Oceania, the Pacific Rim, and the Theory of Linguistic Areas
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
Best Wishes for Another Successful Asian Celebration!
With you for whatever comes next in life. Whatever you’re dreaming of — your first house, first year of college or first day of retirement — we’re here to help you get there. As an OCCU member, you’ll have 24/7 access to your accounts through our free online banking services including Internet Banking, mobile app, mobile deposit and online bill pay, plus 30,000 free ATMs nationwide and people in our branches who are genuinely glad to see you. That’s just the start. OregonCommunityCU.org COLLEGE MORTGAGE REFINANCING AUTO RETIREMENT BUSINESS SERVICES 541.687.2347 • 800.365.1111 Federally Insured by NCUA 2 Contents Main Stage & What’s New 4-5 Atrium Stage . 6 Martial Arts Stage . 7 Kumoricon Room . 8 Children’s Room . 9 THE 2015 OREGON Sponsored by Oregon Community Credit Union ASIAN CELEBRATION COMMITTEE and Copic Markers/Imagination International Chairpersons David Tam & Ardyn Wolfe Children’s Carnival . 9 Site Ken Nagao, Miriam Lasalita Arts & Crafts . 10 Finance Marvy Schuman, Chau Nguyen Arts exhibit sponsored by the University of Oregon Host/Tickets Frances Kucera Publicity/ Carrie Matsushita, David Tam, Asian Heritage & Justice . 11 Sponsors Marvy Schuman, Ardyn Wolfe An Event Is Born . 12-13 Advertising Marvy Schuman Main Stage Roger Yamaguchi, Ken Nagao Cooking Demonstrations . 15 Food Court Mike Takahashi Sponsored by Kikkoman Marketplace Sing Lee, Mengdan Lin Asian Marketplace . 16-17 Art Exhibit Teresa Hsu, Thaston Riklon, Kathy Hoy Food Court . 19 Crafts Jean Lee Children’s Room Shann Ormsbee Partner Events . 20 Martial Arts Alan Best Asian Resource Directory . 22 Asian Heritage Stephen Williamson Cooking Demos Maria Clark Warren, Jodi Willis, Site Map . -

Perspectives on Managing Natural Hazard Risk in Pacific Rim Countries
GUEST EDITORIAL Living on the Ring of Fire: Perspectives on Managing Natural Hazard Risk in Pacific Rim Countries Douglas Paton University of Tasmania, Australia rom the perspective of studying natural hazards, the peace and tranquillity that might be expected Ffrom a literal translation of its name does not always capture the reality of life for communities on the Pacific Rim. This reality is more readily discerned in its alter ego: the Ring of Fire. The latter leaves one in less doubt as to the hazardous circumstances likely to prevail in this region. In addition to the hazards posed by the numerous volcanoes that resulted in the ‘Ring of Fire’ appellation, communities situated around the Pacific Rim also have to contend with earthquakes, tsunami, storms, cyclones/typhoons, flood and bushfire. To this list of acute events can be added hazards of a chronic nature such as salinity, environmental degradation and sea-level rise that represent growing threats to many Pacific Rim countries. The region also faces increased risk from health-related hazards. Sydney, for example, has been identified as a pandemic hotspot as a result of it being a hub linking the airways of Asia and the United States. Recognition of the risk these hazards pose to Pacific Rim modate this issue and offer insights into how personal, communities has stimulated interest in identifying how to community, societal, cultural and organizational factors facilitate sustainability by developing community and interact to facilitate sustainability. Furthermore, they do societal capacity to co-exist with the potentially hazardous so in a way that supports the growing recognition of a elements in the environment (Paton, 2006a). -

USF Center for the Pacific Rim
Copyright 1988 -2007 USF Center for the Pacific Rim The Occasional Paper Series of the USF Center for the Pacific Rim :: www.pacificrim.usfca.edu Pacific Rim Report No. 52, January 2009 China’s Relations with Mexico and Cuba: A Study of Contrasts by Adrian H. Hearn, Ph.D. Adrian Hearn is a Senior Research Fellow at the University of Sydney, and Kiriyama Research Fellow at the University of San Francisco Center for the Pacific Rim. Adrian is conducting an anthropological study of the political and cultural implications of China’s deepening engagement with Latin America. Hearn has undertaken research in Cuba (three years), China (ten months), Senegal (one year), and Mexico (eight months), and is currently teaching a course on China-Latin America relations at the Universidad de Baja California. He is the author of Cuba: Religion, Social Capital, and Development (Duke University Press, 2008), China and Latin America: The Social Foundations of a Global Alliance (Duke University Press, forthcoming), and editor of Cultura, Tradición, y Comunidad: Perspectivas sobre el Desarrollo y Participación en Cuba (Imagen Contemporánea and UNESCO Center for Human Development 2008.) We gratefully acknowledge The Kiriyama Chair for Pacific Rim Studies at the USF Center for the Pacific Rim for underwriting the publication of this issue of Pacific Rim Report. In terms of economic openness and political ideology Mexico and Cuba are at opposite ends of the spectrum. Nevertheless, for China both hold high strategic value. Examining China’s relations with Mexico and Cuba opens an analytic window into the way that bilateral commercial, cultural, and diplomatic cooperation programs have adapted to distinct local conditions. -

Pacific Rim Topic Paper for the National Federation of High
Pacific Rim 1 Pacific Rim Topic Paper For the National Federation of High Schools 2015 Topic Selection Meeting By Chad Flisowski, Galveston-Ball HS When I first began research on this topic, I was initially surprised that the term “Pacific Rim” was a commonly used term of art, as I knew that the many countries bordering the Pacific Basin were very different. Indeed, the 54 countries commonly identified as Pacific Rim come from four different continents and represent vast differences in development and challenges. Because of the size and complexity of this region, as well as the fact that the ground for debate had no clear common factor, led me to consider narrowing the focus while still staying in the same region. After looking at a variety of options, I settled on ASEAN, or the Association of Southeast Asian Nations. Comprised of ten nations – Indonesia, Malaysia, the Philippines, Singapore, Thailand, Brunei, Cambodia, Laos, Myanmar (Burma), and Vietnam – this organization represents an economic region that, according to the ASEAN Community in Figures (2014), would rank as the seventh largest economy if it were a single nation. ASEAN presents several interesting options that I will continue to explore as my research develops. First, it is about to celebrate its 50th year as an organization, since it was founded with the Bangkok Declaration in 1967. Second, it is dedicated to being both an economic and political organization, much like the European Union. Third, it is actively engaged in the region and has strong ties to regional powers like China and Japan. Fourth, among its aims are continued progress in development, education, and security. -

Pacific Rim Specialty Cocktails House Infusions Bar Features Inglorious
Pacific Rim Specialty Cocktails Inglorious Cocktails obscure | unknown | unsung Queen of Thorns 11 Raynal VSOP brandy | Barolo Chinato vermouth | sparkling wine | lime juice | rose Red Lotus 9 Poblano Gimlet 12 Arbor vodka | Soho lychee liqueur | cranberry juice | lime wedge Hendrick's Gin | Cocchi Americano Bianco | poblano pepper | lime juice Pimm’s Cup 9 Pimm’s #1 | Fever Tree ginger brew | lemon juice | cucumber Seasonal Gin & Tonic 10 Moletto tomato infused gin | dill | house tonic with cinchona bark, Bee’s Knees 10 lemongrass, citrus, Rose hips Arbor ‘Spring’ gin | lemon juice | honey syrup Summerthyme 12 Martinez 11 Reyka vodka | Momokawa ‘Pearl’ Nigori sake | raspberry | lemon juice | Ransom Old Tom gin | Carpano Antica Formula vermouth | thyme Luxardo Maraschino | house-made blood orange bitters | orange twist Nanas Punch 11 Singapore Sling 10 Barsol pisco | Olmeca Altos Plata tequila | pineapple syrup| lemon juice Bombay ‘Sapphire – East’ gin | Cherry Heering | Bénédictine | lime juice | angostura bitters | soda Bitter Breeze 12 Paper Plane 11 Batavia Arrack sugarcane spirit | Amaro Nonino Quintessentia | lemon Maker’s Mark bourbon | Amaro Nonino Quintessentia | Contratto aperitif | juice | passionfruit | espresso orgeat lemon juice Shochu Lemonade 11 Sazerac 9 Kurokame Honkaku shochu | house lemonade | Madeira | zinfandel Rittenhouse rye | Vieux Carré absinthe | demerara | Peychaud’s bitters | reduction lemon twist Quiet T Please 11 Saratoga 10 House infused Chamomile Quiet Man Irish whiskey | honey syrup | soda Knob Creek -

California: America's Gateway for Pacific Rim Economies
® State Resource Sites for Business Governor’s Office of Economic Development (GoED) www.business.ca.gov Business, Transportation & Housing Agency www.bth.ca.gov Governor’s web page www.gov.ca.gov California: America’s Gateway for Pacific Rim Economies “Welcome to California. I hope you will “California’s diversity—in geography, enjoy the beauty and many attractions of population, agriculture, industries, and the Bay Area as you meet to discuss ways more—makes it fertile ground for ventures to improve trade and the lives of people with partners around the Pacific Rim.” along the Pacific Rim.” S. Shariq Yosufzai 2011 Chair, CalChamber Board Of Directors Governor Edmund G. Brown Jr. Vice President And Former President, Global Marketing, Chevron Corporation Leader in International Commerce/Investment California Advantages • California is a leading export state—$143+ billion in 2010— 11% of total U.S. exports. • California exported approximately $100 billion to the APEC economies in 2010, 13% of the national total. • Among California’s top trading partners are many of the 21 APEC economies—Mexico, Canada, China, Japan, South Agricultural Bounty Globally Connected with a World Class Infrastructure Korea, Hong Kong, Taiwan and Singapore, to name a few. • California is the No. 1 exporter in the nation of computers, • California produces more than 400 commodities, including • More than 15,000 miles of highways and freeways. electronic products, and sales of food and kindred products. nearly half of U.S.-grown fruits, nuts and vegetables. Across • 12 cargo airports and 11 cargo seaports—Pacific Rim access. Computers and electronic products are California’s top export, the nation, U.S. -

Western South Pacific Regional Workshop in Nadi, Fiji, 22 to 25 November 2011
SPINE .24” 1 1 Ecologically or Biologically Significant Secretariat of the Convention on Biological Diversity 413 rue St-Jacques, Suite 800 Tel +1 514-288-2220 Marine Areas (EBSAs) Montreal, Quebec H2Y 1N9 Fax +1 514-288-6588 Canada [email protected] Special places in the world’s oceans The full report of this workshop is available at www.cbd.int/wsp-ebsa-report For further information on the CBD’s work on ecologically or biologically significant marine areas Western (EBSAs), please see www.cbd.int/ebsa south Pacific Areas described as meeting the EBSA criteria at the CBD Western South Pacific Regional Workshop in Nadi, Fiji, 22 to 25 November 2011 EBSA WSP Cover-F3.indd 1 2014-09-16 2:28 PM Ecologically or Published by the Secretariat of the Convention on Biological Diversity. Biologically Significant ISBN: 92-9225-558-4 Copyright © 2014, Secretariat of the Convention on Biological Diversity. Marine Areas (EBSAs) The designations employed and the presentation of material in this publication do not imply the expression of any opinion whatsoever on the part of the Secretariat of the Convention on Biological Diversity concerning the legal status of any country, territory, city or area or of its authorities, or concerning the delimitation of Special places in the world’s oceans its frontiers or boundaries. The views reported in this publication do not necessarily represent those of the Secretariat of the Areas described as meeting the EBSA criteria at the Convention on Biological Diversity. CBD Western South Pacific Regional Workshop in Nadi, This publication may be reproduced for educational or non-profit purposes without special permission from the copyright holders, provided acknowledgement of the source is made. -

The Emergence of a Regional Ocean Regime in the South Pacific*
The Emergence of a Regional Ocean Regime in the South Pacific* Biliana Cicin-Sain** Robert W. Knecht*** INTRODUCTION The introduction of 200-mile resource zones into a large area of for- merly open ocean can have a dramatic impact on the character of the area. This is especially true for ocean areas that contain numerous island groupings such as those existing in the South Pacific. Virtually over- night, isolated tiny island nations acquire the legal right to resources within and underlying vast areas of the surrounding ocean. In the pro- cess, widely separated island nations become members of a neighborhood consisting of the now adjoining 200-mile zones. Paralleling the actions of other coastal nations, the establishment of 200-mile zones in the South Pacific in the last decade by twenty-two self- governing South Pacific island nations and island territories' created a Copyright © 1989 by ECOLOGY LAW QUARTERLY * The authors gratefully acknowledge the financial support of the University of California Pacific Rim Program and the Institute for Global Conflict and Cooperation in the conduct of this study. The authors also appreciate the insights provided by their discussions with the individuals listed in the Appendix, as well as the research assistance of William R. Nester. The preparation of this Article profited immensely from a period of uninterrupted study at the Environment and Policy Institute of the East-West Center during Summer 1988, and the authors thank Dr. Norton Ginsburg, Director of the Institute, for making it possible. The authors would also like to thank the many individuals who provided useful comments on the Article, particularly Gracie Fong (Harvard University), Judith Swan (Forum Fisheries Agency), Iosefati Reti (South Pacific Commission), Jon Van Dyke (University of Hawaii), Joe Morgan (East-West Center), Robert Blumberg (U.S. -

Transnational Organized Crime in the Pacific
Transnational Organized Crime in the Pacific: A Threat Assessment September 2016 Copyright © 2016, United Nations Office on Drugs and Crime (UNODC). This publication may be reproduced in whole or in part and in any form for educational or non-profit purposes without special permission from the copyright holder, provided acknowledgement of the source is made. UNODC would appreciate receiving a copy of any publication that uses this publication as a source. Acknowledgements This study was conducted by the UNODC Regional Office for Southeast Asia and the Pacific (ROSEAP) at the Division for Operations (DO), with research support of the UNODC Studies and Threat Analysis Section (STAS), Division for Policy Analysis and Public Affairs (DPA). UNODC thanks the Pacific Islands Forum Secretariat (PIFS) for the support provided throughout the development of the report. The preparation of the report was financially supported by the Government of Australia and the Government of New Zealand. The preparation of this report would not have been possible without data and information reported by governments, the PIFS and other regional organizations to UNODC. UNODC is particularly thankful to government and law enforcement officials consulted during the development of the report. UNODC Team Jeremy Douglas (Regional Representative), Inshik Sim (Information Analyst), Brendan Quinn (Consultant), Brian Lee (Regional Programme Adviser), Tun Nay Soe (Regional Coordinator, Global SMART Programme), Giovanni Broussard (Regional Coordinator, Global Programme for Combating Wildlife and Forest Crime), Benjamin Smith (Regional Coordinator, Human Trafficking/Smuggling of Migrants) and Akara Umapornsakula (Graphic Designer). The study benefited from the valuable input of many UNODC staff members at headquarters who reviewed various sections of this report. -

Will Oil Refineries Make California the Gas Station of the Pacific Rim?
New Climate Threat: Will Oil Refineries make California the Gas Station of the Pacific Rim? Preventing climate disaster requires a global switch from oil before the year 2050.1 On the U.S. West Coast, where Los Angeles, the Bay Area, and Puget Sound host the 1st, 2nd, and 3rd largest oil refining centers in Western North America,2 we are using less oil.3 So we should be leaders in this transition. But instead of switching to sustainable alternatives, as we use less oil, West Coast refiners are boosting production to sell other nations oil-derived fuels. West Coast demand for finished petroleum products West Coast refined products supply exceeds (orange in the charts) peaked during the ten year West Coast demand, 2007–2018.3 period ending in 2010—“TY2010” for short—then fell by ≈ 440 million barrels from TY2010 to TY2018.3 At the same time, West Coast production of finished petroleum products (black in the charts) increased by ≈ 350 million barrels from TY2007 to TY2018.3 Production exceeded demand here by TY2012, and this production excess grew to ≈ 470 million barrels by TY2018 as refiners made more fuel for export.3 Foreign exports of finished refined products from the West Coast (brown) grew by ≈ 390 million barrels, an increase of ≈ 49 %, from TY2007 to TY2018.3 West Coast refinery production increased to Engine fuel exports are driving this excess refinery increase refined fuels exports, 2007–2018.3 production. Increased gasoline, distillate/diesel and jet fuel exports account for the vast majority (93 %) of the total increase from 2007 to 2018 in finished petroleum products exports from the West Coast.3 Petroleum coke exports remained the largest share of these exports by volume and also increased from 2007–2018,3 but pet coke is a byproduct of refining low-quality crude that is exported in part because of air quality controls on this dirty-burning fuel. -

Labour Mobility in Pacific Island Countries
LABOUR MOBILITY IN PACIFIC ISLAND COUNTRIES ILO Office for Pacific Island Countries November 2019 LABOUR MOBILITY IN PACIFIC ISLAND COUNTRIES ILO Office for Pacific Island Countries November 2019 opyright nternaonal abour rganiaon First published ublicaons of the nternaonal abour ce enjoy copyright under rotocol of the Uniersal opyrightonenon Neertheless, short ecerpts from them may be reproduced without authoriaon, oncondion that the source is indicated For rights of reproducon or translaon, applicaon should bemade to ublicaons (ights and icensing), nternaonal abour ce, H enea ,Switerland, or by email rightsiloorg The nternaonal abour ce welcomes such applicaonsibraries, instuons and other users registered with a reproducon rights organiaon may mae copies in accordance with the licences issued to them for this purpose Visit wwwifrroorg to nd the reproducon rights organiaon in your country abour mobility in acic sland countries (print) (web pdf) ataloguing in ublicaon ata The designaons employed in publicaons, which are in conformity with United Naons pracce, and the presentaon of material therein do not imply the epression of any opinion whatsoeer on the part of the nternaonal abour ce concerning the legal status of any country, area or territory or of its authories, or concerning the delimitaon of its froners The responsibility for opinions epressed in signed arcles, studies and other contribuons rests solely with their authors, and publicaon does not constute an endorsement by the nternaonal abour ce of the opinions epressed -
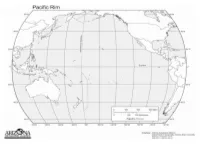
Mapping Ring of Fire Sudent Handout
Mapping the Ring of Fire (part 1) Using a yellow pencil on a map of the world Outline and Label the following in green: make a prediction and shade the areas o United States of America where you think the most earthquakes o Japan occur. Use the information in the data table on the Using an orange pencil on a map of the next page to mark the location of each world make a prediction and shade the earthquake on the world map that follows the areas where you think the most volcanoes data table. occur. Use a blue colored pencil to draw a circle Label each of the following in brown: at each earthquake location. o North America continent o South America continent Use a purple colored pencil to mark the o Australia continent locations of the volcanoes on the map with o Asia continent a triangle. o Pacific Ocean o Sea of Japan o Mt Rainier o Mt Fuji Volcanoes Earthquakes Longitude Latitude Longitude Latitude Longitude Latitude Longitude Latitude 120° W 40° N 125° E 23° N 150° W 60° N 37° E 3° S 110° E 5° S 30° E 35° N 70° W 35° S 145° E 40° N 77° W 4° S 140° E 35° N 120° W 45° N 120° E 10° S 88° E 23° N 12° E 46° N 61° W 15° N 14° E 41° N 121° E 14° S 75° E 28° N 105° W 20° N 105° E 5° S 34° E 7° N 150° W 61° N 75° W 0° 35° E 15° N 74° W 44° N 68° W 47° S 122° W 40° N 70° W 30° S 70° W 30° S 175° E 41° S 30° E 40° N 175° E 39° S 10° E 45° N 121° E 17° N 60° E 30° N 123° E 38° N 85° W 13° N 160° E 55° N Mapping the Ring of Fire (part 2) After you have sketched your inferred View a map of seismic data from the Pacific boundaries compare your map to a map of the Northwest.