pilgrimage -ant a condition or state adjective elegant, brilliant, pregnant -ant a thing or a being noun mutant, coolant, inhalant Page 1 Master morpheme list from Vocabulary Through Morphemes: Suffixes, Prefixes, and Roots for -

COMMON and DIFFERENT ASPECTS in a SET of COMMENTARIES in DICTIONARIES and SEMANTIC TAGS Akhmedova Dildora Bakhodirovna a Teacher
International Scientific Forum on language, literature, translation, literary criticism: international scientific-practical conference on modern approaches and perspectives. Web: https://iejrd.com/ COMMON AND DIFFERENT ASPECTS IN A SET OF COMMENTARIES IN DICTIONARIES AND SEMANTIC TAGS Akhmedova Dildora Bakhodirovna A teacher, BSU Hamidova Iroda Olimovna A student, BSU Annotation: This article discusses dictionaries that can be a source of information for the language corpus, the structure of the dictionary commentary, and the possibilities of this information in tagging corpus units. Key words:corpus linguistics, lexicography, lexical units, semantic tagging, annotated dictionary, general vocabulary, limited vocabulary, illustrative example. I.Introduction Corpus linguistics is closely related to lexicography because the linguistic unit in the dictionary, whose interpretation serves as a linguo-lexicographic supply for tagging corpus units. Digitization of the text of existing dictionaries in the Uzbek language is the first step in linking the dictionary with the corpus. Uzbek lexicography has come a long way, has a rich treasure that serves as a material for the corps. According to Professor E. Begmatov, systematicity in the lexicon is not as obvious as in other levels of language. Lexical units are more numerous than phonemes, morphemes in terms of quantity, and have the property of periodic instability. Therefore, it is not possible to identify and study the lexicon on a scale. Today, world linguistics has begun to solve this problem with the help of language corpora and has already achieved results. Qualitative and quantitative inventory of vocabulary, the possibility of comprehensive research has expanded. The main source for semantic tagging of language units is the explanatory dictionary of the Uzbek language. -

Stylistics Lecture 3 Morphemes & Semantics
Stylistics Lecture 3 Morphemes & Semantics MOAZZAM A L I MALIK ASSISTANT PROFESSOR UNIVERSITY OF GUJRAT Words & Morphemes Words are potentially complex units, composed of even more basic units, called morphemes. A morpheme is the smallest part of a word that has grammatical function or meaning. we will designate them in braces { }. For example, played, plays, playing can all be analyzed into the morphemes {play} + {-ed}, {-s}, and {-ing}, respectively. Basic Concepts in Morphology The English plural morpheme {-s} can be expressed by three different but clearly related phonemic forms /iz/, /z/, and /s/. These are the variant phonological realizations of plural morpheme and hence are known as allomorphs. Morph is a minimal meaningful form, regardless of whether it is a morpheme or allomorph. Basic Concepts in Morphology Affixes are classified according to whether they are attached before or after the form to which they are added. A root morpheme is the basic form to which other morphemes are attached In moveable, {-able} is attached to {move}, which we’ve determined is the word’s root. However, {im- } is attached to moveable, not to {move} (there is no word immove), but moveable is not a root. Expressions to which affixes are attached are called bases. While roots may be bases, bases are not always roots. Basic Concepts in Morphology Words that have meaning by themselves—boy, food, door—are called lexical morphemes. Those words that function to specify the relationship between one lexical morpheme and another—words like at, in, on, -ed, -s— are called grammatical morphemes. Those morphemes that can stand alone as words are called free morphemes (e.g., boy, food, in, on). -

Corpus Linguistic Analysis of Fear-Factor Lexemes of Selected Online Newspaper Headlines on Coronavirus Pandemic
www.idosr.org Anyanwu and Udoh ©IDOSR PUBLICATIONS International Digital Organization for Scientific Research. ISSN: 2550-7958. IDOSR JOURNAL OF COMMUNICATION AND ENGLISH 5(1) 76-83, 2020. Corpus Linguistic Analysis of Fear-Factor Lexemes of Selected Online Newspaper Headlines on Coronavirus Pandemic Esther Chikaodi Anyanwu and Victoria Chinwe Udoh Department of English Language and Literature, Nnamdi Azikiwe University, Awka. Nigeria ABSTRACT As the world expanded, so too did the spread of diseases and their vocabulary. The spread of the corona virus disease has altered the lives of billions of people, and has equally ushered in a new vocabulary to the general populace encompassing specialist terms from the fields of epidemiology and medicine. The aim of the study was to identify those lexemes that relate to corona virus (Covid-19) and which have dominated the language discourse of Nigerians. It has been observed that most of such lexemes project fear and death of human and economic resources. The researcher randomly collected data from online Nigerian newspaper headlines that were centred on corona virus related issues, and analyzed such data using the theoretical framework of corpus linguistics. The researcher identified those linguistic terms which are associated with Covid-19 as they have overwhelmingly dominated global discourse. The study revealed that so many lexemes that relate to Covid-19 project fear, disaster, confusion, restlessness, panic and death. The researcher was able to spot new words and senses associated with the pandemic and assessed the frequency of their usage. She concluded by reiterating that the lexical wealth of every language is not limited, but rather, there are lots of various lexical units created by different professions and epidemiology and medicine are not exceptions.