Tracking Climate Models
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Climate Models and Their Evaluation
8 Climate Models and Their Evaluation Coordinating Lead Authors: David A. Randall (USA), Richard A. Wood (UK) Lead Authors: Sandrine Bony (France), Robert Colman (Australia), Thierry Fichefet (Belgium), John Fyfe (Canada), Vladimir Kattsov (Russian Federation), Andrew Pitman (Australia), Jagadish Shukla (USA), Jayaraman Srinivasan (India), Ronald J. Stouffer (USA), Akimasa Sumi (Japan), Karl E. Taylor (USA) Contributing Authors: K. AchutaRao (USA), R. Allan (UK), A. Berger (Belgium), H. Blatter (Switzerland), C. Bonfi ls (USA, France), A. Boone (France, USA), C. Bretherton (USA), A. Broccoli (USA), V. Brovkin (Germany, Russian Federation), W. Cai (Australia), M. Claussen (Germany), P. Dirmeyer (USA), C. Doutriaux (USA, France), H. Drange (Norway), J.-L. Dufresne (France), S. Emori (Japan), P. Forster (UK), A. Frei (USA), A. Ganopolski (Germany), P. Gent (USA), P. Gleckler (USA), H. Goosse (Belgium), R. Graham (UK), J.M. Gregory (UK), R. Gudgel (USA), A. Hall (USA), S. Hallegatte (USA, France), H. Hasumi (Japan), A. Henderson-Sellers (Switzerland), H. Hendon (Australia), K. Hodges (UK), M. Holland (USA), A.A.M. Holtslag (Netherlands), E. Hunke (USA), P. Huybrechts (Belgium), W. Ingram (UK), F. Joos (Switzerland), B. Kirtman (USA), S. Klein (USA), R. Koster (USA), P. Kushner (Canada), J. Lanzante (USA), M. Latif (Germany), N.-C. Lau (USA), M. Meinshausen (Germany), A. Monahan (Canada), J.M. Murphy (UK), T. Osborn (UK), T. Pavlova (Russian Federationi), V. Petoukhov (Germany), T. Phillips (USA), S. Power (Australia), S. Rahmstorf (Germany), S.C.B. Raper (UK), H. Renssen (Netherlands), D. Rind (USA), M. Roberts (UK), A. Rosati (USA), C. Schär (Switzerland), A. Schmittner (USA, Germany), J. Scinocca (Canada), D. Seidov (USA), A.G. -

Chapter 3. Modelling the Climate System
Introduction to climate dynamics and climate modelling - http://www.climate.be/textbook Chapter 3. Modelling the climate system 3.1 Introduction 3.1.1 What is a climate model ? In general terms, a climate model could be defined as a mathematical representation of the climate system based on physical, biological and chemical principles (Fig. 3.1). The equations derived from these laws are so complex that they must be solved numerically. As a consequence, climate models provide a solution which is discrete in space and time, meaning that the results obtained represent averages over regions, whose size depends on model resolution, and for specific times. For instance, some models provide only globally or zonally averaged values while others have a numerical grid whose spatial resolution could be less than 100 km. The time step could be between minutes and several years, depending on the process studied. Even for models with the highest resolution, the numerical grid is still much too coarse to represent small scale processes such as turbulence in the atmospheric and oceanic boundary layers, the interactions of the circulation with small scale topography features, thunderstorms, cloud micro-physics processes, etc. Furthermore, many processes are still not sufficiently well-known to include their detailed behaviour in models. As a consequence, parameterisations have to be designed, based on empirical evidence and/or on theoretical arguments, to account for the large-scale influence of these processes not included explicitly. Because these parameterisations reproduce only the first order effects and are usually not valid for all possible conditions, they are often a large source of considerable uncertainty in models. -

Ngeo170 Commentary.Indd
COMMENTARY To blog or not to blog? GAVIN SCHMIDT is at the NASA Goddard Institute of Space Studies Columbia University 2880 Broadway, New York, New York 10025, USA; co-founder of RealClimate.org. e-mail: [email protected] Scientists know much more about their fi eld than is ever published in peer-reviewed journals. Blogs can be a good medium with which to disseminate this tacit knowledge. ike it or not, there are certain important from a quick skim of the lively. However, this kind of informal scientific areas, such as climate methodology, a figure or two and the second-stage peer review is vital to change, stem-cell research, principal results. Their experience the need to quickly process the vast genetic modification of food teaches them to pay little attention to amount of information being produced. L or evolution, that attract a the occasional piece of overreach in Scientists from all fields rely on it heavily disproportionate amount of public the last paragraph and to fill in the to make a first cut between the studies attention. This is usually because they are sometimes understated background. that are worth reading in more detail and perceived to have relevance for strongly By contrast, a lay person might focus those that aren’t. held ethical, economic, moral or political much more on the easy-to-understand Scientists writing in blogs can make beliefs. Scientific results in these fields ‘throwaway’ comments, and spend little this context available to anyone who is are therefore parsed extremely closely to time evaluating the usefulness of the interested. -

Chapter 1 Ozone and Climate
1 Ozone and Climate: A Review of Interconnections Coordinating Lead Authors John Pyle (UK), Theodore Shepherd (Canada) Lead Authors Gregory Bodeker (New Zealand), Pablo Canziani (Argentina), Martin Dameris (Germany), Piers Forster (UK), Aleksandr Gruzdev (Russia), Rolf Müller (Germany), Nzioka John Muthama (Kenya), Giovanni Pitari (Italy), William Randel (USA) Contributing Authors Vitali Fioletov (Canada), Jens-Uwe Grooß (Germany), Stephen Montzka (USA), Paul Newman (USA), Larry Thomason (USA), Guus Velders (The Netherlands) Review Editors Mack McFarland (USA) IPCC Boek (dik).indb 83 15-08-2005 10:52:13 84 IPCC/TEAP Special Report: Safeguarding the Ozone Layer and the Global Climate System Contents EXECUTIVE SUMMARY 85 1.4 Past and future stratospheric ozone changes (attribution and prediction) 110 1.1 Introduction 87 1.4.1 Current understanding of past ozone 1.1.1 Purpose and scope of this chapter 87 changes 110 1.1.2 Ozone in the atmosphere and its role in 1.4.2 The Montreal Protocol, future ozone climate 87 changes and their links to climate 117 1.1.3 Chapter outline 93 1.5 Climate change from ODSs, their substitutes 1.2 Observed changes in the stratosphere 93 and ozone depletion 120 1.2.1 Observed changes in stratospheric ozone 93 1.5.1 Radiative forcing and climate sensitivity 120 1.2.2 Observed changes in ODSs 96 1.5.2 Direct radiative forcing of ODSs and their 1.2.3 Observed changes in stratospheric aerosols, substitutes 121 water vapour, methane and nitrous oxide 96 1.5.3 Indirect radiative forcing of ODSs 123 1.2.4 Observed temperature -

Volume 3: Process Issues Raised by Petitioners
EPA’s Response to the Petitions to Reconsider the Endangerment and Cause or Contribute Findings for Greenhouse Gases under Section 202(a) of the Clean Air Act Volume 3: Process Issues Raised by Petitioners U.S. Environmental Protection Agency Office of Atmospheric Programs Climate Change Division Washington, D.C. 1 TABLE OF CONTENTS Page 3.0 Process Issues Raised by Petitioners............................................................................................5 3.1 Approaches and Processes Used to Develop the Scientific Support for the Findings............................................................................................................................5 3.1.1 Overview..............................................................................................................5 3.1.2 Issues Regarding Consideration of the CRU E-mails..........................................6 3.1.3 Assessment of Issues Raised in Public Comments and Re-Raised in Petitions for Reconsideration...............................................................................7 3.1.4 Summary............................................................................................................19 3.2 Response to Claims That the Assessments by the USGCRP and NRC Are Not Separate and Independent Assessments.........................................................................20 3.2.1 Overview............................................................................................................20 3.2.2 EPA’s Response to Petitioners’ -
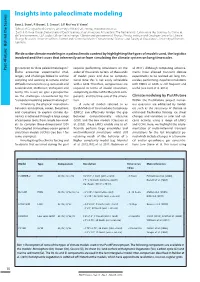
Insights Into Paleoclimate Modeling
Insights into paleoclimate modeling EMMA J. STONE1, P. BAKKER2, S. CHARBIT3, S.P. RITZ4 AND V. VARMA5 1School of Geographical Sciences, University of Bristol, UK; [email protected] 2Earth & Climate Cluster, Department of Earth Sciences, Vrije Universiteit Amsterdam, The Netherlands; 3Laboratoire des Sciences du Climat et de l'Environnement, CEA Saclay, Gif-sur-Yvette, France; 4Climate and Environmental Physics, Physics Institute and Oeschger Centre for Climate Change Research, University of Bern, Switzerland; 5Center for Marine Environmental Sciences and Faculty of Geosciences, University of Bremen, Germany We describe climate modeling in a paleoclimatic context by highlighting the types of models used, the logistics involved and the issues that inherently arise from simulating the climate system on long timescales. n contrast to "data paleoclimatologists" requires performing simulations on the al. 2011). Although computing advance- Past 4Future: Behind the Scenes 4Future: Past Iwho encounter experimental chal- order of thousands to tens of thousands ments have allowed transient climate lenges, and challenges linked to archive of model years and due to computa- experiments to be realized on long tim- sampling and working in remote and/or tional time this is not easily achievable escales, performing snapshot simulations difficult environments (e.g. Gersonde and with a GCM. Therefore, compromises are with EMICs or GCMs is still frequent and Seidenkrantz; Steffensen; Verheyden and required in terms of model resolution, useful (see Lunt et al. 2012). Genty, this issue) we give a perspective complexity, number of Earth system com- on the challenges encountered by the ponents and the timescale of the simula- Climate modeling by Past4Future "computer modeling paleoclimatologist". -

Climate Modeling
Climate Modeling Climate models are important tools for improving our understanding and predictability of climate behavior on seasonal, annual, decadal, and centennial time scales. Models investigate the degree to which observed climate changes may be due to natural variability, human activity, or a combination of both. Their results and projections provide essential information to better inform decisions of national, regional, and local importance, such as water resource management, agriculture, transportation, and urban planning. The Geophysical Fluid Dynamics Laboratory has been one of the world leaders in climate modeling and simulation for the past 50 years. Beginning in the 1960s, GFDL scientists developed the first coupled ocean-atmosphere general circulation climate model, and have continued to pioneer improvements and advances in a growing modeling community. State-of-the art climate modeling at GFDL requires vast computational resources, including supercomputers with thousands of processors and petabytes of data storage. What is a Global Climate Model? A global climate model (GCM) is a complex mathematical representation of the major climate system components (atmosphere, land surface, ocean, and sea ice), and their interactions. Earth's energy balance between the four components is the key to long- term climate prediction. The main climate system components treated in a climate model are: • The atmospheric component, which simulates clouds and aerosols, and plays a large role in transport of heat and water around the globe. • The land surface component, which simulates surface characteristics such as vegetation, snow cover, soil water, rivers, and carbon storing. • The ocean component, which simulates current movement and mixing, and biogeochemistry, since the ocean is the dominant reservoir of heat and carbon in the climate system. -

SUPERIOR COURT of the DISTRICT of COLUMBIA CIVIL DIVISION MICHAEL E. MANN, PH.D., Plaintiff, V. NATIONAL REVIEW, INC., Et Al., D
SUPERIOR COURT OF THE DISTRICT OF COLUMBIA CIVIL DIVISION ) MICHAEL E. MANN, PH.D., ) ) Case No. 2012 CA 008263 B Plaintiff, ) ) Judge Natalia Combs Greene v. ) ) Next event: Initial Scheduling Conference NATIONAL REVIEW, INC., et al., ) January 25, 2013 ) Defendants. ) ) DEFENDANTS COMPETITIVE ENTERPRISE INSTITUTE AND RAND SIMBERG’S SPECIAL MOTION TO DISMISS PURSUANT TO THE D.C. ANTI-SLAPP ACT Pursuant to the District of Columbia Anti-SLAPP Act of 2010, D.C. Code § 16 -5502(a) (“the D.C. Anti-SLAPP Act” or “the Act”), Defendants Competitive Enterprise Institute and Rand Simberg (“CEI Defendants”) respectfully move for an order dismissing the Complaint’s claims against them with prejudice. As set forth in the accompanying memorandum, the CEI Defendants’ commentary on Plaintiff Michael E. Mann’s research and Penn State’s investigation of his research is protected by the D.C Anti-SLAPP Act because it is unquestionably an “act in furtherance of the right of advocacy on issues of public interest,” D.C. Code § 16-5502(a), and Mann cannot demonstrate that his claims are “likely to succeed on the merits,” D.C. Code § 16-5502(b). In the event that this Motion is granted, the CEI Defendants reserve the right to file a motion seeking an award of the costs of this litigation, including attorneys’ fees, pursuant to D.C. Code § 16-5504(a). WHEREFORE, the CEI Defendants respectfully request that the Court grant their Special Motion to Dismiss and enter judgment in their favor dismissing the Complaint’s claims against Defendants Competitive Enterprise Institute and Rand Simberg with prejudice. -

The Jormungand Climate Model
The Jormungand Climate Model By Christopher V. Rackauckas Abstract The geological and paleomagnetic record indicate that around 750 million and 580 millions years ago glaciers grew near the equator, though as of yet we do not fully understand the nature of these glacia- tions. The well-known Snowball Earth Hypothesis states that the Earth was covered entirely by glaciers. However, it is hard for this hypothesis to account for certain aspects of the biological evidence such as the survival of photosynthetic eukaryotes. Thus the Jormungand Hypothesis was developed as an alternative to the Snowball Earth Hypothesis. In this paper we investigate previous models of the Jormungand state and look at the dynamics of the Hadley cells to develop a new model to represent the Jormungand Hypothesis. We end by solving for an analytical approximation to the model using a nite Legendre expansion and geometric singular perturbation theory. The resultant model gives a stable equilibrium point near the equator with strong hysteresis that satises the Jormungand Hypothesis. 1 Introduction Geological and paleomagnetic evidence indicates that glaciers grew near the equator during at least two time periods between 750 million and 580 million years ago in what is known as the Neoproterozoic era [3, 4]. To explain these ndings, the Snowball Earth Hypothesis was proposed. The Snowball Earth hypothesis states the the Earth's surface was covered entirely by glaciers. However, biological evidence such as the survival of photosynthetic eukaryotes has lead some researchers to support alternative hypotheses [1]. Many of these alternatives are unable to satisfy the strong hysteresis of CO2 seen in the data (which is the existence of two stable states over a large range of CO2 values). -

Climate Investigations Using Ice Sheet and Mass Balance Models with Emphasis on North American Glaciation Sean David Birkel
The University of Maine DigitalCommons@UMaine Electronic Theses and Dissertations Fogler Library 2010 Climate Investigations Using Ice Sheet and Mass Balance Models with Emphasis on North American Glaciation Sean David Birkel Follow this and additional works at: http://digitalcommons.library.umaine.edu/etd Part of the Glaciology Commons Recommended Citation Birkel, Sean David, "Climate Investigations Using Ice Sheet and Mass Balance Models with Emphasis on North American Glaciation" (2010). Electronic Theses and Dissertations. 97. http://digitalcommons.library.umaine.edu/etd/97 This Open-Access Dissertation is brought to you for free and open access by DigitalCommons@UMaine. It has been accepted for inclusion in Electronic Theses and Dissertations by an authorized administrator of DigitalCommons@UMaine. CLIMATE INVESTIGATIONS USING ICE SHEET AND MASS BALANCE MODELS WITH EMPHASIS ON NORTH AMERICAN GLACIATION By Sean David Birkel B.S. University of Maine, 2002 M.S. University of Maine, 2004 A THESIS Submitted in Partial Fulfillment of the Requirements for the Degree of Doctor of Philosophy (in Earth Sciences) The Graduate School The University of Maine December, 2010 Advisory Committee: Peter O. Koons, Professor of Earth Sciences, Advisor George H. Denton, Libra Professor of Earth Sciences, Co-advisor Fei Chai, Professor of Oceanography James L. Fastook, Professor of Computer Science Brenda L. Hall, Professor of Earth Science Terrence J. Hughes, Professor Emeritus of Earth Science ©2010 Sean David Birkel All Rights Reserved iii CLIMATE INVESTIGATIONS USING ICE SHEET AND MASS BALANCE MODELS WITH EMPHASIS ON NORTH AMERICAN GLACIATION By Sean D. Birkel Thesis Advisor: Dr. Peter O. Koons An Abstract of the Dissertation Presented in Partial Fulfillment of the Requirements for the Degree of Doctor of Philosophy (in Earth Sciences) December, 2010 This dissertation describes the application of the University of Maine Ice Sheet Model (UM-ISM) and Environmental Change Model (UM-ECM) to understanding mechanisms of ice-sheet/climate integration during ice ages. -

Top NASA Climate Change Expert Retiring 2 April 2013
Top NASA climate change expert retiring 2 April 2013 government, most notably when the administration of George W. Bush sought to muzzle him in 2005. Gavin Schmidt, deputy chief of the Goddard Institute, was quoted as saying that Hansen "has been at the forefront of almost every conceptual advance in climate in science over 40 years." "The stuff that Jim wrote 20 years ago has set the tone for the whole field [and the] predictions he made have generally worked out very favorably," Schmidt said. (c) 2013 AFP James Hansen (L) joins demonstrators during a protest on global warming on March 19, 2009 in Coventry, England. The pioneering NASA climatologist, one of the first scientists to raise the alarm about global warming, is retiring after 46 years, a colleague confirmed to AFP on Tuesday. Pioneering NASA climatologist James Hansen, one of the first scientists to raise the alarm about global warming, is retiring after 46 years, a colleague confirmed to AFP on Tuesday. Hansen, 72, who headed the Goddard Institute for Space Studies in New York, announced his departure in an email to the New York Times on Monday. The Times reported Hansen was stepping down to allow himself to campaign more aggressively for legislation to cut greenhouse gases. Hansen first rose to prominence in 1988 when his testimony at a highly publicized US Congressional hearing thrust the issue of man-made climate change onto the political agenda. His work has often been attacked by climate change skeptics while his activism has also brought him into conflict with the federal 1 / 2 APA citation: Top NASA climate change expert retiring (2013, April 2) retrieved 29 September 2021 from https://phys.org/news/2013-04-nasa-climate-expert.html This document is subject to copyright. -

Communicating Climate Change: the Importance of the Big Picture
NOAA Postdoc program 20th Anniversary Communicating Climate Change: The importance of the big picture Gavin Schmidt (Class 6) NASA GISS and Center for Climate Systems Research, Columbia University New York NOAA Postdocs are... Smart BEFORE AFTER Varied in approach, subject Interdisciplinary by nature Knowledgeable about the big picture Excellent candidates for communicating science! Politicized Science 'Scientized'* Politics Science gets politicized when Politics get scientized when scientific results appear to advocates appear to debate the impact vested political, ethical science in order to avoid debating or moral interests the values that underly their positions (*coined by Dan Sarewitz) New results are only seen in the Nothing to do with real scientific public realm to the extent that debate they project onto the 'Science-iness' is used to make a political/ethical/moral question case, not find the truth Cherry-picking, strawmen, red herrings common Consequences? Good: Scientific papers that project onto the perceived debate are easier to get into Nature or Science More media coverage of your work Bad: Scientific papers frequently quoted out of context, distorted Politics is not as nice as science Scientists under much more public scrutiny Media reports not generally accurate - “False Balance”, sensationalism, over-interpretation common Public understanding decreases, trust in science erodes Continual 'debate' about irrelevancies hinders serious discussion Ethical Issues Scientists have a responsibility to avoid public misuse of their work: - avoiding sensationalism, over-extrapolated conclusions - use/misuse for advocacy purposes? How much effort must scientists invest to improve understanding? - press releases, interviews - briefings for policymakers/journalists/lay public - blogs/FAQs/Interactive Q&A etc.