Flash Team Template
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Wind Rose Data Comes in the Form >200,000 Wind Rose Images
Making Wind Speed and Direction Maps Rich Stromberg Alaska Energy Authority [email protected]/907-771-3053 6/30/2011 Wind Direction Maps 1 Wind rose data comes in the form of >200,000 wind rose images across Alaska 6/30/2011 Wind Direction Maps 2 Wind rose data is quantified in very large Excel™ spreadsheets for each region of the state • Fields: X Y X_1 Y_1 FILE FREQ1 FREQ2 FREQ3 FREQ4 FREQ5 FREQ6 FREQ7 FREQ8 FREQ9 FREQ10 FREQ11 FREQ12 FREQ13 FREQ14 FREQ15 FREQ16 SPEED1 SPEED2 SPEED3 SPEED4 SPEED5 SPEED6 SPEED7 SPEED8 SPEED9 SPEED10 SPEED11 SPEED12 SPEED13 SPEED14 SPEED15 SPEED16 POWER1 POWER2 POWER3 POWER4 POWER5 POWER6 POWER7 POWER8 POWER9 POWER10 POWER11 POWER12 POWER13 POWER14 POWER15 POWER16 WEIBC1 WEIBC2 WEIBC3 WEIBC4 WEIBC5 WEIBC6 WEIBC7 WEIBC8 WEIBC9 WEIBC10 WEIBC11 WEIBC12 WEIBC13 WEIBC14 WEIBC15 WEIBC16 WEIBK1 WEIBK2 WEIBK3 WEIBK4 WEIBK5 WEIBK6 WEIBK7 WEIBK8 WEIBK9 WEIBK10 WEIBK11 WEIBK12 WEIBK13 WEIBK14 WEIBK15 WEIBK16 6/30/2011 Wind Direction Maps 3 Data set is thinned down to wind power density • Fields: X Y • POWER1 POWER2 POWER3 POWER4 POWER5 POWER6 POWER7 POWER8 POWER9 POWER10 POWER11 POWER12 POWER13 POWER14 POWER15 POWER16 • Power1 is the wind power density coming from the north (0 degrees). Power 2 is wind power from 22.5 deg.,…Power 9 is south (180 deg.), etc… 6/30/2011 Wind Direction Maps 4 Spreadsheet calculations X Y POWER1 POWER2 POWER3 POWER4 POWER5 POWER6 POWER7 POWER8 POWER9 POWER10 POWER11 POWER12 POWER13 POWER14 POWER15 POWER16 Max Wind Dir Prim 2nd Wind Dir Sec -132.7365 54.4833 0.643 0.767 1.911 4.083 -

18-447 Computer Architecture Lecture 6: Multi-Cycle and Microprogrammed Microarchitectures
18-447 Computer Architecture Lecture 6: Multi-Cycle and Microprogrammed Microarchitectures Prof. Onur Mutlu Carnegie Mellon University Spring 2015, 1/28/2015 Agenda for Today & Next Few Lectures n Single-cycle Microarchitectures n Multi-cycle and Microprogrammed Microarchitectures n Pipelining n Issues in Pipelining: Control & Data Dependence Handling, State Maintenance and Recovery, … n Out-of-Order Execution n Issues in OoO Execution: Load-Store Handling, … 2 Reminder on Assignments n Lab 2 due next Friday (Feb 6) q Start early! n HW 1 due today n HW 2 out n Remember that all is for your benefit q Homeworks, especially so q All assignments can take time, but the goal is for you to learn very well 3 Lab 1 Grades 25 20 15 10 5 Number of Students 0 30 40 50 60 70 80 90 100 n Mean: 88.0 n Median: 96.0 n Standard Deviation: 16.9 4 Extra Credit for Lab Assignment 2 n Complete your normal (single-cycle) implementation first, and get it checked off in lab. n Then, implement the MIPS core using a microcoded approach similar to what we will discuss in class. n We are not specifying any particular details of the microcode format or the microarchitecture; you can be creative. n For the extra credit, the microcoded implementation should execute the same programs that your ordinary implementation does, and you should demo it by the normal lab deadline. n You will get maximum 4% of course grade n Document what you have done and demonstrate well 5 Readings for Today n P&P, Revised Appendix C q Microarchitecture of the LC-3b q Appendix A (LC-3b ISA) will be useful in following this n P&H, Appendix D q Mapping Control to Hardware n Optional q Maurice Wilkes, “The Best Way to Design an Automatic Calculating Machine,” Manchester Univ. -
Local, Compressed
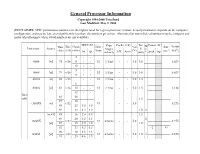
General Processor Information Copyright 1994-2000 Tom Burd Last Modified: May 2, 2000 (DISCLAIMER: SPEC performance numbers are the highest rated for a given processor version. Actual performance depends on the computer configuration, and may be less, even significantly less than, the numbers given here. Also note that non-italicized numbers may be company esti- mates of perforamnce when actual numbers are not available) SPEC-92 Pipe Cache (i/d) Tec Power (W) Date Bits Clock Units / Vdd M Size Xsistor Processor Source Stages h e (ship) (i/d) (MHz) Issue (V) (mm2) (106) int fp int/ldst/fp kB Assoc (um) t peak typ 5 - - 8086 [vi] 78 v/16 8 - - 1/1 1/1/na - - 5.0 3.0 0.029 10 - - 5 - - 8088 [vi] 79 v/16 1/1 1/1/na - - 5.0 3.0 0.029 8 - - 80186 [vi] 82 v/16 - - 1/1 1/1/na - - 5.0 1.5 6 - - 80286 [vi] 82 v/16 10 - - 1/1 1/1/na - - 5.0 1.5 0.134 12 - - Intel 85 16 x86 1.5 87 20 i386DX [vi] v/32 1/1 - - 5.0 0.275 88 25 6.5 1.9 89 33 8.4 3.0 1.0 2 [vi,41] 88 16 2.4 0.9 1.5 89 20 3.5 1.3 2 i386SX v/32 1/1 4/na/na - - 5.0 0.275 [vi] 89 25 4.6 1.9 1.0 92 33 6.2 3.3 ~2 43 90 20 3.5 1.3 i386SL [vi] v/32 1/1 4/na/na - - 5.0 1.0 2 0.855 91 25 4.6 1.9 SPEC-92 Pipe Cache (i/d) Tec Power (W) Date Bits Clock Units / Vdd M Size Xsistor Processor Source Stages h e (ship) (i/d) (MHz) Issue (V) (mm2) (106) int fp int/ldst/fp kB Assoc (um) t peak typ [vi] 89 25 14.2 6.7 1.0 2 i486DX [vi,45] 90 v/32 33 18.6 8.5 2/1 5/na/5? 8 u. -

POWER® Processor-Based Systems
IBM® Power® Systems RAS Introduction to IBM® Power® Reliability, Availability, and Serviceability for POWER9® processor-based systems using IBM PowerVM™ With Updates covering the latest 4+ Socket Power10 processor-based systems IBM Systems Group Daniel Henderson, Irving Baysah Trademarks, Copyrights, Notices and Acknowledgements Trademarks IBM, the IBM logo, and ibm.com are trademarks or registered trademarks of International Business Machines Corporation in the United States, other countries, or both. These and other IBM trademarked terms are marked on their first occurrence in this information with the appropriate symbol (® or ™), indicating US registered or common law trademarks owned by IBM at the time this information was published. Such trademarks may also be registered or common law trademarks in other countries. A current list of IBM trademarks is available on the Web at http://www.ibm.com/legal/copytrade.shtml The following terms are trademarks of the International Business Machines Corporation in the United States, other countries, or both: Active AIX® POWER® POWER Power Power Systems Memory™ Hypervisor™ Systems™ Software™ Power® POWER POWER7 POWER8™ POWER® PowerLinux™ 7® +™ POWER® PowerHA® POWER6 ® PowerVM System System PowerVC™ POWER Power Architecture™ ® x® z® Hypervisor™ Additional Trademarks may be identified in the body of this document. Other company, product, or service names may be trademarks or service marks of others. Notices The last page of this document contains copyright information, important notices, and other information. Acknowledgements While this whitepaper has two principal authors/editors it is the culmination of the work of a number of different subject matter experts within IBM who contributed ideas, detailed technical information, and the occasional photograph and section of description. -

Openpower AI CERN V1.Pdf
Moore’s Law Processor Technology Firmware / OS Linux Accelerator sSoftware OpenStack Storage Network ... Price/Performance POWER8 2000 2020 DRAM Memory Chips Buffer Power8: Up to 12 Cores, up to 96 Threads L1, L2, L3 + L4 Caches Up to 1 TB per socket https://www.ibm.com/blogs/syst Up to 230 GB/s sustained memory ems/power-systems- openpower-enable- bandwidth acceleration/ System System Memory Memory 115 GB/s 115 GB/s POWER8 POWER8 CPU CPU NVLink NVLink 80 GB/s 80 GB/s P100 P100 P100 P100 GPU GPU GPU GPU GPU GPU GPU GPU Memory Memory Memory Memory GPU PCIe CPU 16 GB/s System bottleneck Graphics System Memory Memory IBM aDVantage: data communication and GPU performance POWER8 + 78 ms Tesla P100+NVLink x86 baseD 170 ms GPU system ImageNet / Alexnet: Minibatch size = 128 ADD: Coherent Accelerator Processor Interface (CAPI) FPGA CAPP PCIe POWER8 Processor ...FPGAs, networking, memory... Typical I/O MoDel Flow Copy or Pin MMIO Notify Poll / Int Copy or Unpin Ret. From DD DD Call Acceleration Source Data Accelerator Completion Result Data Completion Flow with a Coherent MoDel ShareD Mem. ShareD Memory Acceleration Notify Accelerator Completion Focus on Enterprise Scale-Up Focus on Scale-Out and Enterprise Future Technology and Performance DriVen Cost and Acceleration DriVen Partner Chip POWER6 Architecture POWER7 Architecture POWER8 Architecture POWER9 Architecture POWER10 POWER8/9 2007 2008 2010 2012 2014 2016 2017 TBD 2018 - 20 2020+ POWER6 POWER6+ POWER7 POWER7+ POWER8 POWER8 P9 SO P9 SU P9 SO 2 cores 2 cores 8 cores 8 cores 12 cores w/ NVLink -

A 4.7 Million-Transistor CISC Microprocessor
Auriga2: A 4.7 Million-Transistor CISC Microprocessor J.P. Tual, M. Thill, C. Bernard, H.N. Nguyen F. Mottini, M. Moreau, P. Vallet Hardware Development Paris & Angers BULL S.A. 78340 Les Clayes-sous-Bois, FRANCE Tel: (+33)-1-30-80-7304 Fax: (+33)-1-30-80-7163 Mail: [email protected] Abstract- With the introduction of the high range version of parallel multi-processor architecture. It is used in a family of the DPS7000 mainframe family, Bull is providing a processor systems able to handle up to 24 such microprocessors, which integrates the DPS7000 CPU and first level of cache on capable to support 10 000 simultaneously connected users. one VLSI chip containing 4.7M transistors and using a 0.5 For the development of this complex circuit, a system level µm, 3Mlayers CMOS technology. This enhanced CPU has design methodology has been put in place, putting high been designed to provide a high integration, high performance emphasis on high-level verification issues. A lot of home- and low cost systems. Up to 24 such processors can be made CAD tools were developed, to meet the stringent integrated in a single system, enabling performance levels in performance/area constraints. In particular, an integrated the range of 850 TPC-A (Oracle) with about 12 000 Logic Synthesis and Formal Verification environment tool simultaneously active connections. The design methodology has been developed, to deal with complex circuitry issues involved massive use of formal verification and symbolic and to enable the designer to shorten the iteration loop layout techniques, enabling to reach first pass right silicon on between logical design and physical implementation of the several foundries. -

From Blue Gene to Cell Power.Org Moscow, JSCC Technical Day November 30, 2005
IBM eServer pSeries™ From Blue Gene to Cell Power.org Moscow, JSCC Technical Day November 30, 2005 Dr. Luigi Brochard IBM Distinguished Engineer Deep Computing Architect [email protected] © 2004 IBM Corporation IBM eServer pSeries™ Technology Trends As frequency increase is limited due to power limitation Dual core is a way to : 2 x Peak Performance per chip (and per cycle) But at the expense of frequency (around 20% down) Another way is to increase Flop/cycle © 2004 IBM Corporation IBM eServer pSeries™ IBM innovations POWER : FMA in 1990 with POWER: 2 Flop/cycle/chip Double FMA in 1992 with POWER2 : 4 Flop/cycle/chip Dual core in 2001 with POWER4: 8 Flop/cycle/chip Quadruple core modules in Oct 2005 with POWER5: 16 Flop/cycle/module PowerPC: VMX in 2003 with ppc970FX : 8 Flops/cycle/core, 32bit only Dual VMX+ FMA with pp970MP in 1Q06 Blue Gene: Low frequency , system on a chip, tight integration of thousands of cpus Cell : 8 SIMD units and a ppc970 core on a chip : 64 Flop/cycle/chip © 2004 IBM Corporation IBM eServer pSeries™ Technology Trends As needs diversify, systems are heterogeneous and distributed GRID technologies are an essential part to create cooperative environments based on standards © 2004 IBM Corporation IBM eServer pSeries™ IBM innovations IBM is : a sponsor of Globus Alliances contributing to Globus Tool Kit open souce a founding member of Globus Consortium IBM is extending its products Global file systems : – Multi platform and multi cluster GPFS Meta schedulers : – Multi platform -

Professor Won Woo Ro, School of Electrical and Electronic Engineering Yonsei University the Intel® 4004 Microprocessor, Introdu
Professor Won Woo Ro, School of Electrical and Electronic Engineering Yonsei University The 1st Microprocessor The Intel® 4004 microprocessor, introduced in November 1971 An electronics revolution that changed our world. There were no customer‐ programmable microprocessors on the market before the 4004. It propelled software into the limelight as a key player in the world of digital electronics design. 4004 Microprocessor Display at New Intel Museum A Japanese calculator maker (Busicom) asked to design: A set of 12 custom logic chips for a line of programmable calculators. Marcian E. "Ted" Hoff Recognized the integrated circuit technology (of the day) had advanced enough to build a single chip, general purpose computer. Federico Faggin to turn Hoff's vision into a silicon reality. (In less than one year, Faggin and his team delivered the 4004, which was introduced in November, 1971.) The world's first microprocessor application was this Busicom calculator. (sold about 100,000 calculators.) Measuring 1/8 inch wide by 1/6 inch long, consisting of 2,300 transistors, Intel’s 4004 microprocessor had as much computing power as the first electronic computer, ENIAC. 2 inch 4004 and 12 inch Core™2 Duo wafer ENIAC, built in 1946, filled 3000‐cubic‐ feet of space and contained 18,000 vacuum tubes. The 4004 microprocessor could execute 60,000 operations per second Running frequency: 108 KHz Founders wanted to name their new company Moore Noyce. However the name sounds very much similar to “more noise”. "Only the paranoid survive". Moore received a B.S. degree in Chemistry from the University of California, Berkeley in 1950 and a Ph.D. -

IBM Powerpc 970 (A.K.A. G5)
IBM PowerPC 970 (a.k.a. G5) Ref 1 David Benham and Yu-Chung Chen UIC – Department of Computer Science CS 466 PPC 970FX overview ● 64-bit RISC ● 58 million transistors ● 512 KB of L2 cache and 96KB of L1 cache ● 90um process with a die size of 65 sq. mm ● Native 32 bit compatibility ● Maximum clock speed of 2.7 Ghz ● SIMD instruction set (Altivec) ● 42 watts @ 1.8 Ghz (1.3 volts) ● Peak data bandwidth of 6.4 GB per second A picture is worth a 2^10 words (approx.) Ref 2 A little history ● PowerPC processor line is a product of the AIM alliance formed in 1991. (Apple, IBM, and Motorola) ● PPC 601 (G1) - 1993 ● PPC 603 (G2) - 1995 ● PPC 750 (G3) - 1997 ● PPC 7400 (G4) - 1999 ● PPC 970 (G5) - 2002 ● AIM alliance dissolved in 2005 Processor Ref 3 Ref 3 Core details ● 16(int)-25(vector) stage pipeline ● Large number of 'in flight' instructions (various stages of execution) - theoretical limit of 215 instructions ● 512 KB L2 cache ● 96 KB L1 cache – 64 KB I-Cache – 32 KB D-Cache Core details continued ● 10 execution units – 2 load/store operations – 2 fixed-point register-register operations – 2 floating-point operations – 1 branch operation – 1 condition register operation – 1 vector permute operation – 1 vector ALU operation ● 32 64 bit general purpose registers, 32 64 bit floating point registers, 32 128 vector registers Pipeline Ref 4 Benchmarks ● SPEC2000 ● BLAST – Bioinformatics ● Amber / jac - Structure biology ● CFD lab code SPEC CPU2000 ● IBM eServer BladeCenter JS20 ● PPC 970 2.2Ghz ● SPECint2000 ● Base: 986 Peak: 1040 ● SPECfp2000 ● Base: 1178 Peak: 1241 ● Dell PowerEdge 1750 Xeon 3.06Ghz ● SPECint2000 ● Base: 1031 Peak: 1067 Apple’s SPEC Results*2 ● SPECfp2000 ● Base: 1030 Peak: 1044 BLAST Ref. -

Embedded Multi-Core Processing for Networking
12 Embedded Multi-Core Processing for Networking Theofanis Orphanoudakis University of Peloponnese Tripoli, Greece [email protected] Stylianos Perissakis Intracom Telecom Athens, Greece [email protected] CONTENTS 12.1 Introduction ............................ 400 12.2 Overview of Proposed NPU Architectures ............ 403 12.2.1 Multi-Core Embedded Systems for Multi-Service Broadband Access and Multimedia Home Networks . 403 12.2.2 SoC Integration of Network Components and Examples of Commercial Access NPUs .............. 405 12.2.3 NPU Architectures for Core Network Nodes and High-Speed Networking and Switching ......... 407 12.3 Programmable Packet Processing Engines ............ 412 12.3.1 Parallelism ........................ 413 12.3.2 Multi-Threading Support ................ 418 12.3.3 Specialized Instruction Set Architectures ....... 421 12.4 Address Lookup and Packet Classification Engines ....... 422 12.4.1 Classification Techniques ................ 424 12.4.1.1 Trie-based Algorithms ............ 425 12.4.1.2 Hierarchical Intelligent Cuttings (HiCuts) . 425 12.4.2 Case Studies ....................... 426 12.5 Packet Buffering and Queue Management Engines ....... 431 399 400 Multi-Core Embedded Systems 12.5.1 Performance Issues ................... 433 12.5.1.1 External DRAMMemory Bottlenecks ... 433 12.5.1.2 Evaluation of Queue Management Functions: INTEL IXP1200 Case ................. 434 12.5.2 Design of Specialized Core for Implementation of Queue Management in Hardware ................ 435 12.5.2.1 Optimization Techniques .......... 439 12.5.2.2 Performance Evaluation of Hardware Queue Management Engine ............. 440 12.6 Scheduling Engines ......................... 442 12.6.1 Data Structures in Scheduling Architectures ..... 443 12.6.2 Task Scheduling ..................... 444 12.6.2.1 Load Balancing ................ 445 12.6.3 Traffic Scheduling ................... -

Microprocessor Training
Microprocessors and Microcontrollers © 1999 Altera Corporation 1 Altera Confidential Agenda New Products - MicroController products (1 hour) n Microprocessor Systems n The Embedded Microprocessor Market n Altera Solutions n System Design Considerations n Uncovering Sales Opportunities © 2000 Altera Corporation 2 Altera Confidential Embedding microprocessors inside programmable logic opens the door to a multi-billion dollar market. Altera has solutions for this market today. © 2000 Altera Corporation 3 Altera Confidential Microprocessor Systems © 1999 Altera Corporation 4 Altera Confidential Processor Terminology n Microprocessor: The implementation of a computer’s central processor unit functions on a single LSI device. n Microcontroller: A self-contained system with a microprocessor, memory and peripherals on a single chip. “Just add software.” © 2000 Altera Corporation 5 Altera Confidential Examples Microprocessor: Motorola PowerPC 600 Microcontroller: Motorola 68HC16 © 2000 Altera Corporation 6 Altera Confidential Two Types of Processors Computational Embedded n Programmable by the end-user to n Performs a fixed set of functions that accomplish a wide range of define the product. User may applications configure but not reprogram. n Runs an operating system n May or may not use an operating system n Program exists on mass storage n Program usually exists in ROM or or network Flash n Tend to be: n Tend to be: – Microprocessors – Microcontrollers – More expensive (ASP $193) – Less expensive (ASP $12) n Examples n Examples – Work Station -

Progress Codes
Power Systems Progress codes Power Systems Progress codes Note Before using this information and the product it supports, read the information in “Notices,” on page 109, “Safety notices” on page v, the IBM Systems Safety Notices manual, G229-9054, and the IBM Environmental Notices and User Guide, Z125–5823. This edition applies to IBM Power Systems™ servers that contain the POWER6® processor and to all associated models. © Copyright IBM Corporation 2007, 2009. US Government Users Restricted Rights – Use, duplication or disclosure restricted by GSA ADP Schedule Contract with IBM Corp. Contents Safety notices ............v Chapter 13. (CAxx) Partition firmware progress codes ...........79 Chapter 1. Progress codes overview . 1 Chapter 14. (CF00) Linux kernel boot Chapter 2. AIX IPL progress codes . 3 progress codes ...........91 Chapter 3. AIX diagnostic load Chapter 15. (D1xx) Service processor progress indicators .........29 firmware progress codes .......93 Chapter 4. Dump progress indicators Chapter 16. (D1xx) Service processor (dump status codes) .........33 status progress codes ........95 Chapter 5. AIX crash progress codes Chapter 17. (D1xx) Service processor (category 1) ............35 dump status progress codes .....97 Chapter 6. AIX crash progress codes Chapter 18. (D1xx) Platform dump (category 2) ............37 status progress codes .......101 Chapter 7. AIX crash progress codes Chapter 19. (D2xx) Partition status (category 3) ............39 progress codes ..........103 Chapter 8. (C1xx) Service processor Chapter 20. (D6xx) General status progress codes ...........41 progress codes ..........105 Chapter 9. (C2xx) Virtual service Chapter 21. (D9xx) General status processor progress codes ......63 progress codes ..........107 Chapter 10. (C3xx, C5xx, C6xx) IPL Appendix. Notices .........109 status progress codes ........67 Trademarks ..............110 Electronic emission notices .........111 Chapter 11.