Cope- BT-2008-Phd-Thesis.Pdf
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Exploring Weak Scalability for FEM Calculations on a GPU-Enhanced Cluster
Exploring weak scalability for FEM calculations on a GPU-enhanced cluster Dominik G¨oddeke a,∗,1, Robert Strzodka b,2, Jamaludin Mohd-Yusof c, Patrick McCormick c,3, Sven H.M. Buijssen a, Matthias Grajewski a and Stefan Turek a aInstitute of Applied Mathematics, University of Dortmund bStanford University, Max Planck Center cComputer, Computational and Statistical Sciences Division, Los Alamos National Laboratory Abstract The first part of this paper surveys co-processor approaches for commodity based clusters in general, not only with respect to raw performance, but also in view of their system integration and power consumption. We then extend previous work on a small GPU cluster by exploring the heterogeneous hardware approach for a large-scale system with up to 160 nodes. Starting with a conventional commodity based cluster we leverage the high bandwidth of graphics processing units (GPUs) to increase the overall system bandwidth that is the decisive performance factor in this scenario. Thus, even the addition of low-end, out of date GPUs leads to improvements in both performance- and power-related metrics. Key words: graphics processors, heterogeneous computing, parallel multigrid solvers, commodity based clusters, Finite Elements PACS: 02.70.-c (Computational Techniques (Mathematics)), 02.70.Dc (Finite Element Analysis), 07.05.Bx (Computer Hardware and Languages), 89.20.Ff (Computer Science and Technology) ∗ Corresponding author. Address: Vogelpothsweg 87, 44227 Dortmund, Germany. Email: [email protected], phone: (+49) 231 755-7218, fax: -5933 1 Supported by the German Science Foundation (DFG), project TU102/22-1 2 Supported by a Max Planck Center for Visual Computing and Communication fellowship 3 Partially supported by the U.S. -

Conga-TR4 User's Guide
COM Express™ conga-TR4 COM Express Type 6 Basic module based on 4th Generation AMD Embedded V- and R-Series SoC User’s Guide Revision 1.10 Copyright © 2018 congatec GmbH TR44m110 1/66 Revision History Revision Date (yyyy.mm.dd) Author Changes 0.1 2018.01.15 BEU • Preliminary release 1.0 2018.10.15 BEU • Updated “Electrostatic Sensitive Device” information on page 3 • Corrected single/dual channel MT/s rates for two variants in table 2 • Updated section 2.2 “Supported Operating Systems” • Added values for four variants in section 2.5 "Power Consumption" • Added values in section 2.6 "Supply Voltage Battery Power" • Updated images in section 4 "Cooling Solutions" • Added note about requiring a re-driver on carrier for USB 3.1 Gen 2 in section 5.1.2 "USB" and 7.4 "USB Host Controller" • Added Intel® Ethernet Controller i211 as assembly option in table 4 "Feature Summary" and section 5.1.4 "Ethernet" • Corrected section 7.4 "USB Host Controller" • Added section 9 "System Resources" 1.1 2019.03.19 BEU • Corrected image in section 2.4 "Supply Voltage Standard Power" • Updated section 10.4 "Supported Flash Devices" 1.2 2019.04.02 BEU • Corrected supported memory in table 2, 3, and added information about supported memory in table 4 • Added information about the new industrial variant in table 3 and 7 1.3 2019.07.30 BEU • Updated note in section 4 "Cooling Solutions" • Changed number of supported USB 3.1 Gen 2 interfaces to two throughout the document • Added note regarding USB 3.1 Gen 2 in section 7.4 "USB Host Controller" 1.4 2020.01.07 BEU -

Warehouse-Scale Video Acceleration: Co-Design and Deployment in the Wild
Warehouse-Scale Video Acceleration: Co-design and Deployment in the Wild Parthasarathy Ranganathan Sarah J. Gwin Narayana Penukonda Daniel Stodolsky Yoshiaki Hase Eric Perkins-Argueta Jeff Calow Da-ke He Devin Persaud Jeremy Dorfman C. Richard Ho Alex Ramirez Marisabel Guevara Roy W. Huffman Jr. Ville-Mikko Rautio Clinton Wills Smullen IV Elisha Indupalli Yolanda Ripley Aki Kuusela Indira Jayaram Amir Salek Raghu Balasubramanian Poonacha Kongetira Sathish Sekar Sandeep Bhatia Cho Mon Kyaw Sergey N. Sokolov Prakash Chauhan Aaron Laursen Rob Springer Anna Cheung Yuan Li Don Stark In Suk Chong Fong Lou Mercedes Tan Niranjani Dasharathi Kyle A. Lucke Mark S. Wachsler Jia Feng JP Maaninen Andrew C. Walton Brian Fosco Ramon Macias David A. Wickeraad Samuel Foss Maire Mahony Alvin Wijaya Ben Gelb David Alexander Munday Hon Kwan Wu Google Inc. Srikanth Muroor Google Inc. USA [email protected] USA Google Inc. USA ABSTRACT management, and new workload capabilities not otherwise possible Video sharing (e.g., YouTube, Vimeo, Facebook, TikTok) accounts with prior systems. To the best of our knowledge, this is the first for the majority of internet traffic, and video processing is also foun- work to discuss video acceleration at scale in large warehouse-scale dational to several other key workloads (video conferencing, vir- environments. tual/augmented reality, cloud gaming, video in Internet-of-Things devices, etc.). The importance of these workloads motivates larger CCS CONCEPTS video processing infrastructures and ś with the slowing of Moore’s · Hardware → Hardware-software codesign; · Computer sys- law ś specialized hardware accelerators to deliver more computing tems organization → Special purpose systems. -

AMD Firepro S9150
The Rise of Open Programming Frameworks JC BARATAULT IWOCL May 2015 1,000+ OpenCL projects SourceForge GitHub Google Code BitBucket AMD | IWOCL 2015 2 1 million fluid cells in a 256x64x64 grid TUM.3D Virtual Wind Tunnel 10K C++ lines of code, 30 GPU kernels CUDA 5.0 to OpenCL 1.2 port in less than a day 30 fps with one FirePro S9150 Multi-GPU & Linux version in June AMD | IWOCL 2015 3 US Army Research Lab Explore programming methodologies for the next generation hardware to achieve performance portability in current, emerging, and tomorrow’s computational resources AMD | IWOCL 2015 4 Dr. Ren WU, BAIDU – “DEEP LEARNING MEETS HETEROGENEOUS COMPUTING” AMD | IWOCL 2015 5 Dr. Ren WU, BAIDU – “DEEP LEARNING MEETS HETEROGENEOUS COMPUTING” AMD | IWOCL 2015 6 Dr. Ren WU, BAIDU – “DEEP LEARNING MEETS HETEROGENEOUS COMPUTING” AMD | IWOCL 2015 7 Open source clBLAS github.com/clMathLibraries/clBLAS AMD FirePro S9150 • 16GB GDDR5 • 320 GB/s memory bandwidth • Full OpenCL + OpenGL • 4 TFlops SGEMM • 2 Tflops DGEMM >80% efficiency AMD | IWOCL 2015 8 #1 GSI L-CSC cluster 600 FirePro S9150 5.27 GFlops/W AMD | IWOCL 2015 9 FirePro W9100 for workstation AMD | IWOCL 2015 10 FirePro S9150 for server AMD | IWOCL 2015 11 REQUIREMENT: Memory and performance dGPU CPU 3D RTM TF Double dGPU AMBER14 NAMD Raw performance Raw performance 3TF FastROC FirePro S9150 RTM ? 2TF XFdtd Intel Haswell 1TF *est 1TF CPU Hadoop 0 64MB 12 GB 16 GB 512GB 1TB 8TB NVIDIA max Memory Availability AMD | IWOCL 2015 per ASIC - Tesla 12 AMD HPC Roadmap Trends S9150 2TF DGEMM Next Gen -

Hardware-Accelerated Multi-Tile Streaming for Realtime Remote Visualization
Eurographics Symposium on Parallel Graphics and Visualization (2018) H. Childs, F. Cucchietti (Editors) Hardware-Accelerated Multi-Tile Streaming for Realtime Remote Visualization T. Biedert1, P. Messmer2, T. Fogal2 and C. Garth1 1Technische Universität Kaiserslautern, Germany 2NVIDIA Corporation Abstract The physical separation of compute resource and end user is one of the core challenges in HPC visualization. While GPUs are routinely used in remote rendering, a heretofore unexplored aspect is these GPUs’ special purpose video en-/decoding hardware that can be used to solve the large-scale remoting challenge. The high performance and substantial bandwidth savings offered by such hardware enable a novel approach to the problems inherent in remote rendering, with impact on the workflows and visualization scenarios available. Using more tiles than previously thought reasonable, we demonstrate a distributed, low- latency multi-tile streaming system that can sustain stable 80 Hz when streaming up to 256 synchronized 3840x2160 tiles and can achieve 365 Hz at 3840x2160 for sort-first compositing over the internet. Categories and Subject Descriptors (according to ACM CCS): I.3.2 [Computer Graphics]: Graphics Systems— Distributed/network graphics 1. Introduction displays is nothing new. However, contemporary resolutions of at The growing use of distributed computing in computational sci- least 4K or more per display at interactive frame rates far exceed ences has put increased pressure on visualization and analysis tech- the capabilities of previous approaches. niques. A core challenge of HPC visualization is the physical sep- Strong scaling the rendering and delivery task enables novel in- aration of visualization resources and end-users. Furthermore, with teractive uses of HPC systems. -
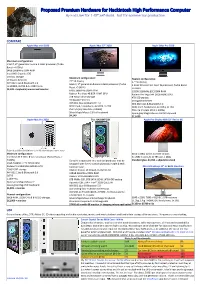
Proposed Premium Hardware for Hackintosh High Performance Computer by End User for 1-Off Self-Build
Proposed Premium Hardware for Hackintosh High Performance Computer By End User for 1-Off Self-Build. Not for commercial production. COMPARE Apple Mac mini 2020 Apple iMac 27" 2020 Apple iMac Pro 2020 Maximum configuration: Intel i7, 8th generation 6‑core 3.2GHz processor (Turbo Boost >4.6GHz) 64GB 2666MHz DDR4 RAM Intel UHD Graphics 630 2TB SSD storage Maximum configuration: 10 Gigabit Ethernet Nearest configuration: 27” 5K display 27” 5K display Wifi 802.11ac & Bluetooth 5.0 Intel i9, 9th generation 8‑core 3.2GHz processor (Turbo 1x HDMI2, 4x TB3 & 2x USB3 ports 2.3GHz 18-core Intel Xeon W processor, Turbo Boost Boost >5.0GHz) >4.3GHz $3,199 + keyboard, mouse and monitor 64GB 2666MHz DDR4 RAM 128GB 2666MHz EEC DDR4 RAM Radeon Pro Vega 48 8GB HBM2 GPU Radeon Pro Vega 64X 16GB HBM2 GPU 3TB Fusion drive storage 4TB SSD storage 10 Gigabit Ethernet 10 Gigabit Ethernet Wifi 802.11ac & Bluetooth 4.2 Wifi 802.11ac & Bluetooth 5.0 SDXC Card, headphone, 4x USB3, 2x TB3 SDXC Card, headphone, 4x USB3, 4x TB3 PSU n/a (my late 2015 is 300W) PSU n/a (my late 2015 is 300W) Silver Magic Mouse 2 & full keyboard Space grey Magic Mouse 2 & full keyboard $4,249 $11,099 Apple Mac Pro 2020 This HACKINTOSH Apple Pro Display XDR 32" Retina 6K Superb polished stainless steel & aluminium tower case Minimum configuration: 6016 x 3384, 10-bit 1.073Bn colours Intel Xeon W 3.5GHz 8‑core processor (Turbo Boost > 3x USB2-C ports & 1x TB3 port | 280g 4.0GHz) Corsair’s elegant and very well designed case may be Standard glass $4,999 + adjustable stand 32GB 2600MHz EEC DDR4 RAM swapped later for my custom plywood, maple & teak Radeon Pro 580X 8GB GDDR5 GPU furniture case. -

AMD Reports 2013 First Quarter Results
April 18, 2013 AMD Reports 2013 First Quarter Results SUNNYVALE, CA -- (Marketwired) -- 04/18/13 -- AMD (NYSE: AMD) Q1 2013 Results AMD revenue $1.09 billion, decreased 6 percent sequentially and 31 percent year- over-year Gross margin 41 percent Operating loss of $98 million, net loss of $146 million, loss per share of $0.19 Non-GAAP(1) operating loss of $46 million, net loss of $94 million, loss per share of $0.13 AMD (NYSE: AMD) today announced revenue for the first quarter of 2013 of $1.09 billion, an operating loss of $98 million and a net loss of $146 million, or $0.19 per share. The company reported a non-GAAP operating loss of $46 million and a non-GAAP net loss of $94 million, or $0.13 per share. "Our first quarter results reflect our disciplined operational execution in a difficult market environment," said Rory Read, AMD president and CEO. "We have largely completed our restructuring and are now focused on delivering a powerful set of new products that will accelerate our business in 2013. We will continue to diversify our portfolio and attack high- growth markets like dense server, ultra low-power client, embedded and semi-custom solutions to create the foundation for sustainable financial returns." GAAP Financial Results ---------------------------------------------------------------------------- Q1-13 Q4-12 Q1-12 ---------------------------------------------------------------------------- Revenue $1.09B $1.16B $1.59B ---------------------------------------------------------------------------- Operating loss $(98)M $(422)M -

Real-Time Hair Rendering
Real-Time Hair Rendering Master Thesis Computer Science and Media M.Sc. Stuttgart Media University Markus Rapp Matrikel-Nr.: 25823 Erstprüfer: Stefan Radicke Zweitprüfer: Simon Spielmann Stuttgart, 7. November 2014 Real-Time Hair Rendering Abstract A b s t r a c t An approach is represented to render hair in real-time by using a small number of guide strands to generate interpolated hairs on the graphics processing unit (GPU). Hair interpolation methods are based on a single guide strand or on multiple guide strands. Each hair strand is composed by segments, which can be further subdivided to render smooth hair curves. The appearance of the guide hairs as well as the size of the hair segments in screen space are used to calculate the amount of detail, which is needed to display smooth hair strands. The developed hair rendering system can handle guide strands with different segment counts. Included features are curly hair, thinning and random deviations. The open graphics library (OpenGL) tessellation rendering pipeline is utilized for hair generation. The hair rendering algorithm was integrated into the Frapper’s character rendering pipeline. Inside Frapper, configuration of the hair style can be adjusted. Development was done in cooperation with the Animation Institute of Filmakademie Baden- Württemberg within the research project “Stylized Animations for Research on Autism” (SARA). Keywords: thesis, hair, view-dependent level of detail, tessellation, OpenGL, Ogre, Frapper i Real-Time Hair Rendering Declaration of Originality Declaration of O r i g i n a l i t y I hereby certify that I am the sole author of this thesis and that no part of this thesis has been published or submitted for publication. -
Opencl-Accelerated Point Feature Histogram and Its Application in Railway Track Point Cloud Data Processing
OpenCL-accelerated Point Feature Histogram and Its Application in Railway Track Point Cloud Data Processing Dongxu Lv, Peijun Wang, Wentao Li and Peng Chen School of Mechanical Engineering, Southwest Jiaotong University, Chengdu, China Keywords: OpenCL, PFH, Parallel Computing, Point Cloud Data. Abstract: To meet the requirements of railway track point cloud processing, an OpenCL-accelerated Point Feature His- togram method is proposed using heterogeneous computing to improve the low computation efficiency. Ac- cording to the characteristics of parallel computing of OpenCL, the data structure for point cloud storage is reconfigured. With the kernel performance analysis by CodeXL, the data reading is improved and the load of ALU is promoted. In the test, it obtains 1.5 to 40 times speedup ratio compared with the original functions at same precision of CPU algorithm, and achieves better real-time performance and good compatibility to PCL. 1 INTRODUCTION processors, GPU is particularly suitable for data par- allel algorithms (Tompson and Schlachter, 2012). Point cloud data processing is an importance issue in These algorithms are implemented by OpenCL pro- computer vision, 3D reconstruction, reverse engi- gramming and compiled into one or more kernels, neering and other industrial fields. For the increasing with GPU as OpenCL devices to execute these kernel. amount of point clouds, a services of function librar- Parallel computing technology provides more ies are developed for point cloud data processing. possibility to process engineering point cloud data. Among them, PCL (Point Cloud Library) is a type of However, some PCL functions with low running effi- C++ based solution with filtering, feature extraction, ciency restrict the real-time performance of system. -

Radeon HD 5000 Series
Radeon HD 5000 series The Evergreen series is a family of GPUs developed by Advanced Micro Devices for its Radeon line under the ATI brand name. It was employed in Radeon HD 5000 graphics card series and competed directly with Nvidia's GeForce 400 Series. ATI Radeon HD 5000 series Release September 10, date 2009 Contents Codename Evergreen Manhattan Release Architecture TeraScale 2 Architecture Transistors Multi-monitor support 292M 40 nm Video acceleration (Cedar) OpenCL (API) 627M 40 nm (Redwood) Radeon Feature Table 1.040B 40 nm Desktop products (Juniper) Radeon HD 5900 2.154B 40 nm Radeon HD 5800 (Cypress) Radeon HD 5700 Radeon HD 5600 Cards Radeon HD 5500 Entry-level 5450 Radeon HD 5400 5550 Mobile products 5570 Mid-range Graphics device drivers 5670 AMD's proprietary graphics device driver "Catalyst" 5750 Free and open-source graphics device driver "Radeon" 5770 High-end 5830 See also 5850 References 5870 External links Enthusiast 5970 Laptop products API support Direct3D Direct3D 11 Release (feature level 11_0) [1] The existence was spotted on a presentation slide from AMD Technology Analyst Day July 2007 as "R8xx". AMD held a Shader Model 5.0 [4] press event in the USS Hornet Museum on September 10, 2009 and announced ATI Eyefinity multi-display technology OpenCL OpenCL 1.2 [2] and specifications of the Radeon HD 5800 series' variants. The first variants of the Radeon HD 5800 series were launched OpenGL OpenGL 4.5[3] September 23, 2009, with the HD 5700 series launching October 12 and HD 5970 launching on November 18[5] The HD 5670, was launched on January 14, 2010, and the HD 5500 and 5400 series were launched in February 2010, completing History what has appeared to be most of AMD's Evergreen GPU lineup. -

Parallel Acceleration of H.265 Video Processing
Eetu Latja Parallel Acceleration of H.265 Video Processing School of Science Thesis submitted for examination for the degree of Master of Science in Technology. Espoo 12.5.2017 Thesis supervisor: Senior university lecturer Vesa Hirvisalo Thesis advisor: M.Sc. Jussi Hanhirova aalto university abstract of the school of science master’s thesis Author: Eetu Latja Title: Parallel Acceleration of H.265 Video Processing Date: 12.5.2017 Language: English Number of pages: 7+65 Department of Computer Science Degree programme: Master’s Programme in Computer, Communication and Information Sciences Major: Software Technology Code: SCI3042 Supervisor: Senior university lecturer Vesa Hirvisalo Advisor: M.Sc. Jussi Hanhirova The objective of this study was to research the scalability of the parallel features in the new H.265 video compression standard, also know as High Efficiency Video Coding (HEVC). Compared to its predecessor, the H.264 standard, H.265 typically achieves around 50% bitrate reduction for the same subjective video quality. Especially videos with higher resolution (Full HD and beyond) achieve better compression ratios. Also a better utilization of parallel computing resources is provided. H.265 introduces two novel parallelization features: Tiles and Wavefront Parallel Processing (WPP). In Tiles, each video frame is divided into areas that can be decoded without referencing to other areas in the same frame. In WPP, the relations between code blocks in a frame are encoded so that the decoding process can progress through the frame as a front using multiple threads. In this study, the reference implementation for the H.265 decoder was augmented to support both of these parallelization features. -

The LPGPU2 Project: Low-Power Parallel Computing on Gpus
View metadata, citation and similar papers at core.ac.uk brought to you by CORE provided by DepositOnce Juurlink, B.; Lucas, J.; Mammeri, N.; Bliss, M.; Keramidas, G.; Kokkala, C.; Richards, A. The LPGPU2 Project: Low-Power Parallel Computing on GPUs Conference paper | Accepted manuscript (Postprint) This version is available at https://doi.org/10.14279/depositonce-7088 © ACM 2017. This is the author's version of the work. It is posted here for your personal use. Not for redistribution. The definitive Version of Record was published in SCOPES '17 Proceedings of the 20th International Workshop on Software and Compilers for Embedded Systems http://dx.doi.org/10.1145/3078659.3078672 Juurlink, B., Lucas, J., Mammeri, N., Bliss, M., Keramidas, G., Kokkala, C., & Richards, A. (2017). The LPGPU2 Project. In Proceedings of the 20th International Workshop on Software and Compilers for Embedded Systems - SCOPES ’17. ACM Press. https://doi.org/10.1145/3078659.3078672 Terms of Use Copyright applies. A non-exclusive, non-transferable and limited right to use is granted. This document is intended solely for personal, non-commercial use. The LPGPU2 Project - Low-Power Parallel Computing on GPUs Extended Abstract Ben Juurlink Jan Lucas Nadjib Mammeri TU Berlin TU Berlin TU Berlin Einsteinufer 17 Einsteinufer 17 Einsteinufer 17 Berlin, Germany 10587 Berlin, Germany 10587 Berlin, Germany 10587 [email protected] [email protected] [email protected] Martyn Bliss Georgios Keramidas Chrysa Kokkala Samsung Electronics Think Silicon Think Silicon Communications