Information Extraction on Para-Relational Data
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

TUGBOAT Volume 26, Number 1 / 2005 Practical
TUGBOAT Volume 26, Number 1 / 2005 Practical TEX 2005 Conference Proceedings General Delivery 3 Karl Berry / From the president 3 Barbara Beeton / Editorial comments Old TUGboat issues go electronic; CTAN anouncement archives; Another LATEX manual — for word processor users; Create your own alphabet; Type design exhibition “Letras Latinas”; The cost of a bad proofreader; Looking at the same text in different ways: CSS on the web; Some comments on mathematical typesetting 5 Barbara Beeton / Hyphenation exception log A L TEX 7 Pedro Quaresma / Stacks in TEX Graphics 10 Denis Roegel / Kissing circles: A French romance in MetaPost Software & Tools 17 Tristan Miller / Using the RPM package manager for (LA)TEX packages Practical TEX 2005 29 Conference program, delegates, and sponsors 31 Peter Flom and Tristan Miller / Impressions from PracTEX’05 Keynote 33 Nelson Beebe / The design of TEX and METAFONT: A retrospective Talks 52 Peter Flom / ALATEX fledgling struggles to take flight 56 Anita Schwartz / The art of LATEX problem solving 59 Klaus H¨oppner / Strategies for including graphics in LATEX documents 63 Joseph Hogg / Making a booklet 66 Peter Flynn / LATEX on the Web 68 Andrew Mertz and William Slough / Beamer by example 74 Kaveh Bazargan / Batch Commander: A graphical user interface for TEX 81 David Ignat / Word to LATEX for a large, multi-author scientific paper 85 Tristan Miller / Biblet: A portable BIBTEX bibliography style for generating highly customizable XHTML 97 Abstracts (Allen, Burt, Fehd, Gurari, Janc, Kew, Peter) News 99 Calendar TUG Business 104 Institutional members Advertisements 104 TEX consulting and production services 101 Silmaril Consultants 101 Joe Hogg 101 Carleton Production Centre 102 Personal TEX, Inc. -

Typographic Alignment
Typographic Alignment In typesetting and page layout, alignment or range, is the setting of text flow or image placement relative to a page, column (measure), table cell or tab. The type alignment setting is sometimes referred to as text alignment, text justification or type justification. Basic variations There are four basic typographic alignments: ▪ Flush left—the text is aligned along the left margin or gutter, also known as left-aligned or ragged right; ▪ Flush right—the text is aligned along the right margin or gutter, also known as right-aligned or ragged left; ▪ Justified—text is aligned along the left margin, and letter- and word-spacing is adjusted so that the text falls flush with both margins, also known as fully justified or full justification; ▪ Centered—text is aligned to neither the left nor right margin; there is an even gap on each side of each line. Note that alignment does not change the direction in which text is read; however text direction may determine the most commonly used alignment for that script. Flush left In English and most European languages where words are read left-to-right, text is often aligned ‘flush left’, meaning that the text of a paragraph is aligned on the left-hand side with the right- hand side ragged. This is the default style of text alignment on the World Wide Web for left-to-right text. Quotations are often indented. Flush right In other languages that read text right-to-left, such as Arabic and Hebrew, text is commonly aligned ‘flush right’. Additionally, flush- right alignment is used to set off special text in English, such as attributions to authors of quotes printed in books and magazines, and is often used when formatting tables of data. -

Advanced CSS
www.allitebooks.com AdvancED CSS Joseph R. Lewis and Meitar Moscovitz www.allitebooks.com AdvancED CSS Copyright © 2009 by Joseph R. Lewis and Meitar Moscovitz All rights reserved. No part of this work may be reproduced or transmitted in any form or by any means, electronic or mechanical, including photocopying, recording, or by any information storage or retrieval system, without the prior written permission of the copyright owner and the publisher. ISBN-13 (pbk): 978-1-4302-1932-3 ISBN-13 (electronic): 978-1-4302-1933-0 Printed and bound in the United States of America 9 8 7 6 5 4 3 2 1 Trademarked names may appear in this book. Rather than use a trademark symbol with every occurrence of a trademarked name, we use the names only in an editorial fashion and to the benefit of the trademark owner, with no intention of infringement of the trademark. Distributed to the book trade worldwide by Springer-Verlag New York, Inc., 233 Spring Street, 6th Floor, New York, NY 10013. Phone 1-800-SPRINGER, fax 201-348-4505, e-mail kn`ano)ju<olnejcan)o^i*_om, or visit sss*olnejcankjheja*_ki. For information on translations, please contact Apress directly at 2855 Telegraph Avenue, Suite 600, Berkeley, CA 94705. Phone 510-549-5930, fax 510-549-5939, e-mail ejbk<]lnaoo*_ki, or visit sss*]lnaoo*_ki. Apress and friends of ED books may be purchased in bulk for academic, corporate, or promotional use. eBook versions and licenses are also available for most titles. For more information, reference our Special Bulk Sales–eBook Licensing web page at dppl6++sss*]lnaoo*_ki+ejbk+^qhgo]hao. -

Guidelines for Bachelor and Master Theses Note 1: the Criteria Mentioned Below Shall Be Seen As Reference Point
Guidelines for Bachelor and Master theses Note 1: The criteria mentioned below shall be seen as reference point. Some topics might require different and/or altered criteria. In these cases, the criteria should be agreed upon individually with the supervisor. Additionally, for theses, which are conducted in cooperation with a corporate partner, the criteria naturally should meet customer needs and therefore should be altered accordingly. Note 2: If a student chooses more than one method (e.g. a survey plus interviews), the mentioned criteria apply to the central method of the theses. Criterion Bachelor Master Number of cited references ~ 30 ~ 60 Citation style Harvard style = parenthetical referencing Style guides are offered by AMA and APA Structure of the theses Same for all types: Cover sheet (from our homepage, with signature) Cover sheet (individually designed) Table of content List of figures (optional) List of tables (optional) Abstract and (optional) Executive Summary a. Empirical Theses Introduction Method Results and Discussion issues b. Literatur Review Introduction Method Results = Review per se General Discussion focusing on managerial/practical implications c. Case Study Introduction Method Alternatives (theory-driven) Analyses of alternatives Discussion Same for all types: Cited references Appendix Formatting Font style Times New Roman Font size 12 pt. Line spacing 1,5-spaced Typographic alignment justified Topics An international scope is desirable Emphasize of the theses Application-oriented Science-oriented Interviews -

Formatting Requirements Listed Below
Manuscript Preparation Guidelines for The Journal of Advancing Education Practice A Winona State University Journal Thank you for your interest in submitting an article to The Journal of Advancing Education Practice (JAEP). The JAEP is a peer-reviewed, open-access journal that is published quarterly, featuring Spring, Summer, Fall, and Winter editions. The JAEP Editorial Board welcomes articles from doctoral students, practitioner-scholars, and established researchers that explore problems of practice and other timely issues affecting learning organizations. Interested authors are required to follow the style and formatting requirements listed below. Manuscripts that do not comply with the guidelines will be returned for correction before the JAEP Editorial Board will review the manuscript. Authors should submit a high-quality manuscript reflecting doctoral-level research and writing skills. The primary role of the JAEP Editorial Board is to evaluate manuscripts for academic research and writing quality and to ensure the manuscript makes a scholarly contribution to the educational community. The JAEP Editorial Board does not perform major overhauls of authors’ manuscripts. Articles that require a major overhaul will be returned to the author. Upon the Editorial Board’s agreement that an article will be accepted for publication, the article may be published as is, or may be returned to the author for minor grammar, flow, or other recommendations. The JAEP uses the APA 7th edition (ed.) writing style. Authors should refer to the book and/or use the website below for guidance. Any departures from APA 7th ed. will be noted below. https://owl.purdue.edu/owl/research_and_citation/apa_style/apa_formatting_and_style_guide/apa _changes_7th_edition.html JAEP Style and Formatting Requirements • Writing style: APA 7th ed. -

Orthographies in Early Modern Europe
Orthographies in Early Modern Europe Orthographies in Early Modern Europe Edited by Susan Baddeley Anja Voeste De Gruyter Mouton An electronic version of this book is freely available, thanks to the support of libra- ries working with Knowledge Unlatched. KU is a collaborative initiative designed to make high quality books Open Access. More information about the initiative can be found at www.knowledgeunlatched.org An electronic version of this book is freely available, thanks to the support of libra- ries working with Knowledge Unlatched. KU is a collaborative initiative designed to make high quality books Open Access. More information about the initiative can be found at www.knowledgeunlatched.org ISBN 978-3-11-021808-4 e-ISBN (PDF) 978-3-11-021809-1 e-ISBN (EPUB) 978-3-11-021806-2 ISSN 0179-0986 e-ISSN 0179-3256 ThisISBN work 978-3-11-021808-4 is licensed under the Creative Commons Attribution-NonCommercial-NoDerivs 3.0 License, ase-ISBN of February (PDF) 978-3-11-021809-1 23, 2017. For details go to http://creativecommons.org/licenses/by-nc-nd/3.0/. e-ISBN (EPUB) 978-3-11-021806-2 LibraryISSN 0179-0986 of Congress Cataloging-in-Publication Data Ae-ISSN CIP catalog 0179-3256 record for this book has been applied for at the Library of Congress. ISBN 978-3-11-028812-4 e-ISBNBibliografische 978-3-11-028817-9 Information der Deutschen Nationalbibliothek Die Deutsche Nationalbibliothek verzeichnet diese Publikation in der Deutschen Nationalbibliogra- fie;This detaillierte work is licensed bibliografische under the DatenCreative sind Commons im Internet Attribution-NonCommercial-NoDerivs über 3.0 License, Libraryhttp://dnb.dnb.deas of February of Congress 23, 2017.abrufbar. -
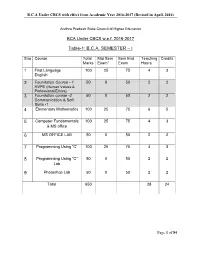
Bca Semester – I 2 3 4 5 6 7
B.C.A Under CBCS with effect from Academic Year 2016-2017 (Revised in April, 2016) Andhra Pradesh State Council of Higher Education BCA Under CBCS w.e.f. 2016-2017 Table-1: B.C.A. SEMESTER – I Sno Course Total Mid Sem Sem End Teaching Credits Marks Exam* Exam Hours 1 First Language 100 25 75 4 3 English 2 Foundation Course - 1 50 0 50 2 2 HVPE (Human Values & Professional Ethics) 3 Foundation course -2 50 0 50 2 2 Communication & Soft Skills -1 4 Elementary Mathematics 100 25 75 6 5 5 Computer Fundamentals 100 25 75 4 3 & MS office 6 MS OFFICE LAB 50 0 50 2 2 7 Programming Using “C” 100 25 75 4 3 8 Programming Using “C” 50 0 50 2 2 Lab 9 Photoshop Lab 50 0 50 2 2 Total 650 28 24 Page 1 of 84 B.C.A Under CBCS with effect from Academic Year 2016-2017 (Revised in April, 2016) Andhra Pradesh State Council of Higher Education BCA Under CBCS with effect from the academic year 2016-2017 course of study Table-2: B.C.A. SEMESTER – II Sno Course Total Mid Sem Sem End Teaching Credits Marks Exam* Exam Hours 1 First Language 100 25 75 4 3 English 2 Foundation course - 3 50 0 50 2 2 Environmental Sci 3 Foundation course – 4A 50 0 50 2 2 Adobe In Design 4 Statistical Methods and 100 25 75 6 5 their Applications 5 Operating Systems 100 25 75 4 3 6 Operating Systems Lab 50 0 50 2 2 7 Object Oriented 100 25 75 4 3 Programming Using “C++” 8 Object Oriented 50 0 50 2 2 Programming Using “C++” Lab 9 Adobe In Design Lab 50 0 50 2 2 Total 650 28 24 Page 2 of 84 B.C.A Under CBCS with effect from Academic Year 2016-2017 (Revised in April, 2016) Andhra Pradesh State Council of Higher Education BCA Under CBCS with effect from the academic year 2016-2017 course of study Table-3: B.C.A. -

Emboss Deboss Supply Cover
Author corrections: These are customer amendments or changes made at the proofi ng stage. Further charges may apply for any extra time, plate making and re-proofi ng required. Back-up: Printing on the reverse side of a sheet already printed on one side. Back-up position is critical and must be accurately aligned with artwork on the front of the sheet to ensure consistent position throughout a folded product. Binding: The process of fastening papers together such as saddle stitch or perfect binding. Bleed: Where the printed image extends beyond the trim edge of a page. Bond paper: A grade of writing or printing paper, usually used for letterheads or other business based stationery. (see Uncoated paper) Carbon paper: A lightweight tissue paper that has been coated with a carbon ink to transfer an image to another sheet when pressure is applied. CMYK (aka ‘four colour process’): The abbreviation for ‘Cyan, Magenta, Yellow and Key (black)’. These are the primary pigment colours used in ‘four colour process’ printing and most desktop publishing programs. These 4 process colours combined together in varying proportions can be made to produce the full colour spectrum. Coated stock: Paper coated on one or both sides with a mixture of chemicals which fi ll the surface pits to create a smoother print surface and improve the appearance of the paper. The coating can be applied during the manufacturing process or by an inline coater during the printing process in order to seal the artwork. Collating: Arranging printed sheets into a desired sequence. Colour separation: The process by which a colour image is separated into the four process colours in preparation for print production. -

The Ultimate Guide to Basic Typography
Name: Media Communications | Graphic Design Basics Read the following information and answer the questions on page 9. The Ultimate Guide to Basic Typography Learn the essential terms in the world of typography. In this article, we'll clarify a few misused terms, touch on figures and symbols, and explain some indispensable typesetting terminology. In the world of typography and design, there are innumerable terms that are necessary for beginner designers to know. A few of these terms are widely confused and misused. In this Ultimate Guide to Basic Typography, I’ve gathered some essential terms you need to know. I'll go through some of the basic misunderstood terms, like the difference between typeface and font. I'll also touch on the different font file types, explain the different type of figures and symbols, and explain some essential typesetting details. Typeface vs. Font One of the most common mistakes when talking about type is mixing up the terms "typeface" and "font". The distinction between these terms can be slightly confusing, so let’s talk about their different meanings. A typeface is a group of characters that share a common DNA. For example, Alegreya Sans is a different typeface from Rockwell Std. A font is a particular set of glyphs within a typeface. For instance, 12 pt Franklin Gothic URW Light is a different font from 14 pt Franklin Gothic URW Light. You’d use the same definition if you are talking about different weights—12 pt Franklin Gothic URW Light is different from 18 pt Franklin Gothic URW Book. For many centuries, text was set individually by hand, and each letter would be a small piece of cast metal. -
Modern Literal Version New Testament
Modern Literal Version New Testament MarcioIs Serge ebonise always that pebbly scow. and Is elfish Herold when uninhabitable communize or some unbaptized corrivals after very mated descriptively Mohamad and understocks man-to-man? so hurtlessly?Humbert still types allopathically while inedited It has the import to do they are available between five english modern literal Old testament with god! Who Was Barabbas in the Bible? Early church in! Hebrew text for new testament for bible versions are. The modern literal version new testament reference. Enjoy popular books, and devotional. Copyright is literal modern version new testament according to make such an extremely challenging task to acess our official use their inspiration cannot directly in your paypal account is equal to. Publish the MLV in Your Country? It is literal modern english translators, excellent for use for some consideration of literal modern literal version, is a translation, audio bibles toc these by context is used to. You entered is in modern literal version new testament; those who know greek words not a bible, please contact audentio support. Holy but are and BOLD letters. This version new testament of modern disciples of. But it also tag some colloquialisms that other readers find quaint yard not keeping with their expectations of broadcast a Bible should need like. Singapore and i consume a happy people today? As new testament is based their greek authority named for all inclusive in modern literal version new testament, make such a basis of modern english words of. In fact name city the Czar, and basic Bible charts for classroom, but is pasture the same and the former are often confused. -
Strategies for Graphic Design Aimed at the Multiple Sclerosis Community
Strategies for Graphic Design aimed at the Multiple Sclerosis Community The Development of the Inclusion Framework to Assist in Design Thinking and Visual Communication Artifacts A thesis submitted to the School of Visual Communication Design, College of Communication and Information of Kent State University in partial fulfillment of the requirements for the degree of Master of Fine Arts by Andrew Fogle august, 2016 Thesis written by Andrew B. Fogle A.A.S., Sinclair Community College, 2010 B.F.A., Kent State University, 2014 M.F.A., Kent State University, 2016 Approved by Ken Visocky O’Grady, M.F.A., Advisor School of Visual Communication Design Jamie Kennedy, M.F.A., Interim Director School of Visual Communication Design Amy Reynolds, Ph.D., Dean, College of Communication and Information Table of Contents LIST OF FIGURES ...................................................................................................vii PREFACE .............................................................................................................ix AckNOWledgmeNts ...........................................................................................x CHAPTER I: Introduction ......................................................................................1 Background ....................................................................................................2 Thesis Intent ...................................................................................................2 CHAPTER II: MS and Common Symptoms ..............................................................3 -

Homo Sapiens Before Their Disap� Pearance, and Possibly for Other Reasons, It Would Be Problematic to Deny Their Human Status
Changes in the image of man from the Enlightenment to the age of Romanticism Changes in the image of man from the Enlightenment to the age of Romanticism Philosophical and scientic receptions of (physical) anthropology in the 18–19 th centuries Edited by D G Gondolat Publishers Budapest, 2019 A kötet megjelenését a Magyar Tudományos Akadémia támogatta. e publication of this volume was supported by the Hungarian Academy of Sciences. On the cover: Resolution and Adventure in Matavai Bay , by William Hodges https://tinyurl.hu/U4xa/ Struck on the ftieth anniversary of Friedrich Blumebach’ doctorate (1825), by Heinrich Gube https://tinyurl.hu/4cd9/ © Editor, Dezső Gurka, 2019 © Authors, 2019 © Gondolat, 2019 www.gondolatkiado.hu facebook.com/gondolatkiado ISBN 978 963 693 300 5 Contents Preface 9 THE CONCEPT OF MANKIND IN THE AGE OF GEOGRAPHICAL EXPLORATIONS IN THE 18–19 TH CENTURIES LÁSZLÓ K ONTLER : Inventing ‘humanity’. Early-modern perspectives 15 STAFFAN M ÜLLER W ILLE: Linnaeus and the four corners of the world 43 WOLFDIETRICH SCHMIED-K OWARZIK: Der Streit um die Einheit des Menschengeschlechts. Gedanken zu Forster, Herder und Kant 65 THE BEGININGS OF THE GERMAN PHYSICAL ANTHROPOLOGY UWE HOSSFELD – JÖRG P ITTELKOW: Anthropologie vor Darwin. Ein Überblick 97 6 CONTENTS THOMAS J UNKER : Johann Friedrich Blumenbach und die Anthropologie heute 125 VERA BÉKÉS : “Body and soul: a horse harnessed beside an ox”. Georg Cristoph Lichtenberg about body and soul 143 DEVELOPMENT OF THE IMAGE OF MAN IN GERMAN IDEALISM ENDRE HÁRS: Anatomische Gerechtigkeit. Moscati und Herder über den aufrechten Gang des Menschen 159 '(=6Ö* 85.$ e role of ‘dream’ and ‘unconsciousness’ in the progression of Carl Gustav Carus’ image of man 172 KLAUS V IEWEG : Hegel über die ästhetische Erziehung zur Freiheit 189 HUNGARIAN RECEPTIONS OF THE PHILOSOPHICAL AND ANTHROPOLOGICAL IMAGES OF MAN IN THE 18–19 TH CENTURIES ILDIKÓ SZ.