Hypertransport™ Technology in 2009 and Beyond
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Exploring Weak Scalability for FEM Calculations on a GPU-Enhanced Cluster
Exploring weak scalability for FEM calculations on a GPU-enhanced cluster Dominik G¨oddeke a,∗,1, Robert Strzodka b,2, Jamaludin Mohd-Yusof c, Patrick McCormick c,3, Sven H.M. Buijssen a, Matthias Grajewski a and Stefan Turek a aInstitute of Applied Mathematics, University of Dortmund bStanford University, Max Planck Center cComputer, Computational and Statistical Sciences Division, Los Alamos National Laboratory Abstract The first part of this paper surveys co-processor approaches for commodity based clusters in general, not only with respect to raw performance, but also in view of their system integration and power consumption. We then extend previous work on a small GPU cluster by exploring the heterogeneous hardware approach for a large-scale system with up to 160 nodes. Starting with a conventional commodity based cluster we leverage the high bandwidth of graphics processing units (GPUs) to increase the overall system bandwidth that is the decisive performance factor in this scenario. Thus, even the addition of low-end, out of date GPUs leads to improvements in both performance- and power-related metrics. Key words: graphics processors, heterogeneous computing, parallel multigrid solvers, commodity based clusters, Finite Elements PACS: 02.70.-c (Computational Techniques (Mathematics)), 02.70.Dc (Finite Element Analysis), 07.05.Bx (Computer Hardware and Languages), 89.20.Ff (Computer Science and Technology) ∗ Corresponding author. Address: Vogelpothsweg 87, 44227 Dortmund, Germany. Email: [email protected], phone: (+49) 231 755-7218, fax: -5933 1 Supported by the German Science Foundation (DFG), project TU102/22-1 2 Supported by a Max Planck Center for Visual Computing and Communication fellowship 3 Partially supported by the U.S. -

Conga-TR4 User's Guide
COM Express™ conga-TR4 COM Express Type 6 Basic module based on 4th Generation AMD Embedded V- and R-Series SoC User’s Guide Revision 1.10 Copyright © 2018 congatec GmbH TR44m110 1/66 Revision History Revision Date (yyyy.mm.dd) Author Changes 0.1 2018.01.15 BEU • Preliminary release 1.0 2018.10.15 BEU • Updated “Electrostatic Sensitive Device” information on page 3 • Corrected single/dual channel MT/s rates for two variants in table 2 • Updated section 2.2 “Supported Operating Systems” • Added values for four variants in section 2.5 "Power Consumption" • Added values in section 2.6 "Supply Voltage Battery Power" • Updated images in section 4 "Cooling Solutions" • Added note about requiring a re-driver on carrier for USB 3.1 Gen 2 in section 5.1.2 "USB" and 7.4 "USB Host Controller" • Added Intel® Ethernet Controller i211 as assembly option in table 4 "Feature Summary" and section 5.1.4 "Ethernet" • Corrected section 7.4 "USB Host Controller" • Added section 9 "System Resources" 1.1 2019.03.19 BEU • Corrected image in section 2.4 "Supply Voltage Standard Power" • Updated section 10.4 "Supported Flash Devices" 1.2 2019.04.02 BEU • Corrected supported memory in table 2, 3, and added information about supported memory in table 4 • Added information about the new industrial variant in table 3 and 7 1.3 2019.07.30 BEU • Updated note in section 4 "Cooling Solutions" • Changed number of supported USB 3.1 Gen 2 interfaces to two throughout the document • Added note regarding USB 3.1 Gen 2 in section 7.4 "USB Host Controller" 1.4 2020.01.07 BEU -

Lewis University Dr. James Girard Summer Undergraduate Research Program 2021 Faculty Mentor - Project Application
Lewis University Dr. James Girard Summer Undergraduate Research Program 2021 Faculty Mentor - Project Application Exploring the Use of High-level Parallel Abstractions and Parallel Computing for Functional and Gate-Level Simulation Acceleration Dr. Lucien Ngalamou Department of Engineering, Computing and Mathematical Sciences Abstract System-on-Chip (SoC) complexity growth has multiplied non-stop, and time-to- market pressure has driven demand for innovation in simulation performance. Logic simulation is the primary method to verify the correctness of such systems. Logic simulation is used heavily to verify the functional correctness of a design for a broad range of abstraction levels. In mainstream industry verification methodologies, typical setups coordinate the validation e↵ort of a complex digital system by distributing logic simulation tasks among vast server farms for months at a time. Yet, the performance of logic simulation is not sufficient to satisfy the demand, leading to incomplete validation processes, escaped functional bugs, and continuous pressure on the EDA1 industry to develop faster simulation solutions. In this research, we will explore a solution that uses high-level parallel abstractions and parallel computing to boost the performance of logic simulation. 1Electronic Design Automation 1 1 Project Description 1.1 Introduction and Background SoC complexity is increasing rapidly, driven by demands in the mobile market, and in- creasingly by the fast-growth of assisted- and autonomous-driving applications. SoC teams utilize many verification technologies to address their complexity and time-to-market chal- lenges; however, logic simulation continues to be the foundation for all verification flows, and continues to account for more than 90% [10] of all verification workloads. -

Virtualization: Comparision of Windows and Linux
VIRTUALIZATION: COMPARISION OF WINDOWS AND LINUX Ms. Pooja Sharma Lecturer (I.T) PCE, Jaipur Email:[email protected] Charnaksh Jain IV yr (I.T) PCE, Jaipur [email protected] Abstract Full-Virtualization, Para-Virtualization, hyper- visior(Hyper-V), Guest Operating System, Host Virtualization as a concept is not new; computational Operating System. environment virtualization has been around since the first mainframe systems. But recently, the term 1. Introduction "virtualization" has become ubiquitous, representing any type of process obfuscation where a process is Virtualization provides a set of tools for increasing somehow removed from its physical operating flexibility and lowering costs, things that are environment. Because of this ambiguity, important in every enterprise and Information virtualization can almost be applied to any and all Technology organization. Virtualization solutions are parts of an IT infrastructure. For example, mobile becoming increasingly available and rich in features. device emulators are a form of virtualization because the hardware platform normally required to run the Since virtualization can provide significant benefits mobile operating system has been emulated, to your organization in multiple areas, you should be removing the OS binding from the hardware it was establishing pilots, developing expertise and putting written for. But this is just one example of one type virtualization technology to work now. of virtualization; there are many definitions of the In essence, virtualization increases flexibility by term "virtualization" floating around in the current decoupling an operating system and the services and lexicon, and all (or at least most) of them are correct, applications supported by that system from a specific which can be quite confusing. -

A Survey of Reconfigurable Processors
Hindawi Publishing Corporation VLSI Design Volume 2013, Article ID 683615, 18 pages http://dx.doi.org/10.1155/2013/683615 Review Article Ingredients of Adaptability: A Survey of Reconfigurable Processors Anupam Chattopadhyay MPSoC Architectures, UMIC Research Centre, RWTH Aachen University, Mies-van-der-Rohe Strasse 15, 52074 Aachen, Germany Correspondence should be addressed to Anupam Chattopadhyay; [email protected] Received 18 December 2012; Revised 14 May 2013; Accepted 1 June 2013 Academic Editor: Yann Thoma Copyright © 2013 Anupam Chattopadhyay. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited. For a design to survive unforeseen physical effects like aging, temperature variation, and/or emergence of new application standards, adaptability needs to be supported. Adaptability, in its complete strength, is present in reconfigurable processors, which makes it an important IP in modern System-on-Chips (SoCs). Reconfigurable processors have risen to prominence as a dominant computing platform across embedded, general-purpose, and high-performance application domains during the last decade. Significant advances have been made in many areas such as, identifying the advantages of reconfigurable platforms, their modeling, implementation flow and finally towards early commercial acceptance. This paper reviews these progresses from various perspectives with particular emphasis on fundamental challenges and their solutions. Empowered with the analysis of past, the future research roadmap is proposed. 1. Introduction Circuits (ASICs) in terms of flexibility and performance. Since this work, notable research has been done in accel- The changing technology landscape and fast evolution of erator design (application-specific processors), multicore application standards make it imperative for a design to homogeneous and heterogeneous System-on-Chip (SoC) be adaptable. -

Warehouse-Scale Video Acceleration: Co-Design and Deployment in the Wild
Warehouse-Scale Video Acceleration: Co-design and Deployment in the Wild Parthasarathy Ranganathan Sarah J. Gwin Narayana Penukonda Daniel Stodolsky Yoshiaki Hase Eric Perkins-Argueta Jeff Calow Da-ke He Devin Persaud Jeremy Dorfman C. Richard Ho Alex Ramirez Marisabel Guevara Roy W. Huffman Jr. Ville-Mikko Rautio Clinton Wills Smullen IV Elisha Indupalli Yolanda Ripley Aki Kuusela Indira Jayaram Amir Salek Raghu Balasubramanian Poonacha Kongetira Sathish Sekar Sandeep Bhatia Cho Mon Kyaw Sergey N. Sokolov Prakash Chauhan Aaron Laursen Rob Springer Anna Cheung Yuan Li Don Stark In Suk Chong Fong Lou Mercedes Tan Niranjani Dasharathi Kyle A. Lucke Mark S. Wachsler Jia Feng JP Maaninen Andrew C. Walton Brian Fosco Ramon Macias David A. Wickeraad Samuel Foss Maire Mahony Alvin Wijaya Ben Gelb David Alexander Munday Hon Kwan Wu Google Inc. Srikanth Muroor Google Inc. USA [email protected] USA Google Inc. USA ABSTRACT management, and new workload capabilities not otherwise possible Video sharing (e.g., YouTube, Vimeo, Facebook, TikTok) accounts with prior systems. To the best of our knowledge, this is the first for the majority of internet traffic, and video processing is also foun- work to discuss video acceleration at scale in large warehouse-scale dational to several other key workloads (video conferencing, vir- environments. tual/augmented reality, cloud gaming, video in Internet-of-Things devices, etc.). The importance of these workloads motivates larger CCS CONCEPTS video processing infrastructures and ś with the slowing of Moore’s · Hardware → Hardware-software codesign; · Computer sys- law ś specialized hardware accelerators to deliver more computing tems organization → Special purpose systems. -

Introduction Hardware Acceleration Philosophy Popular Accelerators In
Special Purpose Accelerators Special Purpose Accelerators Introduction Recap: General purpose processors excel at various jobs, but are no Theme: Towards Reconfigurable High-Performance Computing mathftch for acce lera tors w hen dea ling w ith spec ilidtialized tas ks Lecture 4 Objectives: Platforms II: Special Purpose Accelerators Define the role and purpose of modern accelerators Provide information about General Purpose GPU computing Andrzej Nowak Contents: CERN openlab (Geneva, Switzerland) Hardware accelerators GPUs and general purpose computing on GPUs Related hardware and software technologies Inverted CERN School of Computing, 3-5 March 2008 1 iCSC2008, Andrzej Nowak, CERN openlab 2 iCSC2008, Andrzej Nowak, CERN openlab Special Purpose Accelerators Special Purpose Accelerators Hardware acceleration philosophy Popular accelerators in general Floating point units Old CPUs were really slow Embedded CPUs often don’t have a hardware FPU 1980’s PCs – the FPU was an optional add on, separate sockets for the 8087 coprocessor Video and image processing MPEG decoders DV decoders HD decoders Digital signal processing (including audio) Sound Blaster Live and friends 3 iCSC2008, Andrzej Nowak, CERN openlab 4 iCSC2008, Andrzej Nowak, CERN openlab Towards Reconfigurable High-Performance Computing Lecture 4 iCSC 2008 3-5 March 2008, CERN Special Purpose Accelerators 1 Special Purpose Accelerators Special Purpose Accelerators Mainstream accelerators today Integrated FPUs Realtime graphics GiGaming car ds Gaming physics -

AMD Firepro S9150
The Rise of Open Programming Frameworks JC BARATAULT IWOCL May 2015 1,000+ OpenCL projects SourceForge GitHub Google Code BitBucket AMD | IWOCL 2015 2 1 million fluid cells in a 256x64x64 grid TUM.3D Virtual Wind Tunnel 10K C++ lines of code, 30 GPU kernels CUDA 5.0 to OpenCL 1.2 port in less than a day 30 fps with one FirePro S9150 Multi-GPU & Linux version in June AMD | IWOCL 2015 3 US Army Research Lab Explore programming methodologies for the next generation hardware to achieve performance portability in current, emerging, and tomorrow’s computational resources AMD | IWOCL 2015 4 Dr. Ren WU, BAIDU – “DEEP LEARNING MEETS HETEROGENEOUS COMPUTING” AMD | IWOCL 2015 5 Dr. Ren WU, BAIDU – “DEEP LEARNING MEETS HETEROGENEOUS COMPUTING” AMD | IWOCL 2015 6 Dr. Ren WU, BAIDU – “DEEP LEARNING MEETS HETEROGENEOUS COMPUTING” AMD | IWOCL 2015 7 Open source clBLAS github.com/clMathLibraries/clBLAS AMD FirePro S9150 • 16GB GDDR5 • 320 GB/s memory bandwidth • Full OpenCL + OpenGL • 4 TFlops SGEMM • 2 Tflops DGEMM >80% efficiency AMD | IWOCL 2015 8 #1 GSI L-CSC cluster 600 FirePro S9150 5.27 GFlops/W AMD | IWOCL 2015 9 FirePro W9100 for workstation AMD | IWOCL 2015 10 FirePro S9150 for server AMD | IWOCL 2015 11 REQUIREMENT: Memory and performance dGPU CPU 3D RTM TF Double dGPU AMBER14 NAMD Raw performance Raw performance 3TF FastROC FirePro S9150 RTM ? 2TF XFdtd Intel Haswell 1TF *est 1TF CPU Hadoop 0 64MB 12 GB 16 GB 512GB 1TB 8TB NVIDIA max Memory Availability AMD | IWOCL 2015 per ASIC - Tesla 12 AMD HPC Roadmap Trends S9150 2TF DGEMM Next Gen -

Torrenza and the Pareto Distribution
CoEHT Symposium February 16, 2007 Douglas O’Flaherty The Heterogeneous Processing Imperative ≤ 1981 Single16-bit 486 Core x8 By the end of Spreadsheets,the decade,6 word-processing homogenous PERF. So 2 multi-core1990s becomes increasingly inadequate f tw 32-bit a Single r e AMD64 Core E-mail, GUI, PowerPoint,C web browsers om p l Dual- ex i Opteron ty Java, XML, web a services CoE HT Symposia n C d PERF. D ore 2000s i ve 64-bit rsi 3D, digital mediat Single Core y ER/PERF. POW 64-bit ogeneous HD, DRM HomMulti-CPU essing DIVERSITY 2010s The End of “One Size Fits All” Computing Platform Co-Proc HeterogeneousCPU+xPU Industry Landscape: The Insight Gap Accelerators Devices optimized to enhance the performance on a particular function “The Insight Gap” Data Driven X86 PerformanceComputing Time 3 CoE HT Symposia Torrenza and the Pareto Distribution • New features are introduced in niche markets y Some features will never reach broad market appeal, but will have stable niche markets over time y The sum of those niche market opportunities is itself a considerable market opportunity • Features with broad market appeal are quickly moved up the value chain y FPGA to custom logic on add-in board y Custom logic integrated into chipset y For very high value features, chipset logic moves into processor • Our goals for Torrenza y Enable new markets by changing system economics with a standard platform y Evaluate new features for their potential in the mass market % of Target Market Value Migration Mass New Features Enter Market in Niches Market Niche Markets ◄ General Features Specialized Features ► 4 CoE HT Symposia Early vs. -

Hardware-Accelerated Multi-Tile Streaming for Realtime Remote Visualization
Eurographics Symposium on Parallel Graphics and Visualization (2018) H. Childs, F. Cucchietti (Editors) Hardware-Accelerated Multi-Tile Streaming for Realtime Remote Visualization T. Biedert1, P. Messmer2, T. Fogal2 and C. Garth1 1Technische Universität Kaiserslautern, Germany 2NVIDIA Corporation Abstract The physical separation of compute resource and end user is one of the core challenges in HPC visualization. While GPUs are routinely used in remote rendering, a heretofore unexplored aspect is these GPUs’ special purpose video en-/decoding hardware that can be used to solve the large-scale remoting challenge. The high performance and substantial bandwidth savings offered by such hardware enable a novel approach to the problems inherent in remote rendering, with impact on the workflows and visualization scenarios available. Using more tiles than previously thought reasonable, we demonstrate a distributed, low- latency multi-tile streaming system that can sustain stable 80 Hz when streaming up to 256 synchronized 3840x2160 tiles and can achieve 365 Hz at 3840x2160 for sort-first compositing over the internet. Categories and Subject Descriptors (according to ACM CCS): I.3.2 [Computer Graphics]: Graphics Systems— Distributed/network graphics 1. Introduction displays is nothing new. However, contemporary resolutions of at The growing use of distributed computing in computational sci- least 4K or more per display at interactive frame rates far exceed ences has put increased pressure on visualization and analysis tech- the capabilities of previous approaches. niques. A core challenge of HPC visualization is the physical sep- Strong scaling the rendering and delivery task enables novel in- aration of visualization resources and end-users. Furthermore, with teractive uses of HPC systems. -

What Every Programmer Should Know About Memory
What Every Programmer Should Know About Memory Ulrich Drepper Red Hat, Inc. [email protected] November 21, 2007 Abstract As CPU cores become both faster and more numerous, the limiting factor for most programs is now, and will be for some time, memory access. Hardware designers have come up with ever more sophisticated memory handling and acceleration techniques–such as CPU caches–but these cannot work optimally without some help from the programmer. Unfortunately, neither the structure nor the cost of using the memory subsystem of a computer or the caches on CPUs is well understood by most programmers. This paper explains the structure of memory subsys- tems in use on modern commodity hardware, illustrating why CPU caches were developed, how they work, and what programs should do to achieve optimal performance by utilizing them. 1 Introduction day these changes mainly come in the following forms: In the early days computers were much simpler. The var- • RAM hardware design (speed and parallelism). ious components of a system, such as the CPU, memory, mass storage, and network interfaces, were developed to- • Memory controller designs. gether and, as a result, were quite balanced in their per- • CPU caches. formance. For example, the memory and network inter- faces were not (much) faster than the CPU at providing • Direct memory access (DMA) for devices. data. This situation changed once the basic structure of com- For the most part, this document will deal with CPU puters stabilized and hardware developers concentrated caches and some effects of memory controller design. on optimizing individual subsystems. Suddenly the per- In the process of exploring these topics, we will explore formance of some components of the computer fell sig- DMA and bring it into the larger picture. -
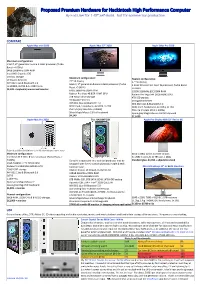
Proposed Premium Hardware for Hackintosh High Performance Computer by End User for 1-Off Self-Build
Proposed Premium Hardware for Hackintosh High Performance Computer By End User for 1-Off Self-Build. Not for commercial production. COMPARE Apple Mac mini 2020 Apple iMac 27" 2020 Apple iMac Pro 2020 Maximum configuration: Intel i7, 8th generation 6‑core 3.2GHz processor (Turbo Boost >4.6GHz) 64GB 2666MHz DDR4 RAM Intel UHD Graphics 630 2TB SSD storage Maximum configuration: 10 Gigabit Ethernet Nearest configuration: 27” 5K display 27” 5K display Wifi 802.11ac & Bluetooth 5.0 Intel i9, 9th generation 8‑core 3.2GHz processor (Turbo 1x HDMI2, 4x TB3 & 2x USB3 ports 2.3GHz 18-core Intel Xeon W processor, Turbo Boost Boost >5.0GHz) >4.3GHz $3,199 + keyboard, mouse and monitor 64GB 2666MHz DDR4 RAM 128GB 2666MHz EEC DDR4 RAM Radeon Pro Vega 48 8GB HBM2 GPU Radeon Pro Vega 64X 16GB HBM2 GPU 3TB Fusion drive storage 4TB SSD storage 10 Gigabit Ethernet 10 Gigabit Ethernet Wifi 802.11ac & Bluetooth 4.2 Wifi 802.11ac & Bluetooth 5.0 SDXC Card, headphone, 4x USB3, 2x TB3 SDXC Card, headphone, 4x USB3, 4x TB3 PSU n/a (my late 2015 is 300W) PSU n/a (my late 2015 is 300W) Silver Magic Mouse 2 & full keyboard Space grey Magic Mouse 2 & full keyboard $4,249 $11,099 Apple Mac Pro 2020 This HACKINTOSH Apple Pro Display XDR 32" Retina 6K Superb polished stainless steel & aluminium tower case Minimum configuration: 6016 x 3384, 10-bit 1.073Bn colours Intel Xeon W 3.5GHz 8‑core processor (Turbo Boost > 3x USB2-C ports & 1x TB3 port | 280g 4.0GHz) Corsair’s elegant and very well designed case may be Standard glass $4,999 + adjustable stand 32GB 2600MHz EEC DDR4 RAM swapped later for my custom plywood, maple & teak Radeon Pro 580X 8GB GDDR5 GPU furniture case.