BCM56070 Switch Programming Guide
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
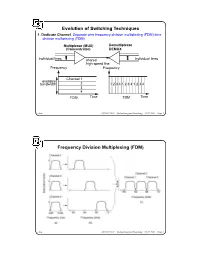
Evolution of Switching Techniques Frequency Division Multiplexing
Evolution of Switching Techniques 1. Dedicate Channel. Separate wire frequency division multiplexing (FDM) time division multiplexing (TDM) Multiplexor (MUX) Demultiplexor (Concentrator) DEMUX individual lines shared individual lines high speed line Frequency Frequency Channel 1 available bandwidth 2 1 2 3 4 1 2 3 4 1 2 3 4 3 4 FDM Time TDM Time chow CS522 F2001—Multiplexing and Switching—10/17/2001—Page 1 Frequency Division Multiplexing (FDM) chow CS522 F2001—Multiplexing and Switching—10/17/2001—Page 2 Wavelength Division Multiplexing chow CS522 F2001—Multiplexing and Switching—10/17/2001—Page 3 Impact of WDM z Many big organizations are starting projects to design WDM system or DWDN (Dense Wave Division Mutiplexing Network). We may see products appear in next three years.In Fujitsu and CCL/Taiwan, 128 different wavelengthes on the same strand of fiber was reported working in the lab. z We may have optical routers between end systems that can take one wavelenght signal, covert to different wavelenght, send it out on different links. Some are designing traditional routers that covert optical signal to electronical signal, and use time slot interchange based on high speed memory to do the switching, the convert the electronic signal back to optical signal. z With this type of optical networks, we will have a virtual circuit network, where each connection is assigned some wave length. Each connection can have 2.4 gbps tremedous bandwidth. z With inital 128 different wavelength, we can have about 10 end users. If each pair of end users needs to communicate simultaneously, it will use 10*10=100 different wavelength. -

Lecture 8: Overview of Computer Networking Roadmap
Lecture 8: Overview of Computer Networking Slides adapted from those of Computer Networking: A Top Down Approach, 5th edition. Jim Kurose, Keith Ross, Addison-Wesley, April 2009. Roadmap ! what’s the Internet? ! network edge: hosts, access net ! network core: packet/circuit switching, Internet structure ! performance: loss, delay, throughput ! media distribution: UDP, TCP/IP 1 What’s the Internet: “nuts and bolts” view PC ! millions of connected Mobile network computing devices: server Global ISP hosts = end systems wireless laptop " running network apps cellular handheld Home network ! communication links Regional ISP " fiber, copper, radio, satellite access " points transmission rate = bandwidth Institutional network wired links ! routers: forward packets (chunks of router data) What’s the Internet: “nuts and bolts” view ! protocols control sending, receiving Mobile network of msgs Global ISP " e.g., TCP, IP, HTTP, Skype, Ethernet ! Internet: “network of networks” Home network " loosely hierarchical Regional ISP " public Internet versus private intranet Institutional network ! Internet standards " RFC: Request for comments " IETF: Internet Engineering Task Force 2 A closer look at network structure: ! network edge: applications and hosts ! access networks, physical media: wired, wireless communication links ! network core: " interconnected routers " network of networks The network edge: ! end systems (hosts): " run application programs " e.g. Web, email " at “edge of network” peer-peer ! client/server model " client host requests, receives -
Circuit-Switched Coherence
Circuit-Switched Coherence ‡Natalie Enright Jerger, ‡Mikko Lipasti, and ?Li-Shiuan Peh ‡Electrical and Computer Engineering Department, University of Wisconsin-Madison ?Department of Electrical Engineering, Princeton University Abstract—Circuit-switched networks can significantly lower contention, overall system performance can degrade by 20% the communication latency between processor cores, when or more. This latency sensitivity coupled with low link uti- compared to packet-switched networks, since once circuits are set up, communication latency approaches pure intercon- lization motivates our exploration of circuit-switched fabrics nect delay. However, if circuits are not frequently reused, the for CMPs. long set up time and poorer interconnect utilization can hurt Our investigations show that traditional circuit-switched overall performance. To combat this problem, we propose a hybrid router design which intermingles packet-switched networks do not perform well, as circuits are not reused suf- flits with circuit-switched flits. Additionally, we co-design a ficiently to amortize circuit setup delay. This observation prediction-based coherence protocol that leverages the exis- motivates a network with a hybrid router design that sup- tence of circuits to optimize pair-wise sharing between cores. The protocol allows pair-wise sharers to communicate di- ports both circuit and packet switching with very fast circuit rectly with each other via circuits and drives up circuit reuse. reconfiguration (setup/teardown). Our preliminary results Circuit-switched coherence provides overall system perfor- show this leading to up to 8% improvement in overall system mance improvements of up to 17% with an average improve- performance over a packet-switched fabric. ment of 10% and reduces network latency by up to 30%. -

Medium Access Control Layer
Telematics Chapter 5: Medium Access Control Sublayer User Server watching with video Beispielbildvideo clip clips Application Layer Application Layer Presentation Layer Presentation Layer Session Layer Session Layer Transport Layer Transport Layer Network Layer Network Layer Network Layer Univ.-Prof. Dr.-Ing. Jochen H. Schiller Data Link Layer Data Link Layer Data Link Layer Computer Systems and Telematics (CST) Physical Layer Physical Layer Physical Layer Institute of Computer Science Freie Universität Berlin http://cst.mi.fu-berlin.de Contents ● Design Issues ● Metropolitan Area Networks ● Network Topologies (MAN) ● The Channel Allocation Problem ● Wide Area Networks (WAN) ● Multiple Access Protocols ● Frame Relay (historical) ● Ethernet ● ATM ● IEEE 802.2 – Logical Link Control ● SDH ● Token Bus (historical) ● Network Infrastructure ● Token Ring (historical) ● Virtual LANs ● Fiber Distributed Data Interface ● Structured Cabling Univ.-Prof. Dr.-Ing. Jochen H. Schiller ▪ cst.mi.fu-berlin.de ▪ Telematics ▪ Chapter 5: Medium Access Control Sublayer 5.2 Design Issues Univ.-Prof. Dr.-Ing. Jochen H. Schiller ▪ cst.mi.fu-berlin.de ▪ Telematics ▪ Chapter 5: Medium Access Control Sublayer 5.3 Design Issues ● Two kinds of connections in networks ● Point-to-point connections OSI Reference Model ● Broadcast (Multi-access channel, Application Layer Random access channel) Presentation Layer ● In a network with broadcast Session Layer connections ● Who gets the channel? Transport Layer Network Layer ● Protocols used to determine who gets next access to the channel Data Link Layer ● Medium Access Control (MAC) sublayer Physical Layer Univ.-Prof. Dr.-Ing. Jochen H. Schiller ▪ cst.mi.fu-berlin.de ▪ Telematics ▪ Chapter 5: Medium Access Control Sublayer 5.4 Network Types for the Local Range ● LLC layer: uniform interface and same frame format to upper layers ● MAC layer: defines medium access .. -

Rule-Based Forwarding (RBF): Improving the Internet's Flexibility
Rule-based Forwarding (RBF): improving the Internet’s flexibility and security Lucian Popa∗ Ion Stoica∗ Sylvia Ratnasamy† 1Introduction 4. rules allow flexible forwarding: rules can select ar- From active networks [33] to the more recent efforts on bitrary forwarding paths and/or invoke functionality GENI [5], a long-held goal of Internet research has been made available by on-path routers; both path and to arrive at a network architecture that is flexible.Theal- function selection can be conditioned on (dynamic) lure of greater flexibility is that it would allow us to more network and packet state. easily incorporate new ideas into the Internet’s infras- The first two properties enable security by ensuring tructure, whether these ideas aim to improve the existing the network will not forward a packet unless it has network (e.g., improving performance [36, 23, 30], relia- been explicitly cleared by its recipients while the third bility [12, 13], security [38, 14, 25], manageability [11], property ensures that rules cannot be (mis)used to attack etc.) or to extend it with altogether new services and the network itself. As we shall show, our final property business models (e.g., multicast, differentiated services, enables flexibility by allowing a user to give the network IPv6, virtualized networks). fine-grained instructions on how to forward his packets. An unfortunate stumbling block in these efforts has In the remainder of this paper, we present RBF, a been that flexibility is fundamentally at odds with forwarding architecture that meets the above properties. another long-held goal: that of devising a secure network architecture. -

Routing and Packet Forwarding
Routing and Packet Forwarding Tina Schmidt September 2008 Contents 1 Introduction 1 1.1 The Different Layers of the Internet . .2 2 IPv4 3 3 Routing and Packet Forwarding 5 3.1 The Shortest Path Problem . .6 3.2 Dijkstras Algorithm . .7 3.3 Practical Realizations of Routing Algorithms . .8 4 Autonomous Systems 10 4.1 Intra-AS-Routing . 10 4.2 Inter-AS-Routing . 11 5 Other Services of IP 11 A Dijkstra's Algorithm 13 1 Introduction The history of the internet and Peer-to-Peer networks starts in the 60s with the ARPANET (Advanced Research Project Agency Network). Back then, when computers were expen- sive and linked to several terminals, the aim of ARPANET was to establish a continuous network inbetween mainframe computers in the U.S. Starting with only three computers in 1969, mainly universities were involved in establishing the ARPANET. The ARPANET became a network inbetween networks of mainframe computes and therefore was called inter-net. Today it became the internet which links millions of computers. For a long time nobody knew what use such a Wide Area Netwok (WAN) could have for the pop- ulation. The internet was used for e-mails, newsgroups, exchange of scientific data and some special software, all in all services that were barely known in public. The spread of 1 Application Layer Peer-to-Peer-networks, e.g. Telnet = Telecommunication Network FTP = File Transfer Protocol HTTP = Hypertext Transfer Protocol SMTP = Simple Mail Transfer Protocol Transport Layer TCP = Transmission Control Protocol UDP = User Datagram Protocol Internet Layer IP = Internet Protocol ICMP = Internet Control Message Protocol IGMP = Internet Group Management Protocol Host-to-Network Layer device drivers or Link Layer (e.g. -

F. Circuit Switching
CSE 3461: Introduction to Computer Networking and Internet Technologies Circuit Switching Presentation F Study: 10.1, 10.2, 8 .1, 8.2 (without SONET/SDH), 8.4 10-02-2012 A Closer Look At Network Structure: • network edge: applications and hosts • network core: —routers —network of networks • access networks, physical media: communication links d. xuan 2 1 The Network Core • mesh of interconnected routers • the fundamental question: how is data transferred through net? —circuit switching: dedicated circuit per call: telephone net —packet-switching: data sent thru net in discrete “chunks” d. xuan 3 Network Layer Functions • transport packet from sending to receiving hosts application transport • network layer protocols in network data link network physical every host, router network data link network data link physical data link three important functions: physical physical network data link • path determination: route physical network data link taken by packets from source physical to dest. Routing algorithms network network data link • switching: move packets from data link physical physical router’s input to appropriate network data link application router output physical transport network data link • call setup: some network physical architectures require router call setup along path before data flows d. xuan 4 2 Network Core: Circuit Switching End-end resources reserved for “call” • link bandwidth, switch capacity • dedicated resources: no sharing • circuit-like (guaranteed) performance • call setup required d. xuan 5 Circuit Switching • Dedicated communication path between two stations • Three phases — Establish (set up connection) — Data Transfer — Disconnect • Must have switching capacity and channel capacity to establish connection • Must have intelligence to work out routing • Inefficient — Channel capacity dedicated for duration of connection — If no data, capacity wasted • Set up (connection) takes time • Once connected, transfer is transparent • Developed for voice traffic (phone) g. -

AT-GS950/16 Gigabit Ethernet Switch
AT-GS950/16 Gigabit Ethernet Switch AT-GS950/16 Web Interface User Guide AT-S114 Version 1.1.0 [1.00.021] 613-001857 Rev A Copyright © 2013 Allied Telesis, Inc. All rights reserved. No part of this publication may be reproduced without prior written permission from Allied Telesis, Inc. Allied Telesis and the Allied Telesis logo are trademarks of Allied Telesis, Incorporated. All other product names, company names, logos or other designations mentioned herein are trademarks or registered trademarks of their respective owners. Allied Telesis, Inc. reserves the right to make changes in specifications and other information contained in this document without prior written notice. The information provided herein is subject to change without notice. In no event shall Allied Telesis, Inc. be liable for any incidental, special, indirect, or consequential damages whatsoever, including but not limited to lost profits, arising out of or related to this manual or the information contained herein, even if Allied Telesis, Inc. has been advised of, known, or should have known, the possibility of such damages. Contents List of Figures ................................................................................................................................................ 11 List of Tables ................................................................................................................................................. 15 Preface ........................................................................................................................................................... -

Introduction to IP Multicast Routing
Introduction to IP Multicast Routing by Chuck Semeria and Tom Maufer Abstract The first part of this paper describes the benefits of multicasting, the Multicast Backbone (MBONE), Class D addressing, and the operation of the Internet Group Management Protocol (IGMP). The second section explores a number of different algorithms that may potentially be employed by multicast routing protocols: - Flooding - Spanning Trees - Reverse Path Broadcasting (RPB) - Truncated Reverse Path Broadcasting (TRPB) - Reverse Path Multicasting (RPM) - Core-Based Trees The third part contains the main body of the paper. It describes how the previous algorithms are implemented in multicast routing protocols available today. - Distance Vector Multicast Routing Protocol (DVMRP) - Multicast OSPF (MOSPF) - Protocol-Independent Multicast (PIM) Introduction There are three fundamental types of IPv4 addresses: unicast, broadcast, and multicast. A unicast address is designed to transmit a packet to a single destination. A broadcast address is used to send a datagram to an entire subnetwork. A multicast address is designed to enable the delivery of datagrams to a set of hosts that have been configured as members of a multicast group in various scattered subnetworks. Multicasting is not connection oriented. A multicast datagram is delivered to destination group members with the same “best-effort” reliability as a standard unicast IP datagram. This means that a multicast datagram is not guaranteed to reach all members of the group, or arrive in the same order relative to the transmission of other packets. The only difference between a multicast IP packet and a unicast IP packet is the presence of a “group address” in the Destination Address field of the IP header. -

Analysis and Improvement of Name-Based Packet Forwarding
Analysis and Improvement of Name-based Packet Forwarding over Flat ID Network Architectures Antonio Rodrigues Peter Steenkiste Ana Aguiar [email protected] [email protected] [email protected] Carnegie Mellon University Carnegie Mellon University Faculty of Engineering, Univ. of Porto Pittsburgh, PA, USA Pittsburgh, PA, USA Instituto de Telecomunicações Faculty of Engineering, Univ. of Porto Porto, Portugal Instituto de Telecomunicações Porto, Portugal ABSTRACT URLs to identify web objects. Name-based Information Centric One of ICN’s main challenges is attaining forwarding table scala- Networks (ICNs) such as NDN [8] promise to be a good fit for such bility when confronted with a huge content space. This is specially applications, for two reasons: (1) no need for external name lookup true in flat ID architectures, which do not naturally support route (e.g., DNS or GNS [18]) by using name-based forwarding at the aggregation for hierarchical names. Previous work has proposed network layer; and (2) reduced forwarding table sizes as a result improving scalability by aggregating content names in a fixed-size of the aggregation enabled by the hierarchical structure of names. Bloom Filters (BF). However, the negative impact of false positive In contrast, ICNs based on flat IDs (defined as fixed-size bit strings (FPs) matches on forwarding correctness and performance has not in this paper), e.g., DONA [12], PURSUIT [6], do not natively have been studied thoroughly. In this paper, we study the end-to-end net- these benefits. work performance of BF-based forwarding. We devise an analytical Recently, a forwarding scheme based on Bloom Filters (BFs) [13, model that accurately models BF-based forwarding and the flow of 14] has been proposed to enable aggregation of content descriptors BF-based packets over inter-domain topologies. -

Unicast Reverse Path Forwarding Configuration Guide, Cisco IOS XE 17 (Cisco ASR 900 Series)
Unicast Reverse Path Forwarding Configuration Guide, Cisco IOS XE 17 (Cisco ASR 900 Series) First Published: 2020-01-10 Americas Headquarters Cisco Systems, Inc. 170 West Tasman Drive San Jose, CA 95134-1706 USA http://www.cisco.com Tel: 408 526-4000 800 553-NETS (6387) Fax: 408 527-0883 THE SPECIFICATIONS AND INFORMATION REGARDING THE PRODUCTS IN THIS MANUAL ARE SUBJECT TO CHANGE WITHOUT NOTICE. ALL STATEMENTS, INFORMATION, AND RECOMMENDATIONS IN THIS MANUAL ARE BELIEVED TO BE ACCURATE BUT ARE PRESENTED WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED. USERS MUST TAKE FULL RESPONSIBILITY FOR THEIR APPLICATION OF ANY PRODUCTS. THE SOFTWARE LICENSE AND LIMITED WARRANTY FOR THE ACCOMPANYING PRODUCT ARE SET FORTH IN THE INFORMATION PACKET THAT SHIPPED WITH THE PRODUCT AND ARE INCORPORATED HEREIN BY THIS REFERENCE. IF YOU ARE UNABLE TO LOCATE THE SOFTWARE LICENSE OR LIMITED WARRANTY, CONTACT YOUR CISCO REPRESENTATIVE FOR A COPY. The Cisco implementation of TCP header compression is an adaptation of a program developed by the University of California, Berkeley (UCB) as part of UCB's public domain version of the UNIX operating system. All rights reserved. Copyright © 1981, Regents of the University of California. NOTWITHSTANDING ANY OTHER WARRANTY HEREIN, ALL DOCUMENT FILES AND SOFTWARE OF THESE SUPPLIERS ARE PROVIDED “AS IS" WITH ALL FAULTS. CISCO AND THE ABOVE-NAMED SUPPLIERS DISCLAIM ALL WARRANTIES, EXPRESSED OR IMPLIED, INCLUDING, WITHOUT LIMITATION, THOSE OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT OR ARISING FROM A COURSE OF DEALING, USAGE, OR TRADE PRACTICE. IN NO EVENT SHALL CISCO OR ITS SUPPLIERS BE LIABLE FOR ANY INDIRECT, SPECIAL, CONSEQUENTIAL, OR INCIDENTAL DAMAGES, INCLUDING, WITHOUT LIMITATION, LOST PROFITS OR LOSS OR DAMAGE TO DATA ARISING OUT OF THE USE OR INABILITY TO USE THIS MANUAL, EVEN IF CISCO OR ITS SUPPLIERS HAVE BEEN ADVISED OF THE POSSIBILITY OF SUCH DAMAGES. -

Show Crypto Ace Redundancy Through Show Cts Sxp
show crypto ace redundancy through show cts sxp • show crypto ace redundancy, on page 4 • show crypto ca certificates, on page 6 • show crypto ca crls, on page 9 • show crypto ca roots, on page 10 • show crypto ca timers, on page 11 • show crypto ca trustpoints, on page 12 • show crypto call admission statistics, on page 13 • show crypto ctcp, on page 15 • show crypto datapath, on page 17 • show crypto debug-condition, on page 20 • show crypto dynamic-map, on page 23 • show crypto eli, on page 24 • show crypto eng qos, on page 26 • show crypto engine, on page 27 • show crypto engine accelerator sa-database, on page 31 • show crypto engine accelerator ring, on page 32 • show crypto engine accelerator logs, on page 34 • show crypto engine accelerator statistic, on page 36 • show crypto gdoi, on page 52 • show crypto ha, on page 81 • show crypto identity, on page 82 • show crypto ikev2 cluster, on page 83 • show crypto ikev2 diagnose error, on page 85 • show crypto ikev2 policy, on page 86 • show crypto ikev2 profile, on page 88 • show crypto ikev2 proposal, on page 90 • show crypto ikev2 sa, on page 92 • show crypto ikev2 session, on page 95 • show crypto ikev2 stats, on page 98 • show crypto ipsec client ezvpn, on page 105 • show crypto ipsec transform-set default, on page 108 show crypto ace redundancy through show cts sxp 1 show crypto ace redundancy through show cts sxp • show crypto ipsec sa, on page 110 • show crypto ipsec security-association idle-time, on page 120 • show crypto ipsec security-association lifetime, on page 121 • show