A Cloud-Based Robust Semaphore Mirroring System for Social Robots
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Many Faced Robot - Design and Manufacturing of a Parametric, Modular and Open Source Robot Head
Many Faced Robot - Design and Manufacturing of a Parametric, Modular and Open Source Robot Head Metodi Netzev1, Quentin Houbre1, Eetu Airaksinen1, Alexandre Angleraud1 and Roel Pieters1 Abstract— Robots developed for social interaction and care show great promise as a tool to assist people. While the functionality and capability of such robots is crucial in their acceptance, the visual appearance should not be underesti- mated. Current designs of social robots typically can not be altered and remain the same throughout the life-cycle of the robot. Moreover, customization to different end-users is rarely taken into account and often alterations are strictly prohibited due to the closed-source designs of the manufacturer. The current trend of low-cost manufacturing (3D printing) and open-source technology, however, open up new opportunities for third parties to be involved in the design process. In this work, we propose a development platform based on FreeCAD that offers a parametric, modular and open-source design tool specifically aimed at robot heads. Designs can be generated by altering different features in the tool, which automatically Fig. 1. Different end-users of social robots require different features and design. The designs shown here are generated by the parametric and modular reconfigures the head. In addition, we present several design development platform, proposed in this work. Left design shows a robot approaches that can be integrated in the design to achieve head with wooden facial covering. Right design shows a robot head with different functionalities (face and skin aesthetics, component more humanoid characteristics. Both designs can be generated by changing assembly), while still relying on 3D printing technology. -

Robot Umanoidi E Tecniche Di Interazione Naturale Per Servizi Di Accoglienza Ed Informazioni
POLITECNICO DI TORINO Corso di Laurea Magistrale in Ingegneria Informatica Tesi di Laurea Magistrale Robot umanoidi e tecniche di interazione naturale per servizi di accoglienza ed informazioni Relatori Prof. Fabrizio Lamberti Ing. Federica Bazzano Candidato Simon Dario Mezzomo Dicembre 2017 Quest’opera è stata rilasciata con licenza Creative Commons Attribuzione - Non commerciale - Non opere derivate 4.0 Internazionale. Per leggere una copia della licenza visita il sito web http://creativecommons.org/licenses/by-nc-nd/4.0/ o spedisci una lettera a Creative Commons, PO Box 1866, Mountain View, CA 94042, USA. Ringraziamenti Grazie a tutti quelli che mi sono stati vicino durante questo lungo percorso che mi ha portato al tanto atteso traguardo della laurea. A tutta la famiglia che mi ha sempre sostenuto anche nei momenti più difficili. Agli amici di casa e di università Andrea, Hervé, Jacopo, Maurizio, Didier, Marco, Matteo, Luca, Thomas, Nicola, Simone che hanno condiviso numerose esperienze. A tutti i colleghi di lavoro Edoardo, Francesco, Emanuele, Gianluca, Gabriele, Nicolas, Rebecca, Chiara, Allegra. E a tutti quelli di cui mi sarò sicuramente scordato. iii Sommario L’obiettivo di questo lavoro di tesi è quello di esplorare l’uso di robot umanoidi nel- l’ambito della robotica di servizio per applicazioni che possono essere utili all’uomo e di analizzarne l’effettiva utilità. In particolare, è stata analizzata l’interazione con un robot umanoide (generalmente chiamato receptionist) che accoglie gli utenti e fornisce loro, su richiesta, delle indicazioni per raggiungere il luogo in cui questi si vogliono recare. L’innovazione rispetto allo stato dell’arte in materia consiste nell’integrare le in- dicazioni vocali fornite all’utente con delle indicazioni che mostrano il percorso da seguire su una mappa posta di fronte al robot. -

The Dialectics of Virtuosity: Dance in the People's Republic of China
The Dialectics of Virtuosity: Dance in the People’s Republic of China, 1949-2009 by Emily Elissa Wilcox A dissertation submitted in partial satisfaction of the requirements for the degree of Joint Doctor of Philosophy with the University of California, San Francisco in Medical Anthropology of the University of California, Berkeley Committee in charge: Professor Xin Liu, Chair Professor Vincanne Adams Professor Alexei Yurchak Professor Michael Nylan Professor Shannon Jackson Spring 2011 Abstract The Dialectics of Virtuosity: Dance in the People’s Republic of China, 1949-2009 by Emily Elissa Wilcox Joint Doctor of Philosophy with the University of California, San Francisco in Medical Anthropology University of California, Berkeley Professor Xin Liu, Chair Under state socialism in the People’s Republic of China, dancers’ bodies became important sites for the ongoing negotiation of two paradoxes at the heart of the socialist project, both in China and globally. The first is the valorization of physical labor as a path to positive social reform and personal enlightenment. The second is a dialectical approach to epistemology, in which world-knowing is connected to world-making. In both cases, dancers in China found themselves, their bodies, and their work at the center of conflicting ideals, often in which the state upheld, through its policies and standards, what seemed to be conflicting points of view and directions of action. Since they occupy the unusual position of being cultural workers who labor with their bodies, dancers were successively the heroes and the victims in an ever unresolved national debate over the value of mental versus physical labor. -

Assistive Humanoid Robot MARKO: Development of the Neck Mechanism
MATEC Web of Conferences 121, 08005 (2017) DOI: 10.1051/ matecconf/201712108005 MSE 2017 Assistive humanoid robot MARKO: development of the neck mechanism Marko Penčić1,*, Maja Čavić1, Srđan Savić1, Milan Rackov1, Branislav Borovac1, and Zhenli Lu2 1Faculty of Technical Sciences, University of Novi Sad, TrgDositejaObradovića 6, 21000 Novi Sad, Serbia 2School of Electrical Engineering and Automation, Changshu Institute of Technology, Hushan Road 99, 215500 Changshu, People's Republic of China Abstract.The paper presents the development of neck mechanism for humanoid robots. The research was conducted within the project which is developing a humanoid robot Marko that represents assistive apparatus in the physical therapy for children with cerebral palsy.There are two basic ways for the neck realization of the robots. The first is based on low backlash mechanisms that have high stiffness and the second one based on the viscoelastic elements having variable flexibility. We suggest low backlash differential gear mechanism that requires small actuators. Based on the kinematic-dynamic requirements a dynamic model of the robots upper body is formed. Dynamic simulation for several positions of the robot was performed and the driving torques of neck mechanism are determined.Realized neck has 2 DOFs and enables movements in the direction of flexion-extension 100°, rotation ±90° and the combination of these two movements. It consists of a differential mechanism with three spiral bevel gears of which the two are driving and are identical, and the third one which is driven gear to which the robot head is attached. Power transmission and motion from the actuators to the input links of the differential mechanism is realized with two parallel placed gear mechanisms that are identical.Neck mechanism has high carrying capacity and reliability, high efficiency, low backlash that provide high positioning accuracy and repeatability of movements, compact design and small mass and dimensions. -

Animation and Machines: Designing Expressive Robot-Human Interactions Ⅰ
http://dx.doi.org/10.7230/KOSCAS.2017.49.677 Animation and Machines: designing expressive robot-human interactions Ⅰ. Introduction Ⅱ. Expanded animation Ⅲ. Animation and ubiquitous computing Ⅳ. Social Robots: a survey of the state of the art Ⅴ. Cartoons, animators and robots Ⅵ. Conclusion References 국문초록 Joao Paulo Amaral Schlittler ABSTRACT Cartoons and consequently animation are an effective way of visualizing futuristic scenarios. Here we look at how animation is becoming ubiquitous and an integral part of this future today: the cybernetic and mediated society that we are being transformed into. Animation therefore becomes a form of speech between humans and this networked reality, either as an interface or as representation that gives temporal form to objects. Animation or specifically animated films usually are associated with character based short and feature films, fiction or nonfiction. However animation is not constricted to traditional cinematic formats and language, the same way that design and communication have become treated as separate fields, however according to Vilém Flusser they aren’t. The same premise can be applied to animation in a networked culture: Animation has become an intrinsic to design processes and products - as in motion graphics, interface design and three-dimensional visualization. Video-games, virtual reality, map based apps and social networks constitute layers of an expanded universe that embodies our network based culture. They are products of design and media disciplines that are increasingly relying on animation as a universal language suited to multi-cultural interactions carried in digital ambients. In this sense animation becomes a discourse, the same way as Roland Barthes describes myth as a type of speech. -
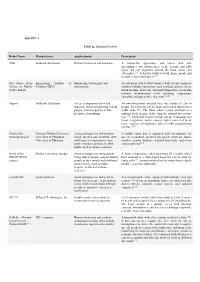
Humanoid Robots Robot Name Manufacturer
Appendix A Table 1.Humanoid robots Robot Name Manufacturer Application(s) Description NAO Softbank-Aldebaran Human interaction and assistance A human-like appearance and comes with four microphones, two loudspeakers, tactile sensors, and LED lights that are dispersed around the head, torso, and extremities [47]. It has the ability to walk, dance, speak, and recognize faces and objects [47]. RIA (Robo Idoso Engineering Institute of Monitoring vital signals and An extension of NAO that equips it with several sensors to Activo, or Elderly Coimbra (ISEC) environment monitor multiple parameters, such as blood glucose levels, Active Robot) blood pressure, heart rate, and body temperature. It can also monitor environmental levels including temperature, humidity, and gas and fire detection [6,33] Pepper Softbank-Aldebaran Act as a companion, assist and An omnidirectional wheeled base that stands at 1.2m in supervise independent-living elderly height. The robot has a head, arms, and a torso attached to a people, promote quality of life, stable body [48]. The three wheel system attached to a facilitate relationships uniform body is more stable than the normal two robotic legs [31]. Additional features include advanced language and facial recognition, tactile sensors, tablet connected to its torso, cameras, microphones, and a flexible programming interface [31] Pearl of the Carnegie Mellon University, Assist and supervise independent- A mobile robot that is equipped with microphones for Nursebot project University of Pittsburgh, living elderly people and those with speech recognition, speakers for speech synthesis, touch- University of Michigan mild cognitive impairment, issue sensitive graphic displays, actuated head units, and stereo daily reminders, promote healthy camera systems [14]. -

Evaluating the Co-Dependence and Co-Existence Between Religion and Robots: Past, Present and Insights on the Future
International Journal of Social Robotics https://doi.org/10.1007/s12369-020-00636-x Evaluating the Co-dependence and Co-existence between Religion and Robots: Past, Present and Insights on the Future Habib Ahmed1 · Hung Manh La1 Accepted: 19 February 2020 © Springer Nature B.V. 2020 Abstract The relationship between religions and science can be considered historically controversial in nature. In constantly evolving global societies, it is important to provide a new perspective on the past and present relationship between religions and technological developments in the different societies. In this regard, this paper will provide insights into the different ways in which ancient societies and their religious traditions helped in the development of technological progress. At one end, it will highlight some of the positive contributions of different religions towards technological progress in the past. At the other end, this discussion will aid in dispelling the viewpoint that perceived the ancient cultures and societies as bereft of technological knowledge and innovation. This paper will provide a historical perspective on the development of relationship between religion and robotics in the past. A brief look at the existing scenario within the contemporary societies will also be examined, along with discussion of socio-cultural norms and values related to perception of robots in different Eastern and Western cultures. The discussion will conclude with some predictions regarding the future, along with the different ways in which the relationship of co-existence and co-dependence is expected to evolve between religion and robotics in the future, which goes beyond the predictions of mass annihilation and mass enslavement by sentient AI-based robots. -
Displays of Emotions Reduce the Uncanniness of Humanlike Robots
Overcoming the Uncanny Valley: Displays of Emotions Reduce the Uncanniness of Humanlike Robots Miriam Koschate∗, Richard Potter∗, Paul Bremnery and Mark Levine∗ ∗Department of Psychology University of Exeter, Exeter, EX4 4QG, U.K. Email: [email protected], [email protected] yBristol Robotics Lab University of the West of England, Bristol, BS16 1QY, U.K. Email: [email protected] Abstract—In this paper we show empirically that highly humanlike robots make thoughts of death more accessible, leading to perceptions of uncanniness and eeriness of such robots. Rather than reducing the humanlikeness of robots, our research suggests the addition of emotion displays to decrease a sense of uncanniness. We show that a highly humanlike robot displaying emotions in a social context reduces death-thought accessibility (DTA), which in turn reduces uncanniness. In a pre-test with N = 95 participants, we established that not all humanoid robots elicit thoughts of death and that the extent to which a robot appears humanlike may be linked to DTA. In our Main Study, N = 44 participants briefly interacted with a highly humanlike robotic head that either showed appropriate basic emotions or reacted by blinking. The display of emotions significantly reduced perceptions of uncanniness, which was mediated by a corresponding reduction in DTA. Implications for the design of humanoid robots are proposed. Keywords—humanoid robot; uncanny valley; emotion display; death-thought accessibility (DTA) Fig. 1. The uncanny valley by Mori (1970) I. INTRODUCTION assumptions [3]. In recent years, researchers have suggested uncanny valley The has haunted humanoid robot design for a number of reasons why humanlike robots create a sense of several decades since Mori proposed the relationship between 1 eeriness and uncanniness. -

Materials of Imagination on the Limits and the Potentials of the Humanoid Robot
Materials of Imagination On the Limits and the Potentials of the Humanoid Robot Asli Kemiksiz† Osaka University Abstract Before developing into a category of technologies, the robot was an imagined figure in science fiction (SF). The gap between imaginary robots and their real-life counterparts creates a distinctive opportunity to examine how science fiction is embedded in technoscience and vice versa. This paper explores how materials of imagination––facts, fictions, beliefs, rationales, aesthetics, norms, etc.––shape emerging Japanese humanoid robots. Using Donna Haraway’s image of string figures to consider the intimate relations between SF, technoscience and science studies, I also identify and break down some powerful, conventional imaginaries—ranging from the companion robots to the Laws of Robotics—in order to elucidate how the Japanese humanoid robot came to be what it is. I end by arguing that science fiction thought experiments provide materials of imagination with potentials for opening up current robotics to imaginaries beyond current experimental systems. Introduction The word “robot” refers to multiple, entangled entities. Originally, it was an artificial laborer in the play Rossum’s Universal Robots ([1920] 2014) by Karel Čapek. It evolved into a science fiction figure, often depicted as a machine with various humanlike traits. Soon, real-life machines also dubbed robots appeared,1 and while they did not exactly live up to their fictional counterparts, they did open the way to the techno-scientific discipline called robotics. Today, the robot has come to refer to a category of machines that are mostly programmable and have † [email protected] 1 An American company named Westinghouse produced a telephone answering machine called “Televox” in 1927. -

Le Féminin Manufacturé Dans Blade Runner Et Ex Machina : La Figure De La Gynoïde Comme Cristallisation De La Condition Féminine Camille Piriou
Le féminin manufacturé dans Blade Runner et Ex Machina : la figure de la gynoïde comme cristallisation de la condition féminine Camille Piriou To cite this version: Camille Piriou. Le féminin manufacturé dans Blade Runner et Ex Machina : la figure de la gynoïde comme cristallisation de la condition féminine. Art et histoire de l’art. 2018. dumas-01877235 HAL Id: dumas-01877235 https://dumas.ccsd.cnrs.fr/dumas-01877235 Submitted on 19 Sep 2018 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. Université Paris 1 Panthéon - Sorbonne Diplôme national de master Année Universitaire 2017-2018 LE FÉMININ MANUFACTURÉ DANS BLADE RUNNER ET EX MACHINA: LA FIGURE DE LA GYNOÏDE COMME CRISTALLISATION DE LA CONDITION FÉMININE Camille Piriou Sous la direction de Vincent Amiel UFR 04 - Arts Plastiques et Science de l’Art Mémoire de Master 2 Mention: Cinéma et Audiovisuel Parcours: Recherche Table des Matières Introduction 1 I. La gynoïde comme objet narratif subordonné 13 1. La créature pour le créateur 13 a) Une autre à travers laquelle se chercher soi-même: la gynoïde comme miroir 13 b) La gynoïde et le désir immortel 16 c) Subordonner le naturel, subordonner le féminin 19 2. -

A Review Study of the 3-D Printing Techniques Utilized in Developing Humanoid Robot
© 2018 JETIR December 2018, Volume 5, Issue 12 www.jetir.org (ISSN-2349-5162) A Review Study of the 3-D Printing Techniques utilized in Developing Humanoid Robot Priyanka Grover Arora1*, Varsha Yadav2, Sandeep Singh2 1Assistant Professor, Department of Electronics and Communication Engineering, Lovely Professional University, Punjab 2Research Scholar, Department of Mechanical Engineering, Lovely Professional University, Punjab. Abstract Research in the field of 3-D printing in humanoid robot is trending. Ranging from the designing of the structure of the robot, stability of the structure, material to be used, actuators, sensors, machine learning and artificial intelligence, machine vision, etc.In this review paper the role of 3-D printing in the Humanoid robots is discussed. Humanoid robot is a multidisciplinary platform combining electromechanical systems and artificial intelligence. Morphology in biped locomotion is a great challenge which is being worked by researchers. Varying from kid-size to adult size various research groups are working. Also a concept called soft skin for humanoid robots is being developed using 3-D printing with many-materials.Many robotic platforms don’t give access to all research groups to use to proceed with that so that also becomes a great challenge.Humanoid robots are being used in various fields like domestic, medical, industries, etc. Reducing the number of actuators is also of a great significance.The concept of variable hyper-redundant robotic arm also came into existence using some materials.Humanoid robots are being developed for the interaction of them with the humans and the environment which should be safe. I. Introduction Humanoid robots evolution occur really fast. -

The Evolution of Japanese Robotics: from the Beginning to the Newest Tendencies
THE EVOLUTION OF JAPANESE ROBOTICS: FROM THE BEGINNING TO THE NEWEST TENDENCIES Víctor Manuel Àlvarez Sanz Tutor: Gemma Garcia Brosa Bachelor’s degree in International Business TFG 2nd semester ii Abstract This study will go through the robotics sector of Japan. It will show when the robots in concept arrived in Japan and its evolution through history and the rise of it as a robotics superpower, with historical and economic data. It will also discuss the presence of robots in cultural aspects of Japan and the reasons of the good relationship between Japanese citizens and their creations. By the ending, the worrisome future scheme for Japan will be shown and the response of Japan’s government as well as its companies to counteract this situation with the usage of robots. Key words robotics, Japan, Japanese history, Japanese culture, future, humanoid robots, aging population, robotic market, research & development, exports Resum Aquest treball estarà enfocat en el sector de la robòtica al Japó. Es mostrarà quan el concepte de robot va arribar al Japó i la seva evolució durant la historia, amb dades històriques i econòmiques. També es parlarà de la presència dels robots en el àmbit cultural japonès i les raons de la acceptació entre japonesos i les seves creacions. Per finalitzar es tractarà del seu preocupant futur en termes de població i com s’encararà aquest problema per part del govern japonès i de les seves empreses amb la utilització de robots. Paraules clau robòtica, Japó, historia japonesa, cultura japonesa, futur, robots humanoides, població envellida, mercat robòtic, recerca i desenvolupament, exportacions iii Table of Contents I.