Key Nehalem Choices
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

AMD Athlon™ Processor X86 Code Optimization Guide
AMD AthlonTM Processor x86 Code Optimization Guide © 2000 Advanced Micro Devices, Inc. All rights reserved. The contents of this document are provided in connection with Advanced Micro Devices, Inc. (“AMD”) products. AMD makes no representations or warranties with respect to the accuracy or completeness of the contents of this publication and reserves the right to make changes to specifications and product descriptions at any time without notice. No license, whether express, implied, arising by estoppel or otherwise, to any intellectual property rights is granted by this publication. Except as set forth in AMD’s Standard Terms and Conditions of Sale, AMD assumes no liability whatsoever, and disclaims any express or implied warranty, relating to its products including, but not limited to, the implied warranty of merchantability, fitness for a particular purpose, or infringement of any intellectual property right. AMD’s products are not designed, intended, authorized or warranted for use as components in systems intended for surgical implant into the body, or in other applications intended to support or sustain life, or in any other applica- tion in which the failure of AMD’s product could create a situation where per- sonal injury, death, or severe property or environmental damage may occur. AMD reserves the right to discontinue or make changes to its products at any time without notice. Trademarks AMD, the AMD logo, AMD Athlon, K6, 3DNow!, and combinations thereof, AMD-751, K86, and Super7 are trademarks, and AMD-K6 is a registered trademark of Advanced Micro Devices, Inc. Microsoft, Windows, and Windows NT are registered trademarks of Microsoft Corporation. -

Intel® Architecture Instruction Set Extensions and Future Features Programming Reference
Intel® Architecture Instruction Set Extensions and Future Features Programming Reference 319433-037 MAY 2019 Intel technologies features and benefits depend on system configuration and may require enabled hardware, software, or service activation. Learn more at intel.com, or from the OEM or retailer. No computer system can be absolutely secure. Intel does not assume any liability for lost or stolen data or systems or any damages resulting from such losses. You may not use or facilitate the use of this document in connection with any infringement or other legal analysis concerning Intel products described herein. You agree to grant Intel a non-exclusive, royalty-free license to any patent claim thereafter drafted which includes subject matter disclosed herein. No license (express or implied, by estoppel or otherwise) to any intellectual property rights is granted by this document. The products described may contain design defects or errors known as errata which may cause the product to deviate from published specifica- tions. Current characterized errata are available on request. This document contains information on products, services and/or processes in development. All information provided here is subject to change without notice. Intel does not guarantee the availability of these interfaces in any future product. Contact your Intel representative to obtain the latest Intel product specifications and roadmaps. Copies of documents which have an order number and are referenced in this document, or other Intel literature, may be obtained by calling 1- 800-548-4725, or by visiting http://www.intel.com/design/literature.htm. Intel, the Intel logo, Intel Deep Learning Boost, Intel DL Boost, Intel Atom, Intel Core, Intel SpeedStep, MMX, Pentium, VTune, and Xeon are trademarks of Intel Corporation in the U.S. -

Inside Intel® Core™ Microarchitecture Setting New Standards for Energy-Efficient Performance
White Paper Inside Intel® Core™ Microarchitecture Setting New Standards for Energy-Efficient Performance Ofri Wechsler Intel Fellow, Mobility Group Director, Mobility Microprocessor Architecture Intel Corporation White Paper Inside Intel®Core™ Microarchitecture Introduction Introduction 2 The Intel® Core™ microarchitecture is a new foundation for Intel®Core™ Microarchitecture Design Goals 3 Intel® architecture-based desktop, mobile, and mainstream server multi-core processors. This state-of-the-art multi-core optimized Delivering Energy-Efficient Performance 4 and power-efficient microarchitecture is designed to deliver Intel®Core™ Microarchitecture Innovations 5 increased performance and performance-per-watt—thus increasing Intel® Wide Dynamic Execution 6 overall energy efficiency. This new microarchitecture extends the energy efficient philosophy first delivered in Intel's mobile Intel® Intelligent Power Capability 8 microarchitecture found in the Intel® Pentium® M processor, and Intel® Advanced Smart Cache 8 greatly enhances it with many new and leading edge microar- Intel® Smart Memory Access 9 chitectural innovations as well as existing Intel NetBurst® microarchitecture features. What’s more, it incorporates many Intel® Advanced Digital Media Boost 10 new and significant innovations designed to optimize the Intel®Core™ Microarchitecture and Software 11 power, performance, and scalability of multi-core processors. Summary 12 The Intel Core microarchitecture shows Intel’s continued Learn More 12 innovation by delivering both greater energy efficiency Author Biographies 12 and compute capability required for the new workloads and usage models now making their way across computing. With its higher performance and low power, the new Intel Core microarchitecture will be the basis for many new solutions and form factors. In the home, these include higher performing, ultra-quiet, sleek and low-power computer designs, and new advances in more sophisticated, user-friendly entertainment systems. -

Dual-Core Intel® Xeon® Processor 3100 Series Specification Update
Dual-Core Intel® Xeon® Processor 3100 Series Specification Update — on 45 nm Process in the 775-land LGA Package December 2010 Notice: Dual-Core Intel® Xeon® Processor 3100 Series may contain design defects or errors known as errata which may cause the product to deviate from published specifications. Current characterized errata are documented in this Specification Update. Document Number: 319006-009 INFORMATION IN THIS DOCUMENT IS PROVIDED IN CONNECTION WITH INTEL® PRODUCTS. NO LICENSE, EXPRESS OR IMPLIED, BY ESTOPPEL OR OTHERWISE, TO ANY INTELLECTUAL PROPERTY RIGHTS IS GRANTED BY THIS DOCUMENT. EXCEPT AS PROVIDED IN INTEL’S TERMS AND CONDITIONS OF SALE FOR SUCH PRODUCTS, INTEL ASSUMES NO LIABILITY WHATSOEVER, AND INTEL DISCLAIMS ANY EXPRESS OR IMPLIED WARRANTY, RELATING TO SALE AND/OR USE OF INTEL PRODUCTS INCLUDING LIABILITY OR WARRANTIES RELATING TO FITNESS FOR A PARTICULAR PURPOSE, MERCHANTABILITY, OR INFRINGEMENT OF ANY PATENT, COPYRIGHT OR OTHER INTELLECTUAL PROPERTY RIGHT. UNLESS OTHERWISE AGREED IN WRITING BY INTEL, THE INTEL PRODUCTS ARE NOT DESIGNED NOR INTENDED FOR ANY APPLICATION IN WHICH THE FAILURE OF THE INTEL PRODUCT COULD CREATE A SITUATION WHERE PERSONAL INJURY OR DEATH MAY OCCUR. Intel products are not intended for use in medical, life saving, or life sustaining applications. Intel may make changes to specifications and product descriptions at any time, without notice. Designers must not rely on the absence or characteristics of any features or instructions marked “reserved” or “undefined.” Intel reserves these for future definition and shall have no responsibility whatsoever for conflicts or incompatibilities arising from future changes to them. Enabling Execute Disable Bit functionality requires a PC with a processor with Execute Disable Bit capability and a supporting operating system. -

Microcode Revision Guidance August 31, 2019 MCU Recommendations
microcode revision guidance August 31, 2019 MCU Recommendations Section 1 – Planned microcode updates • Provides details on Intel microcode updates currently planned or available and corresponding to Intel-SA-00233 published June 18, 2019. • Changes from prior revision(s) will be highlighted in yellow. Section 2 – No planned microcode updates • Products for which Intel does not plan to release microcode updates. This includes products previously identified as such. LEGEND: Production Status: • Planned – Intel is planning on releasing a MCU at a future date. • Beta – Intel has released this production signed MCU under NDA for all customers to validate. • Production – Intel has completed all validation and is authorizing customers to use this MCU in a production environment. -

Single Board Computer
Single Board Computer SBC with the Intel® 8th generation Core™/Xeon® (formerly Coffee Lake H) SBC-C66 and 9th generation Core™ / Xeon® / Pentium® / Celeron® (formerly Coffee Lake Refresh) CPUs High-performing, flexible solution for intelligence at the edge HIGHLIGHTS CONNECTIVITY CPU 2x USB 3.1; 4x USB 2.0; NVMe SSD Slot; PCI-e x8 Intel® 8th gen. Core™ / Xeon® and 9th gen. Core™ / port (PCI-e x16 mechanical slot); VPU High Speed Xeon® / Pentium® / Celeron® CPUs Connector with 4xUSB3.1 + 2x PCI-ex4 GRAPHICS MEMORY Intel® UHD Graphics 630/P630 architecture, up to 128GB DDR4 memory on 4x SO-DIMM Slots supports up to 3 independent displays (ECC supported) Available in Industrial Temperature Range MAIN FIELDS OF APPLICATION Biomedical/ Gaming Industrial Industrial Surveillance Medical devices Automation and Internet of Control Things FEATURES ® ™ ® Intel 8th generation Core /Xeon (formerly Coffee Lake H) CPUs: Max Cores 6 • Intel® Core™ i7-8850H, Six Core @ 2.6GHz (4.3GHz Max 1 Core Turbo), 9MB Cache, 45W TDP (35W cTDP), with Max Thread 12 HyperThreading • Intel® Core™ i5-8400H, Quad Core @ 2.5GHz (4.2GHz Intel® QM370, HM370 or CM246 Platform Controller Hub Chipset Max 1 Core Turbo), 8MB Cache, 45W TDP (35W cTDP), (PCH) with HyperThreading • Intel® Core™ i3-8100H, Quad Core @ 3.0GHz, 6MB 2x DDR4-2666 or 4x DDR4-2444 ECC SODIMM Slots, up to 128GB total (only with 4 SODIMM modules). Cache, 45W TDP (35W cTDP) Memory ® ™ ® ® ECC DDR4 memory modules supported only with Xeon Core Information subject to change. Please visit www.seco.com to find the latest version of this datasheet Information subject to change. -

"PCOM-B216VG-ECC.Pdf" (581 Kib)
Intel® Arrandale processor based Type II COM Express module support ECC DDR3 SDRAM PCOM-B216VG-ECC with Gigabit Ethernet 204pin ECC DDR3 SODIMM socket ® Intel QM57 ® Intel Arrandale processor FEATURES GENERAL CPU & Package: Intel® 45nm Arrandale Core i7/i5/i3 or Celeron P4505 ® Processor The Intel Arrandale and QM57 platform processor up to 2.66 GHz with 4MB Cache in FC-BGA package with turbo boost technology to maximize DMI x4 Link: 4.8GT/s (Full-Duplex) CPU & Graphic performance Chipset/Core Logic Intel® QM57 ® Intel Arrandale platform support variously System Memory Up to 8GB ECC DDR3 800/1066 SDRAM on two SODIMM sockets powerful processor from ultra low power AMI BIOS to mainstream performance type BIOS Storage Devices SATA: Support four SATA 300 and one IDE Supports Intel® intelligent power sharing Expansion Interface VGA and LVDS technology to reduce TDP (Thermal Six PCI Express x1 Design Power) LPC & SPI Interface High definition audio interface ® ® Enhance Intel vPro efficiency by Intel PCI 82577LM GbE PHY and AMT6.0 Hardware Monitoring CPU Voltage and Temperature technology Power Requirement TBA Support two ECC DDR3 800/1066 SDRAM on Dimension Dimension: 125(L) x 95(W) mm two SODIMM sockets, up to 8GB memory size Environment Operation Temperature: 0~60 °C Storage Temperature: -20~80 °C Operation Humidity: 5~90% I/O ORDERING GUIDE MIO N/A IrDA N/A PCOM-B216VG-ECC ® Standard Ethernet One Intel 82577LM Gigabit Ethernet PHY Intel® Arrandale processor based Type II COM Express module with ECC DDR3 SDRAM and Audio N/A Gigabit Ethernet USB Eight USB ports Keyboard & Mouse N/A CPU Intel® Core i7-610E SV (4M Cache, 2.53 GHz) Support List Intel® Core i7-620LE LV (4M Cache, 2.00 GHz) Intel® Core i7-620UE ULV (4M Cache, 1.06 GHz) Intel® Core i5-520E SV (3M Cache, 2.40 GHz) Intel® Celeron P4505 SV (2M Cache, 1.86 GHz) DISPLAY Graphic Controller Intel® Arrandale integrated Graphics Media Accelerator (Gen 5.75 with 12 execution units) * Specifications are subject to change without notice. -
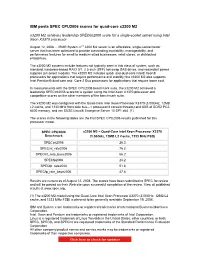
IBM Posts SPEC CPU2006 Scores for Quad-Core X3200 M2 X3200 M2 Achieves Leadership Specint2006 Score for a Single-Socket Server Using Intel Xeon X3370 Processor
IBM posts SPEC CPU2006 scores for quad-core x3200 M2 x3200 M2 achieves leadership SPECint2006 score for a single-socket server using Intel Xeon X3370 processor August 12, 2008 ... IBM® System xTM 3200 M2 server is an affordable, single-socket tower server that has been optimized to provide outstanding availability, manageability, and performance features for small to medium-sized businesses, retail stores, or distributed enterprises. The x3200 M2 systems include features not typically seen in this class of system, such as standard, hardware-based RAID 0/1, 2.5-inch (SFF) hot-swap SAS drives, and redundant power supplies (on select models). The x3200 M2 includes quad- and dual-core Intel® Xeon® processors for applications that require performance and stability; the x3200 M2 also supports Intel Pentium® dual-core and Core 2 Duo processors for applications that require lower cost. In measurements with the SPEC CPU2006 benchmark suite, the x3200 M2 achieved a leadership SPECint2006 score for a system using the Intel Xeon X3370 processor and competitive scores on the other members of the benchmark suite. The x3200 M2 was configured with the Quad-Core Intel Xeon Processor X3370 (3.00GHz, 12MB L2 cache, and 1333 MHz front-side bus—1 processor/4 cores/4 threads) and 8GB of DDR2 PC2- 6400 memory, and ran SUSE Linux® Enterprise Server 10 SP1 x64. (1) The scores in the following tables are the first SPEC CPU2006 results published for this processor model. SPEC CPU2006 x3200 M2 – Quad-Core Intel Xeon Processor X3370 Benchmark (3.00GHz, 12MB L2 Cache, 1333 MHz FSB) SPECint2006 26.3 SPECint_rate2006 76.2 SPECint_rate_base2006 66.2 SPECfp2006 24.2 SPECfp_rate2006 51.8 SPECfp_rate_base2006 47.8 Results are current as of August 12, 2008. -

A Superscalar Out-Of-Order X86 Soft Processor for FPGA
A Superscalar Out-of-Order x86 Soft Processor for FPGA Henry Wong University of Toronto, Intel [email protected] June 5, 2019 Stanford University EE380 1 Hi! ● CPU architect, Intel Hillsboro ● Ph.D., University of Toronto ● Today: x86 OoO processor for FPGA (Ph.D. work) – Motivation – High-level design and results – Microarchitecture details and some circuits 2 FPGA: Field-Programmable Gate Array ● Is a digital circuit (logic gates and wires) ● Is field-programmable (at power-on, not in the fab) ● Pre-fab everything you’ll ever need – 20x area, 20x delay cost – Circuit building blocks are somewhat bigger than logic gates 6-LUT6-LUT 6-LUT6-LUT 3 6-LUT 6-LUT FPGA: Field-Programmable Gate Array ● Is a digital circuit (logic gates and wires) ● Is field-programmable (at power-on, not in the fab) ● Pre-fab everything you’ll ever need – 20x area, 20x delay cost – Circuit building blocks are somewhat bigger than logic gates 6-LUT 6-LUT 6-LUT 6-LUT 4 6-LUT 6-LUT FPGA Soft Processors ● FPGA systems often have software components – Often running on a soft processor ● Need more performance? – Parallel code and hardware accelerators need effort – Less effort if soft processors got faster 5 FPGA Soft Processors ● FPGA systems often have software components – Often running on a soft processor ● Need more performance? – Parallel code and hardware accelerators need effort – Less effort if soft processors got faster 6 FPGA Soft Processors ● FPGA systems often have software components – Often running on a soft processor ● Need more performance? – Parallel -

Multiprocessing Contents
Multiprocessing Contents 1 Multiprocessing 1 1.1 Pre-history .............................................. 1 1.2 Key topics ............................................... 1 1.2.1 Processor symmetry ...................................... 1 1.2.2 Instruction and data streams ................................. 1 1.2.3 Processor coupling ...................................... 2 1.2.4 Multiprocessor Communication Architecture ......................... 2 1.3 Flynn’s taxonomy ........................................... 2 1.3.1 SISD multiprocessing ..................................... 2 1.3.2 SIMD multiprocessing .................................... 2 1.3.3 MISD multiprocessing .................................... 3 1.3.4 MIMD multiprocessing .................................... 3 1.4 See also ................................................ 3 1.5 References ............................................... 3 2 Computer multitasking 5 2.1 Multiprogramming .......................................... 5 2.2 Cooperative multitasking ....................................... 6 2.3 Preemptive multitasking ....................................... 6 2.4 Real time ............................................... 7 2.5 Multithreading ............................................ 7 2.6 Memory protection .......................................... 7 2.7 Memory swapping .......................................... 7 2.8 Programming ............................................. 7 2.9 See also ................................................ 8 2.10 References ............................................. -

2Nd Generation Intel® Core™ Processor Family Mobile with ECC
2nd Generation Intel® Core™ Processor Family Mobile with ECC Datasheet Addendum May 2012 Revision 002 Document Number: 324855-002 INFORMATION IN THIS DOCUMENT IS PROVIDED IN CONNECTION WITH INTEL PRODUCTS. NO LICENSE, EXPRESS OR IMPLIED, BY ESTOPPEL OR OTHERWISE, TO ANY INTELLECTUAL PROPERTY RIGHTS IS GRANTED BY THIS DOCUMENT. EXCEPT AS PROVIDED IN INTEL'S TERMS AND CONDITIONS OF SALE FOR SUCH PRODUCTS, INTEL ASSUMES NO LIABILITY WHATSOEVER AND INTEL DISCLAIMS ANY EXPRESS OR IMPLIED WARRANTY, RELATING TO SALE AND/OR USE OF INTEL PRODUCTS INCLUDING LIABILITY OR WARRANTIES RELATING TO FITNESS FOR A PARTICULAR PURPOSE, MERCHANTABILITY, OR INFRINGEMENT OF ANY PATENT, COPYRIGHT OR OTHER INTELLECTUAL PROPERTY RIGHT. UNLESS OTHERWISE AGREED IN WRITING BY INTEL, THE INTEL PRODUCTS ARE NOT DESIGNED NOR INTENDED FOR ANY APPLICATION IN WHICH THE FAILURE OF THE INTEL PRODUCT COULD CREATE A SITUATION WHERE PERSONAL INJURY OR DEATH MAY OCCUR. A "Mission Critical Application" is any application in which failure of the Intel Product could result, directly or indirectly, in personal injury or death. SHOULD YOU PURCHASE OR USE INTEL'S PRODUCTS FOR ANY SUCH MISSION CRITICAL APPLICATION, YOU SHALL INDEMNIFY AND HOLD INTEL AND ITS SUBSIDIARIES, SUBCONTRACTORS AND AFFILIATES, AND THE DIRECTORS, OFFICERS, AND EMPLOYEES OF EACH, HARMLESS AGAINST ALL CLAIMS COSTS, DAMAGES, AND EXPENSES AND REASONABLE ATTORNEYS' FEES ARISING OUT OF, DIRECTLY OR INDIRECTLY, ANY CLAIM OF PRODUCT LIABILITY, PERSONAL INJURY, OR DEATH ARISING IN ANY WAY OUT OF SUCH MISSION CRITICAL APPLICATION, WHETHER OR NOT INTEL OR ITS SUBCONTRACTOR WAS NEGLIGENT IN THE DESIGN, MANUFACTURE, OR WARNING OF THE INTEL PRODUCT OR ANY OF ITS PARTS. -

Intel® Core™ Microarchitecture • Wrap Up
EW N IntelIntel®® CoreCore™™ MicroarchitectureMicroarchitecture MarchMarch 8,8, 20062006 Stephen L. Smith Bob Valentine Vice President Architect Digital Enterprise Group Intel Architecture Group Agenda • Multi-core Update and New Microarchitecture Level Set • New Intel® Core™ Microarchitecture • Wrap Up 2 Intel Multi-core Roadmap – Updates since Fall IDF 3 Ramping Multi-core Everywhere 4 All products and dates are preliminary and subject to change without notice. Refresher: What is Multi-Core? Two or more independent execution cores in the same processor Specific implementations will vary over time - driven by product implementation and manufacturing efficiencies • Best mix of product architecture and volume mfg capabilities – Architecture: Shared Caches vs. Independent Caches – Mfg capabilities: volume packaging technology • Designed to deliver performance, OEM and end user experience Single die (Monolithic) based processor Multi-Chip Processor Example: 90nm Pentium® D Example: Intel Core™ Duo Example: 65nm Pentium D Processor (Smithfield) Processor (Yonah) Processor (Presler) Core0 Core1 Core0 Core1 Core0 Core1 Front Side Bus Front Side Bus Front Side Bus *Not representative of actual die photos or relative size 5 Intel® Core™ Micro-architecture *Not representative of actual die photo or relative size 6 Intel Multi-core Roadmap 7 Intel Multi-core Roadmap 8 Intel® Core™ Microarchitecture Based Platforms Platform 2006 20072007 Caneland Platform (2007) MP Servers Tigerton (QC) (2007) Bensley Platform (Q2’06)/ Glidewell Platform (Q2’06) ) DP Servers/ Woodcrest (Q3’06) DP Workstation Clovertown (QC) (Q1’07) Kaylo Platform (Q3’06)/ Wyloway Platform (Q3 ’06) UP Servers/ Conroe (Q3’06) UP Workstation Kentsfield (QC) (Q1’07) Bridge Creek Platform (Mid’06) Desktop -Home Conroe (Q3’06) Kentsfield (QC) (Q1’07) Desktop -Office Averill Platform (Mid’06) Conroe (Q3’06) Mobile Client Napa Platform (Q1’06) Merom (2H’06) All products and dates are preliminary 9 Note: only Intel® Core™ microarchitecture QC refers to Quad-Core and subject to change without notice.