Inside Intel® Core™ Microarchitecture and Smart Memory Access an In-Depth Look at Intel Innovations for Accelerating Execution of Memory-Related Instructions
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

AMD Athlon™ Processor X86 Code Optimization Guide
AMD AthlonTM Processor x86 Code Optimization Guide © 2000 Advanced Micro Devices, Inc. All rights reserved. The contents of this document are provided in connection with Advanced Micro Devices, Inc. (“AMD”) products. AMD makes no representations or warranties with respect to the accuracy or completeness of the contents of this publication and reserves the right to make changes to specifications and product descriptions at any time without notice. No license, whether express, implied, arising by estoppel or otherwise, to any intellectual property rights is granted by this publication. Except as set forth in AMD’s Standard Terms and Conditions of Sale, AMD assumes no liability whatsoever, and disclaims any express or implied warranty, relating to its products including, but not limited to, the implied warranty of merchantability, fitness for a particular purpose, or infringement of any intellectual property right. AMD’s products are not designed, intended, authorized or warranted for use as components in systems intended for surgical implant into the body, or in other applications intended to support or sustain life, or in any other applica- tion in which the failure of AMD’s product could create a situation where per- sonal injury, death, or severe property or environmental damage may occur. AMD reserves the right to discontinue or make changes to its products at any time without notice. Trademarks AMD, the AMD logo, AMD Athlon, K6, 3DNow!, and combinations thereof, AMD-751, K86, and Super7 are trademarks, and AMD-K6 is a registered trademark of Advanced Micro Devices, Inc. Microsoft, Windows, and Windows NT are registered trademarks of Microsoft Corporation. -

A Dual Core Processor Has Two Cores (Essentially, Two Cpus on One Chip)
Faculty of Engineering & Information Technology Al-Azhar University-Gaza Dr. Mohammad Aqel Microprocessors and Interfacing (ITCC 3301) Homework (1) Intel Core is a brand name used for various mid-range to high-end consumer and business microprocessors made by Intel. In general, processors sold as Core are more powerful variants of the same processors marketed as entry-level Celeron and Pentium. Similarly, identical or more capable versions of Core processors are also sold as Xeon processors for the server market. The current lineup of Core processors includes the latest Intel Core i7, Intel Core i5 and Intel Core i3, and the older Intel Core 2 Solo, Intel Core 2 Duo, Intel Core 2 Quad, and Intel Core 2 Extreme lines. 1- The original Core brand refers to Intel's 32-bit dual-core x86 CPUs. 2- Unlike the Intel Core, Intel Core 2 is a 64-bit processor, supporting Intel 64. The Core brand comprised two branches: the Duo (dual-core) and Solo (Duo with one disabled core). A dual core processor has two cores (essentially, two CPUs on one die (piece) silicon chip (IC)). Core2Duo is a specific dual-core processor design. Thus, all Core2Duo CPUs are dual-core CPUs, but not all Intel dual-core CPUs are Core2Duo designs. Core 2 is a brand encompassing a range of Intel's consumer 64-bit x86-64 single-, dual-, and quad-core microprocessors based on the Core microarchitecture. The single- and dual-core models are single-die, whereas the quad-core models comprise two dies, each containing two cores, packaged in a multi-chip module. -

Inside Intel® Core™ Microarchitecture Setting New Standards for Energy-Efficient Performance
White Paper Inside Intel® Core™ Microarchitecture Setting New Standards for Energy-Efficient Performance Ofri Wechsler Intel Fellow, Mobility Group Director, Mobility Microprocessor Architecture Intel Corporation White Paper Inside Intel®Core™ Microarchitecture Introduction Introduction 2 The Intel® Core™ microarchitecture is a new foundation for Intel®Core™ Microarchitecture Design Goals 3 Intel® architecture-based desktop, mobile, and mainstream server multi-core processors. This state-of-the-art multi-core optimized Delivering Energy-Efficient Performance 4 and power-efficient microarchitecture is designed to deliver Intel®Core™ Microarchitecture Innovations 5 increased performance and performance-per-watt—thus increasing Intel® Wide Dynamic Execution 6 overall energy efficiency. This new microarchitecture extends the energy efficient philosophy first delivered in Intel's mobile Intel® Intelligent Power Capability 8 microarchitecture found in the Intel® Pentium® M processor, and Intel® Advanced Smart Cache 8 greatly enhances it with many new and leading edge microar- Intel® Smart Memory Access 9 chitectural innovations as well as existing Intel NetBurst® microarchitecture features. What’s more, it incorporates many Intel® Advanced Digital Media Boost 10 new and significant innovations designed to optimize the Intel®Core™ Microarchitecture and Software 11 power, performance, and scalability of multi-core processors. Summary 12 The Intel Core microarchitecture shows Intel’s continued Learn More 12 innovation by delivering both greater energy efficiency Author Biographies 12 and compute capability required for the new workloads and usage models now making their way across computing. With its higher performance and low power, the new Intel Core microarchitecture will be the basis for many new solutions and form factors. In the home, these include higher performing, ultra-quiet, sleek and low-power computer designs, and new advances in more sophisticated, user-friendly entertainment systems. -

Dual-Core Intel® Xeon® Processor 3100 Series Specification Update
Dual-Core Intel® Xeon® Processor 3100 Series Specification Update — on 45 nm Process in the 775-land LGA Package December 2010 Notice: Dual-Core Intel® Xeon® Processor 3100 Series may contain design defects or errors known as errata which may cause the product to deviate from published specifications. Current characterized errata are documented in this Specification Update. Document Number: 319006-009 INFORMATION IN THIS DOCUMENT IS PROVIDED IN CONNECTION WITH INTEL® PRODUCTS. NO LICENSE, EXPRESS OR IMPLIED, BY ESTOPPEL OR OTHERWISE, TO ANY INTELLECTUAL PROPERTY RIGHTS IS GRANTED BY THIS DOCUMENT. EXCEPT AS PROVIDED IN INTEL’S TERMS AND CONDITIONS OF SALE FOR SUCH PRODUCTS, INTEL ASSUMES NO LIABILITY WHATSOEVER, AND INTEL DISCLAIMS ANY EXPRESS OR IMPLIED WARRANTY, RELATING TO SALE AND/OR USE OF INTEL PRODUCTS INCLUDING LIABILITY OR WARRANTIES RELATING TO FITNESS FOR A PARTICULAR PURPOSE, MERCHANTABILITY, OR INFRINGEMENT OF ANY PATENT, COPYRIGHT OR OTHER INTELLECTUAL PROPERTY RIGHT. UNLESS OTHERWISE AGREED IN WRITING BY INTEL, THE INTEL PRODUCTS ARE NOT DESIGNED NOR INTENDED FOR ANY APPLICATION IN WHICH THE FAILURE OF THE INTEL PRODUCT COULD CREATE A SITUATION WHERE PERSONAL INJURY OR DEATH MAY OCCUR. Intel products are not intended for use in medical, life saving, or life sustaining applications. Intel may make changes to specifications and product descriptions at any time, without notice. Designers must not rely on the absence or characteristics of any features or instructions marked “reserved” or “undefined.” Intel reserves these for future definition and shall have no responsibility whatsoever for conflicts or incompatibilities arising from future changes to them. Enabling Execute Disable Bit functionality requires a PC with a processor with Execute Disable Bit capability and a supporting operating system. -

Microcode Revision Guidance August 31, 2019 MCU Recommendations
microcode revision guidance August 31, 2019 MCU Recommendations Section 1 – Planned microcode updates • Provides details on Intel microcode updates currently planned or available and corresponding to Intel-SA-00233 published June 18, 2019. • Changes from prior revision(s) will be highlighted in yellow. Section 2 – No planned microcode updates • Products for which Intel does not plan to release microcode updates. This includes products previously identified as such. LEGEND: Production Status: • Planned – Intel is planning on releasing a MCU at a future date. • Beta – Intel has released this production signed MCU under NDA for all customers to validate. • Production – Intel has completed all validation and is authorizing customers to use this MCU in a production environment. -

Single Board Computer
Single Board Computer SBC with the Intel® 8th generation Core™/Xeon® (formerly Coffee Lake H) SBC-C66 and 9th generation Core™ / Xeon® / Pentium® / Celeron® (formerly Coffee Lake Refresh) CPUs High-performing, flexible solution for intelligence at the edge HIGHLIGHTS CONNECTIVITY CPU 2x USB 3.1; 4x USB 2.0; NVMe SSD Slot; PCI-e x8 Intel® 8th gen. Core™ / Xeon® and 9th gen. Core™ / port (PCI-e x16 mechanical slot); VPU High Speed Xeon® / Pentium® / Celeron® CPUs Connector with 4xUSB3.1 + 2x PCI-ex4 GRAPHICS MEMORY Intel® UHD Graphics 630/P630 architecture, up to 128GB DDR4 memory on 4x SO-DIMM Slots supports up to 3 independent displays (ECC supported) Available in Industrial Temperature Range MAIN FIELDS OF APPLICATION Biomedical/ Gaming Industrial Industrial Surveillance Medical devices Automation and Internet of Control Things FEATURES ® ™ ® Intel 8th generation Core /Xeon (formerly Coffee Lake H) CPUs: Max Cores 6 • Intel® Core™ i7-8850H, Six Core @ 2.6GHz (4.3GHz Max 1 Core Turbo), 9MB Cache, 45W TDP (35W cTDP), with Max Thread 12 HyperThreading • Intel® Core™ i5-8400H, Quad Core @ 2.5GHz (4.2GHz Intel® QM370, HM370 or CM246 Platform Controller Hub Chipset Max 1 Core Turbo), 8MB Cache, 45W TDP (35W cTDP), (PCH) with HyperThreading • Intel® Core™ i3-8100H, Quad Core @ 3.0GHz, 6MB 2x DDR4-2666 or 4x DDR4-2444 ECC SODIMM Slots, up to 128GB total (only with 4 SODIMM modules). Cache, 45W TDP (35W cTDP) Memory ® ™ ® ® ECC DDR4 memory modules supported only with Xeon Core Information subject to change. Please visit www.seco.com to find the latest version of this datasheet Information subject to change. -
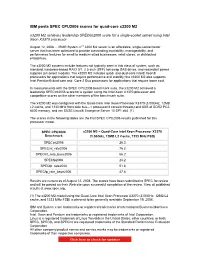
IBM Posts SPEC CPU2006 Scores for Quad-Core X3200 M2 X3200 M2 Achieves Leadership Specint2006 Score for a Single-Socket Server Using Intel Xeon X3370 Processor
IBM posts SPEC CPU2006 scores for quad-core x3200 M2 x3200 M2 achieves leadership SPECint2006 score for a single-socket server using Intel Xeon X3370 processor August 12, 2008 ... IBM® System xTM 3200 M2 server is an affordable, single-socket tower server that has been optimized to provide outstanding availability, manageability, and performance features for small to medium-sized businesses, retail stores, or distributed enterprises. The x3200 M2 systems include features not typically seen in this class of system, such as standard, hardware-based RAID 0/1, 2.5-inch (SFF) hot-swap SAS drives, and redundant power supplies (on select models). The x3200 M2 includes quad- and dual-core Intel® Xeon® processors for applications that require performance and stability; the x3200 M2 also supports Intel Pentium® dual-core and Core 2 Duo processors for applications that require lower cost. In measurements with the SPEC CPU2006 benchmark suite, the x3200 M2 achieved a leadership SPECint2006 score for a system using the Intel Xeon X3370 processor and competitive scores on the other members of the benchmark suite. The x3200 M2 was configured with the Quad-Core Intel Xeon Processor X3370 (3.00GHz, 12MB L2 cache, and 1333 MHz front-side bus—1 processor/4 cores/4 threads) and 8GB of DDR2 PC2- 6400 memory, and ran SUSE Linux® Enterprise Server 10 SP1 x64. (1) The scores in the following tables are the first SPEC CPU2006 results published for this processor model. SPEC CPU2006 x3200 M2 – Quad-Core Intel Xeon Processor X3370 Benchmark (3.00GHz, 12MB L2 Cache, 1333 MHz FSB) SPECint2006 26.3 SPECint_rate2006 76.2 SPECint_rate_base2006 66.2 SPECfp2006 24.2 SPECfp_rate2006 51.8 SPECfp_rate_base2006 47.8 Results are current as of August 12, 2008. -

Data Sampling on MDS-Resistant 10Th Generation Intel Core (Ice Lake) 1
Data Sampling on MDS-resistant 10th Generation Intel Core (Ice Lake) Daniel Moghimi Worcester Polytechnic Institute, Worcester, MA, USA Abstract the store buffer. MSBDS has been shown in attacks on the kernel space as well as on SGX [1]. In addition to the leakage Microarchitectural Data Sampling (MDS) is a set of hardware component, MSBDS can also be turned around easily to tran- vulnerabilities in Intel CPUs that allows an attacker to leak siently inject values into a victim, an attack technique known bytes of data from memory loads and stores across various as Load Value Injection (LVI) [14]. security boundaries. On affected CPUs, some of these vulner- abilities were patched via microcode updates. Additionally, To mitigate these vulnerabilities, Intel released software Intel announced that the newest microarchitectures, namely workarounds and microcode updates for affected CPUs [4]. Cascade Lake and Ice Lake, were not affected by MDS. While One of the most recent microarchitectures, Ice Lake, is re- Cascade Lake turned out to be vulnerable to the ZombieLoad ported to be unaffected by MDS attacks [6,8]. Intel has also v2 MDS attack (also known as TAA), Ice Lake was not af- explicitly listed Ice Lake processors as not being vulnera- fected by this attack. ble to LVI-SB [14], which exploits MSBDS for Load Value Injection [7]. In this technical report, we show a variant of MSBDS (CVE- 2018-12126), an MDS attack, also known as Fallout, that To better analyze the MDS vulnerabilities, and potentially works on Ice Lake CPUs. This variant was automatically find new variants, Moghimi et al. -

Sgxometer: Open and Modular Benchmarking for Intel SGX
SGXoMeter: Open and Modular Benchmarking for Intel SGX Mohammad Mahhouk Nico Weichbrodt Rüdiger Kapitza TU Braunschweig, Germany TU Braunschweig, Germany TU Braunschweig, Germany ABSTRACT mobile devices like phones and tablets. Also, personal computers, Intel’s Software Guard Extensions (SGX) are currently the most laptops and servers can be secured using AMD Secure Encrypted wide-spread commodity trusted execution environment, which Virtualisation [22, 23], and Intel SGX [24, 27]. provides integrity and confidentiality of sensitive code and data. Intel SGX promises with its isolated memory regions, so called Thereby, it offers protection even against privileged attackers and enclaves, both confidentiality and integrity protection of the sen- various forms of physical attacks. As a technology that only be- sitive data and code running inside them against malicious and came available in late 2015, it has received massive interest and privileged software. It also provides local and remote attestation undergone a rapid evolution. Despite first ad-hoc attempts, there is mechanisms [21] to ensure the authenticity and integrity of the so far no standardised approach to benchmark the SGX hardware, running enclaves, adding protection against forging attempts. Thus, its associated environment, and techniques that were designed to the utilisation of SGX in cloud services can considerably reduce harden SGX-based applications. the customers’ reluctance of using them. Furthermore, Intel has re- In this paper, we present SGXoMeter, an open and modular leased a Software Development Kit (SDK)[18] to ease programming framework designed to benchmark different SGX-aware CPUs, with SGX. It introduces wrappers for low-level instructions and `code revisions, SDK versions and extensions to mitigate side- provides a high-level interface that offers multiple functionalities, channel attacks. -

A Superscalar Out-Of-Order X86 Soft Processor for FPGA
A Superscalar Out-of-Order x86 Soft Processor for FPGA Henry Wong University of Toronto, Intel [email protected] June 5, 2019 Stanford University EE380 1 Hi! ● CPU architect, Intel Hillsboro ● Ph.D., University of Toronto ● Today: x86 OoO processor for FPGA (Ph.D. work) – Motivation – High-level design and results – Microarchitecture details and some circuits 2 FPGA: Field-Programmable Gate Array ● Is a digital circuit (logic gates and wires) ● Is field-programmable (at power-on, not in the fab) ● Pre-fab everything you’ll ever need – 20x area, 20x delay cost – Circuit building blocks are somewhat bigger than logic gates 6-LUT6-LUT 6-LUT6-LUT 3 6-LUT 6-LUT FPGA: Field-Programmable Gate Array ● Is a digital circuit (logic gates and wires) ● Is field-programmable (at power-on, not in the fab) ● Pre-fab everything you’ll ever need – 20x area, 20x delay cost – Circuit building blocks are somewhat bigger than logic gates 6-LUT 6-LUT 6-LUT 6-LUT 4 6-LUT 6-LUT FPGA Soft Processors ● FPGA systems often have software components – Often running on a soft processor ● Need more performance? – Parallel code and hardware accelerators need effort – Less effort if soft processors got faster 5 FPGA Soft Processors ● FPGA systems often have software components – Often running on a soft processor ● Need more performance? – Parallel code and hardware accelerators need effort – Less effort if soft processors got faster 6 FPGA Soft Processors ● FPGA systems often have software components – Often running on a soft processor ● Need more performance? – Parallel -

8Th Generation Intel® Core™ Processors Product Brief
PRODUCT BRIEF 8TH GENERATION INTEL® CORE™ PROCESSORS Mobile U-Series: Peak Performance on the Go The new 8th generation Intel® Core™ Processor U-series—for sleek notebooks and 2 in 1s elevates your computing experience with an astounding 40 percent leap in productivity performance over 7th Gen PCs,1 brilliant 4K Ultra HD entertainment, and easier, more convenient ways to interact with your PC. With 10 hour battery life2 and robust I/O support, Intel’s first quad-core U-series processors enable portable, powerhouse thin and light PCs, so you can accomplish more on the go. Extraordinary Performance and Responsiveness With Intel’s latest power-efficient microarchitecture, advanced process technology, and silicon optimizations, the 8th generation Intel Core processor (U-series) is Intel’s fastest 15W processor3 with up to 40 percent greater productivity than 7th Gen processors and 2X more productivity vs. comparable 5-year-old processors.4 • Get fast and responsive web browsing with Intel® Speed Shift Technology. • Intel® Turbo Boost Technology 2.0 lets you work more productively by dynamically controlling power and speed—across cores and graphics— boosting performance precisely when it is needed, while saving energy when it counts. • With up to four cores, 8th generation Intel Core Processor U-series with Intel® Hyper-Threading Technology (Intel® HT Technology) supports up to eight threads, making every day content creation a compelling experience on 2 in 1s and ultra-thin clamshells. • For those on the go, PCs enabled with Microsoft Windows* Modern Standby wake instantly at the push of a button, so you don’t have to wait for your system to start up. -

6Th Gen Intel® Core™ Desktop Processor Product Brief
Product Brief 6th Gen Intel® Core™ Processors for Desktops: S-series LOOKING FOR AN AMAZING PROCESSOR for your next desktop PC? Look no further than 6th Gen Intel® Core™ processors. With amazing performance and stunning visuals, PCs powered by 6th Gen Intel Core processors will help take things to the next level and transform how you use a PC. The performance of 6th Gen Intel Core processors enable great user experiences today and in the future, including no passwords and more natural user interfaces. When paired with Intel® RealSense™ technology and Windows* 10, 6th Gen Intel Core processors can help remove the hassle of remembering and typing in passwords. Product Brief 6th Gen Intel® Core™ Processors for Desktops: S-series THAT RESPONSIVE PERFORMANCE EXTRA New architecture and design in 6th Gen Intel Core processors for desktops bring: BURST OF Support for DDR4 RAM memory technology in mainstream platforms, allowing systems to have up to 64GB of memory and higher transfer PERFORMANCE speeds at lower power when compared to DDR3 (DDR4 speed 2133 MT/s at 1.2V vs DDR3 speed 1600 MT/s at 1.5). 6th Gen Intel Core i7 and Core i5 processors come with Intel® Turbo boost 2.0 Technology which gives you that extra burst of performance for those jobs that require a bit more frequency.1 Intel ® Hyper-Threading Technology1 allows each processor core to work on two tasks at the same time, improving multitasking, speeding up the workfl ow, and accomplishing more in less time. With the Intel Core i7 processor you can have up to 8 threads running at the same time.