A Resource-Efficient IP-Based Network Architecture for In-Vehicle
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Literature Review in the Fields of Standards, Projects, Industry and Science
LITERATURE REVIEW IN THE FIELDS OF STANDARDS, PROJECTS, INDUSTRY AND SCIENCE DOCUMENT TYPE: DELIVERABLE DELIVERABLE N0: D1.1 DISTRIBUTION LEVEL: PUBLIC DATE: 11/07/2016 VERSION: FINAL AUTHOR(S): LEONID LICHTENSTEIN, FLORIAN RIES, MICHAEL VÖLKER, JOS HÖLL, CHRISTIAN KÖNIG (TWT); JOSEF ZEHETNER (AVL); OLIVER KOTTE, ISIDRO CORAL, LARS MIKELSONS (BOSCH); NICOLAS AMRINGER, STEFFEN BERINGER, JANEK JOCHHEIM, STEFAN WALTER (DSPACE); CORINA MITROHIN, NATARAJAN NAGARAJAN (ETAS); TORSTEN BLOCHWITZ (ITI); DESHENG FU (LUH); TIMO HAID (PORSCHE); JEAN- MARIE QUELIN (RENAULT); RENE SAVELSBERG, SERGE KLEIN (RWTH); PACOME MAGNIN, BRUNO LACABANNE (SIEMENS); VIKTOR SCHREIBER (TU-IL); MARTIN KRAMMER, NADJA MARKO, MARTIN BENEDIKT, STEFAN THONHOFER, GEORG STETTINGER, MARKUS TRANNINGER (VIF); THIES FILLER (VW) REVIEWED: BRUNO LACABANNE (SIEMENS), JEAN-MARIE QUELIN (RENAULT), VALENTIN IVANOV (TUIL), JOSEF ZEHETNER (AVL), NADJA MARKO (VIF) APPROVED: LEONID LICHTENSTEIN (TWT), MARTIN BENEDIKT (VIF) D1.1 ACOSAR PROJECT ACRONYM: ACOSAR PROJECT TITLE: ADVANCED CO-SIMULATION OPEN SYSTEM ARCHITECTURE ITEA PROJECT N0: 14004 CHALLENGE: ENGINEERING PROJECT DURATION: 01/09/2015 - 31/08/2018 PROJECT WEBSITE: WWW.ACOSAR.EU COORDINATION: VIRTUAL VEHICLE RESEARCH CENTER (AT) PROJECT LEADER: DR. MARTIN BENEDIKT 14004 – Deliverable D1.1 – Distribution Level: Public 2 / 126 D1.1 ACOSAR 14004 – Deliverable D1.1 – Distribution Level: Public 3 / 126 D1.1 ACOSAR 1 Contents 1 Contents....................................................................................................................... -

Mikrodenetleyicili Endüstriyel Seri Protokol Çözümleyici Sisteminin Programi
YILDIZ TEKNİK ÜNİVERSİTESİ FEN BİLİMLERİ ENSTİTÜSÜ MİKRODENETLEYİCİLİ ENDÜSTRİYEL SERİ PROTOKOL ÇÖZÜMLEYİCİ SİSTEMİNİN PROGRAMI Elektronik ve Haberleşme Müh. Kemal GÜNSAY FBE Elektronik ve Haberleşme Anabilim Dalı Elektronik Programında Hazırlanan YÜKSEK LİSANS TEZİ Tez Danışmanı : Yrd. Doç. Dr. Tuncay UZUN (YTÜ) İSTANBUL, 2009 YILDIZ TEKNİK ÜNİVERSİTESİ FEN BİLİMLERİ ENSTİTÜSÜ MİKRODENETLEYİCİLİ ENDÜSTRİYEL SERİ PROTOKOL ÇÖZÜMLEYİCİ SİSTEMİNİN PROGRAMI Elektronik ve Haberleşme Müh. Kemal GÜNSAY FBE Elektronik ve Haberleşme Anabilim Dalı Elektronik Programında Hazırlanan YÜKSEK LİSANS TEZİ Tez Danışmanı : Yrd. Doç. Dr. Tuncay UZUN (YTÜ) İSTANBUL, 2009 İÇİNDEKİLER Sayfa KISALTMA LİSTESİ ................................................................................................................ v ŞEKİL LİSTESİ ...................................................................................................................... viii ÇİZELGE LİSTESİ .................................................................................................................... x ÖNSÖZ ...................................................................................................................................... xi ÖZET ........................................................................................................................................ xii ABSTRACT ............................................................................................................................ xiii 1. GİRİŞ ...................................................................................................................... -

Gigabit Ethernet - CH 3 - Ethernet, Fast Ethernet, and Gigabit Ethern
Switched, Fast, and Gigabit Ethernet - CH 3 - Ethernet, Fast Ethernet, and Gigabit Ethern.. Page 1 of 36 [Figures are not included in this sample chapter] Switched, Fast, and Gigabit Ethernet - 3 - Ethernet, Fast Ethernet, and Gigabit Ethernet Standards This chapter discusses the theory and standards of the three versions of Ethernet around today: regular 10Mbps Ethernet, 100Mbps Fast Ethernet, and 1000Mbps Gigabit Ethernet. The goal of this chapter is to educate you as a LAN manager or IT professional about essential differences between shared 10Mbps Ethernet and these newer technologies. This chapter focuses on aspects of Fast Ethernet and Gigabit Ethernet that are relevant to you and doesn’t get into too much technical detail. Read this chapter and the following two (Chapter 4, "Layer 2 Ethernet Switching," and Chapter 5, "VLANs and Layer 3 Switching") together. This chapter focuses on the different Ethernet MAC and PHY standards, as well as repeaters, also known as hubs. Chapter 4 examines Ethernet bridging, also known as Layer 2 switching. Chapter 5 discusses VLANs, some basics of routing, and Layer 3 switching. These three chapters serve as a precursor to the second half of this book, namely the hands-on implementation in Chapters 8 through 12. After you understand the key differences between yesterday’s shared Ethernet and today’s Switched, Fast, and Gigabit Ethernet, evaluating products and building a network with these products should be relatively straightforward. The chapter is split into seven sections: l "Ethernet and the OSI Reference Model" discusses the OSI Reference Model and how Ethernet relates to the physical (PHY) and Media Access Control (MAC) layers of the OSI model. -

Ethernet and Wifi
Ethernet and WiFi hp://xkcd.com/466/ CSCI 466: Networks • Keith Vertanen • Fall 2011 Overview • Mul?ple access networks – Ethernet • Long history • Dominant wired technology – 802.11 • Dominant wireless technology 2 Classic Ethernet • Ethernet – luminferous ether through which electromagne?c radiaon once thought to propagate – Carrier Sense, Mul?ple Access with Collision Detec?on (CSMA/CD) – IEEE 802.3 Robert Metcalfe, co- inventor of Ethernet 3 Classic Ethernet • Ethernet – Xerox Ethernet standardized as IEEE 802.3 in 1983 – Xerox not interested in commercializing – Metcalfe leaves and forms 3Com 4 Ethernet connec?vity • Shared medium – All hosts hear all traffic on cable – Hosts tapped the cable – 2500m maximum length – May include repeaters amplifying signal – 10 Mbps bandwidth 5 Classic Ethernet cabling Cable aSer being "vampire" tapped. Thick Ethernet cable (yellow), 10BASE-5 transceivers, cable tapping tool (orange), 500m maximum length. Thin Ethernet cable (10BASE2) with BNC T- connector, 185m maximum length. 6 Ethernet addressing • Media Access Control address (MAC) – 48-bit globally unique address • 281,474,976,710,656 possible addresses • Should last ?ll 2100 • e.g. 01:23:45:67:89:ab – Address of all 1's is broadcast • FF:FF:FF:FF:FF:FF 7 Ethernet frame format • Frame format – Manchester encoded – Preamble products 10-Mhz square wave • Allows clock synch between sender & receiver – Pad to at least 64-bytes (collision detec?on) Ethernet 802.3 AlternaWng 0's 48-bit MAC and 1's (except addresses SoF of 11) 8 Ethernet receivers • Hosts listens to medium – Deliver to host: • Any frame with host's MAC address • All broadcast frames (all 1's) • Mul?cast frames (if subscribed to) • Or all frames if in promiscuous mode 9 MAC sublayer • Media Access Control (MAC) sublayer – Who goes next on a shared medium – Ethernet hosts can sense if medium in use – Algorithm for sending data: 1. -

Gigabit Ethernet
Ethernet Technologies and Gigabit Ethernet Professor John Gorgone Ethernet8 Copyright 1998, John T. Gorgone, All Rights Reserved 1 Topics • Origins of Ethernet • Ethernet 10 MBS • Fast Ethernet 100 MBS • Gigabit Ethernet 1000 MBS • Comparison Tables • ATM VS Gigabit Ethernet •Ethernet8SummaryCopyright 1998, John T. Gorgone, All Rights Reserved 2 Origins • Original Idea sprang from Abramson’s Aloha Network--University of Hawaii • CSMA/CD Thesis Developed by Robert Metcalfe----(1972) • Experimental Ethernet developed at Xerox Palo Alto Research Center---1973 • Xerox’s Alto Computers -- First Ethernet Ethernet8systemsCopyright 1998, John T. Gorgone, All Rights Reserved 3 DIX STANDARD • Digital, Intel, and Xerox combined to developed the DIX Ethernet Standard • 1980 -- DIX Standard presented to the IEEE • 1980 -- IEEE creates the 802 committee to create acceptable Ethernet Standard Ethernet8 Copyright 1998, John T. Gorgone, All Rights Reserved 4 Ethernet Grows • Open Standard allows Hardware and Software Developers to create numerous products based on Ethernet • Large number of Vendors keeps Prices low and Quality High • Compatibility Problems Rare Ethernet8 Copyright 1998, John T. Gorgone, All Rights Reserved 5 What is Ethernet? • A standard for LANs • The standard covers two layers of the ISO model – Physical layer – Data link layer Ethernet8 Copyright 1998, John T. Gorgone, All Rights Reserved 6 What is Ethernet? • Transmission speed of 10 Mbps • Originally, only baseband • In 1986, broadband was introduced • Half duplex and full duplex technology • Bus topology Ethernet8 Copyright 1998, John T. Gorgone, All Rights Reserved 7 Components of Ethernet • Physical Medium • Medium Access Control • Ethernet Frame Ethernet8 Copyright 1998, John T. Gorgone, All Rights Reserved 8 CableCable DesignationsDesignations 10 BASE T SPEED TRANSMISSION MAX TYPE LENGTH Ethernet8 Copyright 1998, John T. -
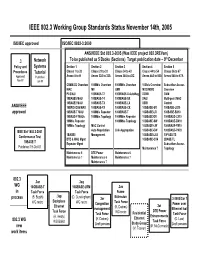
IEEE 802.3 Working Group Standards Status November 14Th, 2005
IEEE 802.3 Working Group Standards Status November 14th, 2005 ISO/IEC approved ISO/IEC 8802-3:2000 ANSI/IEEE Std 802.3-2005 (Was IEEE project 802.3REVam) th .3 Network To be published as 5 Books (Sections) Target publication date – 9 December Policy and Systems Section 1 Section 2 Section 3 Section 4 Section 5 Procedures Tutorial Clause 1 to 20 Clause 21 to 33 Clause 34 to 43 Clause 44 to 54 Clause 56 to 67 Approved Published Annex A to H Annex 22A to 32A Annex 36A to 43C Annex 44A to 50A Annex 58A to 67A Nov-97 Jun-95 CSMA/CD Overview 100Mb/s Overview 1000Mb/s Overview 10Gb/s Overview Subscriber Access MAC MII GMII MDC/MDIO Overview PLS/AUI 100BASE-T2 1000BASE-X AutoNeg XGMII OAM 10BASE5 MAU 100BASE-T4 1000BASE-SX XAUI Multi-point MAC 10BASE2 MAU 100BASE-TX 1000BASE-LX XSBI Control ANSI/IEEE 10BROAD36 MAU 100BASE-FX 1000BASE-CX 10GBASE-SR 100BASE-LX10 approved 10BASE-T MAU 100Mb/s Repeater 1000BASE-T 10GBASE-LR 100BASE-BX10 10BASE-F MAUs 100Mb/s Topology 1000Mb/s Repeater 10GBASE-ER 1000BASE-LX10 10Mb/s Repeater 1000Mb/s Topology 10GBASE-SW 1000BASE-BX10 10Mb/s Topology MAC Control 10GBASE-LW 1000BASE-PX10 IEEE Std 1802.3-2001 Auto Negotiation Link Aggregation 10GBASE-EW 1000BASE-PX20 Conformance Test 1BASE5 Management 10GBASE-LX4 10PASS-TS DTE & MAU Mgmt 10GBASE-CX4 2BASE-TL 10BASE-T Repeater Mgmt Subscriber Access Published 19-Oct-01 Maintenance 7 Topology Maintenance 6 DTE Power Maintenance 6 Maintenance 7 Maintenance 6 Maintenance 7 Maintenance 7 802.3 .3an .3aq WG 10GBASE-T 10GBASE-LRM .3as in Task Force Task Force Frame .3ap process (B. -

2.4/5 Ghz Dual-Band 1X1 Wi-Fi 5 (802.11Ac) and Bluetooth 5.2 Solution Rev
88W8987_SDS 2.4/5 GHz Dual-band 1x1 Wi-Fi 5 (802.11ac) and Bluetooth 5.2 Solution Rev. 2 — 21 May 2021 Product short data sheet 1 Product overview The 88W8987 is a highly integrated Wi-Fi (2.4/5 GHz) and Bluetooth single-chip solution, specifically designed to support the speed, reliability, and quality requirements of next generation Very High Throughput (VHT) products. The System-on-Chip (SoC) provides both simultaneous and independent operation of the following: • IEEE 802.11ac (Wave 2), 1x1 with data rates up to MCS9 (433 Mbit/s) • Bluetooth 5.2 (includes Bluetooth Low Energy (LE)) The SoC also provides: • Bluetooth Classic and Bluetooth LE dual (Smart Ready) operation • Wi-Fi indoor location positioning (802.11mc) For security, the device supports high performance 802.11i security standards through implementation of the Advanced Encryption Standard (AES)/Counter Mode CBC- MAC Protocol (CCMP), AES/Galois/Counter Mode Protocol (GCMP), Wired Equivalent Privacy (WEP) with Temporal Key Integrity Protocol (TKIP), AES/Cipher-Based Message Authentication Code (CMAC), and WLAN Authentication and Privacy Infrastructure (WAPI) security mechanisms. For video, voice, and multimedia applications, 802.11e Quality of Service (QoS) is supported. The device also supports 802.11h Dynamic Frequency Selection (DFS) for detecting radar pulses when operating in the 5 GHz range. Host interfaces include SDIO 3.0 and high-speed UART interfaces for connecting Wi-Fi and Bluetooth technologies to the host processor. The device is designed with two front-end configurations to accommodate Wi-Fi and Bluetooth on either separate or shared paths: • 2-antenna configuration—1x1 Wi-Fi and Bluetooth on separate paths (QFN) • 1-antenna configuration—1x1 Wi-Fi and Bluetooth on shared paths (eWLP) The following figures show the application diagrams for each package option. -

Fact Sheet: Single-Pair Ethernet Trade Article
Fact sheet Single Pair Ethernet Matthias Fritsche – product manager device connectivity & Jonas Diekmann – technical editor HARTING Technology group – October 2016– November 2016 Wireless technology and optical cable have already been often heralded as the future transmission technology. However, simple twisted pair cable based on plain old copper, often pronounced dead, is the most common transmission medium. Simple, robust, and perhaps with 100GBASE T1 soon to be also incredibly fast. From the beginnings of Ethernet in the 1970s, then via diverse multi-pair Ethernet developments with multiple parallel transmission paths, now apparently we are taking a step back. Back to single twisted-pair. With a new protocol and new PHYs transmission rates of up to 10 Gbit/s and PoDL capacities of up to 60 W are no longer a problem. Ultimately one pair is enough. When the team surrounding David Boggs and Robert Metcalf in the 1970s developed Ethernet at the Xerox Palo Alto Research Center (PARC), no one could foresee that this transmission method would develop so dynamically and dominate data transmission worldwide to this day. The original 10BASE5 Ethernet still used coax cable as the common medium. Today, next to wireless and optical cables, twisted-pair cable, often pronounced dead, is the most frequently used transmission medium. Starting in 1990 with 10BASE-T, the data transmission rate of the IEEE standards increased by a factor of 10 approximately every 5 years over 100BASE-TX and 1000BASE-T up to 10GBASE-T. This series could not be continued for the jump to 100GBASE-T, instead however four new IEEE standards were finalized in 2016. -

Ethernet Coax Transceiver Interface 1CY7B8392 Functional Description
CY7B8392 Ethernet Coax Transceiver Interface 1CY7B8392 Functional Description Features The CY7B8392 is a low power coaxial transceiver for Ethernet 10BASE5 and 10BASE2 applications. The device contains all • Compliant with IEEE802.3 10BASE5 and 10BASE2 the circuits required to perform transmit, receive, collision de- • Pin compatible with the popular 8392 tection, heartbeat generation, jabber timer and attachment • Internal squelch circuit to eliminate input noise unit interface (AUI) functions. In addition, the CY7B8392 fea- • Hybrid mode collision detect for extended distance tures an advanced hybrid collision detection. • Automatic AUI port isolation when coaxial connector is The transmitter output is connected directly to a double termi- not present nated 50Ω cable. • Low power BiCMOS design The CY7B8392 is fabricated with an advanced low power • 16-Pin DIP or 28-Pin PLCC BiCMOS process. Typical standby current during idle is 25 mA. Logic Block Diagram RX+ HIGH PASS AUI CCM EQUALIZATION DRIVER RX– RXI LOW PASS FILTER CD+ AUI GND – CARRIER DRIVER LOW PASS SENSE CD– FILTER + TX+ TX– – COLLISION CDS LOW PASS + RCV FILTER TXO WAVEFORM + DC/AC SHAPING SQUELCH – VEE 10 MHz CLK WATCHDOG JABBER RESET OSC TIMER26 ms TIMER0.4 sec RR+ REFERENCE 1K CIRCUIT TRANSMIT RECEIVE RR– STATE STATE MACHINE MACHINE HBE 8392–1 Pin Configurations PLCC DIP Top View Top View – RX+ CD CD+ CDS NC RXI TXO CD+ 1 16 CDS 432 1 28 2726 CD– 2 15 TXO VEE (NC) 5 25 VEE (NC) RX+ 3 14 RXI VEE (NC) 6 24 VEE V VEE 7 23 VEE (NC) EE 4 13 VEE 7B8392 7B8392 VEE 8 22 VEE (NC) VEE 5 12 RR– VEE (NC) 9 21 VEE RX– 6 11 RR+ VEE (NC) 10 20 VEE (NC) TX+ 7 10 GND VEE (NC) 11 121314 15 16 1718 RR– TX– 8 9 HBE – – TX+ TX RX 8392–3 RR+ HBE GND GND 8392–2 Cypress Semiconductor Corporation • 3901 North First Street • San Jose • CA 95134 • 408-943-2600 Document #: 38-02016 Rev. -

802.11 Arbitration
802.11 Arbitration White Paper September 2009 Version 1.00 Author: Marcus Burton, CWNE #78 CWNP, Inc. [email protected] Technical Reviewer: GT Hill, CWNE #21 [email protected] Copyright 2009 CWNP, Inc. www.cwnp.com Page 1 Table of Contents TABLE OF CONTENTS ............................................................................................................................... 2 EXECUTIVE SUMMARY ............................................................................................................................. 3 Approach / Intent ................................................................................................................................... 3 INTRODUCTION TO 802.11 CHANNEL ACCESS ................................................................................... 4 802.11 MAC CHANNEL ACCESS ARCHITECTURE ............................................................................... 5 Distributed Coordination Function (DCF) ............................................................................................. 5 Point Coordination Function (PCF) ...................................................................................................... 6 Hybrid Coordination Function (HCF) .................................................................................................... 6 Summary ................................................................................................................................................ 7 802.11 CHANNEL ACCESS MECHANISMS ........................................................................................... -

Module 4: Table of Contents
Data Communications(15CS46) 4th Sem CSE & ISE MODULE 4: TABLE OF CONTENTS INTRODUCTION RANDOM ACCESS PROTOCOL ALOHA Pure ALOHA Vulnerable time Throughput Slotted ALOHA Throughput CSMA Vulnerable Time Persistence Methods CSMA/CD Minimum Frame-size Procedure Energy Level Throughput CSMA/CA Frame Exchange Time Line Network Allocation Vector Collision During Handshaking Hidden-Station Problem CSMA/CA and Wireless Networks CONTROLLED ACCESS PROTOCOL Reservation Polling Token Passing Logical Ring CHANNELIZATION FDMA TDMA CDMA Implementation Chips Data Representation Encoding and Decoding Sequence Generation ETHERNET PROTOCOL IEEE Project 802 Ethernet Evolution STANDARD ETHERNET Characteristics Connectionless and Unreliable Service Frame Format Frame Length Addressing Access Method Efficiency of Standard Ethernet Implementation Encoding and Decoding Changes in the Standard Bridged Ethernet Dept. of ISE,CITECH 1 Data Communications(15CS46) 4th Sem CSE & ISE Switched Ethernet Full-Duplex Ethernet FAST ETHERNET (100 MBPS) Access Method Physical Layer Topology Implementation Encoding GIGABIT ETHERNET MAC Sublayer Physical Layer Topology Implementation Encoding TEN GIGABIT ETHERNET Implementation INTRODUCTION OF WIRELESS-LANS Architectural Comparison Characteristics Access Control IEEE 802.11 PROJECT Architecture BSS ESS Station Types MAC Sublayer DCF Network Allocation Vector Collision During Handshaking PCF Fragmentation Frame Types Frame Format Addressing Mechanism Exposed Station Problem Physical Layer IEEE 802.11 FHSS IEEE 802.11 DSSS IEEE 802.11 Infrared IEEE 802.11a OFDM IEEE 802.11b DSSS IEEE 802.11g BLUETOOTH Architecture Piconets Scatternet Bluetooth Devices Bluetooth Layers Radio Layer Baseband Layer TDMA Links Frame Types Frame Format L2CAP Dept. of ISE,CITECH 2 Data Communications(15CS46) 4th Sem CSE & ISE MODULE 4: MULTIPLE ACCESS 4.1 Introduction When nodes use shared-medium, we need multiple-access protocol to coordinate access to medium. -

Modern Ethernet
Color profile: Generic CMYK printer profile Composite Default screen All-In-One / Network+ Certification All-in-One Exam Guide / Meyers / 225345-2 / Chapter 6 CHAPTER Modern Ethernet 6 The Network+ Certification exam expects you to know how to • 1.2 Specify the main features of 802.2 (Logical Link Control) [and] 802.3 (Ethernet): speed, access method, topology, media • 1.3 Specify the characteristics (for example: speed, length, topology, and cable type) of the following cable standards: 10BaseT and 10BaseFL; 100BaseTX and 100BaseFX; 1000BaseTX, 1000BaseCX, 1000BaseSX, and 1000BaseLX; 10GBaseSR, 10GBaseLR, and 10GBaseER • 1.4 Recognize the following media connectors and describe their uses: RJ-11, RJ-45, F-type, ST,SC, IEEE 1394, LC, MTRJ • 1.6 Identify the purposes, features, and functions of the following network components: hubs, switches • 2.3 Identify the OSI layers at which the following network components operate: hubs, switches To achieve these goals, you must be able to • Define the characteristics, cabling, and connectors used in 10BaseT and 10BaseFL • Explain how to connect multiple Ethernet segments • Define the characteristics, cabling, and connectors used with 100Base and Gigabit Ethernet Historical/Conceptual The first generation of Ethernet network technologies enjoyed substantial adoption in the networking world, but their bus topology continued to be their Achilles’ heel—a sin- gle break anywhere on the bus completely shut down an entire network. In the mid- 1980s, IBM unveiled a competing network technology called Token Ring. You’ll get the complete discussion of Token Ring in the next chapter, but it’s enough for now to say that Token Ring used a physical star topology.