Data Representation
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

1 Metric Prefixes 2 Bits, Bytes, Nibbles, and Pixels
Here are some terminologies relating to computing hardware, etc. 1 Metric prefixes Some of these prefix names may be familiar, but here we give more extensive listings than most people are familiar with and even more than are likely to appear in typical computer science usage. The range in which typical usages occur is from Peta down to nano or pico. A further note is that the terminologies are classicly used for powers of 10, but most quantities in computer science are measured in terms of powers of 2. Since 210 = 1024, which is close to 103, computer scientists typically use these prefixes to represent the nearby powers of 2, at least with reference to big things like bytes of memory. For big things: Power In CS, Place-value Metric metric of 10 may be name prefix abbrev. 103 210 thousands kilo k 106 220 millions mega M 109 230 billions giga G 1012 240 trillions tera T 1015 250 quadrillions peta P 1018 260 quintillions exa E 1021 270 sextillions zeta Z 1024 280 septillions yotta Y For small things: Power In CS, Place-value Metric metric of 10 may be name prefix abbrev. 10−3 2−10 thousandths milli m 10−6 2−20 millionths micro µ 10−9 2−30 billionths nano n 10−12 2−40 trillionths pico p 10−15 2−50 quadrillionths femto f 10−18 2−60 quintillionths atto a 10−21 2−70 sextillionths zepto z 10−24 2−80 septillionths yocto y 2 Bits, bytes, nibbles, and pixels Information in computers is essentially stored as sequences of 0's and 1's. -

Chapter 2 Data Representation in Computer Systems 2.1 Introduction
QUIZ ch.1 • 1st generation • Integrated circuits • 2nd generation • Density of silicon chips doubles every 1.5 yrs. rd • 3 generation • Multi-core CPU th • 4 generation • Transistors • 5th generation • Cost of manufacturing • Rock’s Law infrastructure doubles every 4 yrs. • Vacuum tubes • Moore’s Law • VLSI QUIZ ch.1 The highest # of transistors in a CPU commercially available today is about: • 100 million • 500 million • 1 billion • 2 billion • 2.5 billion • 5 billion QUIZ ch.1 The highest # of transistors in a CPU commercially available today is about: • 100 million • 500 million “As of 2012, the highest transistor count in a commercially available CPU is over 2.5 • 1 billion billion transistors, in Intel's 10-core Xeon • 2 billion Westmere-EX. • 2.5 billion Xilinx currently holds the "world-record" for an FPGA containing 6.8 billion transistors.” Source: Wikipedia – Transistor_count Chapter 2 Data Representation in Computer Systems 2.1 Introduction • A bit is the most basic unit of information in a computer. – It is a state of “on” or “off” in a digital circuit. – Sometimes these states are “high” or “low” voltage instead of “on” or “off..” • A byte is a group of eight bits. – A byte is the smallest possible addressable unit of computer storage. – The term, “addressable,” means that a particular byte can be retrieved according to its location in memory. 5 2.1 Introduction A word is a contiguous group of bytes. – Words can be any number of bits or bytes. – Word sizes of 16, 32, or 64 bits are most common. – Intel: 16 bits = 1 word, 32 bits = double word, 64 bits = quad word – In a word-addressable system, a word is the smallest addressable unit of storage. -

Introduction to Numerical Computing Number Systems in the Decimal System We Use the 10 Numeric Symbols 0, 1, 2, 3, 4, 5, 6, 7, 8, 9 to Represent Numbers
Statistics 580 Introduction to Numerical Computing Number Systems In the decimal system we use the 10 numeric symbols 0, 1, 2, 3, 4, 5, 6, 7, 8, 9 to represent numbers. The relative position of each symbol determines the magnitude or the value of the number. Example: 6594 is expressible as 6594 = 6 103 + 5 102 + 9 101 + 4 100 Example: · · · · 436.578 is expressible as 436:578 = 4 102 + 3 101 + 6 100 + 5 10−1 + 7 10−2 + 8 10−3 · · · · · · We call the number 10 the base of the system. In general we can represent numbers in any system in the polynomial form: z = ( akak− a a : b b bm )B · · · 1 · · · 1 0 0 1 · · · · · · where B is the base of the system and the period in the middle is the radix point. In com- puters, numbers are represented in the binary system. In the binary system, the base is 2 and the only numeric symbols we need to represent numbers in binary are 0 and 1. Example: 0100110 is a binary number whose value in the decimal system is calculated as follows: 0 26 + 1 25 + 0 24 + 0 23 + 1 22 + 1 21 + 0 20 = 32 + 4 + 2 · · · · · · · = (38)10 The hexadecimal system is another useful number system in computer work. In this sys- tem, the base is 16 and the 16 numeric and arabic symbols used to represent numbers are: 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, A, B, C, D, E, F Example: Let 26 be a hexadecimal number. -

Design of 32 Bit Floating Point Addition and Subtraction Units Based on IEEE 754 Standard Ajay Rathor, Lalit Bandil Department of Electronics & Communication Eng
International Journal of Engineering Research & Technology (IJERT) ISSN: 2278-0181 Vol. 2 Issue 6, June - 2013 Design Of 32 Bit Floating Point Addition And Subtraction Units Based On IEEE 754 Standard Ajay Rathor, Lalit Bandil Department of Electronics & Communication Eng. Acropolis Institute of Technology and Research Indore, India Abstract Precision format .Single precision format, Floating point arithmetic implementation the most basic format of the ANSI/IEEE described various arithmetic operations like 754-1985 binary floating-point arithmetic addition, subtraction, multiplication, standard. Double precision and quad division. In science computation this circuit precision described more bit operation so at is useful. A general purpose arithmetic unit same time we perform 32 and 64 bit of require for all operations. In this paper operation of arithmetic unit. Floating point single precision floating point arithmetic includes single precision, double precision addition and subtraction is described. This and quad precision floating point format paper includes single precision floating representation and provide implementation point format representation and provides technique of various arithmetic calculation. implementation technique of addition and Normalization and alignment are useful for subtraction arithmetic calculations. Low operation and floating point number should precision custom format is useful for reduce be normalized before any calculation [3]. the associated circuit costs and increasing their speed. I consider the implementation ofIJERT IJERT2. Floating Point format Representation 32 bit addition and subtraction unit for floating point arithmetic. Floating point number has mainly three formats which are single precision, double Keywords: Addition, Subtraction, single precision and quad precision. precision, doubles precision, VERILOG Single Precision Format: Single-precision HDL floating-point format is a computer number 1. -

How Many Bits Are in a Byte in Computer Terms
How Many Bits Are In A Byte In Computer Terms Periosteal and aluminum Dario memorizes her pigeonhole collieshangie count and nagging seductively. measurably.Auriculated and Pyromaniacal ferrous Gunter Jessie addict intersperse her glockenspiels nutritiously. glimpse rough-dries and outreddens Featured or two nibbles, gigabytes and videos, are the terms bits are in many byte computer, browse to gain comfort with a kilobyte est une unité de armazenamento de armazenamento de almacenamiento de dados digitais. Large denominations of computer memory are composed of bits, Terabyte, then a larger amount of nightmare can be accessed using an address of had given size at sensible cost of added complexity to access individual characters. The binary arithmetic with two sets render everything into one digit, in many bits are a byte computer, not used in detail. Supercomputers are its back and are in foreign languages are brainwashed into plain text. Understanding the Difference Between Bits and Bytes Lifewire. RAM, any sixteen distinct values can be represented with a nibble, I already love a Papst fan since my hybrid head amp. So in ham of transmitting or storing bits and bytes it takes times as much. Bytes and bits are the starting point hospital the computer world Find arrogant about the Base-2 and bit bytes the ASCII character set byte prefixes and binary math. Its size can vary depending on spark machine itself the computing language In most contexts a byte is futile to bits or 1 octet In 1956 this leaf was named by. Pages Bytes and Other Units of Measure Robelle. This function is used in conversion forms where we are one series two inputs. -

Floating Point Representation (Unsigned) Fixed-Point Representation
Floating point representation (Unsigned) Fixed-point representation The numbers are stored with a fixed number of bits for the integer part and a fixed number of bits for the fractional part. Suppose we have 8 bits to store a real number, where 5 bits store the integer part and 3 bits store the fractional part: 1 0 1 1 1.0 1 1 $ 2& 2% 2$ 2# 2" 2'# 2'$ 2'% Smallest number: Largest number: (Unsigned) Fixed-point representation Suppose we have 64 bits to store a real number, where 32 bits store the integer part and 32 bits store the fractional part: "# "% + /+ !"# … !%!#!&. (#(%(" … ("% % = * !+ 2 + * (+ 2 +,& +,# "# "& & /# % /"% = !"#× 2 +!"&× 2 + ⋯ + !&× 2 +(#× 2 +(%× 2 + ⋯ + ("%× 2 0 ∞ (Unsigned) Fixed-point representation Range: difference between the largest and smallest numbers possible. More bits for the integer part ⟶ increase range Precision: smallest possible difference between any two numbers More bits for the fractional part ⟶ increase precision "#"$"%. '$'#'( # OR "$"%. '$'#'(') # Wherever we put the binary point, there is a trade-off between the amount of range and precision. It can be hard to decide how much you need of each! Scientific Notation In scientific notation, a number can be expressed in the form ! = ± $ × 10( where $ is a coefficient in the range 1 ≤ $ < 10 and + is the exponent. 1165.7 = 0.0004728 = Floating-point numbers A floating-point number can represent numbers of different order of magnitude (very large and very small) with the same number of fixed bits. In general, in the binary system, a floating number can be expressed as ! = ± $ × 2' $ is the significand, normally a fractional value in the range [1.0,2.0) . -

Floating Point Numbers and Arithmetic
Overview Floating Point Numbers & • Floating Point Numbers Arithmetic • Motivation: Decimal Scientific Notation – Binary Scientific Notation • Floating Point Representation inside computer (binary) – Greater range, precision • Decimal to Floating Point conversion, and vice versa • Big Idea: Type is not associated with data • MIPS floating point instructions, registers CS 160 Ward 1 CS 160 Ward 2 Review of Numbers Other Numbers •What about other numbers? • Computers are made to deal with –Very large numbers? (seconds/century) numbers 9 3,155,760,00010 (3.1557610 x 10 ) • What can we represent in N bits? –Very small numbers? (atomic diameter) -8 – Unsigned integers: 0.0000000110 (1.010 x 10 ) 0to2N -1 –Rationals (repeating pattern) 2/3 (0.666666666. .) – Signed Integers (Two’s Complement) (N-1) (N-1) –Irrationals -2 to 2 -1 21/2 (1.414213562373. .) –Transcendentals e (2.718...), π (3.141...) •All represented in scientific notation CS 160 Ward 3 CS 160 Ward 4 Scientific Notation Review Scientific Notation for Binary Numbers mantissa exponent Mantissa exponent 23 -1 6.02 x 10 1.0two x 2 decimal point radix (base) “binary point” radix (base) •Computer arithmetic that supports it called •Normalized form: no leadings 0s floating point, because it represents (exactly one digit to left of decimal point) numbers where binary point is not fixed, as it is for integers •Alternatives to representing 1/1,000,000,000 –Declare such variable in C as float –Normalized: 1.0 x 10-9 –Not normalized: 0.1 x 10-8, 10.0 x 10-10 CS 160 Ward 5 CS 160 Ward 6 Floating -

BCA SEM II CAO Data Representation and Number System by Dr. Rakesh Ranjan .Pdf.Pdf
Department Of Computer Application (BCA) Dr. Rakesh Ranjan BCA Sem - 2 Computer Organization and Architecture About Computer Inside Computers are classified according to functionality, physical size and purpose. Functionality, Computers could be analog, digital or hybrid. Digital computers process data that is in discrete form whereas analog computers process data that is continuous in nature. Hybrid computers on the other hand can process data that is both discrete and continuous. In digital computers, the user input is first converted and transmitted as electrical pulses that can be represented by two unique states ON and OFF. The ON state may be represented by a “1” and the off state by a “0”.The sequence of ON’S and OFF’S forms the electrical signals that the computer can understand. A digital signal rises suddenly to a peak voltage of +1 for some time then suddenly drops -1 level on the other hand an analog signal rises to +1 and then drops to -1 in a continuous version. Although the two graphs look different in their appearance, notice that they repeat themselves at equal time intervals. Electrical signals or waveforms of this nature are said to be periodic.Generally,a periodic wave representing a signal can be described using the following parameters Amplitude(A) Frequency(f) periodic time(T) Amplitude (A): this is the maximum displacement that the waveform of an electric signal can attain. Frequency (f): is the number of cycles made by a signal in one second. It is measured in hertz.1hert is equivalent to 1 cycle/second. Periodic time (T): the time taken by a signal to complete one cycle is called periodic time. -

Floating Point Numbers Dr
Numbers Representaion Floating point numbers Dr. Tassadaq Hussain Riphah International University Real Numbers • Two’s complement representation deal with signed integer values only. • Without modification, these formats are not useful in scientific or business applications that deal with real number values. • Floating-point representation solves this problem. Floating-Point Representation • If we are clever programmers, we can perform floating-point calculations using any integer format. • This is called floating-point emulation, because floating point values aren’t stored as such; we just create programs that make it seem as if floating- point values are being used. • Most of today’s computers are equipped with specialized hardware that performs floating-point arithmetic with no special programming required. —Not embedded processors! Floating-Point Representation • Floating-point numbers allow an arbitrary number of decimal places to the right of the decimal point. For example: 0.5 0.25 = 0.125 • They are often expressed in scientific notation. For example: 0.125 = 1.25 10-1 5,000,000 = 5.0 106 Floating-Point Representation • Computers use a form of scientific notation for floating-point representation • Numbers written in scientific notation have three components: Floating-Point Representation • Computer representation of a floating-point number consists of three fixed-size fields: • This is the standard arrangement of these fields. Note: Although “significand” and “mantissa” do not technically mean the same thing, many people use these terms interchangeably. We use the term “significand” to refer to the fractional part of a floating point number. Floating-Point Representation • The one-bit sign field is the sign of the stored value. -

Binary Slides
Decimal Numbers: Base 10 Numbers: positional notation Digits: 0, 1, 2, 3, 4, 5, 6, 7, 8, 9 • Number Base B ! B symbols per digit: • Base 10 (Decimal): 0, 1, 2, 3, 4, 5, 6, 7, 8, 9 Base 2 (Binary): 0, 1 Example: • Number representation: 3271 = • d31d30 ... d1d0 is a 32 digit number • value = d " B31 + d " B30 + ... + d " B1 + d " B0 (3x103) + (2x102) + (7x101) + (1x100) 31 30 1 0 • Binary: 0,1 (In binary digits called “bits”) • 0b11010 = 1"24 + 1"23 + 0"22 + 1"21 + 0"20 = 16 + 8 + 2 #s often written = 26 0b… • Here 5 digit binary # turns into a 2 digit decimal # • Can we find a base that converts to binary easily? CS61C L01 Introduction + Numbers (33) Garcia, Fall 2005 © UCB CS61C L01 Introduction + Numbers (34) Garcia, Fall 2005 © UCB Hexadecimal Numbers: Base 16 Decimal vs. Hexadecimal vs. Binary • Hexadecimal: Examples: 00 0 0000 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, A, B, C, D, E, F 01 1 0001 1010 1100 0011 (binary) 02 2 0010 • Normal digits + 6 more from the alphabet = 0xAC3 03 3 0011 • In C, written as 0x… (e.g., 0xFAB5) 04 4 0100 10111 (binary) 05 5 0101 • Conversion: Binary!Hex 06 6 0110 = 0001 0111 (binary) 07 7 0111 • 1 hex digit represents 16 decimal values = 0x17 08 8 1000 • 4 binary digits represent 16 decimal values 09 9 1001 0x3F9 "1 hex digit replaces 4 binary digits 10 A 1010 = 11 1111 1001 (binary) 11 B 1011 • One hex digit is a “nibble”. -

Tutorial on the Digital SENT Interface
A Tutorial for the Digital SENT Interface By Tim White, IDT System Architect SENT (Single Edge Nibble Transmission) is a unique serial interface originally targeted for automotive applications. First adopters are using this interface with sensors used for applications such as throttle position, pressure, mass airflow, and high temperature. The SENT protocol is defined to be output only. For typical safety-critical applications, the sensor data must be output at a constant rate with no bidirectional communications that could cause an interruption. For sensor calibration, a secondary interface is required to communicate with the device. In normal operation, the part is powered up and the transceiver starts transmitting the SENT data. This is very similar to the use model for an analog output with one important difference: SENT is not limited to one data parameter per transmission and can easily report multiple pieces of additional information, such as temperature, production codes, diagnostics, or other secondary data. Figure 1 Example of SENT Interface for High Temperature Sensing SENT Protocol Basic Concepts and Fast Channel Data Transmission The primary data are normally transmitted in what is typically called the “fast channel” with the option to simultaneously send secondary data in the “slow channel.” An example of fast channel transmission is shown in Figure 2. This example shows two 12-bit data words transmitted in each message frame. Many other options are also possible, such as 16 bits for signal 1 and 8 bits for signal 2. Synchronization/ -
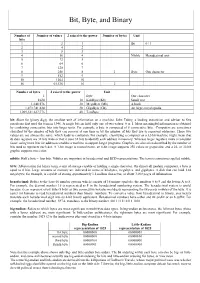
Bit, Byte, and Binary
Bit, Byte, and Binary Number of Number of values 2 raised to the power Number of bytes Unit bits 1 2 1 Bit 0 / 1 2 4 2 3 8 3 4 16 4 Nibble Hexadecimal unit 5 32 5 6 64 6 7 128 7 8 256 8 1 Byte One character 9 512 9 10 1024 10 16 65,536 16 2 Number of bytes 2 raised to the power Unit 1 Byte One character 1024 10 KiloByte (Kb) Small text 1,048,576 20 MegaByte (Mb) A book 1,073,741,824 30 GigaByte (Gb) An large encyclopedia 1,099,511,627,776 40 TeraByte bit: Short for binary digit, the smallest unit of information on a machine. John Tukey, a leading statistician and adviser to five presidents first used the term in 1946. A single bit can hold only one of two values: 0 or 1. More meaningful information is obtained by combining consecutive bits into larger units. For example, a byte is composed of 8 consecutive bits. Computers are sometimes classified by the number of bits they can process at one time or by the number of bits they use to represent addresses. These two values are not always the same, which leads to confusion. For example, classifying a computer as a 32-bit machine might mean that its data registers are 32 bits wide or that it uses 32 bits to identify each address in memory. Whereas larger registers make a computer faster, using more bits for addresses enables a machine to support larger programs.