Development and Performance of the LENA Automatic Autism Screen
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

The Effects and Feasibility of Using Tiered Instruction to Increase Conversational Turn Taking for Preschoolers with and Without Disabilities
THE EFFECTS AND FEASIBILITY OF USING TIERED INSTRUCTION TO INCREASE CONVERSATIONAL TURN TAKING FOR PRESCHOOLERS WITH AND WITHOUT DISABILITIES A dissertation submitted to the Kent State University College and Graduate School of Education, Health, and Human Services in partial fulfillment of the requirements for the degree of Doctor of Philosophy By Sandra Hess Robbins May 2013 © Copyright, 2013 by Sandra Hess Robbins All Rights Reserved ii A dissertation written by Sandra Hess Robbins B.S.Ed., University of Wisconsin, Oshkosh, 2002 M.Ed., Kent State University, 2006 Ph.D., Kent State University, 2013 Approved by ____________________, Co-director, Doctoral Dissertation Committee Kristie Pretti-Frontcak ____________________, Co-director, Doctoral Dissertation Committee Sanna Harjusola-Webb ____________________, Member, Doctoral Dissertation Committee Christine Balan ____________________, Member, Doctoral Dissertation Committee Richard Cowan Accepted by ____________________, Director, School of Lifespan Development and Educational Mary Dellman-Jenkins Sciences ____________________, Dean, College of Education, Health, and Human Services Daniel F. Mahony iii ROBBINS, SANDRA HESS, Ph.D., May 2013 Lifespan Development and Educational Sciences THE EFFECTS AND FEASIBILITY OF USING TIERED INSTRUCTION TO INCREASE CONVERSATIONAL TURN TAKING FOR PRESCHOOLERS WITH AND WITHOUT DISABILITIES (282 pp.) Co-Directors of Dissertation: Kristie Pretti-Frontczak, Ph.D. Sanna Harjusola-Webb, Ph.D. The purpose of the study was to examine the effectiveness and feasibility of using tiered instruction to increase the frequency of conversational turn taking (CTT) among preschoolers with and without disabilities in an inclusive setting. Three CTT interventions (Universal Design for Learning, Peer Mediated Instruction, and Milieu Teaching) were organized on a hierarchy of intensity and implemented in an additive manner. -

Women with High Functioning ASD: Relationships and Sexual Health
Claremont Colleges Scholarship @ Claremont CMC Senior Theses CMC Student Scholarship 2020 Women with High Functioning ASD: Relationships and Sexual Health Isabelle Taylor Follow this and additional works at: https://scholarship.claremont.edu/cmc_theses Part of the Developmental Psychology Commons Recommended Citation Taylor, Isabelle, "Women with High Functioning ASD: Relationships and Sexual Health" (2020). CMC Senior Theses. 2553. https://scholarship.claremont.edu/cmc_theses/2553 This Open Access Senior Thesis is brought to you by Scholarship@Claremont. It has been accepted for inclusion in this collection by an authorized administrator. For more information, please contact [email protected]. Claremont McKenna College Women with High Functioning ASD: Relationships and Sexual Health A Literature Review and Proposed Workshop Manual Submitted to Professor Caitlyn Gumaer By Isabelle Taylor for Senior Thesis 2020 November 30 Table of Contents Author’s Note.................................................................................................................................. 1 Abstract........................................................................................................................................... 2 Literature Review.................................................................................................................... 3 - 38 Symptoms and Diagnosis.............................................................................................. 3 - 7 Gender Differences..................................................................................................... -
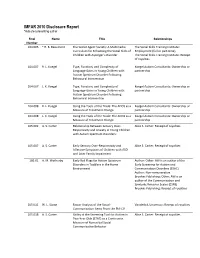
IMFAR 2010 Disclosure Report *Indicates Presenting Author
IMFAR 2010 Disclosure Report *indicates presenting author Final Name Title Relationships Number 104.005 * R. B. Beaumont The Secret Agent Society: A Multimedia The Social Skills Training Institute: Curriculum for Enhancing the Social Skills of Employment (full or part-time) Children with Asperger's Disorder The Social Skills Training Institute: Receipt of royalties 104.007 R. L. Koegel Type, Function, and Complexity of Koegel Autism Consultants: Ownership or Language Gains in Young Children with partnership Autism Spectrum Disorder Following Behavioral Intervention 104.007 L. K. Koegel Type, Function, and Complexity of Koegel Autism Consultants: Ownership or Language Gains in Young Children with partnership Autism Spectrum Disorder Following Behavioral Intervention 104.008 R. L. Koegel Using the Tools of the Trade: The ADOS as a Koegel Autism Consultants: Ownership or Measure of Treatment Change partnership 104.008 L. K. Koegel Using the Tools of the Trade: The ADOS as a Koegel Autism Consultants: Ownership or Measure of Treatment Change partnership 105.002 A. S. Carter Relationship Between Sensory Over- Alice S. Carter: Receipt of royalties Responsivity and Anxiety in Young Children with Autism Spectrum Disorders: 105.007 A. S. Carter Early Sensory Over-Responsivity and Alice S. Carter: Receipt of royalties Affective Symptoms of Children with ASD and Later Family Impairment 105.01 A. M. Wetherby Early Red Flags for Autism Spectrum Author: Other: AW is an author of the Disorders in Toddlers in the Home Early Screening for Autism and Environment Communication Disorders (ESAC) Author: Non-remunerative Brookes Publishing: Other: AW is an author of the Communication and Symbolic Behavior Scales (CSBS) Brookes Publishing: Receipt of royalties 105.011 W. -

(!Congress of Tbe ~Niteb ~Tates ~A~Btngton, Tjb(( 20510
(!Congress of tbe ~niteb ~tates ~a~btngton, tJB(( 20510 August 1, 2016 The Honorable Dr. John King Secretary of Education U.S. Department of Education 400 Maryland Ave., S.W. Washington, DC 20202 Attn: Meredith Miller Re: Notice ofProposed Rulemaking Docket ID ED-2016-0ESE-0032, Elementary and Secondary Education Act of 1965, as Amended by the Every Student Succeeds Act Accountability and State Plans Dear Secretary King: In negotiating the Every Student Succeeds Act (ESSA) with our colleagues, we fought to preserve the Department of Education's (Department) full regulatory authority to promulgate rules and issue guidance. We applaud the Department's notice of proposed rulemaking (NPRM) on 34 CFR parts 200 and 299 for balancing ESSA' s strong and clearly articulated federal guardrails with the new law's flexibility for state and local decision-making. The Department's unique role in upholding the civil rights legacy of this law is critical to ensure implementation honors Congressional intent that states and local educational agencies sufficiently support improving outcomes for the nation's disadvantaged students, including through improving equity of educational opportunity. While Congress replaced much of No Child Left Behind (NCLB) with new statutory requirements in ESSA, the new law maintains the historic and bipartisan focus of the Elementary and Secondary Education Act (ESEA) on improving educational outcomes for our nation's disadvantaged students, including low-income students, students of color, students with disabilities, and English learners. In putting forth the proposed regulations, the Department employed its regulatory authority to articulate parameters that will empower states and school districts to use the new flexibility that ESSA affords. -

Infant Brain Imaging Study Network an NIH Autism Centers of Excellence (ACE) Network: IACC Meeting Washington, D.C. April 2011
Infant Brain Imaging Study Network an NIH Autism Centers of Excellence (ACE) Network University of North Carolina University of Washington Washington University in St. Louis Children’s Hospital of Philadelphia Montreal Neurological Institute University of Utah University of Alberta Principal Investigator: Joe Piven Carolina Institute for Developmental Disabilities University of North Carolina IACC Meeting Washington, D.C. April 2011 IBIS (Infant Brain Imaging Study) Network NIH Autism Center of Excellence (www.ibis-network.org ) “A Longitudinal MRI Study of Infants at Risk for Autism” Infant Siblings of 6 months 12 months 24 months Older Autistic Children Rationale for the IBIS Network: (1) onset of brain overgrowth and (2) onset of autistic behavior both appear to occur in the latter part of the first year of life in autistic individuals Studies Reporting Increased Brain Volume (5-10%) in Autism MRI Studies Brain Volume Subject Age Piven et al. (1992) increased mid-sagittal area 18 - 53 yrs Piven et al (1995) increased total brain volume 14 – 29 yrs Hazlett et al (2005) increased total brain volume (N=51) 2 yrs Courchesne et al (2001) increased cerebral. gray and white 2 – 4 yrs only Sparks et al (2002) increased total cerebral 3-4 yrs Aylward et al (2002) increased TBV (HFA) under 12 yrs Lotspeich et al (2004) increased cerebral gray (N=52) 7 – 18 yr Herbert et al (2004) increased (radiate) white matter (N=13) ~ 9 yrs Palmen et al (2005) increased TBV, cerebral gray (N=21) 7 – 15 yrs Schultz et al (unpub) increased TBV, GM, WM (N=117) 7-36 yrs Hyde et al, (2008) increased gray vol (VBM + cortical thick) young adults Freitag et al, (2009) increased TBV, GM and WM (N=15) HFA adol/adult Hardan et al, (2006) increased TBV, gray/cortical thick 17 HFA children Schuman et al (2010) increased cerebral gray and white 2-5 yrs Increased Brain Volume Noted by Two Years of Age MRI Studies Brain Volume Subject Age Piven et al. -

Researchers Seek Patterns in the Sounds of Autism
Spectrum | Autism Research News https://www.spectrumnews.org NEWS Researchers seek patterns in the sounds of autism BY KELLY RAE CHI 15 MARCH 2010 1 / 7 Spectrum | Autism Research News https://www.spectrumnews.org Not just babble: Researchers are analyzing the grunts, squeals and early chatter of children with autism. 2 / 7 Spectrum | Autism Research News https://www.spectrumnews.org Scientists have created machines to detect distinctive speech patterns in children with autism that go unnoticed by the naked ear. A Colorado-based nonprofit, LENA Foundation, is marketing one such system as a screen for autism in toddlers. Several academic research groups are also dissecting the complex vocalizations of children with the disorder. Because the LENA screen hasn't been rigorously tested in independent studies, some experts are skeptical that the technology can reliably detect autism-specific patterns. But its creators predict that it will soon be ready for the clinic. "For the last several years, I've been quite persuaded that this will become a part of the standard screening and diagnosis not just in autism but in other clinical domains," says D. Kimbrough Oller, a scientific adviser for the LENA Foundation and professor of audiology and speech-language pathology at University of Memphis in Tennessee. Even if the system is not ready for the clinic, some researchers say it is useful for studying speech development. "I think that as a scientific tool, [the LENA system] really does move the field forward," says Catherine Lord, director of the University of Michigan Autism and Communication Disorders Center. Since the 1960s, several studies have identified vocal differences in people with autism. -

LENA Computerized Automatic Analysis of Speech Development from Birth to Three
The 2018 Conference on Computational Linguistics and Speech Processing ROCLING 2018, pp. 158-168 ©The Association for Computational Linguistics and Chinese Language Processing LENA computerized automatic analysis of speech development from birth to three Li-Mei Chen National Cheng Kung University, [email protected] D. Kimbrough Oller University of Memphis, USA, [email protected] Chia-Cheng Lee University of Wisconsin-Eau Claire, USA, [email protected] Chin-Ting Jimbo Liu National Chin-Yi University of Technology, [email protected] Abstract This study investigated the relationship between the linguistic input children receive and the number of children’s vocalizations by using computerized LENA (Language Environment Analysis) system software which is able to collect and analyze the data automatically, instantly, and objectively. Data from three children (two boys and one girl) at ages of 10, 20, and 30 months were analyzed. The results indicated that: 1) child vocalizations (CV) and child-caregiver conversational turns (CT) increased with time while adult word counts (AWC) children overheard in the background decreased; 2) CT is highly correlated with CV. LENA automatic device can substantially shorten the time of data analysis in the study of child language, and provide preliminary results for further analysis. 1. Introduction This paper explores the relationship between children’s vocalization and the linguistic input they received by using LENA (Language Environment Analysis https://www.lena.org/), a computer system of automatic, objective and inexpensive device that collects and analyzes data for up to 16-hour-long recordings. It has been shown that the audio input children exposed to might largely affect their vocalizations [1], [2], [3], which in turn serve as an essential indicator of their later language development [4], [5]. -

A Pilot Quantitative Evaluation of Early Life Language Development in Fragile X Syndrome
brain sciences Article A Pilot Quantitative Evaluation of Early Life Language Development in Fragile X Syndrome Debra L. Reisinger 1 , Rebecca C. Shaffer 1,2, Ernest V. Pedapati 3,4,5, Kelli C. Dominick 3,5 and Craig A. Erickson 3,5,* 1 Division of Developmental and Behavioral Pediatrics, Cincinnati Children’s Hospital Medical Center, Cincinnati, OH 45229, USA; [email protected] (D.L.R.); [email protected] (R.C.S.) 2 Department of Pediatrics, University of Cincinnati College of Medicine, Cincinnati, OH 45267, USA 3 Division of Child and Adolescent Psychiatry, Cincinnati Children’s Hospital Medical Center, Cincinnati, OH 45229, USA; [email protected] (E.V.P.); [email protected] (K.C.D.) 4 Division of Child Neurology, Cincinnati Children’s Hospital Medical Center, Cincinnati, OH 45229, USA 5 Department of Psychiatry and Behavioral Neuroscience, University of Cincinnati College of Medicine, Cincinnati, OH 45267, USA * Correspondence: [email protected]; Tel.: +1-513-636-6265 Received: 15 December 2018; Accepted: 24 January 2019; Published: 29 January 2019 Abstract: Language delay and communication deficits are a core characteristic of the fragile X syndrome (FXS) phenotype. To date, the literature examining early language development in FXS is limited potentially due to barriers in language assessment in very young children. The present study is one of the first to examine early language development through vocal production and the language learning environment in infants and toddlers with FXS utilizing an automated vocal analysis system. Child vocalizations, conversational turns, and adult word counts in the home environment were collected and analyzed in a group of nine infants and toddlers with FXS and compared to a typically developing (TD) normative sample. -

Early Vocal Development in Tuberous Sclerosis Complex
medRxiv preprint doi: https://doi.org/10.1101/2021.01.06.21249364; this version posted January 8, 2021. The copyright holder for this preprint (which was not certified by peer review) is the author/funder, who has granted medRxiv a license to display the preprint in perpetuity. All rights reserved. No reuse allowed without permission. This manuscript is in submission for publication. It has not yet been peer-reviewed. Early Vocal Development in Tuberous Sclerosis Complex Tanjala T. Gipson, MD, Gordon Ramsay, PhD, Ellen Ellison, Edina Bene, PhD, Helen L. Long, PhD, & D. Kimbrough Oller, PhD Abstract Objective: To determine whether entry into the canonical stage, canonical babbling ratios (CBR) and the level of volubility (vocal measures) are delayed in infants with Tuberous Sclerosis Complex (TSC), we completed human coding of their vocalizations at 12 months and compared the results to typically developing infants with no clinical features (TD/NCF). Methods: We randomly selected videos from 40 infants with TSC from the TACERN database. All 78 videos were coded in real-time in AACT (Action Analysis, Coding and Training). Results: Entry into the canonical stage was delayed in the great majority of the infants with TSC. The CBR for the TD/NCF infants was significantly higher than for the infants with TSC (TD/NCF mean = .346, SE = .19; TSC mean = .117, SE = .023). Volubility level in infants with TSC was less than half that of TD/NCF infants (TD/NCF mean = 9.82, SE = 5.78; TSC mean = 3.99, SE = 2.16). CBR and volubility were also lower in TSC infants than in TD/NCF infants recorded all-day at home. -

IMFAR-Prgm-Bk2011:San Diego.Qxd
International Meeting for Autism Research May 12 -14, 2011 Manchester Grand Hyatt n San Diego, California www.autism-insar.org PROGRAM BOOK IMFAR WELCOME IMFAR is celebrating its 10th anniversary and returning to the site of the first conference, San Diego! We are delighted to welcome everyone to what we feel is our best meeting yet. We believe we have planned a very exciting and informative three days covering the very latest in research focusing on autism. This year the Scientific Program Committee reviewed over 1,000 abstracts from around the world and has put together a solid meeting. As Scientific Program Chair, Dan Geschwind, notes in his remarks, there are a few new events planned in addition to several of IMFAR’s popular features including the Invited Educational Symposia, exceptional keynote speakers, oral sessions, poster presentations, Lifetime Achievement Award and Special Interest Group meetings. We also have a few special surprises planned for the main reception following the presentation of the Lifetime Achievement Award so do not miss it. Planning a meeting like this requires the efforts of some very special people and I would like to acknowledge those who contributed so much of their time and effort to INSAR and the IMFAR event. Along these lines I would like to thank the INSAR Board, the Scientific Program Committee, and the many abstract reviewers who helped ensure the inclusion of the best in autism research. A special thank you goes to Joe Dymek of ConferenceDirect whose invaluable assistance made the job of planning the meeting a pleasure. I would like also to personally acknowledge the members of the Meeting Planning Committee who have worked very hard to make the 2011 IMFAR experience special. -

9Th Annual International Meeting for Autism Research (IMFAR)
99thth AAnnualnnual IInternationalnternational MMeetingeeting FForor AAutismutism RResearchesearch ((IMFAR)IMFAR) PPhiladelphiahiladelphia • MMayay 220-22,0-22, 22010010 Program Thursday May 20th 6:30-5:00P Registration (Registration Grand Ballroom Pre-Function Lvl 5) 7:15-8:15A Coffee and Pastries (Grand Ballroom Pre-Function Lvl 5) 8:15-8:30A Greetings from the IMFAR organizers (Grand Ballroom AF Lvl 5) 8:30-9:30A Keynote: Jacqueline Crawley: “Mouse Models of Autism to Discover Causes and Develop Treatments” 8:00-1:00P Poster & Exhibits 9:30-10:00A Break (Franklin Hall B Lvl 4) (Franklin Hall B 10:00-12:00P IES: Neuro-Imaging Genetics (Grand Ballroom F Lvl 5) Lvl 4) Oral Session: Cognition 1 Oral Session: Epidemiology 1 (Grand Ballroom AB Oral Session: Treatment 1 Social Function, 10:00-12:00P (Grand Ballroom CD Lvl 5) Lvl 5) (Grand Ballroom E Lvl 5) Communication, Sensory Systems, 12:00-1:15P Lunch Break Developmental SIG: EEG & MEG Stages, Language, SIG: Postmortem Brain Research SIG: Sleep and Autism 12:15-1:15P (Grand Ballroom AB Lvl 5) Imitation & Play (Grand Ballroom CD Lvl 5) (Grand Ballroom E Lvl 5) 1:30-3:30P IES: The Ethics of Communicating Scientifi c Risk (Grand Ballroom F Lvl 5) 1:00-5:30P Posters Oral Session: Communication & Language Oral Session: Neurophysiology (Grand Ballroom AB Oral Session: Brain Imaging 1 (Grand Ballroom & Exhibits 1:30-3:30P (Grand Ballroom CD Lvl 5) Lvl 5) E Lvl 5) (Franklin Hall B Lvl 4) 3:30-4:00P Break (Franklin Hall B Lvl 4) Social Function, 4:00-4:30P Tom Insel: IACC Update: (Grand Ballroom AF Lvl 5) Developmental Stages, Treatment, Lifetime Achievement Award and Presentations (Grand Ballroom AF Lvl 5) 4:30-6:00P Clinical Phenotype & Edward R. -

Charitable Organizations Eligible for Voluntary Contributions from Tax Refunds As of 11:59 PM, Aug. 30, 2020. Colorado Charities Organized by County
Charitable Organizations Eligible for Voluntary Contributions from Tax Refunds as of 11:59 PM, Aug. 30, 2020. Colorado charities organized by county. Adams County Principal Name of Organization Registration Number A CHILD'S TOUCH 20083006424 A WORLD AWARE, INC. D.B.A. AWA 20083005830 ADAMS 12 FIVE STAR EDUCATION FOUNDATION 20093011502 ADAMS 14 EDUCATION FOUNDATION 20023002971 ADAMS COUNTY EDUCATION CONSORTIUM 20103003023 ADAMS COUNTY FOUNDATION, INC. 20083005695 ADAMS COUNTY YOUTH INITIATIVE, INC. 20143029109 ALLIANCE OF INTERNATIONAL AROMATHERAPISTS 20093007611 AMERICAN LEGION POST 22 20043006901 AMI OF ADAMS COUNTY INC 20093008255 AURORA COMMUNITY CONNECTION FAMILY RESOURCE CENTER 20103032479 BENNETT ELEMENTARY PTSA 20113029174 BETHEL FELLOWSHIP INTERNATIONAL 20093008143 BIRTHDAY SMILES 20123007969 BOLTZ WRESTLING CLUB 20123015119 BREAD OF LIFE AFRICAN MINISTRIES 20093007103 BRIGHTON BULLFROGS SWIM TEAM INC. 20083005395 BRIGHTON COMMUNITY HOSPITAL ASSOCIATION 20063006812 BRIGHTON UNITED SENIOR CITIZEN CENTER, INC. 20083005232 BRIGHTON WRESTLING CLUB 20113023802 BRINGING GOOD NEWS AND GOOD THINGS, INC. 20083005801 BROOMFIELD BLITZ FOOTBALL CLUB, INC. 20103029358 CASA OF ADAMS & BROOMFIELD COUNTIES 20033006284 CEDARWOOD CHRISTIAN ACADEMY 20083005687 CHILDREN'S HOSPITAL COLORADO FOUNDATION 20033011082 CLINICA COLORADO 20113019445 COLORADO ATHLETIC DIRECTORS ASSOCIATION 20093008789 COLORADO BEAGLE RESCUE 20123039623 COLORADO CANINE RESCUE 20093002438 COLORADO ELECTRIC EDUCATIONAL INSTITUTE 20023003622 COLORADO JUDICIAL INSTITUTE 20033001981