Klasifikasi Hasil Pertandingan Tim Sepak Bola
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Match Summary
AFF Suzuki Cup Group B Match Summary Match No. Match Date and Time (UTC+8) Stadium Weather Temp (°C) Attendance 003 SIN vs IDN 2018-11-09 20:00 Singapore Sports Hub (SIN) medium 27 30783 RESULT 1 1st Half 0 0 2nd Half 0 Singapore 1 - 1st Extra time - 0 Indonesia - 2nd Extra time - - Penalty shoot-out - LINE-UPS Singapore (SIN) Indonesia (IDN) No. Pos Name G OG PG PS YC 2Y=R RC S No. Pos Name G OG PG PS YC 2Y=R RC S 18 GK Hassan Abdullah Sunny 26 GK Andritany Ardhiyasa 2 DF Muhammad Shakir 86 2 DF Putu Gede Juni 60 92 Hamzah Antara 7 MF Muhammad 54 4 MF Zulfiandi Zulqarnaen Suzliman 10 MF Muhammad Faris Ramli 6 MF Evan Dimas Darmono 11 MF Muhammad Yasir 9 FW Alberto Goncalves Hanapi Da Costa y r 13 MF Muhammad Izzdin 10 MF Stefano Janjte 84 a Shafiq Yacob Lilipaly 14 MF Hariss Harun (C) 37 13 MF Febri Hariyadi m 16 DF Irfan Fandi Ahmad 14 DF Rizki Rizaldi Pora 8 m 20 FW Ikhsan Fandi Ahmad 93 15 DF Ricky Fajrin Saputra 64 u S 21 DF Muhammad Safuwan 18 MF Irfan Jaya 46 Baharudin h c 22 MF Gabriel Quak Jun Yi 77 23 DF Hansamu Yama t Pranata (C) a Substitutes Substitutes M 1 GK Mohamad Izwan 1 GK Muhammad Ridho Mahbud 30 GK Zaiful Nizam Abdullah 12 GK Awan Setho Raharjo 4 DF Muhammad Nazrul 86 3 MF Alfath Faathier Ahmad Nazari 5 DF Baihakki Khaizan 5 DF Bagas Adi Nugroho 8 DF Mahler Jacob William 8 MF Muhammad Hargianto 9 DF Mohammed Faritz 11 DF Gavin Kwan Adsit Abdul Hameed 15 FW Mohamed Iqbal Hamid 16 DF Fachruddin Wahyudi 64 Hussain Aryanto 17 FW Mohammad Shahril 19 MF Bayu Pradana Ishak Andriatmoko 19 FW Mohammad Khairul 93 21 MF Andik -

Fanatisme Suporter Sepakbola Persija Jakarta
FANATISME SUPORTER SEPAKBOLA PERSIJA JAKARTA Bayu Agung Prakoso, Achmad Mujab Masykur* Fakultas Psikologi Universitas Diponegoro Email : [email protected], [email protected]* ABSTRAK Tujuan penelitian ini adalah mendiskripsikan dan memahami perilaku fanatisme suporter sepakbola. Fanatisme adalah sikap penuh semangat yang berlebihan terhadap satu segi pandangan atau satu sebab. The Jakmania sebagai salah satu suporter fanatik terhadap klub Persija Jakarta memiliki sikap dan perilaku yang positif dalam mendukung klub kesayangan. Perilaku yang ditimbulkan suporter The Jakmania dengan tidak mau merugikan orang lain bahkan merugikan klub Persija sendiri. The Jakmania lebih banyak memunculkan kreatifitas dari pada anarkis. Tetapi tidak dapat dipungkiri bahwa kreatifitas The Jakmania pun lebih menonjol daripada suporter lainnya di Indonesia berdasarkan kefanatikan mereka juga. Metode penelitian fenomenologi ini, Peneliti menggunakan 3 subjek utama. Data yang sudah terkumpul kemudian dianalisis menggunakan model analisis eksplikasi data yang menghasilkan temuan-temuan fanatisme suporter The Jakmania di lapangan. Temuan fanatisme suporter The Jakmania di lapangan banyak berbentuk positif. Dari hasil penelitian diperoleh perilaku fanatik dari ketiga subjek yang bentuknya: Subjek pertama, membentuk band —traficool“ dan berperan sebagai gitaris. Subjek kedua, juga tergabung dalam band —traficool“ dan berperan sebagai drummer. Sedangkan subjek ketiga, menghasilkan jersey dari desain sendiri. Motif dari ketiga subjek semata-mata karena kecintaan subjek terhadap klub Persija Jakarta. Selain itu, peneliti berhasil mengetahui bentuk perilaku fanatik yang terbagi menjadi dua yaitu fanatik individu dan kolektif beserta proses pembentukan perilakunya. The Jak Mania memiliki kesadaran dalam segala perilakunya, sehingga saat ini adanya pembenahan secara bertahap dalam diri The Jak Mania untuk menjadikan perilaku fanatiknya memiliki dampak positif bagi dirinya, klub Persija dan masyarakat sekitar. -

Kematian Haringga Sirila Dalam Wacana Pemberitaan Media
JURNAL AUDIENS VOL. 1, NO. 1 (2020): MARCH 2020 https://doi.org/10.18196/ja.1106 Kematian Haringga Sirila dalam Wacana Pemberitaan Media (Analisis Wacana Pemberitaan Kasus Haringga Sirila pada Surat Kabar Jawa Pos, Kompas, dan Republika tanggal 26-30 September 2018) Kurniasari Alifta Ramadhani (Correspondence Author) Program Studi Ilmu Komunikasi, Universitas Muhammadiyah Yogyakarta, Indonesia [email protected] Submitted: 30 November 2019; Revised: 2 March 2020; Accepted: 2 March 2020 Abstract Chaos and riots between Indonesian football supporters was once again causing casualities. Haringga Sirila, a Persija Jakarta supporter, died because of riot between supporters of Persib Bandung and The Jakmania, Persija Jakarta supporters, in Gojek Traveloka League 1 at the Bandung Lautan Api Stadium (GBLA) on September 23, 2018. The death of Haringga Sirila was adding a long list of riot case that occurred between Persib Bandung supporters vs. Persija Jakarta supporters. This research tries to see how the Daily Newspaper of Jawa Pos, Kompas, and Republika were covering on the case of Haringga Sirila's death. The research uses critical discourse analysis methods, specifically the Norman Fairclough model. This study analyzes text, practice of discourse, and practice of sociocultural inside coverage. In the sociocultural situation of this country; the existence of media conglomerates in Indonesia has propagated and influenced the practice of producing texts and news discourses. Thus, the news bias on an event often occurs. In the results of this study, it finds that the discourse rolled out by each media was different even though it reported the same event. This can be seen from the analysis results which show that in the news related to this case, Jawa Pos identified itself with the supporters and clubs of League 1. -

1.1 . Latar Belakang PENDAHULUAN Berbicara Mengenai Sepak Bola
BABl PENDAHULUAN 1.1 . Latar Belakang Berbicara mengenai sepak bola berarti berbicara mengenai banyak orang yang terlibat di dalamnya di antaranya: pemain, pelatih, dan suporter. Menurut Kamus Besar Bahasa Indonesia, suporter berarti orang yang memberikan dukungan/sokongan. Dalam sebuah pertandingan sepak bola kehadiran suporter merupakan hal yang penting karena dukungan suporter tentunya akan menam bah kemeriahan pertandingan dan juga menjadi penyemangat bagi pemain. Penelitian ini hanya berfokus pada satu suporter sepakbola yakni suporter Persebaya yang biasa disebut bonek mania. Istilah Bonek, akronim bahasa Jawa dari Bondho Nekat (modal nekat), biasanya ditujukan kepada sekelompok pendukung atau suporter kesebelasan Persebaya Surabaya, walaupun ada nama kelompok resmi pendukung kesebelasan ini yaitu Yayasan Suporter Surabaya (YSS) (BondoNekat, 4 April2010, para 1). Sebutan suporter Persebaya bermula saat ada penghimpunan suporter besar-besaran jelang Persebaya bertanding melawan PSIS dalam final kompetisi perserikatan pada era 1987-an. Saat itu Persebaya kalah. Suporter Persebaya mulai berulah dengan merusak apa saja dan menjarah (Bali Post, 31 Januari 2010, para. 7). Para pendukung Persebaya juga memiliki slogan yang amat mengerikan, "Salam Satu Nyali. Wani (berani)!". Slogan ini sengaja dibuat untuk memotivasi bonek agar lebih berani dan nekat membela timnya (Kompas, 22 Maret 2010, para. 2). Kenekatan ini terlihat saat suporter Persebaya yang berada di bawah pembinaan pemerintah kota Surabaya dan kebanyakan suporter juga berasal 1 2 dari Surabaya ini sering melakukan kekacauan, terutama saat Persebaya bertanding dan mengalami kekalahan. Beberapa peristiwa anarkis yang disebabkan para bonek ini antara lain adalah kerusuhan pada pertandingan Copa Dji Sam Soe antara Persebaya Surabaya melawan Arema Malang pada 4 September 2006 di Stadion 10 November, Tambaksari, Surabaya. -

Dinamika Panser Biru Sebagai Suporter Psis Semarang Tahun 2001-2006
PEMAIN KEDUA BELAS MAHESA JENAR : DINAMIKA PANSER BIRU SEBAGAI SUPORTER PSIS SEMARANG TAHUN 2001-2006 SKRIPSI Sebagai pertanggungjawaban untuk memperoleh gelar Sarjana Sosial (S.Sos.) Oleh: Aditya Nodie Fahreza NIM 3111416036 JURUSAN SEJARAH FAKULTAS ILMU SOSIAL UNIVERSITAS NEGERI SEMARANG 2020 ii iii iv MOTTO DAN PERSEMBAHAN Motto “...Allah SWT tidak mempertanyakan 5+5 berapa, karena jawabannya pasti hanya satu, yaitu 10. Tetapi Allah SWT akan bertanya, 10 itu berapa ditambah berapa...” -Muhammad Quraish Shihab “Cendekiawan Muslim” Persembahan Untuk keluarga kecil saya yang telah berjuang hingga pada titik ini. Segala keberkahan selalu tercurah untuk kalian semua. v KATA PENGANTAR Pemilihan topik ini bukanlah tanpa alasan, selain untuk menambah literasi sejarah terkait suporter, juga disebabkan karena dinamika dan dampak keberadaan suporter yang besar bagi klub, kota dan masyarakat disekitar. Sejarah berdirinya Panser Biru serta dinamika yang dialami oleh Panser sangat menarik untuk diteliti, karena keberadaan Panser Biru dapat berdampak pada sosial, ekonomi dan politik bagi klub, kota dan masyarakat di Semarang. Panser Biru sebagai suporter Mahesa Jenar, yaitu julukan PSIS Semarang, serta merupakan organisasi suporter sepakbola pertama yang ada di Semarang dideklarasikan pada tahun 2001, hingga sekarang berumur 19 tahun masih tetap eksis sebagai salah satu suporter terbesar di Indonesia. Beberapa hal tersebut yang mendasari saya untuk mengambil topik ini. Bukan topik ini yang pertama saya usulkan, tetapi ini merupakan usulan dari dosen pembimbing. Kemudian saya research terkait Panser Biru, ternyata belum ada yang membahas mengenai sejarah, dinamika dan dampak dari Panser Biru, penelitian terdahulu hanya berfokus pada fanatisme Panser Biru dan konflik Panser Biru dengan Snex. Saya sendiri sangat menikmati proses melakukan penelitian ini, karena memang saya menyukai hal-hal yang berhubungan dengan sepakbola. -

Digital Repository Universitas Jember Digital Repository Universitas Jember
DigitalDigital RepositoryRepository UniversitasUniversitas JemberJember MODAL SOSIAL SUPORTER BERNI DALAM MEMBANGUN IDENTITAS KELOMPOK SUPORTER DI KABUPATEN JEMBER SOCIAL CAPITAL SUPPORTERS BERNI IN BUILDING SUPPORTER GROUP IDENTITIES IN JEMBER REGENCY SKRIPSI Oleh FRANKO NANDA ARTANTO 140910302027 PROGRAM STUDI SOSIOLOGI FAKULTAS ILMU SOSIAL DAN ILMU POLITIK UNIVERSITAS JEMBER 2019 DigitalDigital RepositoryRepository UniversitasUniversitas JemberJember MODAL SOSIAL SUPORTER BERNI DALAM MEMBANGUN IDENTITAS KELOMPOK SUPORTER DI KABUPATEN JEMBER SOCIAL CAPITAL SUPPORTERS BERNI IN BUILDING SUPPORTER GROUP IDENTITIES IN JEMBER REGENCY SKRIPSI diajukan guna melengkapi tugas akhir dan memenuhi syarat-syarat untuk menyelesaikan Program Studi Sosiologi (S1) dan mencapai Gelar Sarjana Sosial Oleh FRANKO NANDA ARTANTO 140910302027 PROGRAM STUDI SOSIOLOGI FAKULTAS ILMU SOSIAL DAN ILMU POLITIK UNIVERSITAS JEMBER 2019 i DigitalDigital RepositoryRepository UniversitasUniversitas JemberJember PERSEMBAHAN Skripsi ini saya persembahkan untuk: 1. Kedua orang tuaku tercinta, Ibunda Napsari Nande Wati dan Ayahanda Tutus Artanto yang senantiasa memberikan do‟a, dukungan, cinta dan kasih sayang yang abadi, serta semangat yang diberikan kepada penulis untuk dapat menyelesaikan skripsi ini. 2. Saudara-saudaraku tersayang Franky Nanda Artanto, Fransiska Novita Sari, Frisilia Novira Sari dan seluruh keluarga besar yang senantiasa memberikan doa dan dukungan. 3. Kepada dosen pembimbing Lukman Wijaya Baratha, S.Sos., M.A dan Drs. Joko Mulyono, M.Si yang telah memberikan arahan dan perhatian dalam pengerjaan skripsi ini. 4. Almamater tercinta, Program Studi Sosiologi Fakultas Ilmu Sosial dan Ilmu Politik Universitas Jember. ii DigitalDigital RepositoryRepository UniversitasUniversitas JemberJember MOTTO “Sesungguhnya bersama kesulitan ada kemudahan. Maka apabila engkau telah selesai (dari sesuatu atau urusan), tetaplah bekerja keras (untuk urusan yang lain), dan hanya kepada Tuhanmu engkau berharap” ) (terjemahan Surat Asy-Syarh ayat 6-8) ) Departemen Agama Republik Indonesia. -

Peran Satuan Petugas Anti Mafia Bola Terhadap Pengungkapan Tindak
PERAN SATUAN PETUGAS ANTI MAFIA BOLA TERHADAP PENGUNGKAPAN TINDAK PIDANA PENGATURAN SKOR (MATCH FIXING) Baskara Putra Setyawan, Setya Wahyudi, Dessi Perdani Yuris Fakultas Hukum Universitas Jenderal Soedirman Jl. Prof. H.R. Boenyamin No. 708, Banyumas, 53122 [email protected] Abstrak Di Indonesia telah terjadi kejahatan dalam olahraga sepak bola ,salah satu jenis kejahatan yang terjadi pada dunia olahraga sepak bola Indonesia saat ini yaitu Tindak Pidana Pengaturan Skor. Tindak Pidana Pengaturan Skor biasanya dilakukan oleh lebih dari satu orang dalam suatu kelompok dan dilakukan secara terorganisir. Dalam proses penegakan hukum yang dilakukan oleh satuan petugas anti mafia bola terhadap tindak pidana Pengaturan Skor diawali dengan proses penyelidikan lalu penyidikan. Tujuan dari penelitian ini untuk mengetahui bagaimana implementasi satuan petugas anti mafia bola dalam mengungkap tindak pidana pengaturan skor. Metode pendekatan yang digunakan dalam penelitian ini adalah yuridis sosiologis, dengan spesifikasi deskriptif, dan lokasi penelitian di Polda Metro Jaya. Jenis dan sumber data adalah data primer dan data sekunder. Metode pengumpulan data terdiri dari data primer berupa wawancara dan data sekunder berupa studi kepustakaan. Metode penyajian data berbentuk teks naratif dan metode analisis kualitatif. Dari hasil penelitian ini menyebutkan bahwa pejabat penyidik di Satuan Petugas Anti Mafia Bola Polda Metro Jaya dalam pemeriksaan pendahuluan pada tingkat penyidikan sudah menetapkan lebih dari 14 tersangka setelah melalui proses-proses tahapan penyelidikan, penyidikan, dan penetapan tersangka dan Satuan Petugas Anti Mafia Bola Polda Metro Jaya telah sesuai dengan PERKAP Nomor 14 Tahun 2012 Tentang Manajemen Penyidikan Tindak Pidana dalam melakukan proses penyelidikan, penyidikan. Kata Kunci: Tindak Pidana, Proses Penyidikan, Pengaturan Skor. Abstract There has been a crime in soccer in Indonesia, one of the types of crimes that occur in the world of Indonesian soccer today is the Crime Scoring. -

BAB I PENDAHULUAN 1.1 Konteks Penelitian Sepakbola Adalah
BAB I PENDAHULUAN 1.1 Konteks Penelitian Sepakbola adalah olahraga masyarakat yang sangat digemari di seluruh dunia bukanhanya anak muda orang tua pun sangat mengidolakan permainan yang sudah menduniaini. Salah satu jenis olahraga murah meriah yang sangat ‘merakyat’ di dunia ini.Kurang pas rasanya jika kita bermain sepakbola tanpa mengetahui sejarah awal muladan asal muasal permainan atau olahraga ini, kebanyakan orang mengira lahirnyasepakbola ini berasal dari Negara Inggris. Pada dasarnya, banyak sekali berbagaigolongan dan individu yang mengutarakan asal muasal dari sepakbola. Seorang pakarsejarah sepakbola misalnya, Bill Muray, menuliskan sebuah buku The World Game: AHistory of Soccer mengatakan bahwa sepakbola sudah dimainkan sejak awal Masehi,orang-orang di era Mesir Kuno telah mengenal permainan ini dengan cara membawadan menendang bola yang terbuat dari buntalan kain linen. Kemudian, dalam sejarahYunani Purba mencatatkan juga terdapat sebuah permainan yang disebut Episcuro(permainan dengan menggunakan bola) sebutan mereka untuk permainan sepakbola initerbukti dari gambar relief pada dinding museum yang mengisahkan tentang seoranganak muda yang sedang memegang bola bulat dan memainkannya dengan pahanya. Terdapat juga sebuah versi sejarah kuno tentang asal muasal sepakbola lainnya yangberasal dari Negeri Sakura, Jepang, sejak abad ke 8, masyarakat Jepang 1 menyebutnyadengan sebutan Kemari (bola yang digunakan terbuat dari kulit kijang yang ditengahtengahnyaterdapat lubang yang berisi udara).Dikarenakan banyaknya versi dan beragam pendapat dari berbagai kalangan inilahmaka pada awal tahun 1900-an atau tepatnya tahun 1904, didirikanlah sebuahorganisasi tertinggi sepakbola dunia atau yang kita kenal sebagai FIFA. Secara resmipun FIFAmenyatakan bahwa olahraga sepakbola pada awalnya berasal dari daratan Cina yaitutepatnya pada abad ke-2 hingga abad ke-3 SM pada masa pemerintahan Dinasti Han,pada waktu itu dikenal dengan sebutan ‘Tsu-chu’ (Tsu yang artinya menerjang boladengan kaki, sedangkan chu memiliki arti bola dari kulit dan berisi). -

Tugas Akhir Etika Moral
TUGAS AKHIR ETIKA MORAL Dosen pengampu : Dr.A.W.Dewantara,S.S., M.Hum Disusun : Dicky Nur Haryanto ( 11417004) PROGRAM STUDI BIMBINGAN DAN KONSELING FAKULTAS KEGURUAN DAN ILMU PENDIDIKAN UNIVERSITAS KATOLIK WIDYA MANDALA 2018 ABSTRAK Penegakan hukum yang lemah oleh federasi dianggap penyebab Indonesia menjadi lahan subur pengaturan skor laga sepakbola. Hati nurani ialah kapasitas ke eleng an dalam diri manusia. Artinya, sejauh merupakan kapasitas, dia tidak bisa melepaskan diri dari konteks ruang lingkup di mana manusia hidup/ada/menyejarah. Thomas mengatakan : bila kesesatan hati nurani invincible dan inculpable orang dapat luput dari perbuatan yang secara moral jahat. Artinya, bila ia berbuat jahat atas dorongan hatinya yang sesat invicible and inclupable. PSSI, Hidayat di ketahui hidayat kesesatan hati nuraninya culpable and vincible dia berdosa karena mengikuti hati nuraninya yang sesat ingin menyogok madura fc untuk mengalah . Keyword : hati nurani sesat, pengaturan skor, sepak bola KASUS PENGATURAN SKOR SEPAK BOLA INDONESIA : “PENJUDI MENYOGOK DARI MANAJER HINGGA PEMAIN Penegakan hukum yang lemah oleh federasi dianggap penyebab Indonesia menjadi lahan subur pengaturan skor laga sepakbola. Namun PSSI mengklaim telah melakukan beragam upaya yang disarankan induk organisasi sepakbola dunia (FIFA) untuk mencegah kecurangan yang melibatkan jaringan judi. Pengakuan manajemen klub Madura FC soal tawaran uang untuk kesepakatan pengaturan skor disebut momentum baru PSSI memberantas patgulipat yang mencederai sportivitas. Manajer Madura FC, Januar Herwanto, menuding anggota Komite Khusus PSSI, Hidayat, menawarinya uang Rp100-150 juta. Syaratnya, Madura harus memberi kemenangan pada PSS Sleman dalam laga Liga 2. Januar pertama kali mengeluarkan tuduhan itu dalam tayangan gelar wicara televisi, Mata Najwa, 28 November lalu. Dalam acara yang sama, Hidayat membantah tudingan yang diarahkan kepadanya. -

Midweek Regular Coupon 17/06/2019 09:03 1 / 2
Issued Date Page MIDWEEK REGULAR COUPON 17/06/2019 09:03 1 / 2 BOTH TEAMS INFORMATION 3-WAY ODDS (1X2) DOUBLE CHANCE TOTALS 2.5 1ST HALF - 3-WAY HT/FT TO SCORE HANDICAP (1X2) GAME CODE HOME TEAM 1 / 2 AWAY TEAM 1/ 12 /2 2.5- 2.5+ 01 0/ 02 1-1 /-1 2-1 1-/ /-/ 2-/ 2-2 /-2 1-2 ++ -- No CAT TIME DET NS L 1 X 2 1X 12 X2 U O 1 X 2 1/1 X/1 2/1 1/X X/X 2/X 2/2 X/2 1/2 YES NO HC 1 X 2 Tuesday, 18 June, 2019 2001 AUSCR 11:30 L NOOSA LIONS FC - - - BUDERIM WANDERERS FC - - - - - - - - - - - - - - - - - - - - - - - 2002 IND 11:30 BHAYANGKARA SURABAY.. 7 - - - 18 PERSELA LAM. - - - - - - - - - - - - - - - - - - - - - - - 2003 IND 11:30 PERSEPAM MU 1 - - - 4 PSS SLEMAN - - - - - - - - - - - - - - - - - - - - - - - 2004 IND 11:30 PERSERU SERUI 12 - - - 8 PSIS SEMARANG - - - - - - - - - - - - - - - - - - - - - - - 2005 IND 11:30 PERSIJA JAKARTA 16 - - - 10 PUSAMANIA BORNEO - - - - - - - - - - - - - - - - - - - - - - - 2006 IND 11:30 PERSIPURA JAYAPURA 15 - - - 3 PSM MAKASSAR - - - - - - - - - - - - - - - - - - - - - - - 2007 IND 11:30 SEMEN PADANG 14 - - - 5 PS TNI - - - - - - - - - - - - - - - - - - - - - - - 2008 ASB 12:30 GRANGE THISTLE 4 - - - 2 TOOWONG - - - - - - - - - - - - - - - - - - - - - - - 2009 AST 12:30 L WESTERN PRIDE 14 - - - 4 OLYMPIC FC - - - - - - - - - - - - - - - - - - - - - - - 2010 ACLPO 13:00 1 L KASHIMA ANTLERS 1.75 3.30 4.30 HIROSHIMA 1.14 1.24 1.87 - - - - - - - - - - - - - - - - - - - - 2011 AUS4 13:30 L NOOSA LIONS FC - - - BUDERIM WANDERERS FC - - - - - - - - - - - - - - - - - - - - - - - 2012 IND 14:30 AREMA INDONESIA 11 - - - 5 PERSIB BANDUNG - - - - - - - - - - - - - - - - - - - - - - - 2013 IND 14:30 PERSEBAYA SURABAYA 13 - - - 17 BARITO PUTERA - - - - - - - - - - - - - - - - - - - - - - - 2014 IND 14:30 PERSEPAR KALTENG PU. -
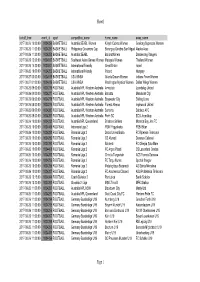
Ponuda 2017-08-26 Prvi Deo.Xlsx
Sheet1 kickoff_time event_id sport competition_name home_name away_name 2017-08-26 10:00:00 1004256 BASKETBALL Australia SEABL Women Kilsyth Cobras Women Geelong Supercats Women 2017-08-26 11:00:00 1004257 BASKETBALL Philippines Governors Cup Barangay Ginebra San Miguel Alaska Aces 2017-08-26 11:30:00 1004258 BASKETBALL Australia SEABL Ballarat Miners Dandenong Rangers 2017-08-26 12:00:00 1004617 BASKETBALL Southeast Asian Games Women Malaysia Women Thailand Women 2017-08-26 15:30:00 1004847 BASKETBALL International Friendly Great Britain Israel 2017-08-26 18:00:00 1004259 BASKETBALL International Friendly Poland Hungary 2017-08-27 00:00:00 1004618 BASKETBALL USA WNBA Atlanta Dream Women Indiana Fever Women 2017-08-27 01:00:00 1004619 BASKETBALL USA WNBA Washington Mystics Women Dallas Wings Women 2017-08-26 09:00:00 1004276 FOOTBALL Australia NPL Western Australia Armadale Joondalup United 2017-08-26 09:00:00 1004277 FOOTBALL Australia NPL Western Australia Balcatta Mandurah City 2017-08-26 09:00:00 1004278 FOOTBALL Australia NPL Western Australia Bayswater City Stirling Lions 2017-08-26 09:00:00 1004279 FOOTBALL Australia NPL Western Australia Floreat Athena Inglewood United 2017-08-26 09:00:00 1004280 FOOTBALL Australia NPL Western Australia Sorrento Subiaco AFC 2017-08-26 09:00:00 1004281 FOOTBALL Australia NPL Western Australia Perth SC ECU Joondalup 2017-08-26 10:00:00 1004282 FOOTBALL Australia NPL Queensland Brisbane Strikers Moreton Bay Jets FC 2017-08-26 10:00:00 1004466 FOOTBALL Indonesia Liga 2 PSIM Yogyakarta PSBI Blitar -

Daftar Susunan Pemain (Match Starting List)
KONSEP TUJUAN DAN KEGUNAAN Manual ini menjadi bagian yang tidak terpisahkan dengan Regulasi dan berisi tentang informasi dan petunjuk (guidelines) untuk Klub. Manual ini digunakan terkait dengan Regulasi dan pelaksanaan Pertandingan. Dalam beberapa bagian dari Manual ini terdapat kesamaan dengan hal-hal yang terdapat di Regulasi dan terdapat hal- hal yang tidak terdapat di Regulasi namun terdapat dalam Manual. Manual ini dibuat sebagai panduan dan tool bagi Klub dalam keikutsertaan di Liga 1 untuk: ! menjalankan dan mengatur high-level home matches; ! memberikan pelayanan terbaik kepada Klub tamu dan perangkat pertandingan sehingga dapat berkonsentrasi penuh dalam Pertandingan dan tugas mereka; ! memberikan kondisi terbaik kepada Klub agar dapat menampilkan permainan terbaik di setiap Pertandingan; ! memberikan fasilitas infrastruktur pertandingan yang aman dan nyaman bagi Pemain dan Ofisial. Manual ini hanya digunakan oleh Klub dan pihak yang terkait dengan pelaksanaan Liga 1. Hal-hal yang terdapat didalamnya tidak diperbolehkan dicetak atau diproduksi ulang tanpa persetujuan LIB. MANUAL LIGA 1 2017 1 KOMPETISI PESERTA Liga 1 diikuti oleh 18 Klub: ! SEMEN PADANG FC ! SRIWIJAYA FC ! PERSIJA JAKARTA ! PERSIB BANDUNG ! PERSELA LAMONGAN ! PERSEGRES GRESIK UNITED ! AREMA FC ! BHAYANGKARA FC ! MADURA UNITED ! BARITO PUTERA ! MITRA KUKAR ! PUSAMANIA BORNEO FC ! PERSIBA BALIKPAPAN ! BALI UNITED ! PSM MAKASSAR ! PS TNI ! PERSERU SERUI ! PERSIPURA JAYAPURA SISTEM DAN FORMAT Pertandingan akan dimainkan dengan sistem kompetisi penuh (round robin)