The New Intel® Xeon® Processor Scalable Family
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Inside Intel® Core™ Microarchitecture Setting New Standards for Energy-Efficient Performance
White Paper Inside Intel® Core™ Microarchitecture Setting New Standards for Energy-Efficient Performance Ofri Wechsler Intel Fellow, Mobility Group Director, Mobility Microprocessor Architecture Intel Corporation White Paper Inside Intel®Core™ Microarchitecture Introduction Introduction 2 The Intel® Core™ microarchitecture is a new foundation for Intel®Core™ Microarchitecture Design Goals 3 Intel® architecture-based desktop, mobile, and mainstream server multi-core processors. This state-of-the-art multi-core optimized Delivering Energy-Efficient Performance 4 and power-efficient microarchitecture is designed to deliver Intel®Core™ Microarchitecture Innovations 5 increased performance and performance-per-watt—thus increasing Intel® Wide Dynamic Execution 6 overall energy efficiency. This new microarchitecture extends the energy efficient philosophy first delivered in Intel's mobile Intel® Intelligent Power Capability 8 microarchitecture found in the Intel® Pentium® M processor, and Intel® Advanced Smart Cache 8 greatly enhances it with many new and leading edge microar- Intel® Smart Memory Access 9 chitectural innovations as well as existing Intel NetBurst® microarchitecture features. What’s more, it incorporates many Intel® Advanced Digital Media Boost 10 new and significant innovations designed to optimize the Intel®Core™ Microarchitecture and Software 11 power, performance, and scalability of multi-core processors. Summary 12 The Intel Core microarchitecture shows Intel’s continued Learn More 12 innovation by delivering both greater energy efficiency Author Biographies 12 and compute capability required for the new workloads and usage models now making their way across computing. With its higher performance and low power, the new Intel Core microarchitecture will be the basis for many new solutions and form factors. In the home, these include higher performing, ultra-quiet, sleek and low-power computer designs, and new advances in more sophisticated, user-friendly entertainment systems. -

Dual-Core Intel® Xeon® Processor 3100 Series Specification Update
Dual-Core Intel® Xeon® Processor 3100 Series Specification Update — on 45 nm Process in the 775-land LGA Package December 2010 Notice: Dual-Core Intel® Xeon® Processor 3100 Series may contain design defects or errors known as errata which may cause the product to deviate from published specifications. Current characterized errata are documented in this Specification Update. Document Number: 319006-009 INFORMATION IN THIS DOCUMENT IS PROVIDED IN CONNECTION WITH INTEL® PRODUCTS. NO LICENSE, EXPRESS OR IMPLIED, BY ESTOPPEL OR OTHERWISE, TO ANY INTELLECTUAL PROPERTY RIGHTS IS GRANTED BY THIS DOCUMENT. EXCEPT AS PROVIDED IN INTEL’S TERMS AND CONDITIONS OF SALE FOR SUCH PRODUCTS, INTEL ASSUMES NO LIABILITY WHATSOEVER, AND INTEL DISCLAIMS ANY EXPRESS OR IMPLIED WARRANTY, RELATING TO SALE AND/OR USE OF INTEL PRODUCTS INCLUDING LIABILITY OR WARRANTIES RELATING TO FITNESS FOR A PARTICULAR PURPOSE, MERCHANTABILITY, OR INFRINGEMENT OF ANY PATENT, COPYRIGHT OR OTHER INTELLECTUAL PROPERTY RIGHT. UNLESS OTHERWISE AGREED IN WRITING BY INTEL, THE INTEL PRODUCTS ARE NOT DESIGNED NOR INTENDED FOR ANY APPLICATION IN WHICH THE FAILURE OF THE INTEL PRODUCT COULD CREATE A SITUATION WHERE PERSONAL INJURY OR DEATH MAY OCCUR. Intel products are not intended for use in medical, life saving, or life sustaining applications. Intel may make changes to specifications and product descriptions at any time, without notice. Designers must not rely on the absence or characteristics of any features or instructions marked “reserved” or “undefined.” Intel reserves these for future definition and shall have no responsibility whatsoever for conflicts or incompatibilities arising from future changes to them. Enabling Execute Disable Bit functionality requires a PC with a processor with Execute Disable Bit capability and a supporting operating system. -

Microcode Revision Guidance August 31, 2019 MCU Recommendations
microcode revision guidance August 31, 2019 MCU Recommendations Section 1 – Planned microcode updates • Provides details on Intel microcode updates currently planned or available and corresponding to Intel-SA-00233 published June 18, 2019. • Changes from prior revision(s) will be highlighted in yellow. Section 2 – No planned microcode updates • Products for which Intel does not plan to release microcode updates. This includes products previously identified as such. LEGEND: Production Status: • Planned – Intel is planning on releasing a MCU at a future date. • Beta – Intel has released this production signed MCU under NDA for all customers to validate. • Production – Intel has completed all validation and is authorizing customers to use this MCU in a production environment. -

Single Board Computer
Single Board Computer SBC with the Intel® 8th generation Core™/Xeon® (formerly Coffee Lake H) SBC-C66 and 9th generation Core™ / Xeon® / Pentium® / Celeron® (formerly Coffee Lake Refresh) CPUs High-performing, flexible solution for intelligence at the edge HIGHLIGHTS CONNECTIVITY CPU 2x USB 3.1; 4x USB 2.0; NVMe SSD Slot; PCI-e x8 Intel® 8th gen. Core™ / Xeon® and 9th gen. Core™ / port (PCI-e x16 mechanical slot); VPU High Speed Xeon® / Pentium® / Celeron® CPUs Connector with 4xUSB3.1 + 2x PCI-ex4 GRAPHICS MEMORY Intel® UHD Graphics 630/P630 architecture, up to 128GB DDR4 memory on 4x SO-DIMM Slots supports up to 3 independent displays (ECC supported) Available in Industrial Temperature Range MAIN FIELDS OF APPLICATION Biomedical/ Gaming Industrial Industrial Surveillance Medical devices Automation and Internet of Control Things FEATURES ® ™ ® Intel 8th generation Core /Xeon (formerly Coffee Lake H) CPUs: Max Cores 6 • Intel® Core™ i7-8850H, Six Core @ 2.6GHz (4.3GHz Max 1 Core Turbo), 9MB Cache, 45W TDP (35W cTDP), with Max Thread 12 HyperThreading • Intel® Core™ i5-8400H, Quad Core @ 2.5GHz (4.2GHz Intel® QM370, HM370 or CM246 Platform Controller Hub Chipset Max 1 Core Turbo), 8MB Cache, 45W TDP (35W cTDP), (PCH) with HyperThreading • Intel® Core™ i3-8100H, Quad Core @ 3.0GHz, 6MB 2x DDR4-2666 or 4x DDR4-2444 ECC SODIMM Slots, up to 128GB total (only with 4 SODIMM modules). Cache, 45W TDP (35W cTDP) Memory ® ™ ® ® ECC DDR4 memory modules supported only with Xeon Core Information subject to change. Please visit www.seco.com to find the latest version of this datasheet Information subject to change. -
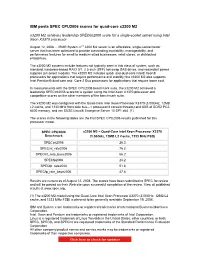
IBM Posts SPEC CPU2006 Scores for Quad-Core X3200 M2 X3200 M2 Achieves Leadership Specint2006 Score for a Single-Socket Server Using Intel Xeon X3370 Processor
IBM posts SPEC CPU2006 scores for quad-core x3200 M2 x3200 M2 achieves leadership SPECint2006 score for a single-socket server using Intel Xeon X3370 processor August 12, 2008 ... IBM® System xTM 3200 M2 server is an affordable, single-socket tower server that has been optimized to provide outstanding availability, manageability, and performance features for small to medium-sized businesses, retail stores, or distributed enterprises. The x3200 M2 systems include features not typically seen in this class of system, such as standard, hardware-based RAID 0/1, 2.5-inch (SFF) hot-swap SAS drives, and redundant power supplies (on select models). The x3200 M2 includes quad- and dual-core Intel® Xeon® processors for applications that require performance and stability; the x3200 M2 also supports Intel Pentium® dual-core and Core 2 Duo processors for applications that require lower cost. In measurements with the SPEC CPU2006 benchmark suite, the x3200 M2 achieved a leadership SPECint2006 score for a system using the Intel Xeon X3370 processor and competitive scores on the other members of the benchmark suite. The x3200 M2 was configured with the Quad-Core Intel Xeon Processor X3370 (3.00GHz, 12MB L2 cache, and 1333 MHz front-side bus—1 processor/4 cores/4 threads) and 8GB of DDR2 PC2- 6400 memory, and ran SUSE Linux® Enterprise Server 10 SP1 x64. (1) The scores in the following tables are the first SPEC CPU2006 results published for this processor model. SPEC CPU2006 x3200 M2 – Quad-Core Intel Xeon Processor X3370 Benchmark (3.00GHz, 12MB L2 Cache, 1333 MHz FSB) SPECint2006 26.3 SPECint_rate2006 76.2 SPECint_rate_base2006 66.2 SPECfp2006 24.2 SPECfp_rate2006 51.8 SPECfp_rate_base2006 47.8 Results are current as of August 12, 2008. -

2Nd Generation Intel Core Processor Family with Intel 6 Series Chipset Development Kit User Guide
2nd Generation Intel® Core™ Processor Family with Intel® 6 Series Chipset Development Kit User Guide March 2011 Document Number: 325208 About This Document INFORMATION IN THIS DOCUMENT IS PROVIDED IN CONNECTION WITH INTEL PRODUCTS. NO LICENSE, EXPRESS OR IMPLIED, BY ESTOPPEL OR OTHERWISE, TO ANY INTELLECTUAL PROPERTY RIGHTS IS GRANTED BY THIS DOCUMENT. EXCEPT AS PROVIDED IN INTEL'S TERMS AND CONDITIONS OF SALE FOR SUCH PRODUCTS, INTEL ASSUMES NO LIABILITY WHATSOEVER AND INTEL DISCLAIMS ANY EXPRESS OR IMPLIED WARRANTY, RELATING TO SALE AND/OR USE OF INTEL PRODUCTS INCLUDING LIABILITY OR WARRANTIES RELATING TO FITNESS FOR A PARTICULAR PURPOSE, MERCHANTABILITY, OR INFRINGEMENT OF ANY PATENT, COPYRIGHT OR OTHER INTELLECTUAL PROPERTY RIGHT. UNLESS OTHERWISE AGREED IN WRITING BY INTEL, THE INTEL PRODUCTS ARE NOT DESIGNED NOR INTENDED FOR ANY APPLICATION IN WHICH THE FAILURE OF THE INTEL PRODUCT COULD CREATE A SITUATION WHERE PERSONAL INJURY OR DEATH MAY OCCUR. Intel may make changes to specifications and product descriptions at any time, without notice. Intel Corporation may have patents or pending patent applications, trademarks, copyrights, or other intellectual property rights that relate to the presented subject matter. The furnishing of documents and other materials and information does not provide any license, express or implied, by estoppel or otherwise, to any such patents, trademarks, copyrights, or other intellectual property rights. Designers must not rely on the absence or characteristics of any features or instructions marked “reserved” or “undefined.” Intel reserves these for future definition and shall have no responsibility whatsoever for conflicts or incompatibilities arising from future changes to them. Intel processor numbers are not a measure of performance. -

Instruction Rate with Ivy Bridge Vs Haswell for Some Common Jobs
Instruction rate with Ivy Bridge vs Haswell for some common jobs David Smith on behalf of IT-DI-LCG, UP team. 20 Oct 2016, ATLAS computing workflow performance meeting 20.10.16 Sandy Bridge / Haswell 1 Introduction • Get some insight about how the job’s code is interacting with the CPU while running by looking at Instructions per Cycle (IPC) • This is not our usual performance measure, but I hope this may let one more easily see how the cpu pipeline is handling the code, and to some extent compare microarchitectures 10/20/2016 Sandy Bridge / Haswell 2 IPC for some jobs • Ratio of retired instructions / unhalted clock cycles (most over whole job). Physical machine. • Atlas simu with single process athena, HT on, affinity fixed to 1 core. No other significant load. • Haswell was Xeon E5-2683 v3 (~3GHz); Ivy Bridge i7-3770k (~3.8GHz) • checked Ivy Bridge also on Xeon E5-2695 v2 (~3.1GHz) running ATLAS Sim (19.2) => 0.91 IPC • checked Atlas simu (19.2) with athenaMP (8) affinity to 4 cores on one socket => 1.58/0.97 IPC • ATLAS sim was job 2972328065 (19.2.4.9, slc6-gcc47-opt or 20.7.8.5, slc6-gcc49-opt; mc15_13TeV.362059.Sherpa_CT10_Znunu_Pt140_280_CFilterBVecto_fac4) • Looked up previous HS06 results; usually ~10% higher for Haswell (per job slot/per GHz) 10/20/2016 Sandy Bridge / Haswell 3 Which microarchitectures are used? • The above are usually classed as the intel microarchitectures: e.g. Ivy Bridge is the die shrink version of SB, and is classed as SB microarch. • This is the last 90 days of ATLAS jobs, raw data from elastic search (thanks Andrea) • Used wall clock time per cpu type, with classification based on type string, weighted by quoted cpu freq, and a rough weighting of x1.5 for Intel Core, as that microarch. -

Im Divar Ip 6000 2U
DIVAR IP 6000 2U DIP-6080-00N, DIP-6082-8HD, DIP-6083-8HD en Installation Manual DIVAR IP 6000 2U Table of Contents | en 3 Table of contents 1 Safety precautions 5 1.1 General safety precautions 5 1.2 Electrical safety precautions 6 1.3 ESD precautions 7 1.4 Operating precautions 7 1.5 Important notices 8 1.6 FCC and ICES compliance 8 2 System overview 9 2.1 Chassis features 9 2.2 Chassis components 9 2.2.1 Chassis 10 2.2.2 Backplane 10 2.2.3 Fans 10 2.2.4 Mounting rails 10 2.2.5 Power supply 10 2.2.6 Air shroud 10 2.3 System interface 10 2.3.1 Control panel buttons 11 2.3.2 Control panel LEDs 12 2.3.3 Drive carrier LEDs 12 3 Chassis setup and maintenance 13 3.1 Removing the chassis cover 13 3.2 Installing hard drives 14 3.2.1 Removing hard drive trays 14 3.2.2 Installing a hard drive 15 3.3 Installing an optional floppy or fixed hard drive 16 3.4 Installing or replacing a DVD-ROM drive 17 3.5 Replacing the internal transcoder device 17 3.6 Replacing or installing the front port panel 17 3.7 Installing the motherboard 18 3.8 Installing the air shroud 18 3.9 System fans 19 3.10 Power supply 20 3.10.1 Replacing the power supply 21 3.10.2 Replacing the power distributor 22 4 Rack installation 23 4.1 Unpacking the system 23 4.2 Preparing for setup 23 4.2.1 Choosing a setup location 23 4.2.2 Rack precautions 23 4.2.3 General system precautions 24 4.2.4 Rack mounting considerations 24 4.3 Rack mounting instructions 24 4.3.1 Separating the sections of the rack rails 25 4.3.2 Installing the inner rails 26 4.3.3 Installing the outer rails to the -

Desktop 4Th Generation Intel® Core™ Processor Family, Desktop Intel® Pentium® Processor Family, and Desktop Intel® Celeron® Processor Family Datasheet – Volume 1 of 2
Desktop 4th Generation Intel® Core™ Processor Family, Desktop Intel® Pentium® Processor Family, and Desktop Intel® Celeron® Processor Family Datasheet – Volume 1 of 2 July 2014 Order No.: 328897-008 By using this document, in addition to any agreements you have with Intel, you accept the terms set forth below. You may not use or facilitate the use of this document in connection with any infringement or other legal analysis concerning Intel products described herein. You agree to grant Intel a non-exclusive, royalty-free license to any patent claim thereafter drafted which includes subject matter disclosed herein. INFORMATION IN THIS DOCUMENT IS PROVIDED IN CONNECTION WITH INTEL PRODUCTS. NO LICENSE, EXPRESS OR IMPLIED, BY ESTOPPEL OR OTHERWISE, TO ANY INTELLECTUAL PROPERTY RIGHTS IS GRANTED BY THIS DOCUMENT. EXCEPT AS PROVIDED IN INTEL'S TERMS AND CONDITIONS OF SALE FOR SUCH PRODUCTS, INTEL ASSUMES NO LIABILITY WHATSOEVER AND INTEL DISCLAIMS ANY EXPRESS OR IMPLIED WARRANTY, RELATING TO SALE AND/OR USE OF INTEL PRODUCTS INCLUDING LIABILITY OR WARRANTIES RELATING TO FITNESS FOR A PARTICULAR PURPOSE, MERCHANTABILITY, OR INFRINGEMENT OF ANY PATENT, COPYRIGHT OR OTHER INTELLECTUAL PROPERTY RIGHT. A "Mission Critical Application" is any application in which failure of the Intel Product could result, directly or indirectly, in personal injury or death. SHOULD YOU PURCHASE OR USE INTEL'S PRODUCTS FOR ANY SUCH MISSION CRITICAL APPLICATION, YOU SHALL INDEMNIFY AND HOLD INTEL AND ITS SUBSIDIARIES, SUBCONTRACTORS AND AFFILIATES, AND THE DIRECTORS, OFFICERS, AND EMPLOYEES OF EACH, HARMLESS AGAINST ALL CLAIMS COSTS, DAMAGES, AND EXPENSES AND REASONABLE ATTORNEYS' FEES ARISING OUT OF, DIRECTLY OR INDIRECTLY, ANY CLAIM OF PRODUCT LIABILITY, PERSONAL INJURY, OR DEATH ARISING IN ANY WAY OUT OF SUCH MISSION CRITICAL APPLICATION, WHETHER OR NOT INTEL OR ITS SUBCONTRACTOR WAS NEGLIGENT IN THE DESIGN, MANUFACTURE, OR WARNING OF THE INTEL PRODUCT OR ANY OF ITS PARTS. -

Intel's Core Microarchitecture Sets New Records in Performance and Energy Efficiency 23 May 2006
Intel's Core Microarchitecture Sets New Records in Performance and Energy Efficiency 23 May 2006 Virtualization Technology (Intel VT), Intel Active Server Manager and Intel I/O Acceleration Technology. (Intel I/OAT)” Fully-buffered dual in-line memory (FB-DIMM) technology allows for better memory capacity, throughput and overall reliability. This is critical for creating balanced platforms using multiple cores and the latest technologies, such as virtualization, to meet the expanding demand for compute headroom. Shipping in Intel Xeon MP processors since last year, Intel Virtualization Technology (Intel VT) Dual-Core Intel Xeon processor 5000 series, previously provides silicon-level software support that codenamed "Dempsey." improves dependability and interoperability and is enabling faster industry innovation. Intel Active Server Manager integrates hardware, software and firmware to manage today’s complex datacenters Intel today disclosed record breaking results on 20 and enterprise environments. Intel I/O Acceleration key dual-processor (DP) server and workstation Technology (Intel I/OAT) improves application benchmarks. The first processor due to launch response time, server I/O performance and based on the new Intel Core microarchitecture — reliability. the Dual-Core Intel Xeon processor 5100 series, previously codenamed “Woodcrest” — delivers up Intel’s new server and workstation platforms, to 125 percent performance improvement over codenamed “Bensley” and “Glidewell” previous generation dual-core Intel Xeon respectively, are architected for today’s dual-core processors and up to 60 percent performance processors. They will also support dual- and quad- improvement over competing x86-based core processors built using Intel’s 65-nanometer architectures, whilst also delivering performance (nm) and future process technologies. -

BRKINI-2390.Pdf
BRKINI-2390 Data Center security within modern compute and attached fabrics - servers, IO, management Dan Hanson Director UCS Architectures and Technical Marketing Cisco Spark Questions? Use Cisco Spark to communicate with the speaker after the session How 1. Find this session in the Cisco Live Mobile App 2. Click “Join the Discussion” 3. Install Spark or go directly to the space 4. Enter messages/questions in the space cs.co/ciscolivebot#BRKINI-2390 © 2018 Cisco and/or its affiliates. All rights reserved. Cisco Public Recent Press Items © 2018 Cisco and/or its affiliates. All rights reserved. Cisco Public Agenda • x86 Architecture Review • BIOS and Kernel Manipulation • Device Firmware Manipulation • On Server Data Storage Manipulation • Segmentation and Device access • Root of Trust Flow • Policy Control vs. Component Configuration (Cisco UCS and ACI) • Example of Security Offloading: Skyport Systems • Conclusion x86 Architecture Review Many Points of possible attack X86 Reference Legacy Elements • You may see many terms in various articles shown here • Over time, items moving on the CPU itself • Memory • PCIe • Processors/Servers differentiation in some areas • Front Side Bus speeds • Direct Media Interface • Southbridge Configurations BRKINI-2390 © 2018 Cisco and/or its affiliates. All rights reserved. Cisco Public 7 X86 Reference Fundamental Architecture • Not shown: Quick Path Interconnect/UltraPath Interconnect for CPU to CPU communications • Varied counts and speeds for multi-socket systems • Current Designs have On-Die PCIe and Memory controllers • Varied numbers and DIMMs in memory channels by CPU • Platform Controller Hub varies and can even offer server acceleration and security functions BRKINI-2390 © 2018 Cisco and/or its affiliates. -

Product Brief: Intel® Xeon® Scalable Platform
PRODUCT BRIEF Intel® Xeon® Scalable Platform The Future-Forward Platform Foundation for Agile Digital Services Empowering Transformation in a Digital World Across an evolving digital world, disruptive and emerging technology trends in business, industry, science, and entertainment increasingly impact the world’s economies. By 2020, the success of half of the world’s Global 2000 companies will depend on their abilities to create digitally enhanced products, services, and experiences,1 and large organizations expect to see an 80 percent increase in their digital revenues,2 all driven by advancements in technology and usage models they enable. This global transformation is rapidly scaling the demands for flexible compute, networking, and storage. Future workloads will necessitate infrastructures that can seamlessly scale to support immediate responsiveness and widely diverse performance requirements. The exponential growth of data generation and consumption, the rapid expansion of cloud-scale computing, emerging 5G networks, and the extension of high-performance computing (HPC) and artificial intelligence (AI) into new usages require that today’s data centers and networks urgently evolve—or be left behind in a highly competitive environment. These demands are driving the architecture of modernized, future-ready data centers and networks that can quickly flex and scale. The Intel® Xeon® Scalable platform provides the foundation for a powerful data center platform that creates an evolutionary leap in agility and scalability.3 Disruptive by design, this innovative processor sets a new level of platform convergence and capabilities across compute, storage, memory, network, and security. Enterprises and cloud and communications service providers can now drive forward their most ambitious digital initiatives with a feature-rich, highly versatile platform.