Darvill 2018.Pdf
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Digital Proportional Amplifier of Linear DC Electromagnet
International Journal of Scientific & Engineering Research Volume 10, Issue 10, October-2019 257 ISSN 2229-5518 Digital proportional amplifier of linear DC electromagnet 1’Hazrat Ali ([email protected]) 2’Wang Xuping ([email protected]) 3’Muhammad Hasham Khan ([email protected]) 4’Haseeb Yar Hiraj ([email protected]) 5’Muhammad Zeeshan Adil([email protected]) Abstract— Digital Signal Processor (DSP) based embedded code generation which is obtained automatically in PSIM software for Permanent Magnet Synchronous Motor (PMSM) control system. The simulation model of the PMSM control system is developed in PSIM environment using Motor Control Blocks and Embedded Target for TI 2000805 block. This control block diagram is send to Sim Coder to generate C-code that is ready to run on the DSP hardware, Sim Coder also creates the complete project files for the TI Code Composer Studio development environment where the code will be compiled, linked, and uploaded to the DSP using High Voltage Motor Control-PFC Kit. So, embedded code generation provides a very quick way to design a motor drive system from user specifications also programming greatly simplifies the generation, prototyping and modification of DSP based design, thus decreasing the development cycle time. Index Terms— Digital Signal Processing Motor Control, PMSM, DSP, Embedded Code Generation, PSIM. —————————— —————————— I. INTRODUCTION H igh capacity and qualification in industry, the permanent magnet synchronous motor (PMSM) has greatly accepted between the various types of alternative current motors. The PMSM’s have been increasingly applied for drive applications, such as robotics and weapon servo-control systems, due to their high power density, torque to inertia ratio and high efficiency [1]. -

Chapter 3 Permanent Magnet Synchronous Motor
Faculdade de Engenharia da Universidade do Porto Traction Control in Electric Vehicles Tiago Oliveira Bastos Pinto de Sá Dissertation prepared under the Master in Electrical and Computers Engineering Major Automation Supervisor: Adriano Carvalho July 2012 © Tiago Sá, 2012 ii To my mother and grandma iii iv Resumo O sector dos transportes é um dos maiores setores industriais hoje em dia. Desde o desenvolvimento do motor de combustão interna e da sua aplicação ao setor dos transportes, as pessoas estão cada vez mais dependentes de uma forma económica e confortável de viajar. Com o aumento do preço dos combustíveis fósseis causado pela sua procura excessiva, e com as recentes preocupações ambientais relativas à emissão de gases poluentes gerados pela queima do combustível, a existência de uma alternativa é fulcral. A forma de transporte alternativo mais comum num ambiente urbano é o autocarro. É mais barato, mais conveniente em determinados casos e produz menos poluição per capita do que um carro próprio. No entanto, continua a poluir. Com isto em mente, e com a recente eminência dos motores elétricos no setor dos transportes, é analisado o controlo de motores síncronos de ímanes permanentes, em particular a aplicação de um de 150kW num autocarro elétrico. O objetivo deste documento é analisar o domínio do controlo na mobilidade elétrica e discutir o projeto do controlador que alimenta o motor, permitindo o seu acionamento e travagem, com a possibilidade de regenerar a energia da travagem, recarregando dessa forma as baterias. O sistema deverá ser capaz de funcionar sem sensores de velocidade ou posição. Pretende-se validar os resultados obtidos na simulação aplicando um motor menos potente do que o objetivo final, de forma a poder validar laboratorialmente esses mesmos resultados. -
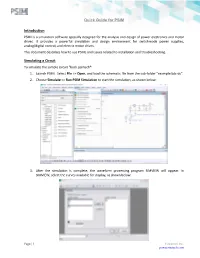
Quick Guide for PSIM Introduction Simulating a Circuit
Quick Guide for PSIM Introduction PSIM is a simulation software specially designed for the analysis and design of power electronics and motor drives. It provides a powerful simulation and design environment for switchmode power supplies, analog/digital control, and electric motor drives. This document describes how to use PSIM, and issues related to installation and troubleshooting. Simulating a Circuit To simulate the sample circuit "buck.psimsch": 1. Launch PSIM. Select File >> Open, and load the schematic file from the sub-folder “examples\dc-dc”. 2. Choose Simulate >> Run PSIM Simulation to start the simulation, as shown below: 3. After the simulation is complete, the waveform processing program SIMVIEW will appear. In SIMVIEW, select the curves available for display, as shown below: Page | 1 Powersim Inc. powersimtech.com Quick Guide for PSIM Setting up Co-Simulation with Matlab/Simulink PSIM can perform co-simulation with Matlab/Simulink. When PSIM is installed, if the SimCoupler Module is enabled in the license, the installation will set up the co-simulation between PSIM and Matlab/Simulink automatically. If you change the PSIM folder name after PSIM is installed, you must run “SetSimPath.exe” in the PSIM directory to set up the co-simulation again. If you are running multiple versions of PSIM or Matlab/Simulink, to associate a specific version of PSIM with a specific version of Matlab/Simulink, from the directory of that PSIM version, run “SetSimPath.exe” located in the PSIM installation folder, and select the desired Matlab/Simulink version. To see how the co-simulation works, follow the steps below to simulate the sample circuit “chop1q_ifb_simulink_r13.mdl”: 1. -

PSIM Presentation
Powersys SUPERCACITOR MODEL IN PSIM Adrien MICHEL POWERSYS International Workshop on Supercapacitors and Energy Storage « SUPERCAPACITORS: On the Pulse of a Revolution » Tuesday 23rd May 2017, ENEA - Bologna, Italy Outline Presentation ✓ POWERSYS overview ✓ PSIM overview and main functions / capabilities ✓ PSIM model for Supercapacitor ✓ Application on automobile hybrid energy storage Powersys: Presentation Powersys is a French consulting and software company providing global solutions of engineering software and services in the field of Electrical & Electromechanical Power Systems. Comprehensive Software offer for Complete range of services: power system applications ▪ Support ▪ Studies Software Services ▪ Training Expert Community Strong relations with the developers to provide the best solution. Connection to a worldwide network of experts, industrial and academic partners. Powersys: A worldwide Presence POWERSYS, France POWERSYS, Canada Corporate headquarters POWERSYS, Germany POWERSYS, USA Softline POWERSYS, Ipetco Hsoft India POWERSYS, India Keliang NEAT CO Tecknocea SAM-A Solutions Elec Soft Astek Future Technologies Legend V Power Offices Powersys Voltex EMTP-RV Distributors Software developers Powersys: Software Distribution Power Systems Transients Power Electronics, Drive and Mechatronic Systems Electromechanical Design PSIM Software Dynamic Simulation Platform for Power Electronics and Motor Drives About PSIM • The Developer of PSIM is www.powersimtech.com • PSIM is born in 1994 in United States • Powersys is the exclusive distributor in Europe • Used in over 70 countries worldwide by thousand of customers PSIM Accelerates Your Pace of Innovation! What is PSIM? • PSIM is a simulation software specifically designed for power electronics, motor drives, and energy conversion applications. • Old version It is positioned between a device/circuit simulator (such as SPICE) and a system/control simulator (such as Matlab/Simulink). -

SHIL and DHIL Simulations of Nonlinear Control Methods Applied for Power Converters Using Embedded Systems
electronics Article SHIL and DHIL Simulations of Nonlinear Control Methods Applied for Power Converters Using Embedded Systems Arthur H. R. Rosa * , Matheus B. E. Silva, Marcos F. C. Campos, Renato A. S. Santana, Welbert A. Rodrigues, Lenin M. F. Morais and Seleme I. Seleme Jr. Graduate Program in Electrical Engineering, Universidade Federal de Minas Gerais, Av. Antônio Carlos 6627, Belo Horizonte 31270-901, MG, Brazil; [email protected] (M.B.E.S.); [email protected] (M.F.C.C.); [email protected] (R.A.S.S.); [email protected] (W.A.R.); [email protected] (L.M.F.M.); [email protected] (S.I.S.J.) * Correspondence: [email protected] Received: 17 August 2018; Accepted: 30 September 2018; Published: 6 October 2018 Abstract: In this work, a new real-time Simulation method is designed for nonlinear control techniques applied to power converters. We propose two different implementations: in the first one (Single Hardware in The Loop: SHIL), both model and control laws are inserted in the same Digital Signal Processor (DSP), and in the second approach (Double Hardware in The Loop: DHIL), the equations are loaded in different embedded systems. With this methodology, linear and nonlinear control techniques can be designed and compared in a quick and cheap real-time realization of the proposed systems, ideal for both students and engineers who are interested in learning and validating converters performance. The methodology can be applied to buck, boost, buck-boost, flyback, SEPIC and 3-phase AC-DC boost converters showing that the new and high performance embedded systems can evaluate distinct nonlinear controllers. -

User's Guide ®
® PSIM User’s Guide Powersim Inc. Chapter : -7 PSIM® User’s Guide Version 9.0 Release 2 March 2010 Copyright © 2001-2010 Powersim Inc. All rights reserved. No part of this manual may be photocopied or reproduced in any form or by any means without the written permission of Powersim Inc. Disclaimer Powersim Inc. (“Powersim”) makes no representation or warranty with respect to the adequacy or accuracy of this documentation or the software which it describes. In no event will Powersim or its direct or indirect suppliers be liable for any damages whatsoever including, but not limited to, direct, indirect, incidental, or consequential damages of any character including, without limitation, loss of business profits, data, business information, or any and all other commercial damages or losses, or for any damages in excess of the list price for the licence to the software and documentation. Powersim Inc. email: [email protected] http://www.powersimtech.com -6 Chapter : Contents 1 General Information 1.1 Introduction 1 1.2 Circuit Structure 2 1.3 Software/Hardware Requirement 3 1.4 Installing the Program 3 1.5 Simulating a Circuit 3 1.6 Component Parameter Specification and Format 3 2 Power Circuit Components 2.1 Resistor-Inductor-Capacitor Branches 7 2.1.1 Resistors, Inductors, and Capacitors 7 2.1.2 Rheostat 8 2.1.3 Saturable Inductor 8 2.1.4 Nonlinear Elements 9 2.2 Switches 10 2.2.1 Diode, LED, Zener Diode, and DIAC 10 2.2.2 Thyristor and TRIAC 12 2.2.3 GTO and Transistors 13 2.2.4 Bi-Directional Switches 15 2.2.5 Linear Switches 16 2.2.6 -
SPICE Module User’S Guide
SPICE Module User’s Guide Powersim Inc. Chapter : -3 SPICE Module User’s Guide Version 12.0 Release 1 July 2019 Copyright © 2016-2019 Powersim Inc. All rights reserved. No part of this manual may be photocopied or reproduced in any form or by any means without the written permission of Powersim Inc. Disclaimer Powersim Inc. (“Powersim”) makes no representation or warranty with respect to the adequacy or accuracy of this documentation or the software which it describes. In no event will Powersim or its direct or indirect suppliers be liable for any damages whatsoever including, but not limited to, direct, indirect, incidental, or consequential damages of any character including, without limitation, loss of business profits, data, business information, or any and all other commercial damages or losses, or for any damages in excess of the list price for the licence to the software and documentation. Powersim Inc. Email: [email protected] powersimtech.com -2 Chapter : Contents 1 Introduction 2 PSIM-SPICE Interface 2.1 Overview 3 2.2 SPICE Model Libraries 3 2.2.1 SPICElib Folder 3 2.2.2 Search Paths for SPICE Models 3 2.2.3 Directives .LIB and .INCLUDE 4 2.2.4 Set Path for LTspice Executable 4 2.2.5 Find SPICE Models in Libraries 4 2.2.6 Netlist Syntax Check 5 2.3 Simulation Control Dialog Options for SPICE Simulation 6 2.3.1 Transient Analysis 6 2.3.2 AC Analysis 7 2.3.3 DC Analysis 8 2.3.4 Step Run Option 9 2.3.5 Other Analysis Options 9 2.4 PSIM Elements for SPICE Simulation 10 2.4.1 Multi-Level Elements 10 2.4.2 SPICE Directive -

Power Electronics: Computer Simulation and Analysis
PROJECT REPORT ON PPOOWWEERR EELLEECCTTRROONNIICCSS:: CCOOMMPPUUTTEERR SSIIMMUULLAATTIIOONN AANNDD AANNAALLYYSSIISS By: Ravi Shankar Singh (10502024) Byaktiranjan Pattanayak (10502030) Shankar Kumar (10502036) B.Tech 8TH SEMESTER Electrical Engineering. Under the guidance of PROF. P.C.PANDA ELECTRICAL ENGINEERING DEPARTMENT NIT ROURKELA ELECTRICAL ENGINEERING DEPARTMENT NATIONAL INSTITUTE OF TECHNOLOGY ROURKELA CERTIFICATE This is to certify that the thesis entitle, “POWER ELECTRONICS:COMPUTER SIMULATION AND ANALYSIS” submitted by Sh. BYAKTIRANJAN PATTANAYAK (10502030) in partial fulfilment of the requirements for the award of Bachelor of Technology Degree in Electrical Engineering at the National Institute of Technology, Rourkela (Deemed University) is an authentic work carried out by him under my supervision and guidance. PLACE: ROURKELA (P.C.PANDA) DATE: PROFESSOR ELECTRICAL ENGINEERING DEPARTMENT NATIONAL INSTITUTE OF TECHNOLOGY ROURKELA CERTIFICATE This is to certify that the thesis entitle, “POWER ELECTRONICS:COMPUTER SIMULATION AND ANALYSIS” submitted by Sh. RAVISHANKAR SINGH (10502024) in partial fulfilment of the requirements for the award of Bachelor of Technology Degree in Electrical Engineering at the National Institute of Technology, Rourkela (Deemed University) is an authentic work carried out by him under my supervision and guidance. PLACE: ROURKELA (P.C.PANDA) DATE: PROFESSOR ELECTRICAL ENGINEERING DEPARTMENT NATIONAL INSTITUTE OF TECHNOLOGY ROURKELA CERTIFICATE This is to certify that the thesis entitle, “POWER ELECTRONICS:COMPUTER SIMULATION AND ANALYSIS” submitted by Sh. SHANKAR KUMAR (10502036) in partial fulfilment of the requirements for the award of Bachelor of Technology Degree in Electrical Engineering at the National Institute of Technology, Rourkela (Deemed University) is an authentic work carried out by him under my supervision and guidance. PLACE: ROURKELA (P.C.PANDA) DATE: PROFESSOR ACKNOWLEDGEMENT: We wish to express our sincere gratitude to our project supervisor Prof. -

PSIM User Manual.Book
® User’s Guide Powersim Inc. Chapter : -7 PSIM® User’s Guide Version 11.1 Release 2 November 2017 Copyright © 2001-2017 Powersim Inc. All rights reserved. No part of this manual may be photocopied or reproduced in any form or by any means without the written permission of Powersim Inc. Disclaimer Powersim Inc. (“Powersim”) makes no representation or warranty with respect to the adequacy or accuracy of this documentation or the software which it describes. In no event will Powersim or its direct or indirect suppliers be liable for any damages whatsoever including, but not limited to, direct, indirect, incidental, or consequential damages of any character including, without limitation, loss of business profits, data, business information, or any and all other commercial damages or losses, or for any damages in excess of the list price for the licence to the software and documentation. Powersim Inc. email: [email protected] http://www.powersimtech.com -6 Chapter : Contents 1 General Information 1.1 Introduction 1 1.2 Circuit Structure 3 1.3 Software/Hardware Requirement 3 1.4 Installing the Program 3 1.5 Simulating a Circuit 4 1.6 Simulation Control 4 1.7 Component Parameter Specification and Format 8 2 Circuit Schematic Design 2.1 PSIM Environment 11 2.2 Creating a Circuit 14 2.3 File Menu 15 2.4 Edit Menu 15 2.5 View Menu 17 2.6 Design Suites Menu 17 2.7 Subcircuit Menu 18 2.7.1 Creating Subcircuit - In the Main Circuit 19 2.7.2 Creating Subcircuit - Inside the Subcircuit 19 2.7.3 Connecting Subcircuit - In the Main Circuit 20 2.7.4 -

PSIM User's Guide
PSIM User’s Guide Powersim Inc. -9 PSIM User’s Guide Version 7.0 Release 3 May 2006 Copyright © 2001-2006 Powersim Inc. All rights reserved. No part of this manual may be photocopied or reproduced in any form or by any means without the written permission of Powersim Inc. Disclaimer Powersim Inc. (“Powersim”) makes no representation or warranty with respect to the adequacy or accuracy of this documentation or the software which it describes. In no event will Powersim or its direct or indirect suppliers be liable for any damages whatsoever including, but not limited to, direct, indirect, incidental, or consequential damages of any character including, without limitation, loss of business profits, data, business information, or any and all other commercial damages or losses, or for any damages in excess of the list price for the licence to the software and documentation. Powersim Inc. email: [email protected] http://www.powersimtech.com -8 Contents 1 General Information 1.1 Introduction 1 1.2 Circuit Structure 2 1.3 Software/Hardware Requirement 3 1.4 Installing the Program 3 1.5 Simulating a Circuit 4 1.6 Component Parameter Specification and Format 4 2 Power Circuit Components 2.1 Resistor-Inductor-Capacitor Branches 7 2.1.1 Resistors, Inductors, and Capacitors 7 2.1.2 Rheostat 8 2.1.3 Saturable Inductor 9 2.1.4 Nonlinear Elements 10 2.2 Switches 11 2.2.1 Diode, DIAC, and Zener Diode 12 2.2.2 Thyristor and TRIAC 13 2.2.3 GTO, Transistors, and Bi-Directional Switch 15 2.2.4 Linear Switches 17 2.2.5 Switch Gating Block 19 2.2.6 Single-Phase -

Design of Isolated Dc-Dc and Dc-Dc-Ac Converters with Reduced
DESIGN OF ISOLATED DC-DC AND DC-DC-AC CONVERTERS WITH REDUCED NUMBER OF POWER SWITCHES A Thesis Submitted to the Faculty of Purdue University by Dhara I. Mallik In Partial Fulfillment of the Requirements for the Degree of Master of Science in Electrical and Computer Engineering August 2017 Purdue University Indianapolis, Indiana ii THE PURDUE UNIVERSITY GRADUATE SCHOOL STATEMENT OF COMMITTEE APPROVAL Dr. Euzeli Cipriano dos Santos, Chair Department of Electrical and Computer Engineering Dr. Mohamed El-Sharkawy Department of Electrical and Computer Engineering Dr. Maher Rizkalla Department of Electrical and Computer Engineering Approved by: Dr. Brian King Head of the Graduate Program iii Dedicated to my beloved parents Munmun Manabee and Dr. M S I Mullick Ma r Bapi iv ACKNOWLEDGMENTS I would like to thank my thesis supervisor and mentor Dr. Euzeli C. dos Santos, for his guidance and inspiration through the research process and course-works. I am grateful to all my committee members. I am immensely indebted to Dr. Brian King, the Head of the Department, not only for his guidance since the very first year of my graduate studies but also for being a continuous support. I am grateful to the other faculty members and staff. I would especially like to mention Sherrie for keep enduring my constant nudging always with a welcoming smile. I want to thank my lab-mates for their support whenever I asked and even when I did not ask. I owe everything to my loving parents who kept sacrificing for me since the day I was born. Even being a thousand of miles away, they never stopped encouraging, motivating and telling me to dream bigger. -

The Ultimate Simulation Environment for Power Electronics and Motor Drives
The Ultimate Simulation Environment for Power Electronics and Motor Drives EXCEPTIONAL PERFORMANCE • Fast simulation speed • Design solutions for motor drive and HEV • Intuitive and easy to use systems • Comprehensive motor drive library • SPICE engine for SPICE model support and device-level simulation • Flexible control simulation • Support of Texas Instruments’ InstaSPIN • Custom C code motor control alg orithm • Automatic code generation for DSP hardware • Link to 3rd-party software POWERSYS - Distributor of PSIM Software With fast simulation and friendly user interface, PSIM provides Our modules fuel the possibilities of power electronics design. a powerful and efficient environment for all your power Select your modules and propel your innovation forwards. electronics and motor drive simulation needs. FRIENDLY USER INTERFACE • SPICE • ModCoupler-VHDL & ModCoupler-Verilog SPICE SIMULATION Support for SPICE models and SPICE simulation Co-simulation with ModelSim® for VHDL & Verilog support PSIM’s graphic user interface is intuitive and very easy to use. While PSIM is ideally suited for system-level and control A circuit can be set up and edited quickly. Simulation results simulation, SPICE excels in device-level simulation, and is good can be analyzed using various post-processing functions in for analysis of a particular device in detail (for example, turn-on/ • Motor Drive • PsimBook Exercise the waveform display program Simview. In addition, PSIM is turn-off transients), or for gate drive circuit studies. With both the Adjustable speed drives & motion control Unified documentation & simulation environment interactive. It allows users to monitor simulation waveforms and PSIM engine and SPICE engine in one integrated environment, change parameters on-the-fly.