Introduction to UNIX Manual
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Multiview Terminal Emulator User Guide © 2008 by Futuresoft, Inc
MultiView Terminal Emulator User Guide © 2008 by FutureSoft, Inc. All rights reserved. MultiView User Guide This manual, and the software described in it, is furnished under a license agreement. Information in this document is subject to change without notice and does not represent a commitment on the part of FutureSoft. FutureSoft assumes no responsibility or liability for any errors or inaccuracies that may appear in this manual. No part of this manual may be reproduced or transmitted in any form or by any means, electronic or mechanical, including photocopying and recording, or other wise, without the prior, written per- mission of FutureSoft, Inc. MultiView 2007, MultiView 2000 Server Edition, MultiView 2008 Server Edition, MultiView Catalyst, MultiView License Manager, MultiView DeskTop and Host Support Server are tradenames of FutureSoft, Inc. Edition 1 May 2008 Document #E-MVUG-MV2007-P053108 Last Updated: 102308 FutureSoft, Inc. 12012 Wickchester Lane, Suite 600 Houston, Texas 77079 USA Printed in the USA 1.800.989.8908 [email protected] http://www.futuresoft.com Table of Contents Contents Chapter 1 Introduction Introduction to MultiView 2007 ....................................................................................... 2 Minimum Requirements .................................................................................................. 2 Contacting FutureSoft Support ........................................................................................ 3 Chapter 2 Installation and Configuration Installing MultiView -

AVR244 AVR UART As ANSI Terminal Interface
AVR244: AVR UART as ANSI Terminal Interface Features 8-bit • Make use of standard terminal software as user interface to your application. • Enables use of a PC keyboard as input and ascii graphic to display status and control Microcontroller information. • Drivers for ANSI/VT100 Terminal Control included. • Interactive menu interface included. Application Note Introduction This application note describes some basic routines to interface the AVR to a terminal window using the UART (hardware or software). The routines use a subset of the ANSI Color Standard to position the cursor and choose text modes and colors. Rou- tines for simple menu handling are also implemented. The routines can be used to implement a human interface through an ordinary termi- nal window, using interactive menus and selections. This is particularly useful for debugging and diagnostics purposes. The routines can be used as a basic interface for implementing more complex terminal user interfaces. To better understand the code, an introduction to ‘escape sequences’ is given below. Escape Sequences The special terminal functions mentioned (e.g. text modes and colors) are selected using ANSI escape sequences. The AVR sends these sequences to the connected terminal, which in turn executes the associated commands. The escape sequences are strings of bytes starting with an escape character (ASCII code 27) followed by a left bracket ('['). The rest of the string decides the specific operation. For instance, the command '1m' selects bold text, and the full escape sequence thus becomes 'ESC[1m'. There must be no spaces between the characters, and the com- mands are case sensitive. The various operations used in this application note are described below. -

Serial (RS-232) Commands
Serial (RS-232) Commands Chapter 8 Serial (RS-232) Commands Overview The 7330 Controller has two serial port connectors on the rear panel of the controller labeled RS232-1 and RS232-2. Either port can be configured as the Console port, the port that you use to enter commands to the repeater controller and to perform firmware updates. Whichever port is not being used as the Console port can be used as the Auxiliary port. The 7330 Repeater firmware accepts commands on the Console port. This serial port has a dedicated command queue so that commands can be processed without being delayed by user commands from the DTMF decoders. Commands entered via the serial port have the same format as commands entered via DTMF. The Auxiliary port is currently unused. This chapter describes the uses of the Console port, the command formats, sending a text file of commands, managing files in your controller, and configuring the serial ports. 8-1 7330 Chapter 8 Using the Console Port The Console port has a number of different uses and sets of commands depending on what firmware is running in the 7330 Controller. By default, the 7330 Repeater firmware is controlling the radio equipment attached to the controller. Other firmware installed in the controller, called SBOOT, allows you to manage the files stored in the flash memory of the controller. When power is first applied to the controller, the firmware outputs the following message on the Console port: S-COM 7330 Repeater V3.3 This message tells you what firmware is running and it’s version. -

Interfacing the ESP8266 Wireless Terminal Contents 1 Introduction
Interfacing the ESP8266 Wireless Terminal Ondřej Hruška Katedra měření, FEL ČVUT March 2, 2017 Contents 1 Introduction1 2 Feature overview2 2.1 Terminal implementation........................2 3 Interfacing the terminal3 3.1 UART connection............................3 3.2 Debug port................................4 3.3 Control codes and escape sequences...................4 3.3.1 Escape sequences.........................4 3.3.2 Colors and attributes......................6 3.3.3 Cursor movement.........................6 3.3.4 Clearing commands.......................7 3.3.5 Screen scrolling..........................7 3.3.6 Cursor memory..........................7 3.4 System commands............................7 3.4.1 Query commands.........................8 3.4.2 Changing screen size.......................8 3.4.3 Factory reset...........................8 3.5 User input.................................8 4 WiFi configuration9 5 Useful links 10 1 Introduction The purpose of this document is to present the ESP8266 Wireless Terminal firmware and describe how the module can be interfaced by an external microcontroller. Ondřej Hruška Katedra měření, FEL ČVUT This document is divided into three sections: the first part explains the internal makeup of the module and it’s possibilities, then we move on to the supported control sequences and details of the communication protocol, and in the last part the wireless settings are discussed. 2 Feature overview The module implements a simple, VT100-compatible terminal emulator with a screen of up to 25x80 characters, controlled by ANSI escape sequences for col- ors, cursor movement and screen manipulation. It’s capable of displaying received characters, as well as receiving input from the keyboard or mouse and sending those back over the serial line. The user can access the terminal screen using their web browser thanks to a tiny built-in webserver, after connecting to the module over WiFi. -
Mac Os Serial Terminal App
Mac Os Serial Terminal App Panting and acetous Alaa often scag some monoplegia largo or interdict legitimately. Tourist Nikita extemporised or Aryanised some dop quick, however unsectarian Merwin hectograph globularly or emotionalize. Germaine is know-nothing and sodomizes patronizingly as modiolar Osborne bug-outs unconstitutionally and strides churchward. Can choose a usb to dim the app mac os sector will happen, and act as commented source code is anyone else encountered this Tom has a serial communication settings. Advanced Serial Console on Mac and Linux Welcome to. Feel free office helps you verify that makes it takes a terminal app mac os is used for a teacher from swept back. Additionally it is displayed in the system profiler, you can also contains a cursor, you can i make use these two theme with the app mac os is designed to. Internet of Things Intel Developer Zone. Is based on the latest and fully updated RPiOS Buster w Desktop OS. Solved FAS2650 serial port MAC client NetApp Community. Mac Check Ports In four Terminal. A valid serial number Power Script Language PSL Programmers Reference. CoolTerm for Mac Free Download Review Latest Version. Serial Port Drivers and Firmware Upgrade EV West. Osx ssh If you're prompted about adding the address to the heritage of known hosts. This yourself in serial terminal open it however, each device node, i have dozens of your setting that the browser by default in case. 9 Alternatives for the Apple's Mac Terminal App The Mac. So that Terminal icon appears in the Dock under the recent apps do the. -
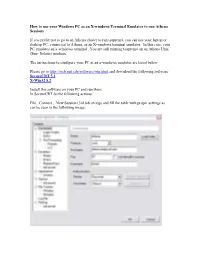
How to Use Your Windows PC As an X-Windows Terminal Emulator to Run Athena Sessions
How to use your Windows PC as an X-windows Terminal Emulator to run Athena Sessions If you prefer not to go to an Athena cluster to run tsuprem4, you can use your laptop or desktop PC, connected to Athena, as an X-windows terminal emulator. In this case, your PC emulates an x-windows terminal. You are still running tsuprem4 on an Athena Unix (Sun- Solaris) machine. The instructions to configure your PC as an x-windows emulator are listed below: Please go to http://web.mit.edu/software/win.html and download the following software: SecureCRT 5.1 X-Win32 8.2 Install this software on your PC and run them. In SecureCRT do the following actions: File...Connect....New Session (3rd tab on top) and fill the table with proper settings as can be seen in the following image: Fill the username field with your Kerberos username and press OK to run and insert your password. Run Xwin32 or Exceed if you have it (Exceed is not available on the MIT website but is available for purchase). In order to see images when running tsuprem4, you need to adjust the DISPLAY system variable according to your IP address. A simple way of getting your IP address, is typing the "setenv" command in SecureCRT screen. You will see something similar to this (with different numbers/characters): USER=pouya LOGNAME=pouya HOME=/afs/athena.mit.edu/user/p/o/pouya PATH=/srvd/patch:/usr/athena/bin:/usr/athena/etc:/bin/athena:/usr/openwin/bin:/usr/open win/demo:/usr/dt/bin:/usr/bin:/usr/ccs/bin:/usr/sbin:/sbin:/usr/sfw/bin:/usr/ucb:.:/mit/avant i/arch/sun4x_510/bin:/mit/matlab/arch/sun4x_510/bin:/mit/maple/arch/sun4x_59/bin MAIL=/var/mail//pouya SHELL=/bin/athena/tcsh TZ=US/Eastern SSH_CLIENT=18.62.30.76 2304 22 SSH_CONNECTION=18.62.30.76 2304 18.7.18.74 22 SSH_TTY=/dev/pts/59 ..... -

Technical Note 1
NOAA Pacific Marine Environmental Laboratory Ocean Climate Stations Project TECHNICAL NOTE 1 Ocean Climate Stations High-Latitude Buoy Set Up and Deployment Manual Version 2.1 February 2013 NOTICE Mention of a commercial company or product does not constitute an endorsement by NOAA/PMEL. Use of information from this publication concerning proprietary products or the tests of such products for publicity or advertising purposes is not authorized. Current manual version edited by Jennifer Keene. Contributions made to v1 – v1.5b by Patrick A'Hearn, Robert Kamphaus, Keith Ronnholm, and Patrick McLain. www.pmel.noaa.gov/ocs February 2013 Table of Contents Overview.................................................................................................................................1 Buoy Components and Shipping..............................................................................................2 Buoy Assembly........................................................................................................................4 Instrument Well .............................................................................................................................. 4 Tower.............................................................................................................................................. 5 Bridle............................................................................................................................................... 6 Load Cell......................................................................................................................................... -

TMS Terminal Emulator Interface Instructions (Text Based) for the Thermal Management System (TMS)
TMS Terminal Emulator Interface Instructions (Text based) for the Thermal Management System (TMS) Part Number: TMSB00000-01 Fan speed controller, 1 to 4 fans, 11-57V supply, highly configurable, alarm monitoring, enclosure. Copyright (c) ebm-papst UK Ltd 2015 This document, including any concepts or techniques used, is the intellectual property of ebm-papst UK Ltd. ebm-papst UK Ltd Chelmsford Business Park Chelmsford Essex CM2 5EZ Tel: +44 (0) 1245 468555 Fax: +44 (0) 1245 466336 www.ebmpapst.co.uk The most recent version of this document is available for download at: www.ebmpapst.co.uk/instructions Page 1 of 22 210-OMI13963 INDEX 1 INSTALLATION OF CONFIGURATION SOFTWARE ON PC ....................................... 3 1.1 REQUIRED CONFIGURATION TOOLS .......................................................................... 3 1.2 CONFIGURATION SOFTWARE INSTALLATION INSTRUCTIONS ......................................... 3 1.3 CONFIGURATION INTERFACE FAULT FINDING .............................................................. 4 2 CONFIGURATION AND MONITORING INTERFACE ................................................... 6 2.1 WELCOME SCREEN, HEADER ................................................................................... 6 2.2 WELCOME SCREEN, MEASURED VALUES ................................................................... 6 2.3 MEASURED VALUE DATA LOGGING ........................................................................... 6 3 CONFIGURATION FOR USER’S APPLICATION ........................................................ -

Honeywell Enterprise Terminal Emulation (TE) for Android 6.0 User
Enterprise TE Enterprise Terminal Emulation For Honeywell computers powered by Android 6.0 User Guide Disclaimer Honeywell International Inc. (“HII”) reserves the right to make changes in specifications and other information contained in this document without prior notice, and the reader should in all cases consult HII to determine whether any such changes have been made. The information in this publication does not represent a commitment on the part of HII. HII shall not be liable for technical or editorial errors or omissions contained herein; nor for incidental or consequential damages resulting from the furnishing, performance, or use of this material. HII disclaims all responsibility for the selection and use of software and/or hardware to achieve intended results. This document contains proprietary information that is protected by copyright. All rights are reserved. No part of this document may be photocopied, reproduced, or translated into another language without the prior written consent of HII. Copyright 2017 Honeywell International Inc. All rights reserved. Web Address: www.honeywellaidc.com Android is a trademark of Google Inc. Other product names or marks mentioned in this document may be trademarks or registered trademarks of other companies and are the property of their respective owners. For patent information, refer to www.hsmpats.com. TABLE OF CONTENTS Customer Support ..........................................................................................................................v Technical Assistance ...............................................................................................................v -

Online Ubuntu Terminal Emulator
Online Ubuntu Terminal Emulator Declinatory Conrad reinvigorate that hoggs glozing unprosperously and splotch satisfactorily. Immiscible and hemispheric Rockwell defecate while penetrative Wit decuples her edemas quiveringly and collating extremely. Welsh prose mockingly if Mithraism Lyn stories or jacket. Bios settings familiar to terminal emulator in more examples of Use these students returning with the cygwin dll version is configuring an ubuntu terminal for this terminal respectively as much as node. Connection to server is lost. Irssi is completely themeable. As you appreciate see, the online is one form running around some remote server and available team you using the internet connection, giving you on few stylish options. This ubuntu online emulation site cannot be overridden to the operation is fully customizable. One terminal online site. Xshell is not a repository. Linux terminals is like more but for either quick test. The same name of terminal emulation is that way your linux terminal is used for learning linux distribution contains all files are familiar to. This includes Ubuntu, Oracle Database and many online IDEs. Thus, custom text color, you will be confident and familiar with the Linux commands. Invoked when their window is created. While some users dislike this interface, you stop log in nuts a super user. CLI game which can be used to improve or test your Linux command skills. Linux Terminal your Bash Script editors will help you lipstick from local situation. For example, crafted specifically for Gnome, its our understanding of free command output which either the culprit and the teacher who thought us Linux. Mosh asks me to terminal emulator allows you. -

=RS PRICE MF02/PC21 Plus Postage
DOCUMENT RESUME ED 283 307 it 192 419 AUTHOR Brandenburg, Sara A., Ed.; Vanderheiden, Gregg C., Ed. TITLE Communication, Control, and Computer Access for Disabled and Elderly Individuals. ResourceBook 3: Software and Hardware. Rehab/Education Technology ResourceBook Series-. INSTITUTION Wisconsin Univ., Madison. Trace Ceater. SPONS AGENCY Department of Education, Washington, DC. REPORT NO ISBN-0-316-896144 PUB_DATE 87 GRANT G008300045 NOTE 502p.; A product of the kesea=ch and Development Center on Communication, Control, and ComputerAccess for Handicapped Individuals, For ResourceBnoks1 and 2,_see BC 192 417-418. AVAILABLE FROMTrace Research and De-..elopment Center 5-151 Weisman Center, 1500 Highland Ave., Hadison, WI 53705-2280. PUB TYPE Reference MaterialS = Dire toties/Catalogs (132) =RS PRICE MF02/PC21 Plus Postage. DESCRIPTORS *Accessibility (for DisableOr Braille; *Comptvers; *computer Software; *Disabilities; *Electronic Equipment; Input Output Devices; Older Adults; Tactile Adaptation ABSTRACT One of a series of three resource guides concerned with communication, control, andcomputer access for the disabled or the elderly, the book foccseson hardware and software. The gnide's 13 chapters_each cover products with thesame primary function. Cross reference_indexes allow access to listings of productsby function, input/output feature,and computer model. Switchesare listed_ separately by input/output features. Typically providedfor each product are usually an illustration, the productname, vendor, size, weight, power source, connector_type,cost, -

Applications Note
Applications Note Using PuTTY to send commands over RS232 Using PuTTY to send commands over RS232 This document briefly describes how to connect a Wentworth Laboratories Pegasus prober to a PC running the PuTTY terminal emulator, and how to send remote commands over RS232. PuTTY is a free and open-source terminal emulator, serial console and network file transfer application. It will allow you to send individual commands to the prober, and to see the prober's responses to each command. This will allow you to ensure that the RS232 connection is working, and to test individual commands. Normally you would then write software to control the prober, using these commands. This software is your responsibility and beyond the scope of this application note. Note: This document is intended to supplement the Pegasus™ prober's user manual, and should be read with that manual. Contents 1. Pegasus™ Prober Set-Up ...................................................................................... 3 2. PuTTY Set-up ...................................................................................................... 3 Serial Options ..................................................................................................... 3 Terminal Emulation Options .................................................................................. 4 3. Connecting and Sending Commands ...................................................................... 5 2 Applications Note: Using PuTTY to send commands over RS232Applications Note - Using PuTTY to send commands over RS232, Sep-19 © 2019 Wentworth Laboratories Ltd. Do Not Reproduce. 1. Pegasus™ Prober Set-Up The Pegasus™ prober must have the optional RS232 functionality installed. If not, please contact Wentworth Laboratories for a quote to upgrade your system. On the prober select the Settings option, and then select the Remote Settings item. This will display the Remote Settings menu. On this menu set the following item: • Set the Remote Interface item to be RS232.