Tablanet: a Real-Time Online Musical Collaboration System for Indian
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

MODAL ANALYSIS and TRANSCRIPTION of STROKES of the MRIDANGAM USING NON-NEGATIVE MATRIX FACTORIZATION Akshay Anantapadmanabhan1, Ashwin Bellur2 and Hema a Murthy1 ∗
MODAL ANALYSIS AND TRANSCRIPTION OF STROKES OF THE MRIDANGAM USING NON-NEGATIVE MATRIX FACTORIZATION Akshay Anantapadmanabhan1, Ashwin Bellur2 and Hema A Murthy1 ∗ 1 Department of Computer Science and Engineering, 2 Department of Electrical Engineering, Indian Institute of Technology, Madras, India - 600 036 ABSTRACT The mridangam is quite different from the tabla in that, the mridangam is a single body instrument with two membranes In this paper we use a Non-negative Matrix Factorization (one producing treble sounds while the other producing bass (NMF) based approach to analyze the strokes of the mri- sounds) as opposed to the tabla, which consists of two inde- dangam, a South Indian hand drum, in terms of the normal pendent bodies. C.V. Raman, in his work on Indian musical modes of the instrument. Using NMF, a dictionary of spectral drums [1], discusses some of the unique traits of the mridan- basis vectors are first created for each of the modes of the gam as a harmonic percussive instrument. He describes some mridangam. The composition of the strokes are then studied of the structural similarities between the mridangam and tabla by projecting them along the direction of the modes using but at the same time highlights some of the major differences NMF. We then extend this knowledge of each stroke in terms in their acoustic properties. He also illustrates the modes of of its basic modes to transcribe audio recordings. Hidden the mridangam using sand figures to reveal the basic physical Markov Models are adopted to learn the modal activations for and acoustic characteristics of the instrument. -

The Percussion Family 1 Table of Contents
THE CLEVELAND ORCHESTRA WHAT IS AN ORCHESTRA? Student Learning Lab for The Percussion Family 1 Table of Contents PART 1: Let’s Meet the Percussion Family ...................... 3 PART 2: Let’s Listen to Nagoya Marimbas ...................... 6 PART 3: Music Learning Lab ................................................ 8 2 PART 1: Let’s Meet the Percussion Family An orchestra consists of musicians organized by instrument “family” groups. The four instrument families are: strings, woodwinds, brass and percussion. Today we are going to explore the percussion family. Get your tapping fingers and toes ready! The percussion family includes all of the instruments that are “struck” in some way. We have no official records of when humans first used percussion instruments, but from ancient times, drums have been used for tribal dances and for communications of all kinds. Today, there are more instruments in the percussion family than in any other. They can be grouped into two types: 1. Percussion instruments that make just one pitch. These include: Snare drum, bass drum, cymbals, tambourine, triangle, wood block, gong, maracas and castanets Triangle Castanets Tambourine Snare Drum Wood Block Gong Maracas Bass Drum Cymbals 3 2. Percussion instruments that play different pitches, even a melody. These include: Kettle drums (also called timpani), the xylophone (and marimba), orchestra bells, the celesta and the piano Piano Celesta Orchestra Bells Xylophone Kettle Drum How percussion instruments work There are several ways to get a percussion instrument to make a sound. You can strike some percussion instruments with a stick or mallet (snare drum, bass drum, kettle drum, triangle, xylophone); or with your hand (tambourine). -

Detecting Tāla Computationally in Polyphonic Context-A Novel Approach Susmita Bhaduri*, Anirban Bhaduri and Dipak Ghosh
Research Article iMedPub Journals American Journal of Computer Science and Information 2018 http://www.imedpub.com/ Vol.6 No.3:30 Technology DOI: 10.21767/2349-3917.100030 ISSN 2349-3917 Detecting tāla Computationally in Polyphonic Context-A Novel Approach Susmita Bhaduri*, Anirban Bhaduri and Dipak Ghosh, Deepa Ghosh Research Foundation, Maharaja Tagore Road, India *Corresponding author: Susmita Bhaduri, Deepa Ghosh Research Foundation, Maharaja Tagore Road, India, Tel: 919836132200; E-mail: [email protected] Received Date: October 01, 2018; Accepted Date: October 04, 2018 Published Date: October 29, 2018 Citation: Bhaduri S, Bhaduri A, Ghosh D (2018) Detecting tāla Computationally in Polyphonic Context-A Novel Approach. Am J Compt Sci Inform Technol Vol.6 No.3: 30 Copyright: ©2018 Bhaduri S, et al. This is an open-access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original author and source are credited. framework. We should consider a knowledge-based approach to create the computational model for NIMS rhythm. Tools Abstract developed for rhythm analysis can be useful in a lot of applications such as intelligent music archival, enhanced In North-Indian-Music-System (NIMS), tablā is mostly used navigation through music collections, content based music as percussive accompaniment for vocal-music in retrieval, for an enriched and informed appreciation of the polyphonic-compositions. The human auditory system uses subtleties of music and for pedagogy. Most of these applications perceptual grouping of musical-elements and easily filters the tablā component, thereby decoding prominent deal with music compositions of polyphonic kind in the context rhythmic features like tāla, tempo from a polyphonic- of blending of various signals arising from different sources. -

Maestro Plays Traditional Tabla
PERFORMAN CE Maestro plays traditional tabla By Arthur Dudney Hu s!ain wi ll be a visiting PlI.IH(:ETOHJAH STA" W RITER faculty member in the music departmen t next se mester, The instrument W: simple tt!aching a -e:ouue titled "in - a large drum and a small troduction to the Music of in drum. played with the fingers dia," which he designed with and palm. But Zaki r Hu ssain mathematics professor and plays the traditional Indian tabla enthusiast Manjul Bh ar instrument, the tabla, with gava. such subtlety that there see ms The appointment is funded to be more to it. by theCounci! of the Humani Nearly 300 community ties. members attended his recital Hussain brgan to study tab Thursday aft ernoon tohear th e la seriously .a t age sev('n with man internationally re nowned hi s father, and the two began for hi s fusion of classica l in touring together when Zakir dian and Western music. Su TABLA pagt4 )RINCETONIAN Friday APRIL 8, 200S Hussain discusses tabla history TABLA of his many appearances at the to work with hi s colleagues in Un iversity since 1974 - began the music department, espe Co nfinutd from pa,9t I with five minutes of virtuos cially those involved in elec ity demonstrating the instru tronic music. was 12. Hi s fa ther, Ali a Rakha, ment's range. He then intro "Princeton is a respected was wide ly considered one of duced himse lf: "My n.ame is education center and I'm look the greates t tabla players of all Zakir Hu ssain and 1 play this ing at this not as something to time. -

Guru Nanak Dev University Amritsar
FACULTY OF VISUAL ARTS & PERFORMING ARTS SYLLABUS FOR BACHELOR OF PERFORMING ARTS (Four Years Degree Course) (PART – IV) Examination: 2015 GURU NANAK DEV UNIVERSITY AMRITSAR Note: (i) Copy rights are reserved. Nobody is allowed to print it in any form. Defaulters will be prosecuted. (ii) Subject to change in the syllabi at any time. Please visit the University website time to time. 1 (FOUR YEARS DEGREE COURSE) BACHELOR OF PERFORMING ARTS IN MUSIC VOCAL FOURTH YEAR Sr. Course Theory/ External Internal Total Timings Total Time No. Practical 1 Applied Theory 100 - 100 3 hrs. 125 hrs. 2 General Theory Theory 100 - 100 3 hrs. 125 hrs. 3 Practical – - - 50 50 - 50 hrs. Internal Assessment (Studio) 4 Practical Practical 350 50 400 600 hrs. Paper A 100 - (Choice from Ragas) Paper B 50 - (other Gayan Shailies) Paper C 100 - (Talas on Tabla & hand) Paper D 100 - (Viva) Total: 350 550 100 650 900 hrs. Paper-IV: Practical (350+50) = 400 Marks 2 (FOUR YEARS DEGREE COURSE) Bachelor of Performing Arts (Music Vocal) Fourth Year Paper-I Applied Theory: 100 Marks Description of 12 selected ragas and talas and their comparative study when ever possible. Miya-Malhar, Darkari–Kanada, Basant, Madhuwanti, Ahir Bhairav, Bilaskhani, Todi, Lalit, Puria, Marva, Maaru Bihag, Shudsarang, Megha, Natt Bhairav. Reading and writing of notations- compositions-alaap, taan. etc. One, Dhrupad, One thumari, one Bhajan, one Ghazal, one Dadra. Reading and writing of Lyakaries of prescribed talas. Taals-Savari, Punjabi, Adha, Pashto, Chachar, Layakaries3/4,4/3. History of Music of Modern period from 1857 to present day. -

Virtual Musical Field Trip with Maestro Andrew Crust
YOUR PASSPORT TO A VIRTUAL MUSICAL FIELD TRIP WITH MAESTRO ANDREW CRUST Premier Education Partner Za The Conductor Today, you met Andrew Crust, the Vancouver Symphony Orchestra’s Assistant Conductor. He joined the VSO this season in September of 2019. He grew up in Kansas City, and his main instrument is the trumpet. He studied music education and conducting, and has worked with orchestras in Canada, the United States, Italy, Germany, the Czech Republic, Chile, and many other exotic places. The conductor keeps the orchestra in time and together. The conductor serves as a messenger for the composer. It is their responsibility to understand the music and convey it through movements so clearly that the musicians in the orchestra understand it perfectly. Those musicians can then send a unified vision of the music out to the audience. Conductors usually beat time with their right hand. This leaves their left hand free to show the various instruments when they have entries (when they start playing) or to show them to play louder or softer. Most conductors have a stick called a “baton”. It makes it easier for people at the back of large orchestras or choirs to see the beat. Other conductors prefer not to use a baton. A conductor stands on a small platform called a “rostrum”. To be a good conductor is not easy. It is not just a question of giving a steady beat. A good conductor has to know the music extremely well so that they can hear any wrong notes. They need to be able to imagine exactly the sound they want the orchestra to make. -
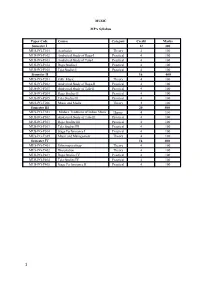
MUSIC MPA Syllabus Paper Code Course Category Credit Marks
MUSIC MPA Syllabus Paper Code Course Category Credit Marks Semester I 12 300 MUS-PG-T101 Aesthetics Theory 4 100 MUS-PG-P102 Analytical Study of Raga-I Practical 4 100 MUS-PG-P103 Analytical Study of Tala-I Practical 4 100 MUS-PG-P104 Raga Studies I Practical 4 100 MUS-PG-P105 Tala Studies I Practical 4 100 Semester II 16 400 MUS-PG-T201 Folk Music Theory 4 100 MUS-PG-P202 Analytical Study of Raga-II Practical 4 100 MUS-PG-P203 Analytical Study of Tala-II Practical 4 100 MUS-PG-P204 Raga Studies II Practical 4 100 MUS-PG-P205 Tala Studies II Practical 4 100 MUS-PG-T206 Music and Media Theory 4 100 Semester III 20 500 MUS-PG-T301 Modern Traditions of Indian Music Theory 4 100 MUS-PG-P302 Analytical Study of Tala-III Practical 4 100 MUS-PG-P303 Raga Studies III Practical 4 100 MUS-PG-P303 Tala Studies III Practical 4 100 MUS-PG-P304 Stage Performance I Practical 4 100 MUS-PG-T305 Music and Management Theory 4 100 Semester IV 16 400 MUS-PG-T401 Ethnomusicology Theory 4 100 MUS-PG-T402 Dissertation Theory 4 100 MUS-PG-P403 Raga Studies IV Practical 4 100 MUS-PG-P404 Tala Studies IV Practical 4 100 MUS-PG-P405 Stage Performance II Practical 4 100 1 Semester I MUS-PG-CT101:- Aesthetic Course Detail- The course will primarily provide an overview of music and allied issues like Aesthetics. The discussions will range from Rasa and its varieties [According to Bharat, Abhinavagupta, and others], thoughts of Rabindranath Tagore and Abanindranath Tagore on music to aesthetics and general comparative. -

Musical Explorers Is Made Available to a Nationwide Audience Through Carnegie Hall’S Weill Music Institute
Weill Music Institute Teacher Musical Guide Explorers My City, My Song A Program of the Weill Music Institute at Carnegie Hall for Students in Grades K–2 2016 | 2017 Weill Music Institute Teacher Musical Guide Explorers My City, My Song A Program of the Weill Music Institute at Carnegie Hall for Students in Grades K–2 2016 | 2017 WEILL MUSIC INSTITUTE Joanna Massey, Director, School Programs Amy Mereson, Assistant Director, Elementary School Programs Rigdzin Pema Collins, Coordinator, Elementary School Programs Tom Werring, Administrative Assistant, School Programs ADDITIONAL CONTRIBUTERS Michael Daves Qian Yi Alsarah Nahid Abunama-Elgadi Etienne Charles Teni Apelian Yeraz Markarian Anaïs Tekerian Reph Starr Patty Dukes Shanna Lesniak Savannah Music Festival PUBLISHING AND CREATIVE SERVICES Carol Ann Cheung, Senior Editor Eric Lubarsky, Senior Editor Raphael Davison, Senior Graphic Designer ILLUSTRATIONS Sophie Hogarth AUDIO PRODUCTION Jeff Cook Weill Music Institute at Carnegie Hall 881 Seventh Avenue | New York, NY 10019 Phone: 212-903-9670 | Fax: 212-903-0758 [email protected] carnegiehall.org/MusicalExplorers Musical Explorers is made available to a nationwide audience through Carnegie Hall’s Weill Music Institute. Lead funding for Musical Explorers has been provided by Ralph W. and Leona Kern. Major funding for Musical Explorers has been provided by the E.H.A. Foundation and The Walt Disney Company. © Additional support has been provided by the Ella Fitzgerald Charitable Foundation, The Lanie & Ethel Foundation, and -

An Evening of Indian Classical Music
INTERNATIONAL CENTRE GOA Organises An Evening of Indian Classical Music For the Faculty and Students of College of William & Mary, USA Sunday, 8 June 2008 at 6:30 – 8:00 pm Venue: MANDOVI Hall, The International Centre, Goa, Dona Paula, Goa 403004 PROGRAMME Welcome by M Rajaretnam, Director/ Chief Executive, International Centre Goa Introduction of the Jugalbandi Dr. Anupam Sarkar and artists by Jugalbandi of Sitar by Shri Manab Das, and Flute by Shri Sonik Arvind Velingkar Accompanied on Tabla by Shri Ulhas Velingkar Compere: Ms. Soma Bhattacharya ------------------------------------------- A jugalbandi (also spelled jugalbandhi ) is a performance, in Indian classical music, featuring two solo musicians. The word jugalbandhi means, literally, “Entwined twins”. Often, the musicians will play different instruments, as for example the famous duets between sitarist Ravi Shankar and sarod player Ali Akbar Khan, who popularized the format with their performances of the 1970s. More rarely, the musicians (either vocalists or instrumentalists) may be from different traditions (i.e. Carnatic music and Hindustani classical music). What defines jugalbandhi is that the two soloists be on an equal footing. While any Indian music performance may feature two musicians, a performance can only be deemed a jugalbandhi if neither is clearly the soloist and neither clearly an accompanist. In jugalbandhi , both musicians act as lead players, and a playful competition often ensues between the two performers. ABOUT ARTISTS Shri Manab Das: Eminent Sitarist Manab Das, Masters in Music from Visva Bharati University. He started his career at the age of six under the tutelage of Late Ustad Ali Ahmed Kahn and later under the guidance of Pandit Indranil Bhattacharya in the age old tradition of Guru Shishya Parampara. -

1St PROGRESS REPORT Scheme : “Safeguarding the Intangible
1 1st PROGRESS REPORT Scheme : “Safeguarding the Intangible Cultural Heritage and Diverse Cultural Traditions of India. Title of the Project/Purpose: Prepared by: Shri Bipul Ojah “A study of various aspects of Khol: Village- Dalahati A Sattriya Musical Instrument” Barpeta-781301 Assam During the first reporting period I proceeded with my works as per my plan, and took up two tasks mentioned in the plan. One of them was to acquire knowledge of ‘Ga-Maan’, “Chok’, “Ghat” etc. of the main time division (taal) of Khol from the experienced masters and Sattriyas of the Satras belonging to the three main groups. The other task was to prepare the pattern of the time division in a scientific method by maintaining the characteristic features of the Sattriya Khol on the basis of the acquired knowledge. For these two tasks, I first chose Barpeta Satra and the Satras of the Kamalabari group of Majuli, and apart from doing field study there, I acquired knowledge of the Khol from the masters there. In this course I talked to Sri Basistha Dev Sarma, Burha Sattriya of Barpeta Satra, Sri Nabajit Das, Deka Sattriya of Barpeta Satra, Sri Jagannath Barbayan (92 years), the chief ‘Bayan’ of Barpeta Satra and Sri Akan Chandra Bayan, besides several distinguished Sattriya artists and writers such as Sri Nilkanta Sutradhar, Sri Gunindra Nath Ojah, Dr. Birinchi Kumar Das, Dr. Babul Chandra Das etc. Moreover, I studied various ‘Charit Books’ (biographies of the Vaishnavite saints), research books etc. and got various data on the Khol practiced in Barpeta Satra. After completing these works on the Khol of Barpeta Satra, I worked on the time division (taal) of the Khol practiced in the Satras of the Kamalabari group of Majuli. -

Stephen M. Slawek Curriculum Vitae
Stephen M. Slawek Curriculum Vitae 10008 Sausalito Drive Butler School of Music Austin, TX 78759-6106 The University of Texas at Austin (512) 794-2981 Austin, TX. 78712-0435 (512) 471-0671 Education 1986 Ph.D. (Ethnomusicology) University of Illinois at Urbana-Champaign 1978 M.A. (Ethnomusicology) University of Hawaii at Manoa 1976 M. Mus. (Sitar) Banaras Hindu University 1974 B. Mus. (Sitar) Banaras Hindu University 1973 Diploma (Tabla) Banaras Hindu University 1971 B.A. (Biology) University of Pennsylvania Employment 1999-present Professor of Ethnomusicology, The University of Texas at Austin 2000 Visiting Professor, Rice University, Hanzsen and Lovett College 1989-1999 Associate Professor of Ethnomusicology and Asian Studies, The University of Texas at Austin 1985-1989 Assistant Professor of Ethnomusicology and Asian Studies, The University of Texas at Austin 1983-1985 Instructor of Ethnomusicology and Asian Studies, The University of Texas at Austin 1983 Visiting Lecturer of Ethnomusicology, University of Illinois at Urbana- Champaign 1982 Graduate Assistant, School of Music, University of Illinois at Urbana- Champaign 1978-1980 Archivist, Archives of Ethnomusicology, School of Music, University of Illinois at Urbana-Champaign Scholarship and Creative Activities Books under contract The Classical Music of India: Going Global with Ravi Shankar. New York and London: Routledge Press. 1997 Musical Instruments of North India: Eighteenth Century Portraits by Baltazard Solvyns. Delhi: Manohar Publishers. Pp. i-vi and 1-153. (with Robert L. Hardgrave) SLAWEK- curriculum vitae 2 1987 Sitar Technique in Nibaddh Forms. New Delhi: Motilal Banarsidass, Indological Publishers and Booksellers. Pp. i-xix and 1-232. Articles in scholarly journals 1996 In Raga, in Tala, Out of Culture?: Problems and Prospects of a Hindustani Musical Transplant in Central Texas. -

The Sixth String of Vilayat Khan
Published by Context, an imprint of Westland Publications Private Limited in 2018 61, 2nd Floor, Silverline Building, Alapakkam Main Road, Maduravoyal, Chennai 600095 Westland, the Westland logo, Context and the Context logo are the trademarks of Westland Publications Private Limited, or its affiliates. Copyright © Namita Devidayal, 2018 Interior photographs courtesy the Khan family albums unless otherwise acknowledged ISBN: 9789387578906 The views and opinions expressed in this work are the author’s own and the facts are as reported by her, and the publisher is in no way liable for the same. All rights reserved No part of this book may be reproduced, or stored in a retrieval system, or transmitted in any form or by any means, electronic, mechanical, photocopying, recording, or otherwise, without express written permission of the publisher. Dedicated to all music lovers Contents MAP The Players CHAPTER ZERO Who Is This Vilayat Khan? CHAPTER ONE The Early Years CHAPTER TWO The Making of a Musician CHAPTER THREE The Frenemy CHAPTER FOUR A Rock Star Is Born CHAPTER FIVE The Music CHAPTER SIX Portrait of a Young Musician CHAPTER SEVEN Life in the Hills CHAPTER EIGHT The Foreign Circuit CHAPTER NINE Small Loves, Big Loves CHAPTER TEN Roses in Dehradun CHAPTER ELEVEN Bhairavi in America CHAPTER TWELVE Portrait of an Older Musician CHAPTER THIRTEEN Princeton Walk CHAPTER FOURTEEN Fading Out CHAPTER FIFTEEN Unstruck Sound Gratitude The Players This family chart is not complete. It includes only those who feature in the book. CHAPTER ZERO Who Is This Vilayat Khan? 1952, Delhi. It had been five years since Independence and India was still in the mood for celebration.