Neural Netowkrs: Genetic-Based Learning, Network Architecture
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Object Summary Collections 11/19/2019 Collection·Contains Text·"Manuscripts"·Or Collection·Contains Text·"University"·And Status·Does Not Contain Text·"Deaccessioned"
Object_Summary_Collections 11/19/2019 Collection·Contains text·"Manuscripts"·or Collection·Contains text·"University"·and Status·Does not contain text·"Deaccessioned" Collection University Archives Artifact Collection Image (picture) Object ID 1993-002 Object Name Fan, Hand Description Fan with bamboo frame with paper fan picture of flowers and butterflies. With Chinese writing, bamboo stand is black with two legs. Collection University Archives Artifact Collection Image (picture) Object ID 1993-109.001 Object Name Plaque Description Metal plaque screwed on to wood. Plaque with screws in corner and engraved lettering. Inscription: Dr. F. K. Ramsey, Favorite professor, V. M. Class of 1952. Collection University Archives Artifact Collection Image (picture) Object ID 1993-109.002 Object Name Award Description Gold-colored, metal plaque, screwed on "walnut" wood; lettering on brown background. Inscription: Present with Christian love to Frank K. Ramsey in recognition of his leadership in the CUMC/WF resotration fund drive, June 17, 1984. Collection University Archives Artifact Collection Image (picture) Object ID 1993-109.003 Object Name Plaque Description Wood with metal plaque adhered to it; plque is silver and black, scroll with graphic design and lettering. Inscription: To Frank K. Ramsey, D. V. M. in appreciation for unerring dedication to teaching excellence and continuing support of the profession. Class of 1952. Page 1 Collection University Archives Artifact Collection Image (picture) Object ID 1993-109.004 Object Name Award Description Metal plaque screwed into wood; plaque is in scroll shape on top and bottom. Inscription: 1974; Veterinary Service Award, F. K. Ramsey, Iowa Veterinary Medical Association. Collection University Archives Artifact Collection Image (picture) Object ID 1993-109.005 Object Name Award Description Metal plaque screwed onto wood; raised metal spray of leaves on lower corner; black lettering. -
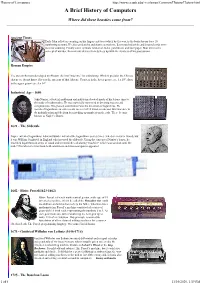
A Brief History of Computers
History of Computers http://www.cs.uah.edu/~rcoleman/Common/History/History.html A Brief History of Computers Where did these beasties come from? Ancient Times Early Man relied on counting on his fingers and toes (which by the way, is the basis for our base 10 numbering system). He also used sticks and stones as markers. Later notched sticks and knotted cords were used for counting. Finally came symbols written on hides, parchment, and later paper. Man invents the concept of number, then invents devices to help keep up with the numbers of his possessions. Roman Empire The ancient Romans developed an Abacus, the first "machine" for calculating. While it predates the Chinese abacus we do not know if it was the ancestor of that Abacus. Counters in the lower groove are 1 x 10 n, those in the upper groove are 5 x 10 n Industrial Age - 1600 John Napier, a Scottish nobleman and politician devoted much of his leisure time to the study of mathematics. He was especially interested in devising ways to aid computations. His greatest contribution was the invention of logarithms. He inscribed logarithmic measurements on a set of 10 wooden rods and thus was able to do multiplication and division by matching up numbers on the rods. These became known as Napier’s Bones. 1621 - The Sliderule Napier invented logarithms, Edmund Gunter invented the logarithmic scales (lines etched on metal or wood), but it was William Oughtred, in England who invented the sliderule. Using the concept of Napier’s bones, he inscribed logarithms on strips of wood and invented the calculating "machine" which was used up until the mid-1970s when the first hand-held calculators and microcomputers appeared. -

Developing Our Future Atanasoff Today
Atanasoff Today Developing Our Future Fall 2015/ Winter 2016 Message from the Chair Greetings Alumni and Friends of Iowa State University I am now in the middle of my second year as Chair of This past year saw many Computer Science, and I am happy to say that it just of our students bring keeps getting better. Currently, I am appreciating the full home top honors. A cycle of academic activities; from the rush to get ready team of our students to start a new academic year, to the welcoming of the competed in the ACM many new undergraduate and graduate students. I am International Collegiate also enjoying exploring new educational and curricular Programming Contest directions and celebrating the many accomplishments (ICPC) World Finals, in of our students and faculty. In fact, after moving to Marrakech, Morocco. Iowa State, I have even learned to appreciate the full cycle of seasons (the perennial warm weather of This is the most Southern California now just seems soooo boring...). prestigious programming competition in This past year, we have been very busy. In Fall 2014, the the world with Computer Science Chair: department hired two Assistant Professors: Wei Le, who thousands of schools Gianfranco Ciardo works in software testing and software reliability, and Jeremy hoping to reach the Sheaffer, who works in high-performance computing and finals, but only 128 actually doing so. This is the second hardware architectures for computer graphics. Both have a year in a row that our department has sent a team to the PhD in computer science from the University of Virginia. -

Pioneers of Computing
Pioneers of Computing В 1980 IEEE Computer Society учредило Золотую медаль (бронзовую) «Вычислительный Пионер» Пионерами учредителями стали 32 члена IEEE Computer Society, связанных с работами по информатике и вычислительным наукам. 1 Pioneers of Computing 1.Howard H. Aiken (Havard Mark I) 2.John V. Atanasoff 3.Charles Babbage (Analytical Engine) 4.John Backus 5.Gordon Bell (Digital) 6.Vannevar Bush 7.Edsger W. Dijkstra 8.John Presper Eckert 9.Douglas C. Engelbart 10.Andrei P. Ershov (theroretical programming) 11.Tommy Flowers (Colossus engineer) 12.Robert W. Floyd 13.Kurt Gödel 14.William R. Hewlett 15.Herman Hollerith 16.Grace M. Hopper 17.Tom Kilburn (Manchester) 2 Pioneers of Computing 1. Donald E. Knuth (TeX) 2. Sergei A. Lebedev 3. Augusta Ada Lovelace 4. Aleksey A.Lyapunov 5. Benoit Mandelbrot 6. John W. Mauchly 7. David Packard 8. Blaise Pascal 9. P. Georg and Edvard Scheutz (Difference Engine, Sweden) 10. C. E. Shannon (information theory) 11. George R. Stibitz 12. Alan M. Turing (Colossus and code-breaking) 13. John von Neumann 14. Maurice V. Wilkes (EDSAC) 15. J.H. Wilkinson (numerical analysis) 16. Freddie C. Williams 17. Niklaus Wirth 18. Stephen Wolfram (Mathematica) 19. Konrad Zuse 3 Pioneers of Computing - 2 Howard H. Aiken (Havard Mark I) – США Создатель первой ЭВМ – 1943 г. Gene M. Amdahl (IBM360 computer architecture, including pipelining, instruction look-ahead, and cache memory) – США (1964 г.) Идеология майнфреймов – система массовой обработки данных John W. Backus (Fortran) – первый язык высокого уровня – 1956 г. 4 Pioneers of Computing - 3 Robert S. Barton For his outstanding contributions in basing the design of computing systems on the hierarchical nature of programs and their data. -

John Vincent Atanasoff
John Vincent Atanasoff Born October 4, 1903, Hamilton N. Y; inventor of the Atanasoff Berry Computer (ABC) with Clifford Berry, predecessor of the 1942 ENIAC, a serial, binary, electromechanical, digital, special-purpose computer with regenerative memory. Education: BSEE, University of Florida, 1925; MS, Iowa State College (now University), 1926; PhD, physics, University of Wisconsin, 1930. Professional Experience: graduate professor at Iowa State College (now University), 1930-1942; US Naval Ordnance Laboratory, 1942-1952; founder, Ordnance Engineering Corp., 1952-1956; vice-president, Atlantic Dir., Aerojet General Corp., 1950-1961. Honors and Awards: US Navy Distinguished Service Award 1945; Bulgarian Order of Cyril and Methodius, First Class, 1970; doctor of science, University of Florida, 1974; Iowa Inventors Hall of Fame, 1978; doctor of science, Moravian College, 1981; Distinguished Achievement Citation, Alumni Association, Iowa State University, 1983; Foreign Member, Bulgarian Academy of Science, 1983; LittD, Western Maryland College, 1984; Pioneer Medal, IEEE Computer Society, 1984; Appreciation Award, EDUCOM, 1985; Holley Medal, ASME, 1985; DSc (Hon.), University of Wisconsin, 1985; First Annual Coors American Ingenuity Award, Colorado Association of Commerce and Industry, 1986; LHD (Hon)., Mount St. Mary's College, 1990; US Department of Commerce, Medal of Technology, 1990,1 IEEE Electrical Engineering Milestone, 1990. Special Honors: Atanasoff Hall, named by Iowa State University; Asteroid 3546-Atanasoff-named by Cal Tech Jet Propulsion Laboratory and Bulgarian Academy. Advent of Electronic Digital Computing2 Introduction I am writing a historical account of what has been an important episode in my life. During the last half of the 1930s I began and, later with Clifford E. Berry, pursued the subject of digital electronic computing. -

Print This Edition (PDF) RSS | Twitter SEARCH INSIDE
SEARCH INSIDE Inside Home | Calendar | Submit News | Archives | About Us | Employee Resources Announcements Phi Kappa Phi initiation March 28 Food drive begins March 29 More functionality for U-Bill Alum Steve King featured during April 6 Reiman entrepreneur series April 1 P&S open forum will focus on ISU FY11 budget planning RSVPs requested for May 6 Lavender Graduation Reserve a spot at ISU Dining's spring brunch April 4 Register for mobile campus lecture University Book Store closed for inventory March 27 Lab safety summit March 26 Nominations for P&S CYtation Award are due March 31 March 25 Chemistry Stores ordering will be Taking the replica cross-country online only, starting April 12 The Atanasoff-Berry Computer replica was moved last week to the Computer History Museum in Mountain View, Calif. It is part of a new exhibit that will be on display for at least 10 years. Receptions & open houses March 25 Experience international cultures at gala event Reception The Global Gala, ISU's annual celebration of cultural diversity, will YWCA Ames-ISU Women of be held March 26. ISU groups scheduled to perform include the Achievement awards and Indian Students' Association, ISU Bhangra, The Celtic Dance scholarships, March 25 Society, Raqs Jahanara, Descarga and the African Students Association. Retirements JoAnn McKinney, March 30 March 25 Martha Olson, March 31 RIO2 application deadline extended to June 1 Neil Nakadate, April 1 Meeting by phone March 24, the state Board of Regents approved a new June 1 application deadline for ISU's second retirement Global Gala incentive option, reviewed proposed parking permit and student Arts & events room and board rates for next year, gave final approval to replacement plans for the horticulture department's greenhouses, directed the regent schools to review specific services for possible consolidation and cost savings, and asked university presidents to develop plans to phase out state funding for their athletics programs. -

Atanasoff-Berry Computer Replica Moves to Computer History Museum
ECpECONNECTIONS The Department of Electrical and Computer Engineering Newsletter for Alumni and Friends l Spring 2010 Atanasoff-Berry Computer Replica Moves to Computer History Museum MORE NEWS: • Three Faculty Receive NSF CAREER Awards • Scholarships Impact Students’ Lives • Alumni Raise Funds to Honor Emeritus Professor www.ece.iastate.edu departmentNEWS Letter from the Chair IN THIS ISSUE Dear alumni and friends, departmentNEWS Aluru, Biswas Named IEEE, APS Fellow ................. page 4 s you may have heard, I will be stepping down as chair of Iowa Iowa State Hosts Third Annual Community AState’s Department of Electrical and Computer Engineering (ECpE) College Cyber Defense Contest ............................. page 4 on June 30. It has been a great honor to serve as the department’s chair Iowa State Hosts IT-Olympics Student for the past seven years, and expand upon the foundation that previous chairs, including my Contest for Third Year .......................................... page 4 predecessor, Mani Venkata, established. ISU Replica of First Electronic Digital Computer to During my tenure as chair, I have aimed to lead the department in a direction that al- be Displayed at Computing History Museum ......... page 5 lows it to grow in multiple directions. We created a new strategic plan for the department in Calendar of Events .............................................. page 6 2003-04 and identified five strategic research areas—bioengineering, cyber infrastructure, Three ECpE Faculty Receive NSF CAREER Awards .. page 6 distributed sensing and decision making, energy infrastructure, and small-scale technology. We have used these areas to strategically grow the department and its infrastructure, and researchNEWS recruit 18 new faculty. Our research expenditures increased from about $5.7 million per year ECpE Professors Use ARRA Funding to to more than $10 million per year during this time. -

John Vincent Atanasoff
John Vincent Atanasoff: Inventor of the Digital Computer October 3, 2006 History of Computer Science (2R930) Department of Mathematics & Computer Science Technische Universiteit Eindhoven Bas Kloet 0461462 [email protected] Paul van Tilburg 0459098 [email protected] Abstract This essay is about John Vincent Atanasoff’s greatest invention, the Atana- soff Berry Computer or ABC. We look into the design and construction of this computer, and also determine the effect the ABC has had on the world. While discussing this machine we cannot avoid the dispute and trial surrounding the ENIAC patents. We will try to put the ENIAC in the right context with respect to the ABC. Copyright c 2006 Bas Kloet and Paul van Tilburg The contents of this and the following documents and the LATEX source code that is used to generate them is licensed under the Creative Commons Attribution-ShareAlike 2.5 license. Photos and images are excluded from this copyright. They were taken from [Mac88], [BB88] and [Mol88] and thus fall under their copyright accordingly. You are free: • to copy, distribute, display, and perform the work • to make derivative works • to make commercial use of the work Under the following conditions: Attribution: You must attribute the work in the manner specified by the author or licensor. Share Alike: If you alter, transform, or build upon this work, you may distribute the resulting work only under a license identical to this one. • For any reuse or distribution, you must make clear to others the license terms of this work. • Any of these conditions can be waived if you get permission from the copyright holder. -
Pioneercomputertimeline2.Pdf
Memory Size versus Computation Speed for various calculators and computers , IBM,ZQ90 . 11J A~len · W •• EDVAC lAS• ,---.. SEAC • Whirlwind ~ , • ENIAC SWAC /# / Harvard.' ~\ EDSAC Pilot• •• • ; Mc;rk I " • ACE I • •, ABC Manchester MKI • • ! • Z3 (fl. pt.) 1.000 , , .ENIAC •, Ier.n I i • • \ I •, BTL I (complexV • 100 ~ . # '-------" Comptometer • Ir.ne l ' with constants 10 0.1 1.0 10 100 lK 10K lOOK 1M GENERATIONS: II] = electronic-vacuum tube [!!!] = manual [1] = transistor Ime I = mechanical [1] = integrated circuit Iem I = electromechanical [I] = large scale integrated circuit CONTENTS THE COMPUTER MUSEUM BOARD OF DIRECTORS The Computer Museum is a non-profit. Kenneth H. Olsen. Chairman public. charitable foundation dedicated to Digital Equipment Corporation preserving and exhibiting an industry-wide. broad-based collection of the history of in Charles W Bachman formation processing. Computer history is Cullinane Database Systems A Compcmion to the Pioneer interpreted through exhibits. publications. Computer Timeline videotapes. lectures. educational programs. C. Gordon Bell and other programs. The Museum archives Digital Equipment Corporation I Introduction both artifacts and documentation and Gwen Bell makes the materials available for The Computer Museum 2 Bell Telephone Laboratories scholarly use. Harvey D. Cragon Modell Complex Calculator The Computer Museum is open to the public Texas Instruments Sunday through Friday from 1:00 to 6:00 pm. 3 Zuse Zl, Z3 There is no charge for admission. The Robert Everett 4 ABC. Atanasoff Berry Computer Museum's lecture hall and rece ption The Mitre Corporation facilities are available for rent on a mM ASCC (Harvard Mark I) prearranged basis. For information call C. -

Pioneers of Computing
Social and Professional Issues in IT Pioneers of Computing Pioneers of Computing Many scientist and engineers have contributed in the development of computing science. This chapter covers all the major scientists and their works, who have played a significant role in the development of computing. Some of the major Pioneers of Computing and their contributions are described here Aristotle (384 BC, Stagira, Greece, 322 BC, Athens, Greece) He was one of the greatest ancient Greek philosophers of his time. Many of his thoughts have become the back bone of computing and artificial Intelligence. His work in the natural and social sciences greatly influenced virtually every area of modern thinking. Biography Aristotle was born in 384 BC in Stagira, on the northwest coast of the Aegean Sea. His father was a friend and the physician of the king of Macedonia, and the lad spent most of his boyhood at the court. At 17, he went to Athens to study. He enrolled at the famous Academy directed by the philosopher Plato. Aristotle threw himself wholeheartedly into Plato's pursuit of truth and goodness. Plato was soon calling him the "mind of the school." Aristotle stayed at the Academy for 20 years, leaving only when his beloved master died in 347 BC. In later years he renounced some of Plato's theories and went far beyond him in breadth of knowledge. Aristotle became a teacher in a school on the coast of Asia Minor. He spent two years studying marine biology on Lesbos. In 342 BC, Philip II invited Aristotle to return to the Macedonian court and teach his 13-year-old son Alexander. -

Irving H. Anellis Introduction a Close and Careful Study of the History Of
DISTORTIONS AND DISCONTINUITIES OF MATHEMATICAL PROGRESS: A MATTER OF STYLE, A MATTER OF LUCK, A MATTER OF TIME, ••• A MATTER OF FACT Irving H. Anellis Introduction A close and careful study of the history of mathematics provides evidence that mathematical progress is not necessarily linear or continuous; nor is it always evolving in precise logical steps, according to the rules of logic. Indeed, logic itself has evolved significantly since the days when Kant pronounced it to be a completed science, finished and in its final form with the pre sentation of Aristotle's Organon (see Kant, K.d.r.V., B viii). In the last years of the nineteenth century and the early years of our century, philosophers of mathematics, many of them trained in mathematics or the physical sciences, sought to un derstand mathematics in a Kantian sense, that is, as a completed body of knowledge, one which did not, however, develop dynam ically in time, but which, rather, developed statically, in logical space, from Euclidean-like axioms, into Euclidean-like theorems according to the rules of logical inference. By 'Euclidean-like' here, I do not intend to suggest that these late nineteenth and early twentieth-century philosophers, among them such crucial figures as Hilbert, Frege, Peano, or Russell, were unaware of the existence or importance of non-Euclidean geometries (for indeed, Russell's 1897 Essay on the Foundations of Geometry was devoted to an elaboration of the epistemological foundation of non Euclidean geometries, with special emphasis on projective ge ometry; and Hilbert's successive versions of his Grundlagen der Geometrie were meant to provide a system of axioms sufficiently general to serve as the inferential basis for all non-Euclidean geometries as well as for Euclidean geometry); rather, these thinkers ignored the nineteenth century developments of non Euclidean geometries, of noncom mutative and nonassociative al gebras in the historical sense, and treated them as logical deductions from a core of axioms which presented a complete and 164 IRVING H. -

GUIDE to AMES and IOWA STATE UNIVERSITY THINKAMES.COM This Guide Is Named After Cy, the Cardinal Welcome Mascot of Iowa State University
FALL 2018 / ISSUE 16 GUIDE TO AMES AND IOWA STATE UNIVERSITY THINKAMES.COM This guide is named after Cy, the cardinal Welcome mascot of Iowa State University. When you visit Ames, you might see Cy cheering with the To AMES fans at a Cyclone athletic event, entertaining guests during a special celebration or greeting We want to welcome you to CYtes students on central campus. We think Cy is the (pronounced sites), your official best mascot around, but don’t just take our guide to all of the sites throughout word for it; Cy has been nationally recognized Ames and Iowa State University. as the CBS Sportsline Most Dominant College Mascot on Earth and the Capital One Bowl National Mascot of the Year. TABLE OF 5 / DO 9 / SHOP CONTENTS 13 / EAT 17 / STAY 22 / AMES MAP ABOUT THE COVER Unlimited Possibilities, 1997 by Doug Shelton 25 / PLAN (American, b. 1941) 27 / IOWA STATE UNIVERSITY Mural commissioned by the University Museums. Funded by University Museums, the Office of External Affairs, 29 / ABOUT AMES the Fisher Representatives System Artist-in-Residence Fund at the ISU Foundation, the Estate of Alice Davis, 31 / LOCAL RESOURCES Marjorie Morrison, and Cornelia and William Buck. In the 39 / CALENDAR OF EVENTS Art on Campus Collection, University Museums, Iowa State University, Ames, Iowa. Location: Iowa State University, Parks Library, Rotunda Image provided by University Museums. 2 SHARE YOUR FAVORITES #CYTESOFAMES THINKAMES.COM / / CYTESOFAMES 515.232.4032 3 DO Reiman Gardens | Ames ATTRACTIONS & ENTERTAINMENT Enjoy the outdoors? Ames offers four seasons of recreational IT’S EASY TO STAY BUSY IN activities with more than 35 parks, 55 miles of bike trails, golf AMES, INDOORS AND OUT courses and much more.