Introductory Statistics with R (2Nd Edition)
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Postgis 3.1.0Alpha1 Manual I
PostGIS 3.1.0alpha1 Manual i PostGIS 3.1.0alpha1 Manual PostGIS 3.1.0alpha1 Manual ii Contents 1 Introdução 1 1.1 Comitê Diretor do Projeto . .1 1.2 Contribuidores Núclero Atuais . .2 1.3 Contribuidores Núclero Passado . .2 1.4 Outros Contribuidores . .2 2 Instalação do PostGIS 5 2.1 Versão Reduzida . .5 2.2 Compilando e instalando da fonte: detalhado . .5 2.2.1 Obtendo o Fonte . .6 2.2.2 Instalando pacotes requeridos . .6 2.2.3 Configuração . .7 2.2.4 Construindo . .9 2.2.5 Contruindo extensões PostGIS e implantado-as . .9 2.2.6 Testando . 11 2.2.7 Instalação . 20 2.3 Instalando e usando o padronizador de endereço . 21 2.3.1 Instalando Regex::Montar . 21 2.4 Instalando, Atualizando o Tiger Geocoder e carregando dados . 21 2.4.1 Tiger Geocoder ativando seu banco de dados PostGIS: Usando Extensão . 22 2.4.1.1 Convertendo uma Instalação Tiger Geocoder Regular para Modelo de Extensão . 24 2.4.2 Tiger Geocoder Ativando seu banco de dados PostGIS: Sem Utilizar Extensões . 24 2.4.3 Usando Padronizador de Endereço com Tiger Geocoder . 25 2.4.4 Carregando Dados Tiger . 25 2.4.5 Atualizando sua Instalação Tiger Geocoder . 26 2.5 Problemas comuns durante a instalação . 26 PostGIS 3.1.0alpha1 Manual iii 3 PostGIS Administration 28 3.1 Tuning your configuration for performance . 28 3.1.1 Startup . 28 3.1.2 Runtime . 29 3.2 Configuring raster support . 29 3.3 Creating spatial databases . 30 3.3.1 Spatially enable database using EXTENSION . -

Vefþjónustur SFR
Vefþjónustur SFR Vefþjónustur SÍ - SFR Efnisyfirlit Vefþjónustur SÍ - SFR Efnisyfirlit 1. Almennt 2. Slóðir 2.1. Skyggnir 2.1.1. Prófunarumhverfi Skyggnir 2.1.2. Raunumhverfi Skyggnir 2.2. TR/SÍ 2.2.1. Prófunarumhverfi TR/SÍ 2.2.2. Raunumhverfi TR/SÍ 3. Umslag : sfr 3.1. profun 3.2. stadasjuklings 3.3. vistaskjal 3.4. tryggingaskra 4. Stoðgögn 4.1. Villulisti 4.2. Staða sjúklings : tafla 4.3. Þjónustuflokkar sjúkrahúsa 4.4. Þjónustflokkar heilsugæslu (hér bætist oft nýtt við með nýjum sendendum) 4.5. TR-kóði: 5. SFR-soap köll 5.1. SFR-profun 5.2. SFR-stadasjuklings 5.3. SFR-vistaskjal 5.4. profun: 5.5. stadasjuklings: 5.6. vistaskjal: 1. Almennt Föll sem viðskiptavinir geta sent SÍ eru móttekin í gegnum SOAP-umslag. Umslag sfr Umslag fyrir upplýsingar tengdar ýmsum lækniskostnaði og útreikningi á komugjöldum. Upplýsingar sem fara á milli grunnkerfa SÍ og kerfa viðskiptavina SÍ. 2. Slóðir 2.1. Skyggnir Föll sem eru uppsett hjá Skyggni eru: profun stadasjuklings tryggingaskra Þau eru uppsett á eftirfarandi slóðum: 2.1.1. Prófunarumhverfi Skyggnir Prófunarumhverfi : https://pws.sjukra.is/sfr/sfr.svc Schema skilgreining : https://pws.sjukra.is/sfr/sfr.svc?wsdl 2.1.2. Raunumhverfi Skyggnir Raunumhverfi : https://ws.sjukra.is/sfr/sfr.svc Schema skilgreining : https://ws.sjukra.is/sfr/sfr.svc?wsdl 2.2. TR/SÍ Föllin sem eru uppsett hjá TR/SÍ eru: profun stadasjuklings vistaskjal Þau eru uppsett á eftirfarandi slóðum 2.2.1. Prófunarumhverfi TR/SÍ Prófunarumhverfi : https://huld.sjukra.is/p/sfr Schema skilgreining : https://huld.sjukra.is/p/sfr?wsdl 2.2.2. -

The R and Omegahat Projects in Statistical Computing
The R and Omegahat Projects in Statistical Computing Brian D. Ripley [email protected] http://www.stats.ox.ac.uk/∼ripley Outline • Statistical Computing – History – S – R • Application and Comparisons – Web servers – Embedding — Medieval Chant – R vs S-PLUS • Omegahat and Component Systems – The Omegahat project – Components — GGobi – The future? Statistical Computing and S Scene-setting: Statistical Computing 1980 Mainly Fortran programming, or PL/I (SAS). Batch computing (SAS, BMDP, SPSS, Genstat) with restricted range of platforms. Some small interactive systems (GLIM 3.77, Minitab). Very poor interactive graphics (2400 baud to a Tektronix storage tube if you were lucky). Flatbed and drum plotters, microfilm for publication-quality output off-line. Mainly home-brew solutions in research. (GLIM macros?) 1990 PCs become widespread, but FPUs still uncommon. Sun etc workstations available for researchers, and for teaching in a few places. Graphics could be pretty good (postscript printers, ca 1000 × 1000 pixel screens), but often was not, and mono text terminals were still widespread. C was beginning to be used, as more portable than Fortran. (Few PC Fortran compilers then and now.) Still SAS, SPSS etc as batch programs. S beginning to be make an impact on research and teaching. 2001 Little spread in machine speed (min 500MHz, max 1.5GHz), fast FPUs are universal. Colour everywhere, usually 24-bit colour. The video-games generation is now at university. Few people would dream of writing a complete program for a research idea: prototype and distribute in a higher-level language such as S or Matlab or Gauss or Ox or ... -

STOC-AGENT 講習会 (コンパイル編) 海岸港湾研究室(有川研究室) Installer
STOC-AGENT 講習会 (コンパイル編) 海岸港湾研究室(有川研究室) Installer 1) • MSMPI(Microsoft MPI v10.0 (Archived)) -msmpisdk.msi 前回配布分との変更点 -msmpisetup.exe 2) • gfortran Compiler(Mingw-w64) -mingw-w64-install.exe 3) • GNU MAKE -make-3.81.exe 4) • CADMAS-VR -CadmasVR_3.1.1_Setup_21050622.exe • CADMAS-MESH-MULTI 4) -CADMAS-MESH-MULTI-1.3.4-x64-setup.exe REFERED 1) https://www.microsoft.com/en-us/download/details.aspx?id=56727 2) http://mingw-w64.org/doku.php/download/mingw-builds 3) http://www.gnu.org/software/make/ http://gnuwin32.sourceforge.net/packages/make.htm 4) https://www.pari.go.jp/about/ MinGW-gfortran 1.以下のサイトからMingw-w64のダウンロードを行うため画面のSourceforgeをク リック. http://mingw-w64.org/doku.php/download/mingw-builds 2.MingW-W64-build を選択し、一番右図のような画面に移る. MinGW-gfortran 3. ダウンロードしたmingw-w64-installを実行インストールします. 基本的には変更なし 3. mingw-w64がインストールされていることを確認 MinGW-gfortran 5. コントロール パネル¥システムとセキュリティ¥システム¥システムの詳細設定 6. 環境変数を開き、ユーザーの環境変数,PATHを編集(PATHもしくはpathがなけれ ば新規で変数名にPATH,変数値に8.のアドレスを入力) 7. 環境変数名の編集→新規をクリック 8. gfortran.exeのあるフォルダのアドレスを入力(おそらくC:¥Program Files (x86) ¥mingw-w64¥i686-8.1.0-posix-dwarf-rt_v6-rev0¥mingw32¥bin) C:¥Program Files (x86)¥mingw-w64¥i686-8.1.0- posix-dwarf-rt_v6-rev0¥mingw32¥bin MinGW-gfortran 9.コマンドプロンプト(cmd)を開き,gfortran –v のコマンドを入力.以下 のような画面になれば環境設定完了(gfortranのPATHが通りました) GNU MAKE 1.以下のサイトからのmake.exeのダウンロードを行うため、画面のComplete packageのSetupをクリック. http://gnuwin32.sourceforge.net/packages/make.htm 2. make-3.8.1.exeを実行しインストールしてください. GnuWin32がインストールされていることを確認します. (おそらくC:¥Program Files (x86)¥) GNU MAKE 3. コントロール パネル¥システムとセキュリティ¥システム¥システムの詳細設定 4. 環境変数を開き、ユーザーの環境変数,PATHを編集(PATHもしくはpathがなけれ ば新規で変数名にPATH,変数値に6.のアドレスを入力) 5. 環境変数名の編集→新規をクリック 6. make.exeのあるフォルダのアドレスを入力 (おそらくC:¥Program Files (x86)¥GnuWin32¥bin) C:¥Program Files (x86)¥GnuWin32¥bin MSMPI 1.以下のサイトからMicrosoft MPI v10.0のダウンロードをクリック. https://www.microsoft.com/en-us/download/details.aspx?id=57467 2.msmpisdk.msi とmsmpisetup.exe をダウンロード. 3. -

Hadley Wickham, the Man Who Revolutionized R Hadley Wickham, the Man Who Revolutionized R · 51,321 Views · More Stats
12/15/2017 Hadley Wickham, the Man Who Revolutionized R Hadley Wickham, the Man Who Revolutionized R · 51,321 views · More stats Share https://priceonomics.com/hadley-wickham-the-man-who-revolutionized-r/ 1/10 12/15/2017 Hadley Wickham, the Man Who Revolutionized R “Fundamentally learning about the world through data is really, really cool.” ~ Hadley Wickham, prolific R developer *** If you don’t spend much of your time coding in the open-source statistical programming language R, his name is likely not familiar to you -- but the statistician Hadley Wickham is, in his own words, “nerd famous.” The kind of famous where people at statistics conferences line up for selfies, ask him for autographs, and are generally in awe of him. “It’s utterly utterly bizarre,” he admits. “To be famous for writing R programs? It’s just crazy.” Wickham earned his renown as the preeminent developer of packages for R, a programming language developed for data analysis. Packages are programming tools that simplify the code necessary to complete common tasks such as aggregating and plotting data. He has helped millions of people become more efficient at their jobs -- something for which they are often grateful, and sometimes rapturous. The packages he has developed are used by tech behemoths like Google, Facebook and Twitter, journalism heavyweights like the New York Times and FiveThirtyEight, and government agencies like the Food and Drug Administration (FDA) and Drug Enforcement Administration (DEA). Truly, he is a giant among data nerds. *** Born in Hamilton, New Zealand, statistics is the Wickham family business: His father, Brian Wickham, did his PhD in the statistics heavy discipline of Animal Breeding at Cornell University and his sister has a PhD in Statistics from UC Berkeley. -
1KA Offline for Portable Use
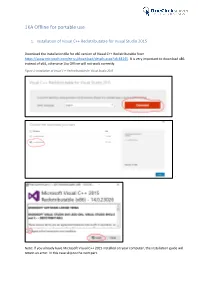
1KA Offline for portable use 1. Installation of Visual C++ Redistributable for Visual Studio 2015 Download the installation file for x86 version of Visual C++ Redistributable from https://www.microsoft.com/en-us/download/details.aspx?id=48145. It is very important to download x86 instead of x64, otherwise 1ka Offline will not work correctly. Figure 1: Installation of Visual C++ Redistributable for Visual Studio 2015 Note: If you already have Microsoft Visual C++ 2015 installed on your computer, the installation guide will return an error. In this case skip to the next part. 2. Download 1KA Offline installation pack Download 1KA Offline from https://www.1ka.si/1ka-offline and unzip the file in the package to your hard drive (C:). First, click the button »Extract to« and then select Local Disk (C:). (Figure 2) Figure 2: Extracting of the installation package After the package is extracted, open the file »UwAmp« you have just created and start the application UwAmp by clicking on »UwAmp.exe«. (Figure 3). You must repeat this step every time you want to use 1KA offline (you can also create a shortcut on the desktop for easy access to the file). Figure 3: File UwAmp.exe 3. Windows users: Installation of additional libraries for data display If you are a Windows user, you must complete the following steps to install additional libraries that enable data display in 1KA Offline. The libraries can be accessed via: • Sed: http://gnuwin32.sourceforge.net/packages/sed.htm • Gawk: http://gnuwin32.sourceforge.net/packages/gawk.htm • Coreutils: http://gnuwin32.sourceforge.net/packages/coreutils.htm You can download the installation files by clicking »Setup« (as seen on figure 4). -

Building Microsoft Windows Versions of R and R Packages Under Intel Linux
BUILDING MICROSOFT WINDOWS VERSIONS OF R AND R PACKAGES UNDER INTEL LINUX Building Microsoft Windows Versions of R and R packages under Intel Linux A Package Developer’s Tool Linux R is in the search path, then by Jun Yan and A.J. Rossini make CrossCompileBuild will run all Makefile targets described up to the section, Disclaimer Building R Packages and Bundles. This assumes: (1) you have the Makefile in a directory RCrossBuild (empty ex- Cross-building R and R packages are documented in the R cept for the makefile), and (2) that ./RCrossBuild is your [1] source by the R Development Core Team, in files such as current working directory. After this, one should man- INSTALL, readme.package, and Makefile, under the directory ually set up the packages of interest for building, though src/gnuwin32/. This point was not clearly stated in an earlier the makefile will still help with many important steps. We version of this document [2] and has caused confusions. We describe this in detail in the section on Building R Packages apologize for the confusion and claim sole responsibility [3]. In and Bundles. addition, we clarify that the final credit should go to the R De- velopment Core Team. We intended to automate and illustrate those steps by presenting an explicit example, hoping that it Setting up the Build area might save people’s time. Follow them at your own risk. Puz- zles caused by this document should NOT be directed to the R We first create a separate directory for R cross-building, Development Core Team. -

Vefþjónustur SFR - Komureikningur
Vefþjónustur SFR - komureikningur Vefþjónustur SÍ - SFR Föll sem viðskiptavinir geta sent SÍ eru móttekin í gegnum SOAP-umslag. Umslag sfr Umslag fyrir upplýsingar tengdar ýmsum lækniskostnaði og útreikningi á komugjöldum. Upplýsingar sem fara á milli grunnkerfa SÍ og kerfa viðskiptavina SÍ. Prófunarumhverfi : https://huld.sjukra.is/p/sfr Schema skilgreining : https://huld.sjukra.is/p/sfr?wsdl Ath:. Tegund gilda eru annað hvort N = númer S=strengur D=Dagsetning. Tala innan sviga eftir tegund segir til um mögulega hámarksstærð þeirra. ( dæmi: N(10) er allt að 10 stafa tala). Dagsetningasvæði eru á forminu yyyy-mm-dd [ ] utan um tegundarskilgreiningu svæði merkir að svæði sé valkvætt. Efnisyfirlit Vefþjónustur SÍ - SFR Efnisyfirlit 1. Umslag : sfr 1.1. profun 1.2. stadasjuklings 1.3. vistaskjal 2. Schema: Reikningur komugjalda 3. Skýringar við xml-tög 4. Skema 5. Stoðgögn 5.1. Villulisti 5.2. Staða sjúklings : tafla 5.3. Þjónustuflokkar sjúkrahúsa 5.4. Þjónustflokkar heilsugæslu (hér bætist oft nýtt við með nýjum sendendum) 5.5. TR-kóði: 6. SFR-soap köll 6.1. SFR-profun 6.2. SFR-stadasjuklings 6.3. SFR-vistaskjal 6.4. profun: 6.5. stadasjuklings: 6.6. vistaskjal: 6.7. Skema: 1. Umslag : sfr Sjá: http://huld.sjukra.is:8887/sfr?wsdl (fá prófunarslóð staðfesta hjá SÍ) 1.1. profun Prófunarfall til að prófa hvort samskipti eru í lagi Heiti Tegund Skýring svæðis Inntak sendandi S(100) Einkenni raunverulegs sendanda ef verið er að senda gögn fyrir hönd einhvers annars annars autt/sleppt. starfsmadur S(50) Einkenni starfsmanns sendanda ef sendandi er útfylltur annars autt/sleppt. Úttak tokst N(1) 1 ef móttaka tókst, 0 annars villulysing S(1000) Lýsing á villu ef móttaka tókst ekki. -
![R Generation [1] 25](https://docslib.b-cdn.net/cover/5865/r-generation-1-25-805865.webp)
R Generation [1] 25
IN DETAIL > y <- 25 > y R generation [1] 25 14 SIGNIFICANCE August 2018 The story of a statistical programming they shared an interest in what Ihaka calls “playing academic fun language that became a subcultural and games” with statistical computing languages. phenomenon. By Nick Thieme Each had questions about programming languages they wanted to answer. In particular, both Ihaka and Gentleman shared a common knowledge of the language called eyond the age of 5, very few people would profess “Scheme”, and both found the language useful in a variety to have a favourite letter. But if you have ever been of ways. Scheme, however, was unwieldy to type and lacked to a statistics or data science conference, you may desired functionality. Again, convenience brought good have seen more than a few grown adults wearing fortune. Each was familiar with another language, called “S”, Bbadges or stickers with the phrase “I love R!”. and S provided the kind of syntax they wanted. With no blend To these proud badge-wearers, R is much more than the of the two languages commercially available, Gentleman eighteenth letter of the modern English alphabet. The R suggested building something themselves. they love is a programming language that provides a robust Around that time, the University of Auckland needed environment for tabulating, analysing and visualising data, one a programming language to use in its undergraduate statistics powered by a community of millions of users collaborating courses as the school’s current tool had reached the end of its in ways large and small to make statistical computing more useful life. -

Matthew Kendall
Stellaris Toolchain - Matthew Kendall http://www.matthewkendall.com/freesoftware/stellaris-to... Matthew Kendall Search this site Navigation Free Software > Home Stellaris Toolchain Contact Electronics Free Software Notes on how to set up the toolchain for development in C on Luminary Micro's Stellaris ARM Cortex M3 microcontrollers. Photos StellarisWare StellarisWare is Luminary Micro's name for the useful set of libraries that they supply. DriverLib is the Peripheral Driver Library for the on-chip peripherals (and appears to have previously been used as the name of the package as a whole). GrLib is the Graphics Library that provides a set of graphics primitives and a widget set for creating graphical user interfaces on boards that have a graphical display. There is also a bootloader, some (target) utilities and (host) tools. StellarisWare is supplied with evaluation kits and also downloadable from Luminary Micro. Download the version associated with the target board you have to get appropriate example programs. GCC, binutils, et al CodeSourcery says "CodeSourcery, in partnership with ARM, Ltd., develops improvements to the GNU Toolchain for ARM processors and provides regular, validated releases of the GNU Toolchain". CodeSourcery also develops proprietary software, principally startup code and various libraries for use on the target, and a debug "sprite" for use on the development host. This is all bundled together in a package named Sourcery G++ which is available in Personal and Professional editions. Ignore this and download the Lite edition which contains just the 1 de 5 14/05/13 20:45 Stellaris Toolchain - Matthew Kendall http://www.matthewkendall.com/freesoftware/stellaris-to.. -

Statistics with Free and Open-Source Software
Free and Open-Source Software • the four essential freedoms according to the FSF: • to run the program as you wish, for any purpose • to study how the program works, and change it so it does Statistics with Free and your computing as you wish Open-Source Software • to redistribute copies so you can help your neighbor • to distribute copies of your modified versions to others • access to the source code is a precondition for this Wolfgang Viechtbauer • think of ‘free’ as in ‘free speech’, not as in ‘free beer’ Maastricht University http://www.wvbauer.com • maybe the better term is: ‘libre’ 1 2 General Purpose Statistical Software Popularity of Statistical Software • proprietary (the big ones): SPSS, SAS/JMP, • difficult to define/measure (job ads, articles, Stata, Statistica, Minitab, MATLAB, Excel, … books, blogs/posts, surveys, forum activity, …) • FOSS (a selection): R, Python (NumPy/SciPy, • maybe the most comprehensive comparison: statsmodels, pandas, …), PSPP, SOFA, Octave, http://r4stats.com/articles/popularity/ LibreOffice Calc, Julia, … • for programming languages in general: TIOBE Index, PYPL, GitHut, Language Popularity Index, RedMonk Rankings, IEEE Spectrum, … • note that users of certain software may be are heavily biased in their opinion 3 4 5 6 1 7 8 What is R? History of S and R • R is a system for data manipulation, statistical • … it began May 5, 1976 at: and numerical analysis, and graphical display • simply put: a statistical programming language • freely available under the GNU General Public License (GPL) → open-source -

Data Analysis in R
Data Analysis in R Course at a Glance This course will provide an introduction to reproducible data analysis with R (see Syllabus). Instructor Gabriel Baud-Bovy ([email protected] ) Credits: 5 Synopsis This course aims at giving to the student a methodology to analyze experimental results, from how to organize data to the writing of a report. It includes: an introduction to R an introduction to reproducible research with R examples of statistical analysis with R During this course, the student will have to analyze his own data and is expected to read before each course the material that will be made available on this page. The final grade will consist in the evaluation of a report demonstrating familiarity with the concepts and methods presented in the course. As an editor, the instructor will use Notepad++ (together with NppToR) on a Windows Machines but the student might use other ones (e.g., R studio, EMACS+ESS, Lyx, TexWork). The course will use Mardown as typesetting language. For those desirous to work with Latex and/or generate pdf, you will need to install also MikeTex. Syllabus Total of 15 hours Class 1: Case study, Reproducible research Class 2: R fundamental Class 3: Exploratory data analysis and graphical methods in R Class 4: Basic statistics Class 5: To be determined There will be a final examination decided by the instructor. Prerequisites The course assumes some familiarity with programming concepts and data structures (MATLAB, C/C++, Java or any other programming language). Contact the instructor if you have never programmed anything.