Programming the GPU in Java CODING
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

The Importance of Data
The landscape of Parallel Programing Models Part 2: The importance of Data Michael Wong and Rod Burns Codeplay Software Ltd. Distiguished Engineer, Vice President of Ecosystem IXPUG 2020 2 © 2020 Codeplay Software Ltd. Distinguished Engineer Michael Wong ● Chair of SYCL Heterogeneous Programming Language ● C++ Directions Group ● ISOCPP.org Director, VP http://isocpp.org/wiki/faq/wg21#michael-wong ● [email protected] ● [email protected] Ported ● Head of Delegation for C++ Standard for Canada Build LLVM- TensorFlow to based ● Chair of Programming Languages for Standards open compilers for Council of Canada standards accelerators Chair of WG21 SG19 Machine Learning using SYCL Chair of WG21 SG14 Games Dev/Low Latency/Financial Trading/Embedded Implement Releasing open- ● Editor: C++ SG5 Transactional Memory Technical source, open- OpenCL and Specification standards based AI SYCL for acceleration tools: ● Editor: C++ SG1 Concurrency Technical Specification SYCL-BLAS, SYCL-ML, accelerator ● MISRA C++ and AUTOSAR VisionCpp processors ● Chair of Standards Council Canada TC22/SC32 Electrical and electronic components (SOTIF) ● Chair of UL4600 Object Tracking ● http://wongmichael.com/about We build GPU compilers for semiconductor companies ● C++11 book in Chinese: Now working to make AI/ML heterogeneous acceleration safe for https://www.amazon.cn/dp/B00ETOV2OQ autonomous vehicle 3 © 2020 Codeplay Software Ltd. Acknowledgement and Disclaimer Numerous people internal and external to the original C++/Khronos group, in industry and academia, have made contributions, influenced ideas, written part of this presentations, and offered feedbacks to form part of this talk. But I claim all credit for errors, and stupid mistakes. These are mine, all mine! You can’t have them. -

AMD Accelerated Parallel Processing Opencl Programming Guide
AMD Accelerated Parallel Processing OpenCL Programming Guide November 2013 rev2.7 © 2013 Advanced Micro Devices, Inc. All rights reserved. AMD, the AMD Arrow logo, AMD Accelerated Parallel Processing, the AMD Accelerated Parallel Processing logo, ATI, the ATI logo, Radeon, FireStream, FirePro, Catalyst, and combinations thereof are trade- marks of Advanced Micro Devices, Inc. Microsoft, Visual Studio, Windows, and Windows Vista are registered trademarks of Microsoft Corporation in the U.S. and/or other jurisdic- tions. Other names are for informational purposes only and may be trademarks of their respective owners. OpenCL and the OpenCL logo are trademarks of Apple Inc. used by permission by Khronos. The contents of this document are provided in connection with Advanced Micro Devices, Inc. (“AMD”) products. AMD makes no representations or warranties with respect to the accuracy or completeness of the contents of this publication and reserves the right to make changes to specifications and product descriptions at any time without notice. The information contained herein may be of a preliminary or advance nature and is subject to change without notice. No license, whether express, implied, arising by estoppel or other- wise, to any intellectual property rights is granted by this publication. Except as set forth in AMD’s Standard Terms and Conditions of Sale, AMD assumes no liability whatsoever, and disclaims any express or implied warranty, relating to its products including, but not limited to, the implied warranty of merchantability, fitness for a particular purpose, or infringement of any intellectual property right. AMD’s products are not designed, intended, authorized or warranted for use as compo- nents in systems intended for surgical implant into the body, or in other applications intended to support or sustain life, or in any other application in which the failure of AMD’s product could create a situation where personal injury, death, or severe property or envi- ronmental damage may occur. -

Exploring Weak Scalability for FEM Calculations on a GPU-Enhanced Cluster
Exploring weak scalability for FEM calculations on a GPU-enhanced cluster Dominik G¨oddeke a,∗,1, Robert Strzodka b,2, Jamaludin Mohd-Yusof c, Patrick McCormick c,3, Sven H.M. Buijssen a, Matthias Grajewski a and Stefan Turek a aInstitute of Applied Mathematics, University of Dortmund bStanford University, Max Planck Center cComputer, Computational and Statistical Sciences Division, Los Alamos National Laboratory Abstract The first part of this paper surveys co-processor approaches for commodity based clusters in general, not only with respect to raw performance, but also in view of their system integration and power consumption. We then extend previous work on a small GPU cluster by exploring the heterogeneous hardware approach for a large-scale system with up to 160 nodes. Starting with a conventional commodity based cluster we leverage the high bandwidth of graphics processing units (GPUs) to increase the overall system bandwidth that is the decisive performance factor in this scenario. Thus, even the addition of low-end, out of date GPUs leads to improvements in both performance- and power-related metrics. Key words: graphics processors, heterogeneous computing, parallel multigrid solvers, commodity based clusters, Finite Elements PACS: 02.70.-c (Computational Techniques (Mathematics)), 02.70.Dc (Finite Element Analysis), 07.05.Bx (Computer Hardware and Languages), 89.20.Ff (Computer Science and Technology) ∗ Corresponding author. Address: Vogelpothsweg 87, 44227 Dortmund, Germany. Email: [email protected], phone: (+49) 231 755-7218, fax: -5933 1 Supported by the German Science Foundation (DFG), project TU102/22-1 2 Supported by a Max Planck Center for Visual Computing and Communication fellowship 3 Partially supported by the U.S. -

Multiplatformní Knihovna Pro Interakci S Grafickým Uživatelským Prostředím
Masarykova univerzita Fakulta}w¡¢£¤¥¦§¨ informatiky !"#$%&'()+,-./012345<yA| Multiplatformní knihovna pro interakci s grafickým uživatelským prostředím Bakalářská práce Jaromír Kala Brno, 2014 Prohlášení Prohlašuji, že tato bakalářská práce je mým původním autorským dílem, které jsem vypracoval samostatně. Všechny zdroje, prameny a literaturu, které jsem při vypracování používal nebo z nich čerpal, v práci řádně cituji s uvedením úplného odkazu na příslušný zdroj. Jaromír Kala Vedoucí práce: RNDr. Pavel Troubil ii Poděkování Rád bych poděkoval RNDr. Pavlu Troubilovi za cenné rady, věcné připomínky a ochotu při konzultacích a vypracování bakalářské práce. iii Shrnutí Cílem bakalářské práce bylo vytvořit multiplatformní knihovnu pro manipulaci s grafickým uživatelským rozhraním. Vzniklá knihovna WDDMan podporuje detekci připojených monitorů a jejich rozlišení, zjištění otevřených oken a manipulaci s nimi (zavření, změny velikostí a přesuny) a detekci virtuálních ploch. Knihovna WDDMan funguje na operačních systémech skupiny Windows, Linux a Mac OS. Kni- hovna s podobnou funkcionalitou doposud nebyla k dispozici a bude použita v middleware CoUniverse pro manipulaci s objekty videokon- ferenčních nástrojů. Prostředí CoUniverse se využije pro vzdálené tlu- močení přednášek pro Středisko pro pomoc studentům se specifickými nároky Masarykovy univerzity. Knihovna WDDMan bude zveřejněna pod otevřenou licencí k volnému užití. Součástí knihovny je i anglická dokumentace a ukázkový a testovací příklad. iv Klíčová slova CoUniverse, Windows API, XLib, JNA, AppleScript, GUI v Obsah 1 Úvod ...............................2 2 Popis použitých technologií .................4 2.1 Java Native Access .....................4 2.1.1 Popis knihovny Java Native Access . .4 2.1.2 Použití JNA v knihovně WDDMan . .7 2.2 Windows API ........................8 2.3 X Window System a Xlib .................9 2.4 AppleScript ........................ -
Unravel Data Systems Version 4.5
UNRAVEL DATA SYSTEMS VERSION 4.5 Component name Component version name License names jQuery 1.8.2 MIT License Apache Tomcat 5.5.23 Apache License 2.0 Tachyon Project POM 0.8.2 Apache License 2.0 Apache Directory LDAP API Model 1.0.0-M20 Apache License 2.0 apache/incubator-heron 0.16.5.1 Apache License 2.0 Maven Plugin API 3.0.4 Apache License 2.0 ApacheDS Authentication Interceptor 2.0.0-M15 Apache License 2.0 Apache Directory LDAP API Extras ACI 1.0.0-M20 Apache License 2.0 Apache HttpComponents Core 4.3.3 Apache License 2.0 Spark Project Tags 2.0.0-preview Apache License 2.0 Curator Testing 3.3.0 Apache License 2.0 Apache HttpComponents Core 4.4.5 Apache License 2.0 Apache Commons Daemon 1.0.15 Apache License 2.0 classworlds 2.4 Apache License 2.0 abego TreeLayout Core 1.0.1 BSD 3-clause "New" or "Revised" License jackson-core 2.8.6 Apache License 2.0 Lucene Join 6.6.1 Apache License 2.0 Apache Commons CLI 1.3-cloudera-pre-r1439998 Apache License 2.0 hive-apache 0.5 Apache License 2.0 scala-parser-combinators 1.0.4 BSD 3-clause "New" or "Revised" License com.springsource.javax.xml.bind 2.1.7 Common Development and Distribution License 1.0 SnakeYAML 1.15 Apache License 2.0 JUnit 4.12 Common Public License 1.0 ApacheDS Protocol Kerberos 2.0.0-M12 Apache License 2.0 Apache Groovy 2.4.6 Apache License 2.0 JGraphT - Core 1.2.0 (GNU Lesser General Public License v2.1 or later AND Eclipse Public License 1.0) chill-java 0.5.0 Apache License 2.0 Apache Commons Logging 1.2 Apache License 2.0 OpenCensus 0.12.3 Apache License 2.0 ApacheDS Protocol -

T U M a Digital Wallet Implementation for Anonymous Cash
Technische Universität München Department of Informatics Bachelor’s Thesis in Information Systems A Digital Wallet Implementation for Anonymous Cash Oliver R. Broome Technische Universität München Department of Informatics Bachelor’s Thesis in Information Systems A Digital Wallet Implementation for Anonymous Cash Implementierung eines digitalen Wallets for anonyme Währungen Author Oliver R. Broome Supervisor Prof. Dr.-Ing. Georg Carle Advisor Sree Harsha Totakura, M. Sc. Date October 15, 2015 Informatik VIII Chair for Network Architectures and Services I conrm that this thesis is my own work and I have documented all sources and material used. Garching b. München, October 15, 2015 Signature Abstract GNU Taler is a novel approach to digital payments with which payments are performed with cryptographically generated representations of actual currencies. The main goal of GNU Taler is to allow taxable anonymous payments to non-anonymous merchants. This thesis documents the implementation of the Android version of the GNU Taler wallet, which allows users to create new Taler-based funds and perform payments with them. Zusammenfassung GNU Taler ist ein neuartiger Ansatz für digitales Bezahlen, bei dem Zahlungen mit kryptographischen Repräsentationen von echten Währungen getätigt werden. Das Hauptziel von GNU Taler ist es, versteuerbare, anonyme Zahlungen an nicht-anonyme Händler zu ermöglichen. Diese Arbeit dokumentiert die Implementation der Android-Version des Taler-Portemonnaies, der es Benutzern erlaubt, neues Taler-Guthaben zu erzeugen und mit ihnen Zahlungen zu tätigen. I Contents 1 Introduction 1 1.1 GNU Taler . .2 1.2 Goals of the thesis . .2 1.3 Outline . .3 2 Implementation prerequisites 5 2.1 Native libraries . .5 2.1.1 Libgcrypt . -

Evolution of the Graphical Processing Unit
University of Nevada Reno Evolution of the Graphical Processing Unit A professional paper submitted in partial fulfillment of the requirements for the degree of Master of Science with a major in Computer Science by Thomas Scott Crow Dr. Frederick C. Harris, Jr., Advisor December 2004 Dedication To my wife Windee, thank you for all of your patience, intelligence and love. i Acknowledgements I would like to thank my advisor Dr. Harris for his patience and the help he has provided me. The field of Computer Science needs more individuals like Dr. Harris. I would like to thank Dr. Mensing for unknowingly giving me an excellent model of what a Man can be and for his confidence in my work. I am very grateful to Dr. Egbert and Dr. Mensing for agreeing to be committee members and for their valuable time. Thank you jeffs. ii Abstract In this paper we discuss some major contributions to the field of computer graphics that have led to the implementation of the modern graphical processing unit. We also compare the performance of matrix‐matrix multiplication on the GPU to the same computation on the CPU. Although the CPU performs better in this comparison, modern GPUs have a lot of potential since their rate of growth far exceeds that of the CPU. The history of the rate of growth of the GPU shows that the transistor count doubles every 6 months where that of the CPU is only every 18 months. There is currently much research going on regarding general purpose computing on GPUs and although there has been moderate success, there are several issues that keep the commodity GPU from expanding out from pure graphics computing with limited cache bandwidth being one. -

Graphics Processing Units
Graphics Processing Units Graphics Processing Units (GPUs) are coprocessors that traditionally perform the rendering of 2-dimensional and 3-dimensional graphics information for display on a screen. In particular computer games request more and more realistic real-time rendering of graphics data and so GPUs became more and more powerful highly parallel specialist computing units. It did not take long until programmers realized that this computational power can also be used for tasks other than computer graphics. For example already in 1990 Lengyel, Re- ichert, Donald, and Greenberg used GPUs for real-time robot motion planning [43]. In 2003 Harris introduced the term general-purpose computations on GPUs (GPGPU) [28] for such non-graphics applications running on GPUs. At that time programming general-purpose computations on GPUs meant expressing all algorithms in terms of operations on graphics data, pixels and vectors. This was feasible for speed-critical small programs and for algorithms that operate on vectors of floating-point values in a similar way as graphics data is typically processed in the rendering pipeline. The programming paradigm shifted when the two main GPU manufacturers, NVIDIA and AMD, changed the hardware architecture from a dedicated graphics-rendering pipeline to a multi-core computing platform, implemented shader algorithms of the rendering pipeline in software running on these cores, and explic- itly supported general-purpose computations on GPUs by offering programming languages and software- development toolchains. This chapter first gives an introduction to the architectures of these modern GPUs and the tools and languages to program them. Then it highlights several applications of GPUs related to information security with a focus on applications in cryptography and cryptanalysis. -

The Shallow Water Equations on Graphics Processing Units
Compact Stencils for the Shallow Water Equations on Graphics Processing Units Technology for a better society 1 Brief Outline • Introduction to Computing on GPUs • The Shallow Water Equations • Compact Stencils on the GPU • Physical correctness • Summary Technology for a better society 2 Introduction to GPU Computing Technology for a better society 3 Long, long time ago, … 1942: Digital Electric Computer (Atanasoff and Berry) 1947: Transistor (Shockley, Bardeen, and Brattain) 1956 1958: Integrated Circuit (Kilby) 2000 1971: Microprocessor (Hoff, Faggin, Mazor) 1971- More transistors (Moore, 1965) Technology for a better society 4 The end of frequency scaling 2004-2011: Frequency A serial program uses 2% 1971-2004: constant 29% increase in of available resources! frequency 1999-2011: 25% increase in Parallelism technologies: parallelism • Multi-core (8x) • Hyper threading (2x) • AVX/SSE/MMX/etc (8x) 1971: Intel 4004, 1982: Intel 80286, 1993: Intel Pentium P5, 2000: Intel Pentium 4, 2010: Intel Nehalem, 2300 trans, 740 KHz 134 thousand trans, 8 MHz 1.18 mill. trans, 66 MHz 42 mill. trans, 1.5 GHz 2.3 bill. trans, 8 X 2.66 GHz Technology for a better society 5 How does parallelism help? 100% The power density of microprocessors Single Core 100% is proportional to the clock frequency cubed: 100% 85% Multi Core 100% 170 % Frequency Power 30% Performance GPU 100 % ~10x Technology for a better society 6 The GPU: Massive parallelism CPU GPU Cores 4 16 Float ops / clock 64 1024 Frequency (MHz) 3400 1544 GigaFLOPS 217 1580 Memory (GiB) 32+ 3 Performance -

Developers Guide
jjPPrroodduuccttiivviittyy LLLLCC Protection User Guide Developers Guide Licensing Toolkit Protect your investments Protect your with Protection! http://www.jproductivity.com v 5 . 2 ! tm Revision 397 - 1/7/20 Notice of Copyright Published by jProductivity, LLC Copyright ©2003-2019 All rights reserved. Registered Trademarks and Proprietary Names Product names mentioned in this document may be trademarks or registered trademarks of jProductivity, LLC or other hardware, software, or service providers and are used herein for identification purposes only. Applicability This document applies to Protection! v5.2 software. 2 Protection! Developers Guide v5.2 Copyright © 2003-2019 jProductivity L.L.C. http://www. jproductivity.com Contents Contents ....................................................................................................................... 3 1. Protection! Licensing Toolkit Concepts ........................................................................... 6 1.1 Key Concepts ................................................................................................. 6 1.1.1 License File .............................................................................................. 6 1.1.2 Protection! Control Center ......................................................................... 6 1.1.3 Secret Storage ......................................................................................... 6 1.2 Protection! Process ......................................................................................... -

Fragment Shader
Programmable Graphics Hardware Outline 2/ 49 A brief Introduction into Programmable Graphics Hardware • Hardware Graphics Pipeline • Shading Languages • Tools • GPGPU • Resources [email protected] Dynamic Graphics Project University of Toronto Hardware Graphics Pipeline 3/ 49 Hardware Graphics Pipeline From vertices to pixels ... and what you can do in between. [email protected] Dynamic Graphics Project University of Toronto Hardware Graphics Pipeline 4/ 49 Hardware Graphics Pipeline GPU Video Memory CPU Vertex Fragment Processor Processor Raster Render Screen Unit Target [email protected] Dynamic Graphics Project University of Toronto Hardware Graphics Pipeline 5/ 49 Hardware Graphics Pipeline GPU Video Memory CPU Vertex Fragment Processor Processor Raster Render Screen Unit Target [email protected] Dynamic Graphics Project University of Toronto Hardware Graphics Pipeline 6/ 49 Hardware Graphics Pipeline GPU Video Memory CPU Vertex Fragment Processor Processor Raster Render Screen Unit Target [email protected] Dynamic Graphics Project University of Toronto Hardware Graphics Pipeline 7/ 49 Hardware Graphics Pipeline GPU Video Memory CPU Vertex Fragment Processor Processor Raster Render Screen Unit Target [email protected] Dynamic Graphics Project University of Toronto Hardware Graphics Pipeline 8/ 49 Hardware Graphics Pipeline GPU Video Memory CPU Vertex Fragment Processor Processor Raster Render Screen Unit Target [email protected] Dynamic Graphics Project University of Toronto Hardware Graphics Pipeline -
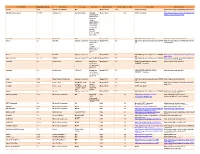
Third Party Version
Third Party Name Third Party Version Manufacturer License Type Comments Merge Product Merge Product Versions License details Software source autofac 3.5.2 Autofac Contributors MIT Merge Cardio 10.2 SOUP repository https://www.nuget.org/packages/Autofac/3.5 .2 Gibraltar Loupe Agent 2.5.2.815 eSymmetrix Gibraltor EULA Gibraltar Merge Cardio 10.2 SOUP repository https://my.gibraltarsoftware.com/Support/Gi Loupe Agent braltar_2_5_2_815_Download will be used within the Cardio Application to view events and metrics so you can resolve support issues quickly and easily. Modernizr 2.8.3 Modernizr MIT Merge Cadio 6.0 http://modernizr.com/license/ http://modernizr.com/download/ drools 2.1 Red Hat Apache License 2.0 it is a very old Merge PACS 7.0 http://www.apache.org/licenses/LICENSE- http://mvnrepository.com/artifact/drools/dro version of 2.0 ols-spring/2.1 drools. Current version is 6.2 and license type is changed too drools 6.3 Red Hat Apache License 2.0 Merge PACS 7.1 http://www.apache.org/licenses/LICENSE- https://github.com/droolsjbpm/drools/releases/ta 2.0 g/6.3.0.Final HornetQ 2.2.13 v2.2..13 JBOSS Apache License 2.0 part of JBOSS Merge PACS 7.0 http://www.apache.org/licenses/LICENSE- http://mvnrepository.com/artifact/org.hornet 2.0 q/hornetq-core/2.2.13.Final jcalendar 1.0 toedter.com LGPL v2.1 MergePacs Merge PACS 7.0 GNU LESSER GENERAL PUBLIC http://toedter.com/jcalendar/ server uses LICENSE Version 2. v1, and viewer uses v1.3.